主成分分析 —PCA
一.定义
主成分分析(principal components analysis)是一种无监督的降维算法,一般在应用其他算法前使用,广泛应用于数据预处理中。其在保证损失少量信息的前提下,把多个指标转化为几个综合指标的多元统计方法。这样可达到简化数据结构,提高分信息效率的目的。
通常,把转化生成的综合指标称为主成分,其中每个成分都是原始变量的线性组合,且每个主成分之间互不相关,使得主成分比原始变量具有某些更优越的性能。
一般,经主成分分析分析得到的主成分与原始变量之间的关系有:
- (1)每个主成分都是各原始变量的线性组合
- (2)主成分的数目大大骚鱼原始变量的数目
- (3)主成分保留了原始变量的绝大多数信息
- (4)各主成分之间互不相关
二.过程
其过程是对坐标系旋转的过程,各主成分表达式就是新坐标系与原坐标系的转换关系,在新坐标系中,各坐标轴的方向就是原始数据变差最大的方向。(参见《多元统计分析》P114-117,新坐标轴Y1和Y2,用X1和X2的线性组合表示,几何上是将坐标轴按逆时针方向旋转一定的角度而得出)
详细版:数据从原来的坐标系转换到新的坐标系。转换坐标系时,以方差最大的方向作为新坐标轴方向(数据的最大方差给出了数据的最重要的信息)。第一个新坐标轴选择的是原始数据中方差最大的方法,第二个新坐标轴选择的是与第一个新坐标轴正交且方差次大的方向。重复以上过程,重复次数为原始数据的特征维数。
在重复中,我们不断地得到新的坐标系。Generally,方差集中于前面几个综合变量中,且综合变量在总方差中所占的比重依次递减,而后面新的坐标轴所包含的方差越来越小,甚至接近0。实际应用中,一般只要挑选前几个方差较大的主成分即可。
那么,我们如何得到这些包含最大差异性的主成分方向呢?事实上,通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值及特征向量,选择特征值最大(也即包含方差最大)的N个特征所对应的特征向量组成的矩阵,我们就可以将数据矩阵转换到新的空间当中,实现数据特征的降维(N维)。
由于得到协方差矩阵的特征值特征向量有两种方法:特征值分解协方差矩阵、奇异值分解协方差矩阵,所以PCA算法有两种实现方法:基于特征值分解协方差矩阵实现PCA算法、基于SVD分解协方差矩阵实现PCA算法。(特征值分解最大的问题是只能针对方阵,即n*n的矩阵。而在实际的应用中,我们分解的大部分都不是方阵,所以产生了SVD。)
三.Python实现
1.sklearn.decomposition.PCA
sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False, svd_solver=’auto’, tol=0.0, iterated_power=’auto’, random_state=None)
它利用SVD分解协方差矩阵实现PCA算法,实现降维效果。
注意:此类不适用于稀疏数据。
参数:
(1)n_components : 整型, 浮点型, None or 字符串类型。设置最后保留下来的主成分个数。
如果不设置该参数,则保留所有主成分。
赋值为string,如n_components='mle',将自动选取特征个数n,使得满足所要求的方差百分比。
(2)copy : 布尔值 (默认值 True)。表示在运算时,是否将原始数据复制一遍。
True:运算后,原始数据不会变化,因为运算是在原始数据的副本上进行的。
False:算法运算将在原始数据上运行,原始数据最终发生变化。
(3)whiten : 布尔值(默认 False)
True:对降维后的主成分进行归一化,使所有主成分的方差为1。
一般不白化,使用默认的False即可。
(4)svd_solver :指定奇异值分解SVD的方法。字符串,{auto、 full、arpack、 randomized}
auto :默认值。该类会自行选择以下三种中最佳的一种来实现算法。一般使用默认值即可。
full :传统意义的SVD,使用了scipy库的对应实现法。
arpack :用于数据量较大、维度较多,最后主成分较少的情况。
randomized :一般用于数据量大,数据维度多,且主成分较少的情况。
(5)random_state :设置复现的参数。
2.属性:
(1)components_ :返回降维后各主成分方向,并按照各主成分的方差值大小排序。
(2)explained_variance_ :降维后各主成分的方差值
(3)explained_variance_ratio_ :返回各个成分的方差百分比(贡献率)
(4)n_components_ :返回所保留的成分个数n。
3.例1:iris数据集
import numpy as np
import pandas as pd
from sklearn import datasets
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.decomposition import PCA #主成分分析用
from mpl_toolkits.mplot3d import Axes3D #画三维图
# 导入鸢尾花数据
iris = datasets.load_iris()
x, y = iris.data, iris.target
print("x:", x.shape)
print("y:", y.shape)
print("原始变量名:", iris.feature_names)
print("标签分类:",iris.target_names)
x: (150, 4)
y: (150,)
原始变量名: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
标签分类: ['setosa' 'versicolor' 'virginica']
有150个样本,每个样本有四个特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度,根据上诉四个特征,将150个样本分成三类。
pca0 = PCA(n_components=4)
pca0.fit(x).transform(x)
print("四个主成分方向:\n", pca.components_)
四个主成分方向:
[[ 0.36158968 -0.08226889 0.85657211 0.35884393]
[ 0.65653988 0.72971237 -0.1757674 -0.07470647]
[-0.58099728 0.59641809 0.07252408 0.54906091]
[ 0.31725455 -0.32409435 -0.47971899 0.75112056]]
假设原始变量为x1、x2、x3、x4, Y1为新的第一个主成分,则可认为Y1 = 0.36158968x1 - 0.08226889x2 + 0.85657211x3 + 0.35884393x4,以此类推,可写出Y2、Y3、Y4。
print("各主成分的方差值:\n",pca.explained_variance_)
print("各主成分的方差值占比:\n",pca.explained_variance_ratio_)
各主成分的方差值:
[ 4.22484077 0.24224357 0.07852391 0.02368303]
各主成分的方差值占比:
[ 0.92461621 0.05301557 0.01718514 0.00518309]
第一个主成分占方差百分比的92.5%,第二个主成分占百分比的5.3%,第三个主成分占百分比的0.2%,前面三个主成分已包含原始变量中99%的信息,现在剔除最后一个主成分,仅保留前三个主成分。
pca1 = PCA(n_components=3)
pca1.fit(x)
x1_new = pca1.transform(x)
print("前三个主成分方向:\n",pca1.components_)
print("各主成分的方差值:\n",pca1.explained_variance_)
print("各主成分的方差值占比:\n",pca1.explained_variance_ratio_)
前三个主成分方向:
[[ 0.36158968 -0.08226889 0.85657211 0.35884393]
[ 0.65653988 0.72971237 -0.1757674 -0.07470647]
[-0.58099728 0.59641809 0.07252408 0.54906091]]
各主成分的方差值:
[ 4.22484077 0.24224357 0.07852391]
各主成分的方差值占比:
[ 0.92461621 0.05301557 0.01718514]
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(x1_new[:,0],x1_new[:,1],x1_new[:,2],c=y)
<mpl_toolkits.mplot3d.art3d.Path3DCollection at 0xe352bb35c0>

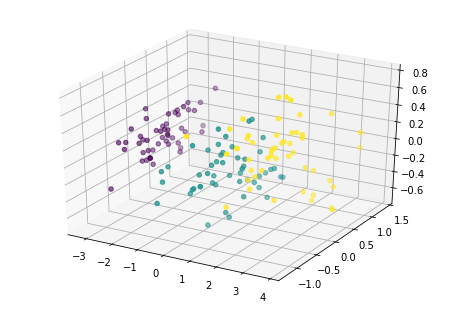
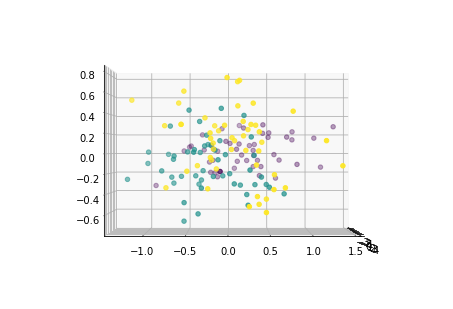
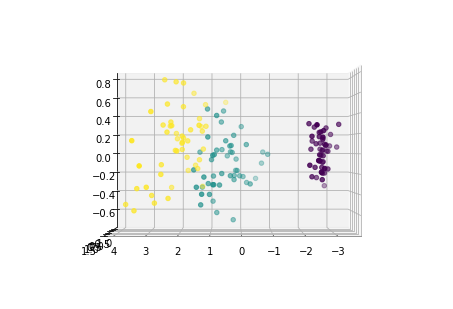
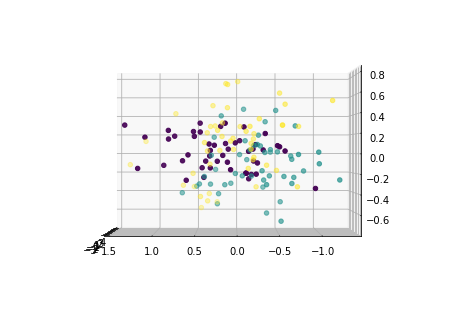
下面从多个角度来看各主成分的分布情况:
for i in [0,90,180,270]:
fig = plt.figure()
ax = Axes3D(fig,elev=0, azim=i)
ax.scatter(x1_new[:,0],x1_new[:,1],x1_new[:,2],c=y)




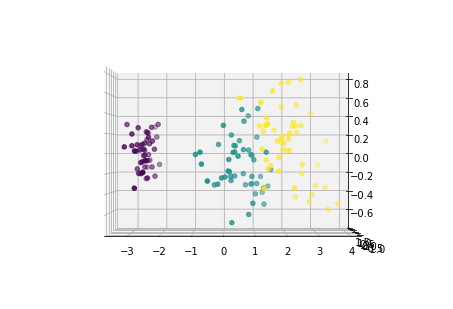
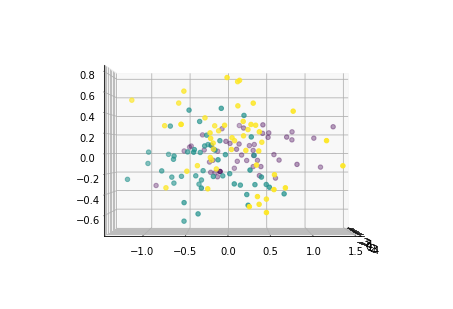
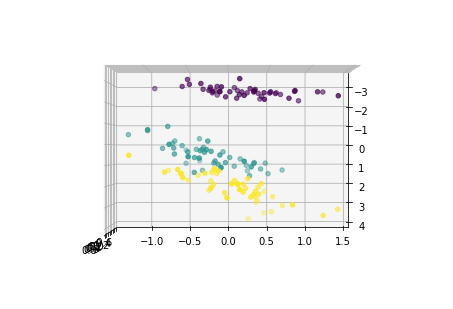
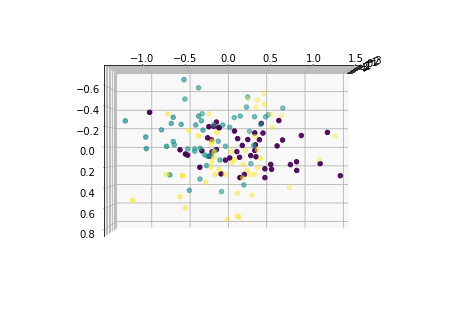
for i in [0,90,180,270]:
fig = plt.figure()
ax = Axes3D(fig,elev=i, azim=0)
ax.scatter(x1_new[:,0],x1_new[:,1],x1_new[:,2],c=y)




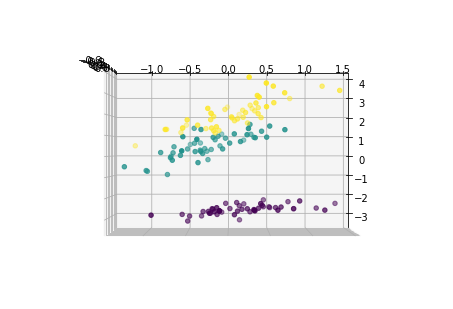
pca2 = PCA(n_components=2)
pca2.fit(x)
x2_new = pca2.transform(x)
print("2个主成分方向:\n", pca2.components_)
print("2个主成分的解释方差值:\n", pca2.explained_variance_)
print("2个主成分解释方差占比:\n", pca2.explained_variance_ratio_)
plt.scatter(x2_new[:,0],x2_new[:,1],c=y)
2个主成分方向:
[[ 0.36158968 -0.08226889 0.85657211 0.35884393]
[ 0.65653988 0.72971237 -0.1757674 -0.07470647]]
2个主成分的解释方差值:
[ 4.22484077 0.24224357]
2个主成分解释方差占比:
[ 0.92461621 0.05301557]
<matplotlib.collections.PathCollection at 0xe353a2af98>


四.PCA的缺点
1.各个主成分的含义具有模糊性,不具有原始变量的清晰含义。
2.方差小的主成分可能含有对样本差异的重要信息,那么降维后可能影响后续的数据分析。
主成分分析 —PCA的更多相关文章
- 深度学习入门教程UFLDL学习实验笔记三:主成分分析PCA与白化whitening
主成分分析与白化是在做深度学习训练时最常见的两种预处理的方法,主成分分析是一种我们用的很多的降维的一种手段,通过PCA降维,我们能够有效的降低数据的维度,加快运算速度.而白化就是为了使得每个特征能有同 ...
- 线性判别分析(LDA), 主成分分析(PCA)及其推导【转】
前言: 如果学习分类算法,最好从线性的入手,线性分类器最简单的就是LDA,它可以看做是简化版的SVM,如果想理解SVM这种分类器,那理解LDA就是很有必要的了. 谈到LDA,就不得不谈谈PCA,PCA ...
- 降维(一)----说说主成分分析(PCA)的源头
降维(一)----说说主成分分析(PCA)的源头 降维系列: 降维(一)----说说主成分分析(PCA)的源头 降维(二)----Laplacian Eigenmaps --------------- ...
- 主成分分析PCA(转载)
主成分分析PCA 降维的必要性 1.多重共线性--预测变量之间相互关联.多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯. 2.高维空间本身具有稀疏性.一维正态分布有68%的值落于正负标准差之 ...
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
- 一步步教你轻松学主成分分析PCA降维算法
一步步教你轻松学主成分分析PCA降维算法 (白宁超 2018年10月22日10:14:18) 摘要:主成分分析(英语:Principal components analysis,PCA)是一种分析.简 ...
- 机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩 第二种类型的 无监督学习问题,称为 降维.有几个不同的的原因使你可能想要做降维.一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快 ...
- 主成分分析(PCA)原理及推导
原文:http://blog.csdn.net/zhongkejingwang/article/details/42264479 什么是PCA? 在数据挖掘或者图像处理等领域经常会用到主成分分析,这样 ...
- K-L变换和 主成分分析PCA
一.K-L变换 说PCA的话,必须先介绍一下K-L变换了. K-L变换是Karhunen-Loeve变换的简称,是一种特殊的正交变换.它是建立在统计特性基础上的一种变换,有的文献也称其为霍特林(Hot ...
- 05-03 主成分分析(PCA)
目录 主成分分析(PCA) 一.维数灾难和降维 二.主成分分析学习目标 三.主成分分析详解 3.1 主成分分析两个条件 3.2 基于最近重构性推导PCA 3.2.1 主成分分析目标函数 3.2.2 主 ...
随机推荐
- 开发函数计算的正确姿势 —— 使用 Fun Local 本地运行与调试
前言 首先介绍下在本文出现的几个比较重要的概念: 函数计算(Function Compute): 函数计算是一个事件驱动的服务,通过函数计算,用户无需管理服务器等运行情况,只需编写代码并上传.函数计算 ...
- DNS生产系统架构
主机名控制者: DNS 服务器地址:http://vbird.dic.ksu.edu.tw/linux_server/0350dns_1.php 安装博客:http://www.linuxidc.co ...
- Servlet+Tomcat总结
Tomcat的缺省端口是多少,怎么修改 1.找到Tomcat目录下的conf文件夹 2.进入conf文件夹里面找到server.xml文件 3.打开server.xml文件 4.在server.xml ...
- spring原理案例-基本项目搭建 01 spring framework 下载 官网下载spring jar包
下载spring http://spring.io/ 最重要是在特征下面的这段话,需要注意: All avaible features and modules are described in the ...
- SSH学习
简介 SSH或Secure Shell是一种远程管理协议,允许用户通过Internet控制和修改远程服务器.该服务是作为未加密Telnet的安全替代品创建的,它使用加密技术确保与远程服务器之间的所有通 ...
- 一统江湖的大前端(4)shell.js——穿上马甲我照样认识你
<一统江湖的大前端>系列是自己的前端学习笔记,旨在介绍javascript在非网页开发领域的应用案例和发现各类好玩的js库,不定期更新.如果你对前端的理解还是写写页面绑绑事件,那你真的是有 ...
- 第37章 资源所有者密码验证(Resource Owner Password Validation) - Identity Server 4 中文文档(v1.0.0)
如果要使用OAuth 2.0资源所有者密码凭据授权(aka password),则需要实现并注册IResourceOwnerPasswordValidator接口: public interface ...
- C# 如何获取Url的host以及是否是http
参考资料:https://sites.google.com/site/netcorenote/asp-net-core/get-scheme-url-host Example there's an g ...
- 简述ADO.NET(一)
ADO.NET 宏观定义 传统ADO主要针对紧密连接的客户端/服务器端系统,而 ADO.NET考虑到了断开连接式应用并且引进了 Dateset 它代表任意数量的关联表,其中每个表都包含了行和列的集合的 ...
- 多线程(3)ThreadPool
使用Thread类已经可以创建并启动线程了,但是随着开启的线程越来越多,线程的创建和终止都需要手动操作,非常繁琐,另一个问题是,开启更多新的线程但是没有用的线程没有及时得到终止的时候,会占用越来越多的 ...