MapReduce实现PageRank算法(稀疏图法)
前言
本文用Python编写代码,并通过hadoop streaming框架运行。
算法思想
下图是一个网络:

考虑转移矩阵是一个很多的稀疏矩阵,我们可以用稀疏矩阵的形式表示,我们把web图中的每一个网页及其链出的网页作为一行,即用如下方式表示:
1 A B C D
2 B A D
3 C C
4 D B C
Map阶段
在Map阶段,Map操作的每一行,对所有出链发射当前网页概率值的1/k,k是当前网页的出链数,比如对第一行输出<B,1/3*1/4>,<C,1/3*1/4>,<D,1/3*1/4>。
Reduce阶段
Reduce操作收集同一网页的值,累加并按权重计算,即$P_{i} = \alpha \cdot (b_{1}+b_{2}+\cdots +b_{m})+\frac{(1-\alpha )}{N}$,其中$m$是指向网页$j$的网页数,$N$为所有网页数。
实践的时候,怎样在Map阶段知道当前行网页的概率值,需要一个单独的文件专门保存上一轮的概率分布值,先进行一次排序,让出链行与概率值按网页id出现在同一Mapper里面,整个流程如下:
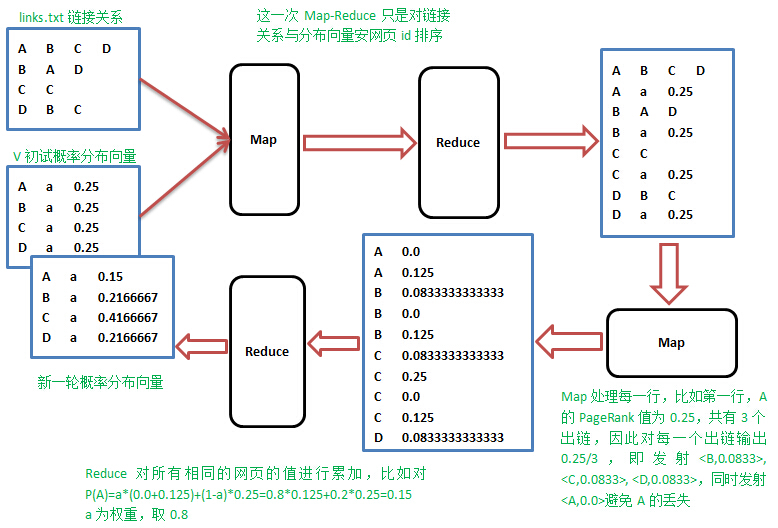
算法实现
sortMapper.py 和 sortReducer.py的功能就是将图和概率矩阵读入并进行排序。
sortMapper.py
#!/usr/bin/env python3
import sys for line in sys.stdin:
print(line.strip())
sortReducer.py
#!/usr/bin/env python3
import sys for line in sys.stdin:
print(line.strip())
pageRankMapper.py
#!/usr/bin/env python3
import sys node1 = node2 = None
count1 = count2 = 0
page_rank = 0.0 for line in sys.stdin:
if line.count('\n') == len(line):
continue # 除去空行
data = line.strip().split('\t')
if data[1] == 'a': # 该行数据是PageRank
count1 += 1
if count1 > 1: # 避免某个结点的PageRank丢失,因为有可能连着两行数据是PageRank
print('%s\t%s' % (node1, 0.0))
node1 = data[0] # 记录出发结点
page_rank = float(data[2]) # 记录出发结点的PageRank
else: # 该行是链
node2 = data[0]
reach_node_list = data[1:] if node1 == node2 and node1: # 注意除去None的情况
node_number = len(reach_node_list) # 出链数
for reach_node in reach_node_list:
print('%s\t%s' % (reach_node, page_rank*1.0/node_number))
print('%s\t%s' % (node1, 0.0))
node1 = node2 = None
count1 = 0
pageRankReducer.py
#!/usr/bin/env python3
import sys alpha = 0.8
node = None # 记录当前结点
page_rank_sum = 0.0 # 记录当前结点的PageRank总和
N = 4 for line in sys.stdin:
if line.count('\n') == len(line): continue
data = line.strip().split('\t')
if node is None or node != data[0]:
if(node): print('%s\ta\t%s' % (node, alpha*page_rank_sum + (1.0-alpha)/N))
node = data[0]
page_rank_sum = 0.0
page_rank_sum += float(data[1]) print('%s\ta\t%s' % (node, alpha*page_rank_sum + (1.0-alpha)/N))
算法运行
由于该算法需要迭代运行,所以编写shell脚本来运行。
我也不是很会写shell脚本,所以写了一个感觉比较傻的。
run.sh
#!/bin/bash max=50 for i in `seq 1 $max`
do
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-streaming-2.9.2.jar \
-mapper /usr/local/hadoop/sortMapper.py \
-file /usr/local/hadoop/sortMapper.py \
-reducer /usr/local/hadoop/sortReducer.py \
-file /usr/local/hadoop/sortReducer.py \
-input links.txt pageRank.txt \
-output out1 /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-streaming-2.9.2.jar \
-mapper /usr/local/hadoop/pageRankMapper.py \
-file /usr/local/hadoop/pageRankMapper.py \
-reducer /usr/local/hadoop/pageRankReducer.py \
-file /usr/local/hadoop/pageRankReducer.py \
-input out1/part-00000 \
-output out2 /usr/local/hadoop/bin/hadoop fs -rm pageRank.txt
/usr/local/hadoop/bin/hadoop fs -cp out2/part-00000 pageRank.txt
/usr/local/hadoop/bin/hadoop fs -rm -r -f out1
/usr/local/hadoop/bin/hadoop fs -rm -r -f out2 rm -r ~/Desktop/tmp.txt
/usr/local/hadoop/bin/hadoop fs -get pageRank.txt ~/Desktop/tmp.txt
echo $i | ~/Desktop/slove.py
done
解释一下该脚本,首先每次需要执行sortMapper.py,sortReducer.py,pageRankMapper.py,pageRankReducer.py四段代码,执行完之后会产生新的结点pageRank值,即保存在part-00000中。因为下一次运行需要用到这新的数据,所以此时把旧的pageRank.txt文件删除,再把新产生的数据复制过去。
为了记录每次迭代的结果,我还额外编写了一段代码来将记录每次结果。代码如下:
slove.py
#!/usr/bin/env python3
import sys number = sys.stdin.readline().strip() f_src = open("tmp.txt","r")
f_dst = open("result.txt", "a") mat = "{:^30}\t"
f_dst.write('\n' + number) lines = f_src.readlines()
for line in lines:
if line.count('\n') == len(line):
continue
data = line.strip().split('\t')
f_dst.write(mat.format(data[2]))
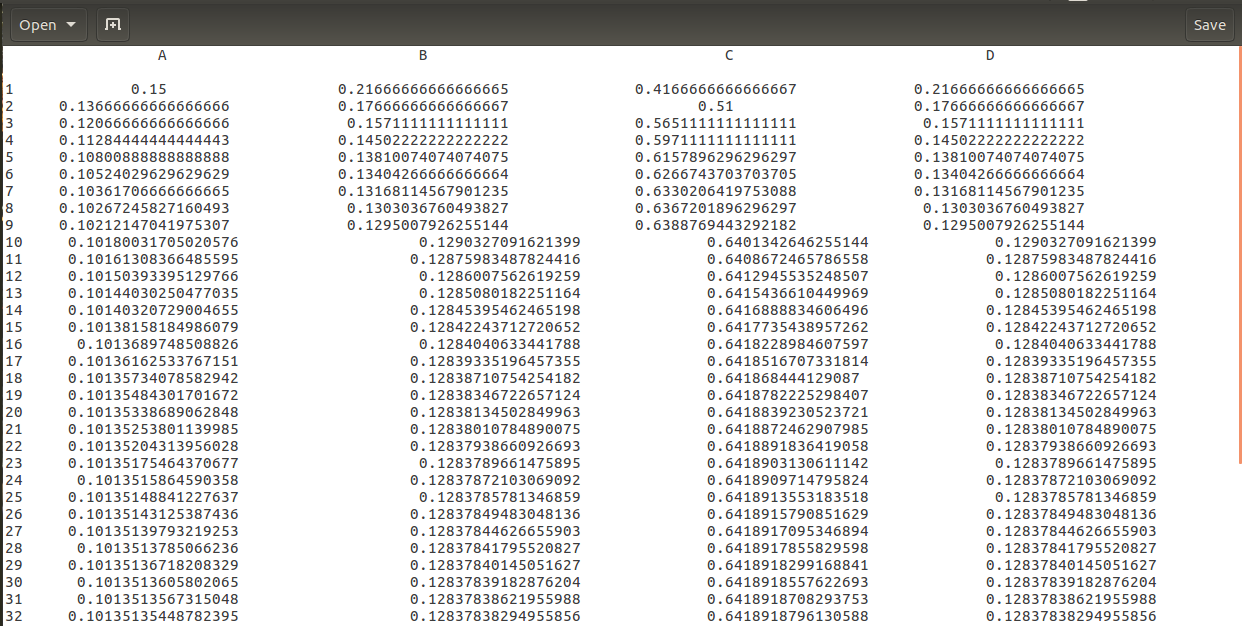
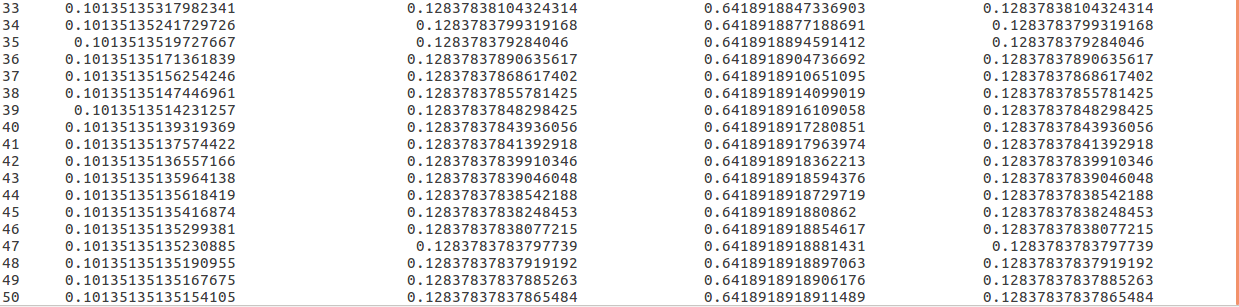
最后的运行结果为:
后记
上面实现的稀疏图的算法,后来我又实现了矩阵的算法。有兴趣的可以转至:传送门
参考:
MapReduce实现PageRank算法(稀疏图法)的更多相关文章
- MapReduce实现PageRank算法(邻接矩阵法)
前言 之前写过稀疏图的实现方法,这次写用矩阵存储数据的算法实现,只要会矩阵相乘的话,实现这个就很简单了.如果有不懂的可以先看一下下面两篇随笔. MapReduce实现PageRank算法(稀疏图法) ...
- Hadoop实战训练————MapReduce实现PageRank算法
经过一段时间的学习,对于Hadoop有了一些了解,于是决定用MapReduce实现PageRank算法,以下简称PR 先简单介绍一下PR算法(摘自百度百科:https://baike.baidu.co ...
- PageRank算法简介及Map-Reduce实现
PageRank对网页排名的算法,曾是Google发家致富的法宝.以前虽然有实验过,但理解还是不透彻,这几天又看了一下,这里总结一下PageRank算法的基本原理. 一.什么是pagerank Pag ...
- pagerank算法在数学模型中的运用(有向无环图中节点排序)
一.模型介绍 pagerank算法主要是根据网页中被链接数用来给网页进行重要性排名. 1.1模型解释 模型核心: a. 如果多个网页指向某个网页A,则网页A的排名较高. b. 如果排名高A的网页指向某 ...
- 同步图计算实现pageRank算法
pageRank算法是Google对网页重要性的打分算法. 一个用户浏览一个网页时,有85%的可能性点击网页中的超链接,有15%的可能性转向任意的网页.pageRank算法就是模拟这种行为. Rv:定 ...
- AcWing 858. Prim算法求最小生成树 稀疏图
//稀疏图 #include <cstring> #include <iostream> #include <algorithm> using namespace ...
- PageRank算法初探
1. PageRank的由来和发展历史 0x1:源自搜索引擎的需求 Google早已成为全球最成功的互联网搜索引擎,在Google出现之前,曾出现过许多通用或专业领域搜索引擎.Google最终能击败所 ...
- PageRank算法--从原理到实现
本文将介绍PageRank算法的相关内容,具体如下: 1.算法来源 2.算法原理 3.算法证明 4.PR值计算方法 4.1 幂迭代法 4.2 特征值法 4.3 代数法 5.算法实现 5.1 基于迭代法 ...
- MapReduce 模式、算法和用例
翻译自:http://highlyscalable.wordpress.com/2012/02/01/mapreduce-patterns/ 在这篇文章里总结了几种网上或者论文中常见的MapReduc ...
随机推荐
- python pandas库的基本内容
pandas主要为数据预处理 DataFrame import pandas food_info = pandas.read_csv("路径") #绝对路径和相对路径都可以 ty ...
- oracle树形结构全路径查询
很实用的语法,父子节点通过id与patientId来关联,知道子节点的id,想查出所有的父节点: START WITH ...CONNECT BY ... SELECT T2.ORG_FULLNAME ...
- package,继承,访问修饰符
1.package 包(package),用于管理程序中的类,可用于处理类的同名问题. 1.1定义package的方法 package 包名; package用于定义包,必须写在源文件有效代码的第一句 ...
- 接口自动化框架(java)--5.通过testng.xml生成extentreport测试报告
这套框架的报告是自己封装的 由于之前已经通过Extentreport插件实现了Testng的IReport接口,所以在testng.xml中使用listener标签并指向实现IReport接口的那个类 ...
- vue+element-ui实现表格checkbox单选
公司平台利用vue+elementui搭建前端页面,因为本人第一次使用vue也遇到了不少坑,因为我要实现的效果如下图所示 实现这种单选框,只能选择一个,但element-ui展示的是多选框,check ...
- 对于Java Bean的类型转换问题()使用 org.apache.commons.beanutils.ConvertUtils)
在进行与数据库的交互过程中,由数据库查询到的数据放在 map 中,由 map 到 JavaBean 的过程中可以使用 BeanUtils.populate(map,bean)来进行转换 这里要处理的问 ...
- python学习笔记之线程、进程和协程(第八天)
参考文档: 金角大王博客:http://www.cnblogs.com/alex3714/articles/5230609.html 银角大王博客:http://www.cnblogs.com/wup ...
- 用Nuget部署程序包
用Nuget部署程序包 Nuget是.NET程序包管理工具(类似linux下的npm等),程序员可直接用简单的命令行(或VS)下载包.好处: (1)避免类库版本不一致带来的问题.GitHub是管理源代 ...
- 向 Nginx 主进程发送 USR1 信号
[1]Nginx重新打开日志文件 向 Nginx 主进程发送 USR1 信号.USR1 信号是重新打开日志文件: 方式一: kill -USR1 $(cat /usr/local/lib/ubcsrv ...
- 利用python把成绩用雷达图表示出来
第一步:知道自己的成绩. 第二步:插入代码. import numpy as np import matplotlib.pyplot as plt import matplotlib matplotl ...