支持向量机(SVM)
SVM 简介
SVM:Support Vector Machine , 支持向量机, 是一种分类算法。
同Logistic 分类方法目的一样,SVM 试图想寻找分割线或面,将平面或空间里的样本点一分为二, 不过方法上有所不同:
1.Logistic分割线可以是曲线曲面 (多项式函数),SVM分割线/面只能是线型的。
2. Logistic 算法利用概率模型的最大似然公式求得风险函数,利用标准的梯度下降优化算法求个参数Θ。
3. SVM算法通过需要支持向量求得风险函数,利用带有约束条件的梯度下降优化算法求个参数Θ。过程比较复杂,涉及到拉格朗日函数,kkt条件, 拉格朗日对偶,SMO优化算法。
4. SVM 可处理线型不可分的问题吗? 答案是可以的,但需要将样本特征映射到一个高维空间(2维(x1,x2)到5维(x1,x2,x1x2,x12,x22))然后再寻找向量支持的分割平面,在最后的章节里介绍。
建模线性可分
1. 寻找支持向量
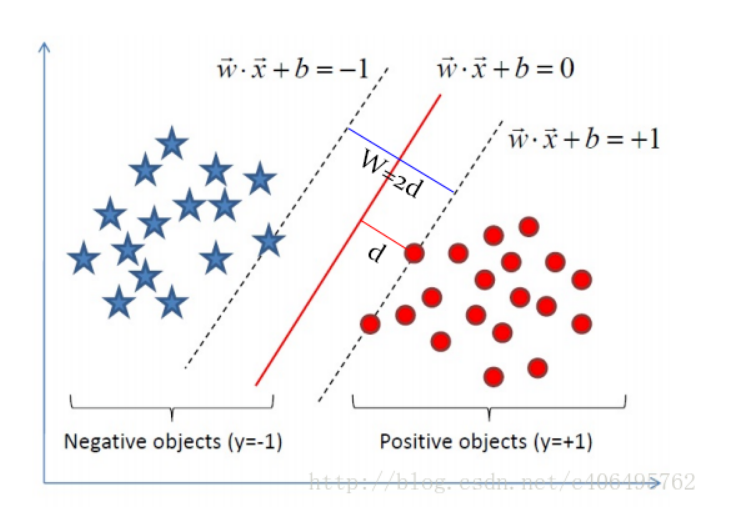
目标的中心分割线函数为ω1X1 + ω2X2 + b= 0
两条穿过支持向量的直线形成了间隔边界。两条边界直线的方程为ω1X1 + ω2X2 + b= -1 和 ω1X1 + ω2X2 + b= 1
边界与中心分割线的距离称为边界距离=d.
所有样本向量(或样本点)与中心分割线的距离的>=d. (约束条件)
SVM算法就是在以上约束条件下,通过优化求得边界 (或称超平面,”决策平面”。)参数(w,b)使边界距离d最大 。
2. 代价函数与风险函数

即:

或一般形式:

对于任意样本向量 , 到中心分割线的距离:
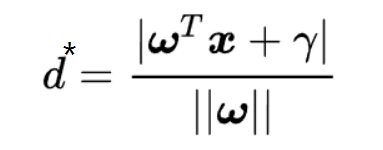
对于任意支持向量 :

在样本点中找到支持向量(2个以上), 使得边界距离的最大, 并满足以上约束条件。
最大化d, 相当于最小化w .
所以, 代价函数为 :

s.t. 是subject to 的缩写, 代表约束条件。
3. KKT条件 和拉格朗日算子法
通常带有约束条件的优化问题, 需要通过加入拉格朗日算子生成拉格朗日函数去掉约束条件,从而转化为对新的拉格朗日函数的优化问题。
带有一个等式约束条件的拉格朗日算子方法可形象的用如下的等高线图来表示。
最小化d=f(x,y) 的过程就是d从一个起点沿着在对于(x,y)的梯度向项点下降 (下降指的是梯度越来越趋于0)的过程 。
任何于f(x,y)与g(x,y) 相交的d点(如d1, d2) 都满足约束条件。
但只有f(x,y)与g(x,y)相切的d (d1)才是f(x,y)的最小值,此时的x,y是d的最优解: f'(x,y) +g'(x,y) = 0, f(x,y)和g(x,y) 复合函数(拉格朗日函数)对x,y的导数为0.

但是当原始优化问题有不等式约束条件是, 需要引入KKT(全称是Karush-Kuhn-Tucker) 条件。
原始有约束条件的优化问题通常是一下形式:
arg min d=f(x,y), x,y是要优化的参数,不是样本特征和标签。
s.t. g(x,y) <= 0;
h(x,y) = 0;
拉格朗日算子方法拉格朗日函数通常是以下形式:
L( x, y,a, b,)= f(x,y) + a*g(x,y)+b*h(x, y)
第一步 , 通过优化拉格朗日算子a,b使 L(x, y,a, b, )最大化得到Θ(x,y,a*,b*) 。 得到的Θ(x,y,a*,b*)实际是一个带有等式约束条件的优化问题。
Θ(x,y,a*,b*) = argmax L( x,y,a, b )
第二步 , 通过优化原始目标参数(x,y)使 Θ(x,y,a*,b*) 达到最小,此时得到的x,y就是能使原始优化问题f(x,y)在满足约束条件下能达到的最小值。过程如上图形象所示。
argmin Θ(x,y) = argmin argmax L(x,y,a, b)
KKT 条件为是以上过程得到最优解的必要条件。
条件一:经过拉格朗日函数L(x,y,a, b)对x,y求导为零:
这个条件意味着a,b一旦确定,拉格朗日函数L( x,y,a, b,)函数一定是一个凸函数, 函数值可以沿着(x,y)梯度下降为0, 从而使等式约束和原始目标函数相切。这个是第二步优化的必要条件。
条件二:h(x,y) = 0;
条件三:α*g(x,y) = 0;
这两个条件是能保证不等式约束后优化为一个等式约束。比如对于某些样本g(x)<0时,相应的a为0,使α*g(x,y) = 0:当 对于某些样本g(x)=0,相应的a可以是取值范围内的任意值,是可以优化的值。
总之这两个条件使α*g(x,y) +bh(x,y) =0, 从而能保证 L(a, b, x, y),沿着a,b的梯度达到最大值,从而使L(x, y,a, b)变成一个只有等式约束的问题。这个是第一步优化的必要条件。
3. 拉格朗日变换

对每一个样本(xi,yi)通过引入拉格朗日算子向量ai (>0), 从得到拉格朗日函数L(w, b, a), (注意a 的分量个数是训练样本的个数, 不是样本特征的维度), x, y 为样本值, 通过调整a算子使函数满足KKT第三条件.
条件二:h(x) = 0是满足的, 因为原始有约束条件的优化问题并没有此等式约束条件,只有不等式约束 所以h(x) = 0 。
条件一 : 需要L(w, b, a)对w和b, 分别求偏导数使偏导数方程为0, 如上节所述,这是第二步优化的必要条件。当a一旦确定,L(w, b, a)对w和b的偏导都可以为0 如下所示, 所以条件一,满足。
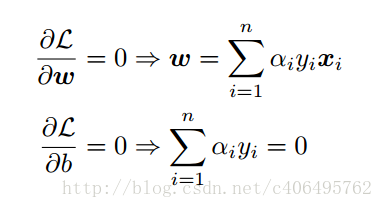
条件三: gi(w,b,xi, yi) = -ai (yi (wTxi + b) -1) = -ai (yi ui -1) ,
1.对于边界外的点, yi ui -1 > 0, 另ai=0, 从而是gi(w,b,xi, yi) =0, 满足条件。
2. 对于边界内的点是异常点, 应排除在优化及约束的范围内, yi ui -1 < 0, 另ai=C (C常数是一个很大的正数), 从而gi(w,b,xi, yi)成为一个很大的正数, 从而不会影响argmax L(w, b, a)的结果。满足条件。
3. 支持向量(间隔边界上样本点)yi ui -1 =0 , gi(w,b,xi, yi)=0. 支持向量是用来argmin Θ(w) 的目标,而w依赖a, 此时a的取值范围为 0<ai < C . 满足条件 。
条件三可表示如下,规定ai的取值从而满足条件。

4. 拉格朗日对偶问题
拉格朗日问题(如下), 是一个先通过优化拉格朗日算子a使 L(w, b, a)最大, 在优化w,b使 Θ(w,b)最小的问题。

算子a分量数目巨大,如果首先对他优化,是个十分复杂到难以求解的问题。需要对问题再进行一次转换,即使用一个数学技巧:拉格朗日对偶:

KKT条件也是强对偶的比较条件,及当 KKT条件满足时, p*=d* .

第一步求L(w,b,α)关于w和b的最小值,我们分别对w和b偏导数,令其等于0,即满足条件1 :
将上述结果带回L(w,b,α)得到:
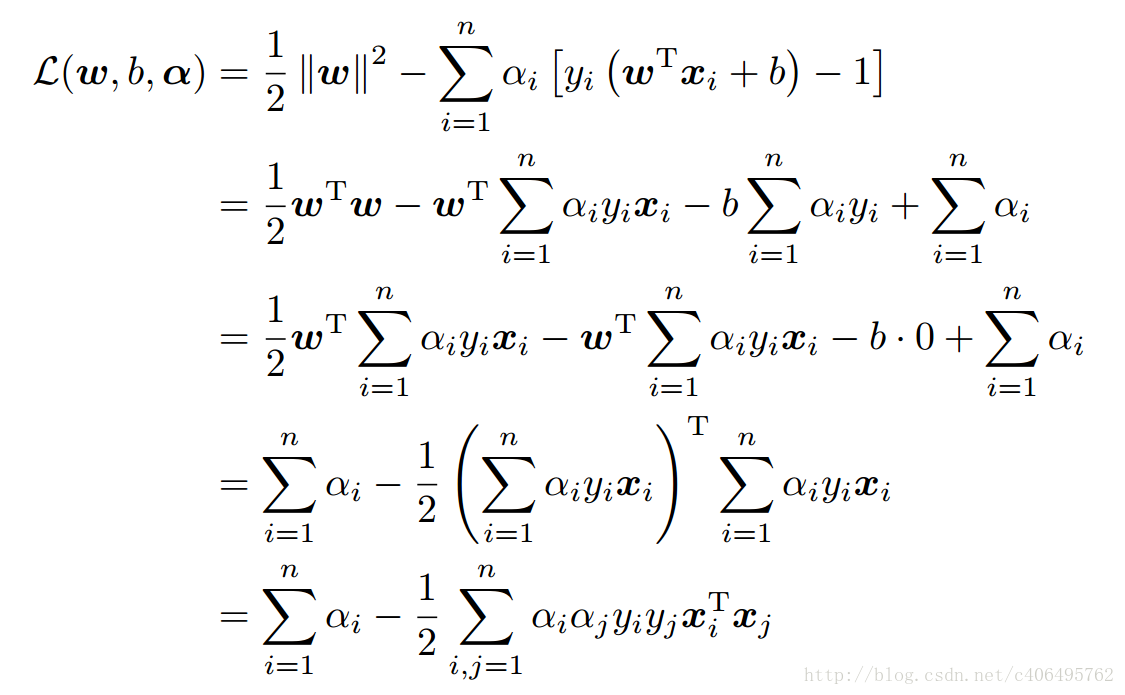
从上面的最后一个式子,我们可以看出,此时的L(w,b,α)函数只含有一个变量,即αi。
第二步:求关于a最大值,从上面的式子得到
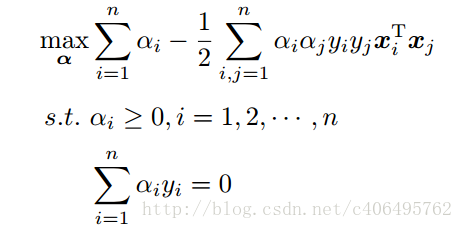
通过优化算法(满足条件三中关于a的取值范围)能得到α,再根据α,我们就可以求解出w和b,进而求得我们最初的目的:找到超平面,即”决策平面”。这个优化算法叫做SMO :表示序列最小化(Sequential Minimal Optimizaion)
满足条件三中关于a的取值范围,就要引入松弛变量(slack variable)C,来允许有些数据点可以处于超平面的错误的一侧。这样我们的优化目标就能保持仍然不变,但是此时我们的约束条件有所改变:
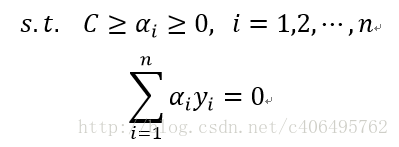
5. SMO 算法
忽略SMO算法的内部原理,让我们列出下算法的具体实现步骤:
步骤1:计算误差:

步骤2:计算上下界L和H:

步骤3:计算η:

步骤4:更新αj:

步骤5:根据取值范围修剪αj:

步骤6:更新αi:
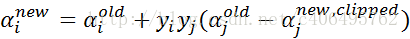
步骤7:更新b1和b2:

步骤8:根据b1和b2更新b:

线性不可分
比如下图是一个线性不可分的问题

中心决策曲线的方程,仿佛可以写作这样的形式:

注意上面的形式,如果我们构造另外一个五维的空间,其中五个坐标的值分别为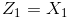

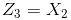

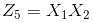

关于新的坐标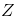
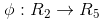
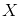
这正是 Kernel 方法处理非线性问题的基本思想。
我只需要把它映射到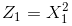
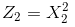
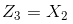

映射函数ø(x)相当于把原来的分类函数

映射成:

然后就可以用拉格朗日对偶问题的优化步骤及SMO算法求得关于 升维的关于ø(x)的超平面的参数w, b,使得:
|wT ø(xi) + b| = 1 对于任意支持向量样本点 。w的维度同ø(x)的维度。
|wT ø(xi)+ b| = 1 对于任意非支持向量样本点。w的维度同ø(x)的维度。
具体计算中如果把简单的从原始空间向多维多项式空间映射,复杂度是非常高的。比如原始空间是三维,需要映射到19维的新空间。
简单的方法是利用整个计算过程中ø(xi)总会另为一个 ø(xj)求向量内积,从而引出核函数K(xi,x) .

核函数能够利用一些低维的计算等价高位的向量内积。
几个核函数
- 线性核函数 , 就是不升高维度, 只能解决线性可分的问题。
κ(x,xi)=x⋅xi
- 多项式核函数 ,能够将低维的输入空间映射到高纬的特征空间,但是多项式核函数的参数多,当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算。
κ(x,xi)=((x⋅xi)+1)d
- 高斯(RBF)核函数
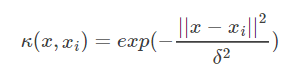
高斯径向基函数是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数。
- tanh核函数

采用sigmoid核函数,支持向量机实现的就是一种多层神经网络。
因此,在选用核函数的时候,如果我们对我们的数据有一定的先验知识,就利用先验来选择符合数据分布的核函数;如果不知道的话,通常使用交叉验证的方法,来试用不同的核函数,误差最下的即为效果最好的核函数,或者也可以将多个核函数结合起来,形成混合核函数。在吴恩达(Andrew Ng, 斯坦福教授)的课上,也曾经给出过一系列的选择核函数的方法:
如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM;
如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。
参考
https://blog.csdn.net/c406495762/article/details/78072313
https://blog.csdn.net/v_july_v/article/details/7624837
https://blog.csdn.net/xianlingmao/article/details/7919597
https://blog.csdn.net/batuwuhanpei/article/details/52354822
支持向量机(SVM)的更多相关文章
- 【IUML】支持向量机SVM
从1995年Vapnik等人提出一种机器学习的新方法支持向量机(SVM)之后,支持向量机成为继人工神经网络之后又一研究热点,国内外研究都很多.支持向量机方法是建立在统计学习理论的VC维理论和结构风险最 ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
- 机器学习算法 - 支持向量机SVM
在上两节中,我们讲解了机器学习的决策树和k-近邻算法,本节我们讲解另外一种分类算法:支持向量机SVM. SVM是迄今为止最好使用的分类器之一,它可以不加修改即可直接使用,从而得到低错误率的结果. [案 ...
- 机器学习之支持向量机—SVM原理代码实现
支持向量机—SVM原理代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9596898.html 1. 解决 ...
- 支持向量机SVM——专治线性不可分
SVM原理 线性可分与线性不可分 线性可分 线性不可分-------[无论用哪条直线都无法将女生情绪正确分类] SVM的核函数可以帮助我们: 假设‘开心’是轻飘飘的,“不开心”是沉重的 将三维视图还原 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学支持向量机SVM算法之理论篇1
一步步教你轻松学支持向量机SVM算法之理论篇1 (白宁超 2018年10月22日10:03:35) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- OpenCV 学习笔记 07 支持向量机SVM(flag)
1 SVM 基本概念 本章节主要从文字层面来概括性理解 SVM. 支持向量机(support vector machine,简SVM)是二类分类模型. 在机器学习中,它在分类与回归分析中分析数据的监督 ...
- OpenCV支持向量机(SVM)介绍
支持向量机(SVM)介绍 目标 本文档尝试解答如下问题: 如何使用OpenCV函数 CvSVM::train 训练一个SVM分类器, 以及用 CvSVM::predict 测试训练结果. 什么是支持向 ...
随机推荐
- windows下安装setuptools与pip
1.下载 setuptools与pip 下载地址如下: https://pypi.Python.org/pypi/setuptools https://pypi.Python.org/pypi/pip ...
- 一次ES故障排查过程
作者:莫那鲁道 原文:http://thinkinjava.cn/#blog 某天晚上,某环境 ES 出现阻塞, 运行缓慢.于是开始排查问题的过程. 开始 思路:现象是阻塞,通常是 CPU 彪高,导致 ...
- 爬虫-requests
一.爬虫系列之第1章-requests模块 爬虫简介 概述 近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的 ...
- 金蝶K/3 固定置产相关SQL语句
金蝶K/3 固定置产相关SQL语句 select * from vw_fa_card --固定置产打印原始数据 select FAssetID,FAssetNumber,FAssetName,FGro ...
- RabbitMQ 消息队列 二
一:查看MQ的用户角色 rabbitmqctl list_users 二:添加新的角色,并授予权限 rabbitmqctl add_user xiaoyao 123456 rabbitmqctl se ...
- zabbix4.0构建实录
[Nginx] #wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo [root@centos ...
- rsyslog 移植与配置方案介绍
rsyslog介绍 rsyslog是一个 syslogd 的多线程增强版.它提供高性能.极好的安全功能和模块化设计.虽然它基于常规的 syslogd,但 rsyslog 已经演变成了一个强大的工具,可 ...
- jade模版js中接收express的res.render
router: router.get('/', function(req, res, next) { res.render('index', { title:{name:'aaa',age:23} } ...
- JS简单实现分页显示
完整代码源码可以在这里下载 1.在 HTML文件建立列表目标节点和翻页器目标节点 <body> <!--页面控制器 --> <div id="nav" ...
- ubuntu中如何安装python3.6
此处使用命令行方式来安装Python3.6: sudo wget https://www.python.org/ftp/python/3.6.0/Python-3.6.0.tar.xz sudo ta ...