CUDA[1] Introductory
Section 0 :Induction of CUDA
CUDA是啥?CUDA®: A General-Purpose Parallel Computing Platform and Programming Model
为什么用显卡就可以实现比CPU高得多的运算性能呢?这要从GPU的结构讲起:
GPU天生是为了图像处理而设计的,讲道理的话它能处理一些简单的运算工作(比如单独的顶点和线段)。但是在一个GPU中包含了许多个流处理器(Stream Processor),这些流处理器都可以并行工作。In this sense, GPUs are stream processors – processors that can operate in parallel by running one kernel on many records in a stream at once. [Reference]
对于CPU来说,12核已经是上天了的配置。然而今天,随意一个亮机卡GPU都有96个CUDA计算单元(每个相当于一个计算核心)。其并行计算能力不可同日而语。
Section 1 :Thread Hierarchy
在CUDA的计算模型中,有如下几个concept:
1.thread
这里的线程和CPU中其实是一个意思。是执行运算的最小单位。
在执行时,每个线程都有一个自己独特的标识符 threadIdx。threadIdx可以是一维/二维/三维的。(threadIdx.x,threadIdx.y,threadIdx.z)
2.block (thread block)
一个线程块包含了多个线程
3.Streaming Multiprocessor
每个SM相当于一个计算单元,里面又包含很多个Streaming Processor。每个SM可并行运行一个block里的线程。
4.Kernel
kernel可以理解成一个函数。同一个kernel函数可以在多个线程中被执行。
比如下面的向量加法的程序:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<, N>>>(A, B, C);
...
}
line 2:用__global__关键字定义了一个kernel函数
line 4:threadIdx表示当前执行该kernel函数的这个thread的一个标号(可以理解为this指针的用途)
line 11:在调用kernel函数时,需要分配<<number_of_blocks , threads_per_block>> 。上述程序中分配了一个block,每个block中N个thread
虽然多个线程调用的都是同一个kernel function,但是它们分别在不同的数据空间进行加法运算(注意A、B、C的数组下标)。因此将一个大向量的加法运算给分解开了。
5.Grid
不同种类的kernel,每种kernel可以调度若干个block。这些block逻辑上被判为一个Grid。
thread、block和Streaming Multiprocessors的关系如下:
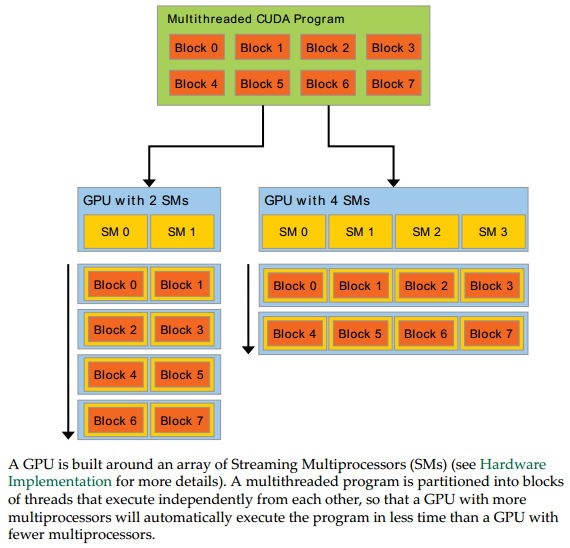
[Source: CUDA C Programming Guide.pdf]
如图,每个SM可以处理一个block,从而实现了并行计算。
两个层次的并行: • grid内多个block的并行 • block内多个thread的并行
注意:block和thread都是逻辑上的概念,物理上只存在SM。并不是一个SM一定严格对应一个block
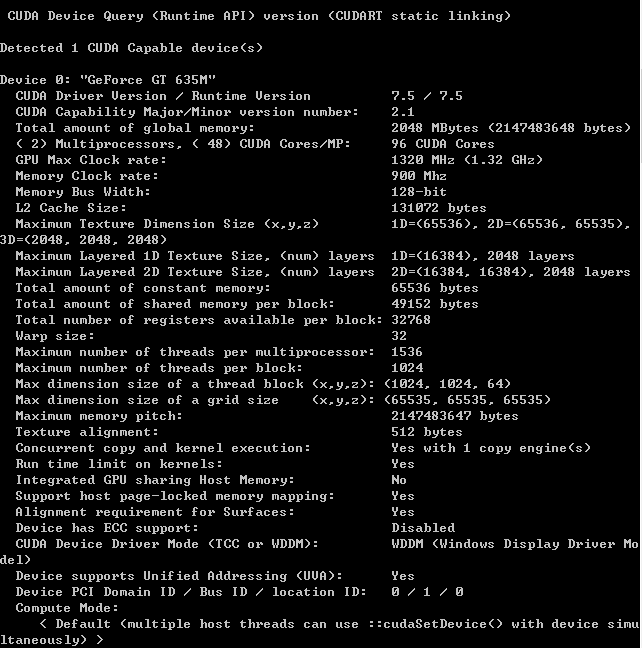
比如对于我的亮机卡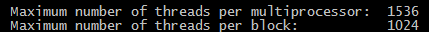
每个SM可以跑1536个线程,而每个block最多1024个
但是实际上因为寄存器大小不一定够,并不一定能全部跑满这些线程。如果强行跑,就可能会爆掉
Section 2:Memory Hierarchy
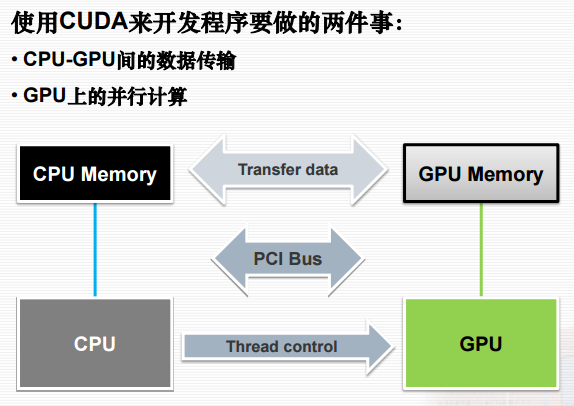
[注意这里说的Memory都是指显存。CPU无法直接访问显存中的数据。][Reference]
因此,一个CUDA程序必然少不了以下三步:
☻cudaMalloc:创建新的动态显存堆
☻cudaMemcpy:将主机(Host)内存复制到设备(Device)显存
☻显存处理完之后,cudaMemcpy:设备(Device)显存复制回主机(Host)内存,释放显存cudaFree
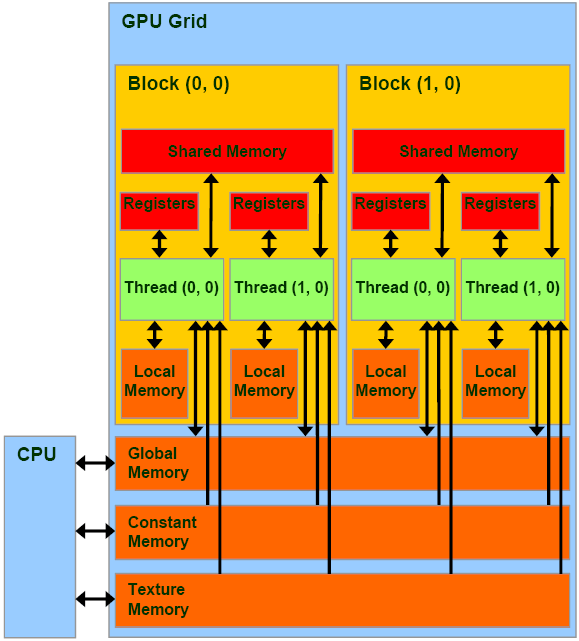
CPU/RAM与GPU/VRAM的关系如图:[Reference]
Gird、block、thread的内存访问/共享机制如下图:
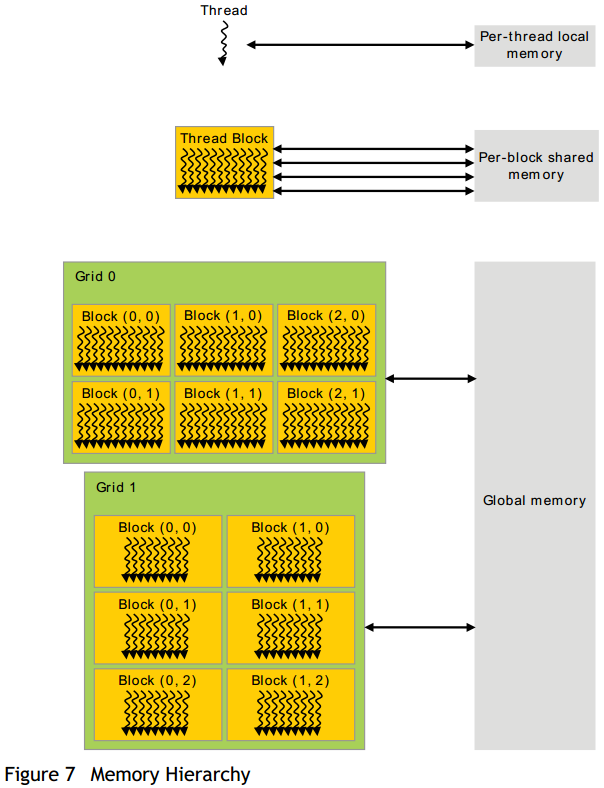
这里有几个概念:
Local Memory:单个线程内使用的内存空间
Shared Memory:一个block内所有线程共享的内存空间,常用于线程之间的通信。
每个SM(StreamingMultiprocessor)大约有16KB的shared memory
Global Memory:所有的block共享的内存空间。比shared速度慢,但是大许多
Constant Memory:存储常量。一块显卡大约有64KB的constant memory
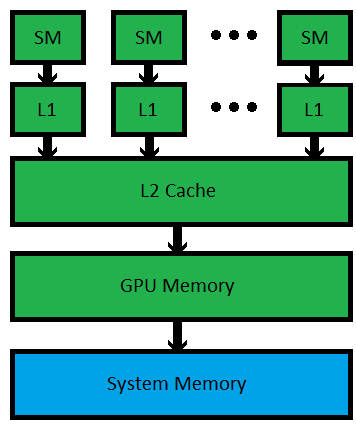
从硬件的角度来看结构是这样的:[Reference] [Reference]
CUDA[1] Introductory的更多相关文章
- CUDA[2] Hello,World
Section 0:Hello,World 这次我们亲自尝试一下如何用粗(CU)大(DA)写程序 CUDA最新版本是7.5,然而即使是最新版本也不兼容VS2015 ...推荐使用VS2012 进入VS ...
- Couldn't open CUDA library cublas64_80.dll etc. tensorflow-gpu on windows
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_load ...
- ubuntu 16.04 + N驱动安装 +CUDA+Qt5 + opencv
Nvidia driver installation(after download XX.run installation file) 1. ctrl+Alt+F1 //go to virtual ...
- 手把手教你搭建深度学习平台——避坑安装theano+CUDA
python有多混乱我就不多说了.这个混论不仅是指整个python市场混乱,更混乱的还有python的各种附加依赖包.为了一劳永逸解决python的各种依赖包对深度学习造成的影响,本文中采用pytho ...
- [CUDA] CUDA to DL
又是一枚祖国的骚年,阅览做做笔记:http://www.cnblogs.com/neopenx/p/4643705.html 这里只是一些基础知识.帮助理解DL tool的实现. “这也是深度学习带来 ...
- 基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记
基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记 飞翔的蜘蛛人 注1:本人新手,文章中不准确的地方,欢迎批评指正 注2:知识储备应达到Linux入门级水平 ...
- CUDA程序设计(一)
为什么需要GPU 几年前我启动并主导了一个项目,当时还在谷歌,这个项目叫谷歌大脑.该项目利用谷歌的计算基础设施来构建神经网络. 规模大概比之前的神经网络扩大了一百倍,我们的方法是用约一千台电脑.这确实 ...
- 使用 CUDA范例精解通用GPU编程 配套程序的方法
用vs新建一个cuda的项目,然后将系统自动生成的那个.cu里头的内容,除了头文件引用外,全部替代成先有代码的内容. 然后程序就能跑了. 因为新建的是cuda的项目,所以所有的头文件和库的引用系统都会 ...
- CUDA代码移植
如果CUDA的代码移植,一个是要 include文件夹对不对,这个是.h文件能否找到的关键,另一个就是lib,这个是.lib文件能否找到的关键.具体检查地方,见下头. include: lib:
随机推荐
- java 正则匹配括号对以及其他成对出现的模式
最近,我们有个大调整,为了控制代码的质量,需要使用一些伪代码让业务人员编写应用逻辑(其实这么做完全是处于研发效能的考虑,95%以上的代码不需要特别注意都不会导致系统性风险,),然后通过工具自动生成实际 ...
- 通过安装一个描述文件在控制台获得设备的udid
在我的这篇博客里面说明了本地获得设备udid的方法,但是只能在模拟器中获得http://www.cnblogs.com/liyy2015/p/6090204.html 当然可以在设备上集成苹果的MDM ...
- ReactNative中iOS和Android的style分开设置教程
reactnative可以编辑iOS程序也可以编辑Android程序, 而且80%的代码都可以重用. 及有些文件是两个系统通用的, 相信大家也都清楚了. 但是也许大家会遇到一些屏幕布局的问题, 最常遇 ...
- emmet 系列(1)基础语法
emmet 系列(1)基础语法 emmet 是一个能显著提升开发html和css开发效率的web开发者工具 emmet基本上目前已知的编辑器都有相应的插件,各个编辑器的emmet插件的下载地址:点我下 ...
- 处理程序“ExtensionlessUrlHandler-Integrated-4.0”在其模块列表中有一个错误模块“ManagedPipelineHandler”
新服务器安装完开发环境后,还需要注册framework4.0到IIS.不然会报错: HTTP 错误 500.21 - Internal Server Error 处理程序“Extensionles ...
- 基于InstallShield2013LimitedEdition的安装包制作
在VS2012之前,我们做安装包一般都是使用VS自带的安装包制作工具来创建安装包的,VS2012.VS2013以后,微软把这个去掉,集成使用了InstallShield进行安装包的制作了,虽然思路差不 ...
- Linux常见查看硬件信息指令
CPUlscpu 查看的是CPU的统计信息./proc/cpuinfo 查看每个cpu信息,如每个CPU的型号,主频等. 内存free -m 概要查看内存情况cat /proc/meminfo 查看内 ...
- PHP语法(三):控制结构(For循环/If/Switch/While)
相关链接: PHP语法(一):基础和变量 PHP语法(二):数据类型.运算符和函数 PHP语法(三):控制结构(For循环/If/Switch/While) 本文我来总结几个PHP常用的控制结构,先来 ...
- hadoop常用的操作命令
1.显示hdfs上test目录下的所有文件列表 hadoop fs -ls /test/ 2.查看hdfs中的文件内容 hadoop fs -cat /daas/bstl/term/rawdt/201 ...
- 如何在github上下载单个文件夹?
作者:ce ge链接:https://www.zhihu.com/question/25369412/answer/96174755来源:知乎著作权归作者所有,转载请联系作者获得授权. Git1.7. ...