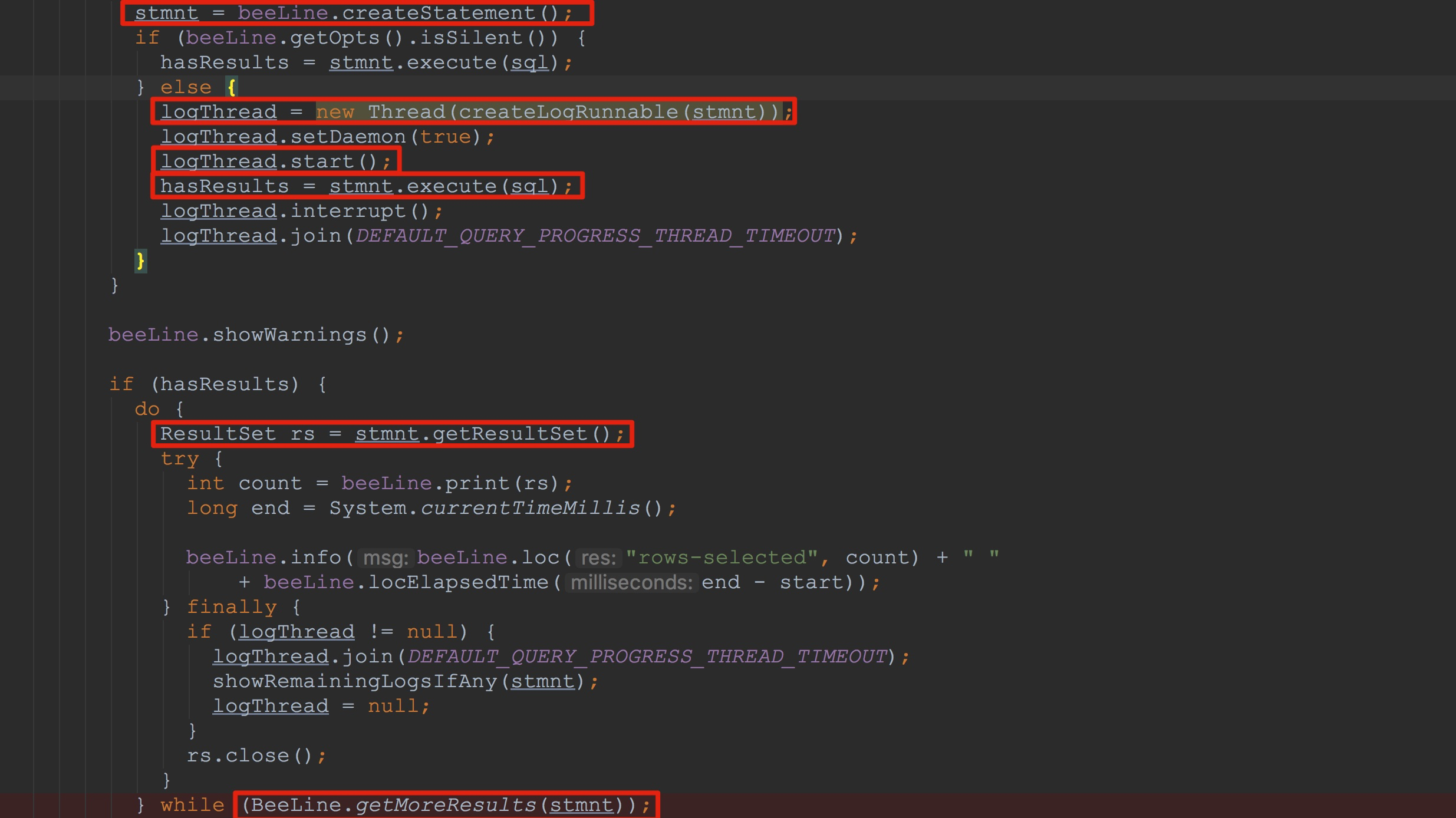
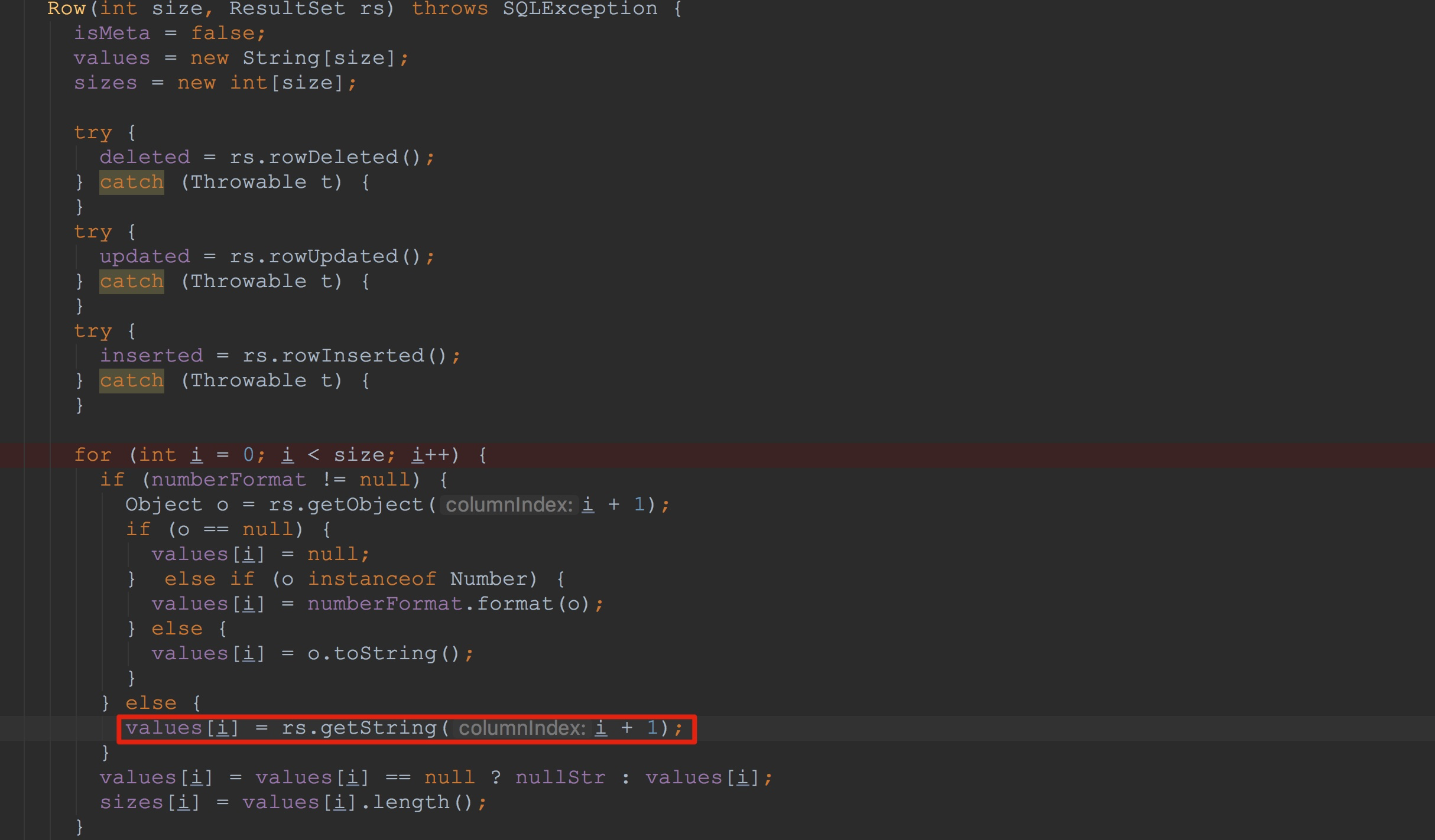
hive中beeline取回数据的完整流程

hive中beeline取回数据的完整流程的更多相关文章
- Hive中的HiveServer2、Beeline及数据的压缩和存储
1.使用HiveServer2及Beeline HiveServer2的作用:将hive变成一种server服务对外开放,多个客户端可以连接. 启动namenode.datanode.resource ...
- hive中grouping sets的使用
hive中grouping sets 数量较多时如何处理? 可以使用如下设置来 set hive.new.job.grouping.set.cardinality = 30; 这条设置的意义在于 ...
- CSS从大图中抠取小图完整教程(background-position应用)
CSS从大图中抠取小图完整教程(background-position应用) 转自: http://www.cnblogs.com/iyangyuan/archive/2013/06/01/3111 ...
- SQL Server中CURD语句的锁流程分析
我只在数据库选项已开启“行版本控制的已提交读”(READ_COMMITTED_SNAPSHOT为ON)中进行了观察. 因此只适用于这种环境的数据库. 该类数据库支持四种不同事务隔离级别,下面分别观察数 ...
- Hive中Join的原理和机制
转自:http://lxw1234.com/archives/2015/06/313.htm 笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Joi ...
- Grunt搭建自动化web前端开发环境--完整流程
Grunt搭建自动化web前端开发环境-完整流程 jQuery在使用grunt,bootstrap在使用grunt,百度UEditor在使用grunt,你没有理由不学.不用! 1. 前言 各位web前 ...
- 关于sparksql操作hive,读取本地csv文件并以parquet的形式装入hive中
说明:spark版本:2.2.0 hive版本:1.2.1 需求: 有本地csv格式的一个文件,格式为${当天日期}visit.txt,例如20180707visit.txt,现在需要将其通过spar ...
- hive中数据存储格式对比:textfile,parquent,orc,thrift,avro,protubuf
这篇文章我会从业务中关注的: 1. 存储大小 2.查询效率 3.是否支持表结构变更既数据版本变迁 5.能否避免分隔符问题 6.优势和劣势总结 几方面完整的介绍下hive中数据以下几种数据格式:text ...
- Hive中自定义Map/Reduce示例 In Java
Hive支持自定义map与reduce script.接下来我用一个简单的wordcount例子加以说明. 如果自己使用Java开发,需要处理System.in,System,out以及key/val ...
随机推荐
- RxJS操作符(三)
一.过滤类操作符:debounce, debounceTime 跟时间相关的过滤 debounceTime自动完成:性能,避免每次请求都往出发 ); debounce中间传入Observable co ...
- About The Order of The Declarations And Definition When Making a Member Function a Friend.关于使类成员成为另一个类友元函数的声明顺序和定义。
If only member function clear of WindowMgr is a friend of Screen, there are some points need to note ...
- hadoop部署
[root@xiong ~]# hostnamectl set-hostname hadoop001 [root@xiong ~]# vim /etc/hostnamehadoop001 vim /e ...
- C# Aspose.Cells 如何设置单元格样式
//Instantiating a Workbook object Workbook workbook = new Workbook(); //Adding a new worksheet to th ...
- C - Thief in a Shop - dp完全背包-FFT生成函数
C - Thief in a Shop 思路 :严格的控制好k的这个数量,这就是个裸完全背包问题.(复杂度最极端会到1e9) 他们随意原来随意组合的方案,与他们都减去 最小的 一个 a[ i ] 组合 ...
- Metasploit运行环境内存不要低于2GB
Metasploit运行环境内存不要低于2GB Metasploit启用的时候,会占用大量的内存.如果所在系统剩余内存不足(非磁盘剩余空间),会直接导致运行出错.这种情况特别容易发生在虚拟机Kali ...
- Stream闪亮登场
Stream闪亮登场 一. Stream(流)是什么,干什么 Stream是一类用于替代对集合操作的工具类+Lambda式编程,他可以替代现有的遍历.过滤.求和.求最值.排序.转换等 二. Strea ...
- 2018-2019-2 网络对抗技术 20162329 Exp3 免杀原理与实践
目录 免杀原理与实践 一.基础问题回答 1.杀软是如何检测出恶意代码的? 2.免杀是做什么? 3.免杀的基本方法有哪些? 二.实验内容 1. 正确使用msf编码器 2. msfvenom生成如jar之 ...
- 关于阿里ICON矢量图(SVG)上传问题.
注意点: 1. 存储为svg格式(建议使用存储为svg,不要使用导出为svg)2. 图像位置:链接(注意哦,不要点嵌入和保留编辑功能)---确定3. AI里面选中图形,点对象-路径-轮廓化描边 软件编 ...
- mac效率工具
前言:在命令行中切换目录是最常用的操作,我相信一遍又一遍重复“cd ls cd ls cd ls ……”绝对会让你抓狂. 记录一下,方便下次系统重装,哈哈 一. oh-my-zsh mac 预装了 z ...