Hadoop3.2.0集群(4节点-无HA)
1.准备环境
1.1配置dns
# cat /etc/hosts
172.27.133.60 hadoop-01
172.27.133.61 hadoop-02
172.27.133.62 hadoop-03
172.27.133.63 hadoop-04
1.2配置免密登陆
# ssh-keygen
# ssh-copy-id root@hadoop-02/03/04
1.3关闭防火墙
# cat /etc/selinux/config
SELINUX=disabled
# systemctl stop firewalld
# systemctl disable firewalld
1.4配置Java环境,Hadoop环境
# tar -xf /data/software/jdk-8u171-linux-x64.tar.gz -C /usr/local/java
# tar -xf /data/software/hadoop-3.2.0.tar.gz -C /data/hadoop
# cat /etc/profile
export HADOOP_HOME=/data/hadoop/hadoop-3.2.0
export JAVA_HOME=/usr/local/java/jdk1.8.0_171
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
# source /etc/profile
# java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
2.配置Hadoop
2.1配置Hadoop环境脚本文件中的JAVA_HOME参数
# cd /data/hadoop/hadoop-3.2.0/etc/hadoop
# vim hadoop-env.sh 和 mapred-env.sh 和 yarn-env.sh,向脚本添加JAVA_HOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_171
# hadoop version
Hadoop 3.2.0
Source code repository https://github.com/apache/hadoop.git -r e97acb3bd8f3befd27418996fa5d4b50bf2e17bf
Compiled by sunilg on 2019-01-08T06:08Z
Compiled with protoc 2.5.0
From source with checksum d3f0795ed0d9dc378e2c785d3668f39
This command was run using /data/hadoop/hadoop-3.2.0/share/hadoop/common/hadoop-common-3.2.0.jar
2.2修改Hadoop配置文件
在hadoop-3.2.0/etc/hadoop目录下,修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers文件,具体参数按照实际情况修改。
2.2.1修改core-site.xml
(文件系统)
<configuration>
<property>
<!-- 配置hdfs地址 -->
<name>fs.defaultFS</name>
<value>hdfs://hadoop-01:9000</value>
</property>
<property>
<!-- 保存临时文件目录,需先在/data/hadoop下创建tmp目录 -->
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
</configuration>
# mkdir /data/hadoop/tmp
2.2.2修改hdfs-site.xml
(副本数)
<configuration>
<property>
<!-- 主节点地址 -->
<name>dfs.namenode.http-address</name>
<value>hadoop-01:50070</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop-02:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/dfs/data</value>
</property>
<property>
<!-- 备份数为默认值2 -->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除.</description>
</property>
</configuration>
2.2.3修改mapred-site.xml
(资源调度框架)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-01:19888</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
2.2.4修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>172.27.133.60:8088</value>
<description>配置外网只需要替换外网ip为真实ip,否则默认为 localhost:8088</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<description>每个节点可用内存,单位MB,默认8182MB</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。</description>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
2.2.5修改workers
添加从节点地址,IP或者hostname
hadoop-02
hadoop-03
hadoop-04
2.3将配置好的文件夹拷贝到其他从节点
# scp -r /data/hadoop root@hadoop-02:/data/hadoop
# scp -r /data/hadoop root@hadoop-03:/data/hadoop
# scp -r /data/hadoop root@hadoop-04:/data/hadoop
2.4配置启动脚本Yarn权限
2.4.1添加hdfs权限
在第二行空白位置添加hdfs权限
# cat sbin/start-dfs.sh
# cat sbin/stop-dfs.sh
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
···
2.4.2添加Yarn权限
在第二行空白位置添加Yarn权限
# cat sbin/start-yarn.sh
# cat sbin/stop-yarn.sh
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=yarn
YARN_NODEMANAGER_USER=root
···
如果不添加权限,在启动时候会报错
ERROR: Attempting to launch hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch.
Starting datanodes
ERROR: Attempting to launch hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting launch.
Starting secondary namenodes [localhost.localdomain]
ERROR: Attempting to launch hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting launch.
3.初始化并启动
3.1格式化hdfs
# bin/hdfs namenode -format
3.2启动
3.2.1一步启动
# sbin/start-all.sh
3.2.2分布启动
# sbin/start-dfs.sh
# sbin/start-yarn.sh
4.验证
4.1列出进程
主节点hadoop-01
# jps
32069 SecondaryNameNode
2405 NameNode
2965 ResourceManager
3645 Jps从节点hadoop-02
# jps
25616 NodeManager
25377 DataNode
25508 SecondaryNameNode
25945 Jps从节点hadoop-03
# jps
14946 NodeManager
15207 Jps
14809 DataNode从节点hadoop-04
# jps
14433 Jps
14034 DataNode
14171 NodeManager4
4.2访问页面
http://hadoop-01:8088打开ResourceManager页面
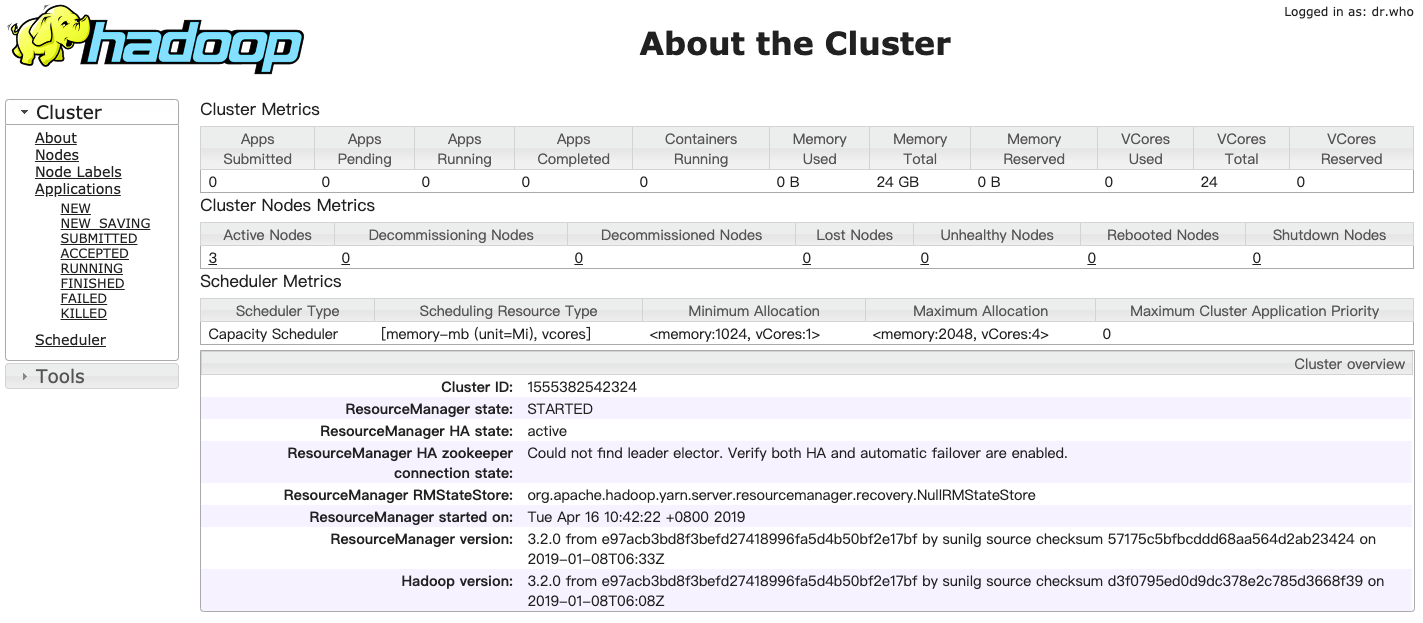
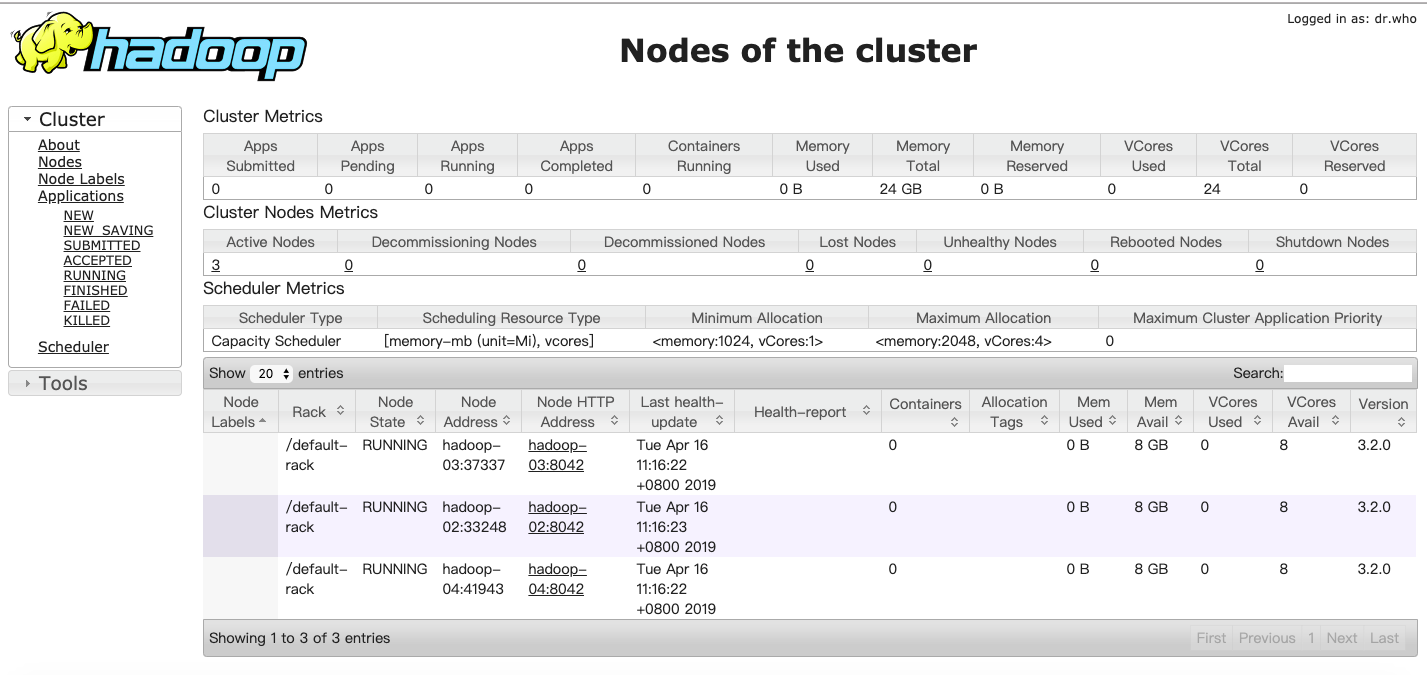
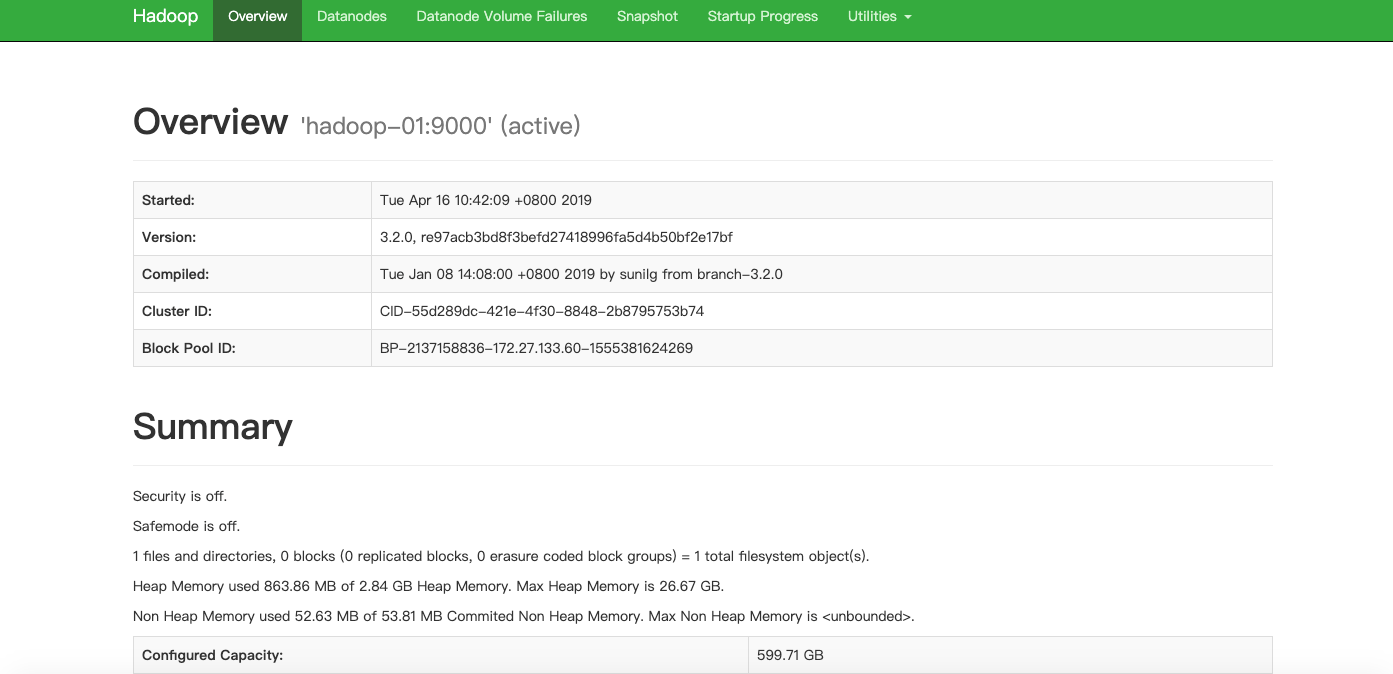
http://hadoop-01:50070打开Hadoop Namenode页面
Hadoop3.2.0集群(4节点-无HA)的更多相关文章
- 全网最新的nacos 2.1.0集群多节点部署教程
原文链接:全网最新的nacos 2.1.0集群多节点部署教程-语雀 基本信息 进度整理中 版本 2.1.0 版本发布日期 2022-04-29 git revision number b5845313 ...
- Kafka 1.0.0集群增加节点
原有环境 主机名 IP 地址 安装路径 系统 sht-sgmhadoopdn-01 172.16.101.58 /opt/kafka_2.12-1.0.0 /opt/kafka(软连接) CentOS ...
- CentOS7搭建Hadoop-3.3.0集群手记
前提 这篇文章是基于Linux系统CentOS7搭建Hadoop-3.3.0分布式集群的详细手记. 基本概念 Hadoop中的HDFS和YARN都是主从架构,主从架构会有一主多从和多主多从两种架构,这 ...
- hadoop3.2.0集群搭建的一些坑!
搭建步骤就不多说了,网上教程很多,这里列举几个: https://blog.csdn.net/pucao_cug/article/details/71698903 2.8版本 https://ww ...
- hadoop 2.2.0集群安装详细步骤(简单配置,无HA)
安装环境操作系统:CentOS 6.5 i586(32位)java环境:JDK 1.7.0.51hadoop版本:社区版本2.2.0,hadoop-2.2.0.tar.gz 安装准备设置集群的host ...
- CentOS完美搭建Redis3.0集群并附测试
线上的统一聊天和推送项目使用的是redis主从,redis版本2.8.6 redis主从和mysql主从目的差不多,但redis主从配置很简单,主要在从节点配置文件指定主节点ip和端口:slaveof ...
- 二进制方式部署Kubernetes 1.6.0集群(开启TLS)
本节内容: Kubernetes简介 环境信息 创建TLS加密通信的证书和密钥 下载和配置 kubectl(kubecontrol) 命令行工具 创建 kubeconfig 文件 创建高可用 etcd ...
- hadoop-2.6.0集群开发环境配置
hadoop-2.6.0集群开发环境配置 一.环境说明 1.1安装环境说明 本例中,操作系统为CentOS 6.6, JDK版本号为JDK 1.7,Hadoop版本号为Apache Hadoop 2. ...
- Kubernetes-保障集群内节点和网络安全
13.1.在pod中使用宿主节点的Linux命名空间 13.1.1.在pod中使用宿主节点的网络命名空间 在pod的yaml文件中就设置spec.hostNetwork: true 这个时候pod使用 ...
随机推荐
- [Day23]IO(字节流、字符流)
1.字节流 1.1 字节输出流OutputStream-抽象类,表示输出字节流的所有类的超类 (1)void close() 关闭此输出流并释放与此流相关的所有系统资源 (2)void flush() ...
- k8s-No.3-pod进阶
本章目录 pod环境变量env pod的资源限制resources pod的健康检查-探针 pod的imagepullsecrets 一 pod-env 环境变量就是系统或者程序运行时的预定义的参 ...
- RemoveError: 'requests' is a dependency of conda and cannot be removed from conda's operating environment
(base)$ conda update conda conda remove -n *** --all 或者 (base)$ conda update --force conda conda rem ...
- linux alias 命令 查看系统设置的命令别名
alias命令用于查看或设置命令别名,但仅作用于该次登陆的会话,若要永久使用别名,可在 ~/.bashrc 中设定别名 [root@MongoDB ~]# alias // 查看别名 [root@Mo ...
- Java面试题和解答(三)
1.这段代码大多数情况下运行正常,但是某些情况下会出问题.什么时候会出现什么问题?如何修正? public class MyStack { private List<String> lis ...
- Oracle中exp导出与imp导入的参数(full,owner/formuser/touser)测试
1.exp导出的参数(FULL,OWNER)测试 先知道的一点是full不能与owner共存,还有都是以用户的方式导出(在这里),其中不仅仅包括表,这可能就是下面报warnings的原因,因为Orac ...
- 出现error: command 'x86_64-linux-gnu-gcc' failed with exit status 1
查看自己python的版本,然后下载自己版本Python的devel,比如python3.6.8就是 sudo apt-get install python3.6-dev
- UML作业第一次:UML用例图绘制
UML第一次作业 一. 用例图:用例图(usecase diagram)是UML用于描述软件功能的图形.用例图包括用例.参与者及其关系,用例图也可以包括注释和约束.程序员要画时序图啥的用其他的比较麻烦 ...
- 【转】福利大放送--不止是Android,Github超高影响力开源大放送,学习开发必备教科书
[福利大放送]不止是Android,Github超高影响力开源大放送,学习开发必备教科书 目录 一.写在前面 1.free-programming-books 2.oh-my-zsh 3.awes ...
- 《ASP.NET Core In Action》读书笔记系列四 创建ASP.NET Core 应用步骤及相应CLI命令
一般情况下,我们都是从一个模板(template)开始创建应用的(模板:提供构建应用程序所需的基本代码).本节使用 Visual Studio 2017 .ASP.NET Core2.0和 Visua ...