python爬虫4猫眼电影的Top100
1 查看网页结构
(1)确定需要抓取的字段
电影名称
电影主演
电影上映时间
电影评分
(2) 分析页面结构
按住f12------->点击右上角(如下图2)---->鼠标点击需要观察的字段
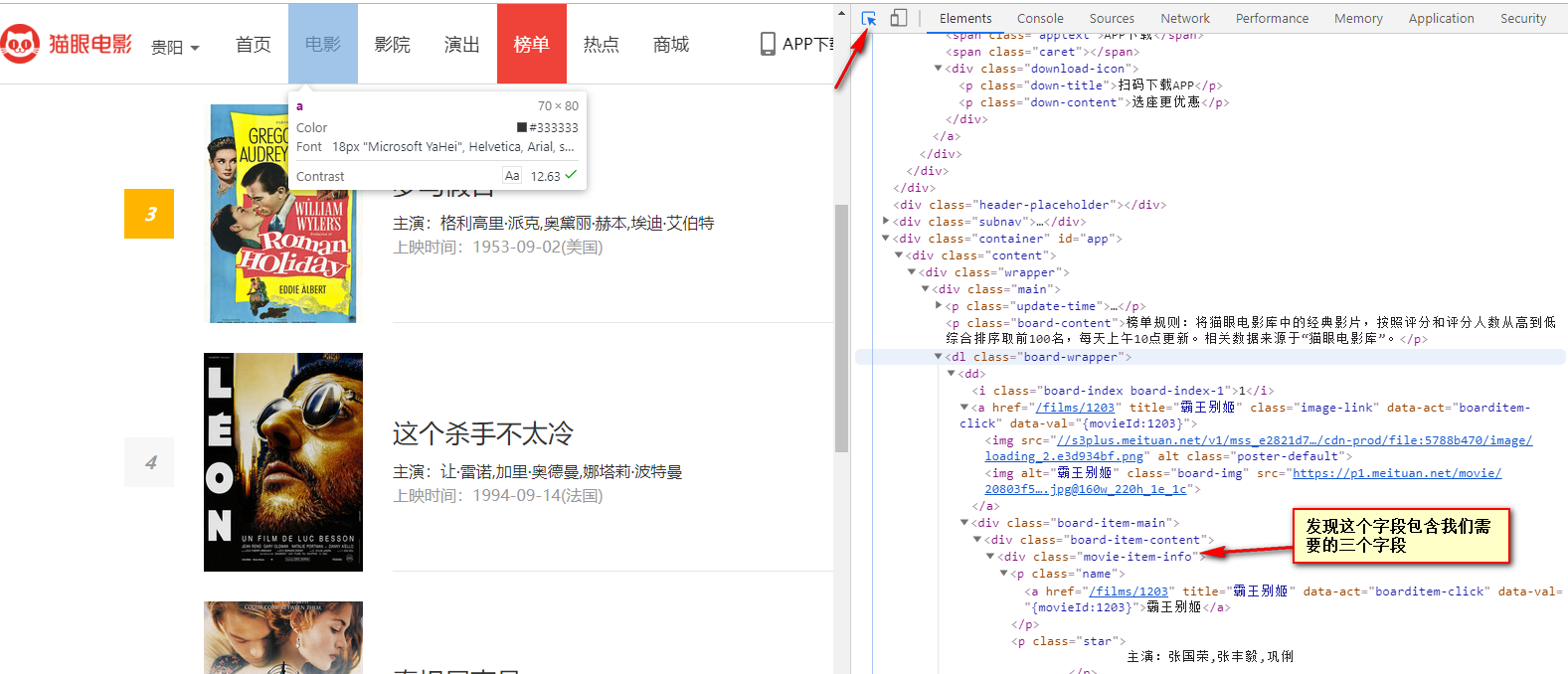
(3)BeautifulSoup解析源代码并设置过滤属性
soup = BeautifulSoup(htmll, 'lxml')
Movie_name = soup.find_all('div',class_='movie-item-info')
Movie_Score1=soup.find_all('p',class_='score')
(4)调试查看过滤属性是否正确

(5)提取对应字段
for cate,score in zip(Movie_name,Movie_Score1):
data={}
movie_name1 = cate.find('a').text.strip('\n')
data['title']=movie_name1
movie_actor = cate.find_all("p")[1].text.replace("\n"," ").strip()
data['actors']=movie_actor
movie_time=cate.find_all("p")[2].text.strip('\n').strip()
data['data']=movie_time
movie_score1=score.find_all("i")[0].string
movie_score2=score.find_all("i")[1].string
movie_score=movie_score1+movie_score2
data['score'] = movie_score
name = movie_name1 + "\t"+movie_actor+"\t" + movie_time+"\t"+movie_score
DATA.append(name)
with open('Movie1.txt', 'a+') as f:
f.write("\n{}".format(name))
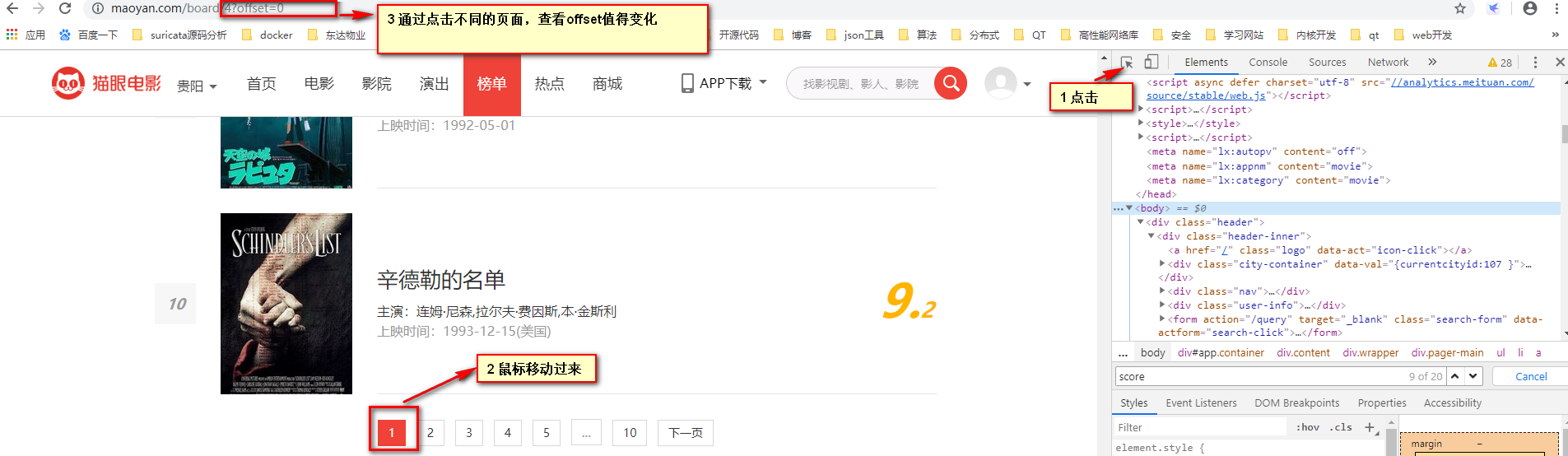
(6)翻页爬取
如下图,按照1 2 3步骤,发现页数是有这样子的规律。比如offset=0 offset=10......

2 存储excel
for datas in DATA:
datas=datas.split('\t')#因为我之前解析字段拼接的时候就是采用\t分割
print(len(datas))
print(datas)
for j in range(len(datas)):#列表中的每一项都包含按照\t分割的字段
print(j)
sheet1.write(i, j, datas[j])
i = i + 1
f.save("d.xls") # 保存文件
3 结果

python爬虫4猫眼电影的Top100的更多相关文章
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- Python正则表达式匹配猫眼电影HTML信息
爬虫项目爬取猫眼电影TOP100电影信息 项目内容来自:https://github.com/Germey/MaoYan/blob/master/spider.py 由于其中需要爬取的包含电影名字.电 ...
- Python 爬取猫眼电影最受期待榜
主要爬取猫眼电影最受期待榜的电影排名.图片链接.名称.主演.上映时间. 思路:1.定义一个获取网页源代码的函数: 2.定义一个解析网页源代码的函数: 3.定义一个将解析的数据保存为本地文件的函数: ...
- 【Python3爬虫】猫眼电影爬虫(破解字符集反爬)
一.页面分析 首先打开猫眼电影,然后点击一个正在热播的电影(比如:毒液).打开开发者工具,点击左上角的箭头,然后用鼠标点击网页上的票价,可以看到源码中显示的不是数字,而是某些根本看不懂的字符,这是因为 ...
- Python爬取猫眼电影100榜并保存到excel表格
首先我们前期要导入的第三方类库有; 通过猫眼电影100榜的源码可以看到很有规律 如: 亦或者是: 根据规律我们可以得到非贪婪的正则表达式 """<div class ...
- 用Python爬取猫眼上的top100评分电影
代码如下: # 注意encoding = 'utf-8'和ensure_ascii = False,不写的话不能输出汉字 import requests from requests.exception ...
- 爬虫_猫眼电影top100(正则表达式)
代码查看码云
随机推荐
- children(),find()
向下遍历 DOM 树 下面是两个用于向下遍历 DOM 树的 jQuery 方法: children() find() jQuery children() 方法 children() 方法返回被选元素的 ...
- [Javascript] Keyword 'in' to check prop exists on Object
function addTo80(n ) { + n; } function memoizedAddTo80 (fn) { let cache = {}; return (n) => { /*k ...
- LeetCode 787. Cheapest Flights Within K Stops
原题链接在这里:https://leetcode.com/problems/cheapest-flights-within-k-stops/ 题目: There are n cities connec ...
- LeetCode 990. Satisfiability of Equality Equations
原题链接在这里:https://leetcode.com/problems/satisfiability-of-equality-equations/ 题目: Given an array equat ...
- window对象方法(open和close)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- ROM
ROM 是 read only memory的简称,表示只读存储器,是一种半导体存储器.只读存储器(ROM)是一种在正常工作时其存储的数据固定不变,其中的数据只能读出,不能写入,即使断电也能够保留数据 ...
- 如何学习uni-app?
uni-app 是一个使用 Vue.js 开发跨平台应用的前端框架. 开发者通过编写 Vue.js 代码,uni-app 将其编译到iOS.Android.微信小程序.H5等多个平台,保证其正确运行并 ...
- 什么是uni-app?
uni-app 是一个使用 Vue.js 开发所有前端应用的框架,开发者编写一套代码,可发布到iOS.Android.H5.以及各种小程序(微信/支付宝/百度/头条/QQ/钉钉)等多个平台. 即使不跨 ...
- Java 堆栈内存的理解
Java中变量在内存中的分配1). 类变量(static修饰的变量):在程序加载时系统就为它在堆中开辟了内存,堆中的内存地址存放于栈以便高速访问.静态变量的生命周期—一直持续到整个“系统”关闭 2). ...
- Serlvet开发
javaweb学习总结(五)——Servlet开发(一) 一.Servlet简介 Servlet是sun公司提供的一门用于开发动态web资源的技术. Sun公司在其API中提供了一个servlet接口 ...