SQL Server里Grouping Sets的威力
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务)。我不是说在生产里使用开发版,也不是说安装盗版SQL Server。
不可能的任务?未必,因为通过SQL Server里所谓的Grouping Sets就可以。在这篇文章里我会给你概括介绍下Grouping Sets,使用它们可以实现哪类查询,什么是它们的性能优势。
使用Grouping Sets的聚合
假设你有个订单表,你想进行跨多个分组的T-SQL聚集查询。在AdventureWorks2012数据库的Sales.SalesOrderHeader表的环境里,这些分组可以类似如下:
- 在每列分组
- GROUP BY SalesPersonID, YEAR(OrderDate)
- GROUP BY CustomerID, YEAR(OrderDate)
- GROUP BY CustomerID, SalesPersonID, YEAR(OrderDate)
当你想用传统T-SQL查询进行这些各自分组时,你需要多个语句,对各个记录集进行UNION ALL。我们来看这样的查询:
SELECT * FROM
(
-- 1st Grouping Set
SELECT
NULL AS 'CustomerID',
NULL AS 'SalesPersonID',
NULL AS 'OrderYear',
SUM(TotalDue) AS 'TotalDue'
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL UNION ALL -- 2nd Grouping Set
SELECT
NULL AS 'CustomerID',
SalesPersonID,
YEAR(OrderDate) AS 'OrderYear',
SUM(TotalDue) AS 'TotalDue'
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
GROUP BY SalesPersonID, YEAR(OrderDate) UNION ALL -- 3rd Grouping Set
SELECT
CustomerID,
NULL AS 'SalesPersonID',
YEAR(OrderDate) AS 'OrderYear',
SUM(TotalDue) AS 'TotalDue'
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
GROUP BY CustomerID, YEAR(OrderDate) UNION ALL -- 4th Grouping Set
SELECT
CustomerID,
SalesPersonID,
YEAR(OrderDate) AS 'OrderYear',
SUM(TotalDue) AS 'TotalDue'
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
GROUP BY CustomerID, SalesPersonID, YEAR(OrderDate)
) AS t
ORDER BY CustomerID, SalesPersonID, OrderYear
GO
用这个T-SQL语句方法有多个缺点:
- T-SQL语句本身很庞大,因为每个单独分组都是一个不同查询。
- 每查询1次,Sales.SalesOrderHeader表需要访问4次。
- 每查询1次,你在执行计划里会看到SQL Server进行了4次的索引查找(非聚集)(Index Seek (NonClustered) )。

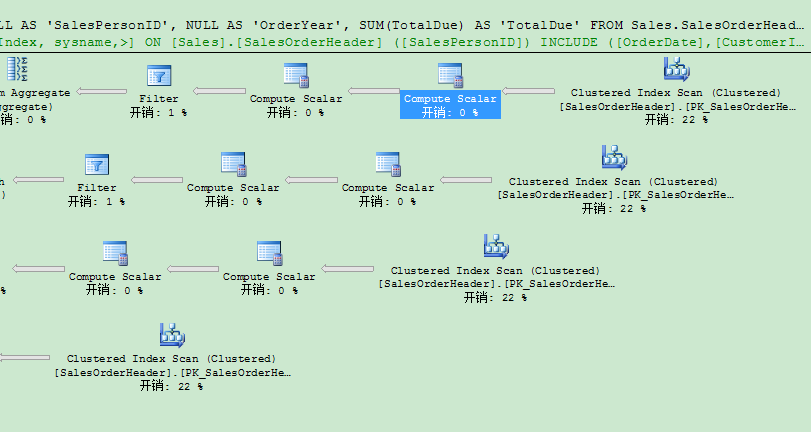
如果你使用自SQL Server 2008以后引入的grouping sets功能,就可以大大简化你需要的T-SQL代码。下面代码展示你同样的查询,但这次用grouping sets实现。
SELECT
CustomerID,
SalesPersonID,
YEAR(OrderDate) AS 'OrderYear',
SUM(TotalDue) AS 'TotalDue'
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
GROUP BY GROUPING SETS
(
-- Our 4 different grouping sets
(CustomerID, SalesPersonID, YEAR(OrderDate)),
(CustomerID, YEAR(OrderDate)),
(SalesPersonID, YEAR(OrderDate)),
()
)
GO
从代码本身可以看到,你只在GROUP BY GROUPING SETS子句里指定需要的分组集——其它的一切都由SQL Server搞定。指定的空括号是所谓的Empty Grouping Set,是跨整个表的聚集。当你看STATISTICS IO输出时,你会发现Sales.SalesOrderHeader只被访问了1次!这是和刚才手工实现的巨大区别。

在执行计划里,SQL Server使用了Table Spool运算符,它把获得的数据临时存储在TempDb里。来自临时表里创建的Worktable的数据在执行计划的第2个分支被使用。因此对来自表的每个分组数据没有重新扫描,这就给整个执行计划的带来了更好的性能。
我们再来看下执行计划,你会发现查询计划包含了3个Stream Aggregate运算符(红色,蓝色,绿色高亮显示)。这3个运算符计算各个分组集:
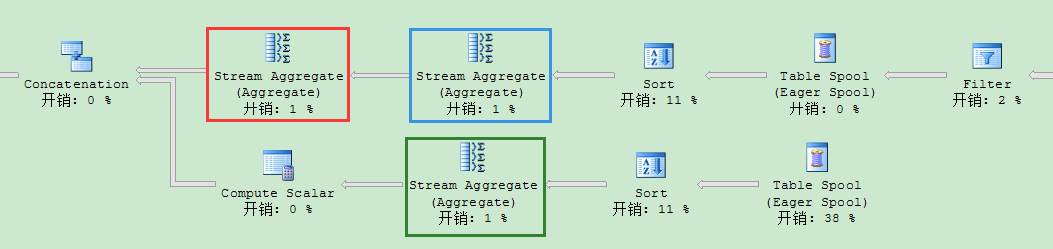
- 蓝色高亮的运算符计算CustomerID, SalesPersonID, YEAR(OrderDate的分组集。
- 红色高亮的运算符计算SalesPersonID, YEAR(OrderDate)的分组集。另外也计算每1列的分组集。
- 绿色高亮的运算符计算CustomerID, YEAR(OrderDate)的分组集。
2个连续的Stream Aggregate运算符的背后想法是计算所谓的Super Aggregates——聚集的聚集。
小结
在今天的文章里我给你介绍了grouping sets,在SQL Server 2008后引入的增强T-SQL。如你所见grouping sets有2个大优点:简化你的代码,只访问一次数据提高查询性能。
我希望现在你已经能够很好理解grouping sets,如果你能在你的数据库里使用这个功能可以在此留言,非常感谢!
感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2014/09/15/the-power-of-grouping-sets-in-sql-server/
SQL Server里Grouping Sets的威力的更多相关文章
- SQL Server里Grouping Sets的威力【转】
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
- SQL Server里PIVOT运算符的”红颜祸水“
在今天的文章里我想讨论下SQL Server里一个特别的T-SQL语言结构——自SQL Server 2005引入的PIVOT运算符.我经常引用这个与语言结构是SQL Server里最危险的一个——很 ...
- SQL Server里在文件组间如何移动数据?
平常我不知道被问了几次这样的问题:“SQL Server里在文件组间如何移动数据?“你意识到这个问题:你只有一个主文件组的默认配置,后来围观了“SQL Server里的文件和文件组”后,你知道,有多 ...
- SQL Server里的文件和文件组
在今天的文章里,我想谈下SQL Server里非常重要的话题:SQL Server如何处理文件的文件组.当你用CREATE DATABASE命令创建一个简单的数据库时,SQL Server为你创建2个 ...
- 在SQL Server里我们为什么需要意向锁(Intent Locks)?
在1年前,我写了篇在SQL Server里为什么我们需要更新锁.今天我想继续这个讨论,谈下SQL Server里的意向锁,还有为什么需要它们. SQL Server里的锁层级 当我讨论SQL Serv ...
- SQL Server里的闩锁介绍
在今天的文章里我想谈下SQL Server使用的更高级的,轻量级的同步对象:闩锁(Latch).闩锁是SQL Server存储引擎使用轻量级同步对象,用来保护多线程访问内存内结构.文章的第1部分我会介 ...
- 在SQL Server里为什么我们需要更新锁
今天我想讲解一个特别的问题,在我每次讲解SQL Server里的锁和阻塞(Locking & Blocking)都会碰到的问题:在SQL Server里,为什么我们需要更新锁?在我们讲解具体需 ...
- 在SQL Server里如何进行页级别的恢复
在今天的文章里我想谈下每个DBA应该知道的一个重要话题:在SQL Server里如何进行页级别还原操作.假设在SQL Server里你有一个损坏的页,你要从最近的数据库备份只还原有问题的页,而不是还原 ...
- SQL Server里强制参数化的痛苦
几天前,我写了篇SQL Server里简单参数化的痛苦.今天我想继续这个话题,谈下SQL Server里强制参数化(Forced Parameterization). 强制参数化(Forced Par ...
随机推荐
- 【CUDA学习】共享存储器
下面简单介绍一些cuda中的共享存储器和全局存储器 共享存储器,shared memory,可以被同一块中的所有线程访问的可读写存储器,生存期是块的生命期. Tesla的每个SM拥有16KB共享存储器 ...
- Delphi 2 Unleashed (一) 介绍
原书作者是作者是 Charles Calvert,国内翻译为<Delphi 2 程序设计大全>,由横空翻译组翻译,机械工业出版社1997年12月出版,看网上评论和介绍,该书是系统学习 De ...
- 滑动返回类库SwipeBackLayout的使用问题,解决返回黑屏,和看到桌面
SwipeBackLayout是一个很好的类库,它可以让Android实现类似iOS系统的右滑返回效果,但是很多用户在使用官方提供的Demo会发现,可能出现黑屏或者返回只是看到桌面背景而没有看到上一个 ...
- C# 中 KeyPress 、KeyDown 和KeyPress的详细区别[转]
研究了一下KeyDown,KeyPress 和KeyUp ,发现之间还是有点学问的. 让我们带着如下问题来说明,如果你看到这些问题你都知道,那么这篇文章你就当复习吧:) 1.这三个事件的顺序是怎么样的 ...
- 用 Mahout 和 Elasticsearch 实现推荐系统
原文地址 本文内容 软件 步骤 控制相关性 总结 参考资料 本文介绍如何用带 Apache Mahout 的 MapR Sandbox for Hadoop 和 Elasticsearch 搭建推荐引 ...
- WPF Window 服务安装
一.安装服务 1.已管理员的身份启动CMD 2.输入 cd C:\Windows\Microsoft.NET\Framework\v4.0.30319 回车 3.输入 InstallUtil.exe ...
- iOS杂谈-我为什么不用Interface builder
在互联网上关于Interface Builder的争吵每天都在发生,用和不用大家都有一大堆的理由.最近看了这篇文章,很多地方和作者有共鸣,结合自己的一些经历,就有了你现在所看到的东西,你可以把它当成前 ...
- oracle小数点前零丢失的问题
1.问题起源 oracle 数据库 字段值为小于1的小数时,使用char类型处理,会丢失小数点前面的0 例如0.2就变成了.2 2.解决办法: (1)用to_char函数 ...
- Gradle 笔记
网上有一篇文章说的很明白,图文来教你在eclipse下用gradle 来打包Androidhttp://blog.csdn.net/x605940745/article/details/4124268 ...
- MassTransit_消费者的创建
Creating a message consumer A message consumer is a class that consumes one or more message types, s ...