redis 系列26 Cluster高可用 (1)
一.概述
Redis集群提供了分布式数据库方案,集群通过分片来进行数据共享,并提供复制和故障转移功能。在大数据量方面的高可用方案,cluster集群比Sentinel有优势。但Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误。学习集群同样先了解一些原理方面包括:节点、槽指派、命令执行、重新分片,转向、故障转移、消息。后面再操作集群演示。关于集群搭建后面会列出实现步骤,也可参考Redis官网的实现步骤:http://www.redis.cn/topics/cluster-tutorial.html
1.1 节点
一个Redis集群通常由多个节点(node)组成,开始每个节点都是相互独立的,需要将独立的节点连接起来,构成一个包含多节点的集群。连接各节点的工作使用cluster meet命令来完成,格式如下:
cluster meet ip port
向一个节点发送该命令,可以让发送的节点与指定的节点进行握手,握手成功时,指定的节点就会添加到发送节点当前所在的集群中。例如:有三个独立的节点,端口分别为:7000, 7001,7002。首先使用客户端连接上节点7000, 通过发送cluster nodes命令可以看到,集群目前只包含7000自己一个节点,通过cluster nodes查看信息如下:
/usr/local/redis/bin
[root@hsr bin]# ./redis-cli -c -p -a
127.0.0.1:> cluster nodes
142116fa16006f39865ebe604d1580c119fa0fea :7000@17000 myself,master - 0 0 0 connected
通过向节点7000发送以下命令,可以将节点7001 添加到7000所在的集群中:
127.0.0.1:> cluster meet 127.0.0.1
OK
继续向节点7000发送以下命令,可以将节点7002也添加到7000和7001所在的集群中:
127.0.0.1:> cluster meet 127.0.0.1
OK
三个节点握手成功,使三个节点都处于同一个集群中,再次查看集群节点情况,三个节点都connected连接成功:
127.0.0.1:> cluster nodes
0eed9cc9122d2724365550b70965c2a8e281043d 127.0.0.1:@ master - connected
aeaaeacb8b4d4c4a3bca3c6f52fc4b363e68f083 127.0.0.1:@ master - connected
142116fa16006f39865ebe604d1580c119fa0fea 127.0.0.1:@ myself,master - connected
cluster nodes由以下字段组成,表格如下:
|
字段名 |
描述 |
节点7002的字段值 |
|
id |
节点 ID,一个40个字符的随机字符串 |
0eed9cc9122d2724365550b70965c2a8e281043d |
| ip:port | 客户端应该联系节点以运行查询的节点地址 | 127.0.0.1:7002 |
| flags | 逗号列表分隔的标志,myself,master,slave,fail等 | master |
| master | 如果节点是从属节点,并且主节点已知,则节点ID为主节点,否则为“ - ”字符 | - |
| ping-sent | 毫秒为单位的当前激活的ping发送的unix时间 | 1545632759414 |
| config-epoch | 当前节点的配置时期,每次发生故障切换时,都会创建一个新的,唯一的 | 2> |
| link-state | 用于节点到节点集群总线的链路状态。我们使用此链接与节点进行通信 | connected |
| slot | 在connected后面还会显示槽号范围 | 分配槽后显示 |
(1) 启动节点
一个节点就是一个运行在集群模式下的Redis服务器,Redis服务器在启动时会根据cluster-enabled 配置选项是否为yes来决定是否开启服务器的集群模式。每个节点还是与普通redis服务一样,具备所有功能比如:支持RDB、AOF持久化、发布与订阅、保存键值对、复制 等等。对于集群模式才会用到的数据,内部保存在cluster.h/clusterState结构中。
(2) 集群数据结构
内部clusterNode结构保存了一个节点的当前状态,比如节点的创建时间、节点的名字、节点当前的配置纪元、节点的IP、Port等等。每个节点都会使用一个clusterNode结构来记录自己的状态,并为集群中的所有其它节点(包括主从)都会创建一个相应的clusterNode结构, 以此来记录其它节点的状态。该结构中的属性不再介绍,详细请查看"redis设计与实现"书。
(3) cluster meet 命令的实现
上面讲到通过cluster meet 命令,可以使节点与指定的节点进行握手形成集群。假设有节点A和B 握手的步骤包括:
(1) 在客户端向节点A发送一条 cluster meet B命令时,节点A会为节点B创建一个ClusterNode结构,并将该结构添加到自己的ClusterState.nodes字典中。
(2) 向节点B发送meet后,如果顺利节点B将接收到节点A消息,节点B会为节点A创建一个ClusterNode结构, 并将该结构添加到自己的ClusterState.nodes字典中。
(3) 节点B 将向节点A返回一条PONG消息。
(4) 节点A接收B返回的消息,能过这条PONG消息节点A知道节点B已经成功接收到了自己发送的MEET消息。
(5) 节点A将向B返回一条PING消息。
(6) 节点B将接收A的消息,通过这条PING消息节点B知道节点A已经成功接收到了自己返回的PONG消息,握手成功。
之后节点A会将节点B的信息通过Gossip协议传播给集群中的其他节点,让其他节点也与节点B进行握手,最终节点B会被集群中所有节点认识。
1.2 槽指派
Redis集群通过分片的方式来保存数据库中的键值对:集群的整个 数据库被分为16384个槽(slot), 数据库中的每个键都属于这16384 个slot其中一个,集群中的每个节点可以处理0个或最多16384个slot。当数据库中的16384个slot都有在节点中分配时,此时集群处于上线状态(OK),相反如果任何一个slot没有得到分配,那么集群处于下线状态(fail)。
在节点7000的客户端通过cluster info可以查看,因为集群中的三个节点都没有在处理任何slot,所以处于下线状态。能过cluster info来查看集群为fail状态,如下所示:
127.0.0.1:> cluster info
cluster_state:fail
cluster_slots_assigned:
cluster_slots_ok:
cluster_slots_pfail:
cluster_slots_fail:
cluster_known_nodes:
通向节点发送cluster addslots命令,可以将一个或多个slot指派给某节点负责。例如将slot 0 到5000指派给节点7000负责,手动添加槽时,一定要退出redis客户端,命令如下:
[root@hsr bin]# ./redis-cli -h 127.0.0.1 -p -a cluster addslots {..}
OK
在登到redis客户端,查看集群节点的槽分配情况,可以看到7000节点已分配了0-5000的槽范围:
[root@hsr bin]# ./redis-cli -c -p -a
127.0.0.1:> cluster nodes
0eed9cc9122d2724365550b70965c2a8e281043d 127.0.0.1:@ master - connected
aeaaeacb8b4d4c4a3bca3c6f52fc4b363e68f083 127.0.0.1:@ master - connected
142116fa16006f39865ebe604d1580c119fa0fea 127.0.0.1:@ myself,master - connected 0-5000
为了让7000、7001、7002三个节点所在的集群进入上线状态,继续将slot 5001~10000指派给节点7001。 将slot 10001~16383指派给7002。当三个cluster addslots 命令都执行后,数据库中的16383个slot都已经指派给了相应的节点,集群进入上线状态。
[root@hsr bin]# ./redis-cli -h 127.0.0.1 -p -a cluster addslots {..}
OK
[root@hsr bin]# ./redis-cli -h 127.0.0.1 -p -a cluster addslots {..}
OK
此时已经进入集群进入上线状态:如下所示:
127.0.0.1:> cluster info
cluster_state:ok
cluster_slots_assigned:
cluster_slots_ok:
cluster_slots_pfail:
cluster_slots_fail:
cluster_known_nodes:
cluster_size:
127.0.0.1:> cluster nodes
a9e82a7870ac31c221a4d13b28ba9897bb12257c 127.0.0.1:@ myself,master - connected 0-5000
3b10786d21bbeb66e3517e8d3daa3ee2ce16705e 127.0.0.1:@ master - connected 5001-10000
7bd0cbd26392d1e98ffe9d46ae153c944d8f398d 127.0.0.1:@ master - connected 10001-16383
一个节点除了会将自己负责处理的slot外,还会将自己的slot数组通过消息发送给集群中的其他节点,以此来告知其他节点自己目前处理哪些slot。例如:当节点A 通过消息从节点B那里接收到节点B的slot数组时,节点A会在自己的ClusterState.nodes字典中查找节点B对应的ClusterState结构,并对结构中的slots数组进行保存或更新。这样下来集群中的每个节点都会知道数据库中的16384个slot分别被指派给了集群中的哪些节点。
下图是集群中各节点的ClusterState.nodes字典,里面记录了slot与各节点的分配关系:
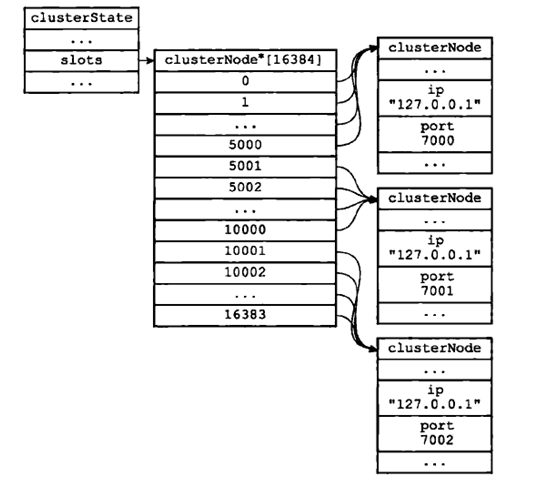
1.3 在集群中执行命令
在对数据库中的16384个slot都进行了指派之后,集群进入上线状态,这时客户端就可以向集群中的节点发送数据命令了。当客户端向节点发送键有关的命令时,接收的节点会计算出命令要处理的键属于哪个slot,并检查这个slot是否派给了节点自己:
(1)如果键所在的slot正好就指派给了当前节点,那么节点直接执行这个命令。
(2)如果键所在的slot并没有指派给当前节点,那么节点会向客户端返回一个moved错误,指引客户端转向到正确的节点,并再次发送之前想要的执行命令。

自动分配节点和槽号,示例如下所示:
-- 在节点7000写入一个键值对,发现自动分配到7001的14041槽号中。
127.0.0.1:> set cluster "hello 7000"
-> Redirected to slot [] located at 127.0.0.1:
OK --节点7000,读取该键,自动重定向到7001节点中出读取
127.0.0.1:> get cluster
-> Redirected to slot [] located at 127.0.0.1:
"hello 7000" --节点7000, 修改该键,自动重定向到7001节点中出修改
127.0.0.1:> set cluster "hello 7001"
-> Redirected to slot [] located at 127.0.0.1:
OK
(1) 计算键属于哪个slot槽
redis 集群共有16384个哈希槽, 每个key通过CRC16校验后对16384个槽取模来决定放置到哪个节点的槽号。使用cluster keyslot key命令可以查看一个指定的键属于哪个slot,例如下面读取cluster键,对应槽号为14041。如下所示:
127.0.0.1:> cluster keyslot cluster
(integer)
(2) moved错误(Redirected重定向 )
当节点发现键所在的槽并非由自己负责处理的时候,节点就会向客户端返回一个moved错误,指引客户端转向到正在负责槽的节点。moved错误格式为:moved slot ip :port。 其中slot为键所在的槽,而ip和port则是负责处理槽slot的节点的ip地址和端口号。
在集群模式下客户端接收到moved错误时,并不会打印出moved错误,而是根据moved错误自动进行节点转向,并打印出转向日志Redirected to slot 信息。只有在单机模式下,才会打印moved信息,因为单机模式下的redis-cli客户端不清楚moved错误的作用,所以会直接将moved信息打印出来,则不是进行节点转向。
(3) 节点数据库的实现
集群节点保存键值对以及键值对 过期的方式与单机redis服务方式完全相同,节点与单机服务器在数据库方面的一个区别是:节点只能使用0号数据库,而单机redis服务则没有这一限制。
1.4 重新分片
Redis集群的重新分片操作可以将任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点,并且相关槽所属的键值对也会从源节点被移动到目标节点。重新分片操作可以在线online进行,重新分片过程中,集群不需要下线,并且源节点和目标节点都可以继续处理命令请求。
例如:在原有节点7000,7001,7002三个节点的集群上,新添加一个节点,端口为7003,然后通过重新分片操作,将原本指派给节点7002的10001~16383的槽,将其中的14042-16383重新分给节点7003。
-- 配置好7003的redis.conf, 启动7003的redis服务
[root@hsr cluster-test]# pwd
/usr/local/redis/cluster-test
[root@hsr cluster-test]# ./redis-server .//redis.conf -- 将7003加入集群中
127.0.0.1:> cluster meet 127.0.0.1
OK -- 查看集群信息时,有两个槽(,)已经自动分配到了7003节点
127.0.0.1:> cluster nodes
399051ed127fbd1df8a0455858da9c103bf4864a 127.0.0.1:@ master - connected 4808 14041
a9e82a7870ac31c221a4d13b28ba9897bb12257c 127.0.0.1:@ myself,master - connected - -
3b10786d21bbeb66e3517e8d3daa3ee2ce16705e 127.0.0.1:@ master - connected -
7bd0cbd26392d1e98ffe9d46ae153c944d8f398d 127.0.0.1:@ master - connected - -
通过setslot来简单演示下重新分配槽:
在迁移(目的节点)执行cluster setslot <slot> IMPORTING <node ID>命令,指明需要迁移的slot和迁移源节点。
下面登录到7003目的节点,使用cluster setslot将参数14042槽号以及所在的源节点ID,导入到当前7003节点中。
127.0.0.1:> cluster setslot importing 7bd0cbd26392d1e98ffe9d46ae153c944d8f398d
OK -- 查看cluster nodes ,7003节点信息如下:
399051ed127fbd1df8a0455858da9c103bf4864a 127.0.0.1:@ myself,master - connected
[14042-<-7bd0cbd26392d1e98ffe9d46ae153c944d8f398d]
取消迁移操作,可在迁移源节点和迁移目的节点上执行cluster setslot <slot> STABLE。下篇介绍使用redis-trib.rb来进行重新分片,redis-trib.rb自动实现了setslot的完整的迁移流程。
redis 系列26 Cluster高可用 (1)的更多相关文章
- redis 系列27 Cluster高可用 (2)
一. ASK错误 集群上篇最后讲到,对于重新分片由redis-trib负责执行,关于该工具以后再介绍.在进行重新分片期间,源节点向目标节点迁移一个槽的过程中,可以会出现该槽中的一部分键值对保存在源节点 ...
- Redis系列4:高可用之Sentinel(哨兵模式)
Redis系列1:深刻理解高性能Redis的本质 Redis系列2:数据持久化提高可用性 Redis系列3:高可用之主从架构 1 背景 从第三篇 Redis系列3:高可用之主从架构 ,我们知道,为Re ...
- Redis系列3:高可用之主从架构
Redis系列1:深刻理解高性能Redis的本质 Redis系列2:数据持久化提高可用性 1 主从复制介绍 上一篇<Redis系列2:数据持久化提高可用性>中,我们介绍了Redis中的数据 ...
- Redis系列(四)-低成本高可用方案设计
关于Redis高可用方案,看到较多的是keepalived.zookeeper方案. keepalived是主备模式,意味着总有一台浪费着.zookeeper工作量成本偏高. 本文主要介绍下使用官方s ...
- Redis Cluster高可用集群在线迁移操作记录【转】
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- Redis Cluster高可用集群在线迁移操作记录
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- Dubbo入门到精通学习笔记(十五):Redis集群的安装(Redis3+CentOS)、Redis集群的高可用测试(含Jedis客户端的使用)、Redis集群的扩展测试
文章目录 Redis集群的安装(Redis3+CentOS) 参考文档 Redis 集群介绍.特性.规范等(可看提供的参考文档+视频解说) Redis 集群的安装(Redis3.0.3 + CentO ...
- Redis从出门到高可用--Redis复制原理与优化
Redis从出门到高可用–Redis复制原理与优化 单机有什么问题? 1.单机故障; 2.单机容量有瓶颈 3.单机有QPS瓶颈 主从复制:主机数据更新后根据配置和策略,自动同步到备机的master/s ...
- net core 实战之 redis 负载均衡和"高可用"实现
net core 实战之 redis 负载均衡和"高可用"实现 1.概述 分布式系统缓存已经变得不可或缺,本文主要阐述如何实现redis主从复制集群的负载均衡,以及 redis的& ...
随机推荐
- bs4解析库
beautifulsoup4 bs4解析库是灵活又方便的网页解析库,处理高效,支持多种解析器.利用它不用编写正则表达式即可方便地实现网页的提取 要解析的html标签 from bs4 import B ...
- pycharm中range的应用
v = range(100) for item in v: print (item) #输出结果是0 1 2 3 ......99 这是在python3中实现的,python2中不一样 下面是一个从大 ...
- POJ 1966 Cable TV Network (点连通度)【最小割】
<题目链接> 题目大意: 给定一个无向图,求点连通度,即最少去掉多少个点使得图不连通. 解题分析: 解决点连通度和边连通度的一类方法总结见 >>> 本题是求点连通度, ...
- 与下位机或设备的通信解析优化的一点功能:T4+动态编译
去年接触的一个项目中,需要通过TCP与设备进行对接的,传的是Modbus协议的数据,然后后台需要可以动态配置协议解析的方式,即寄存器的解析方式,,配置信息有:Key,数据Index,源数据类型 ...
- python 在ubuntu下安装pycurl
https://www.linuxidc.com/Linux/2016-05/131574.htm
- vue与avuex
现在 使用avuex做出来表格效果,但是看到源码看到需要使用vue,不得不开始学习vue 配置环境:cnpm配置过程:a:首先下载node.js然后根据https://www.cnblogs.com/ ...
- (转)Jquery获取上级、下级或者同级的元素
下面介绍JQUERY的父,子,兄弟节点查找方法 jQuery.parent(expr) 找父亲节点,可以传入expr进行过滤,比如$("span").parent()或者$(&qu ...
- 推荐vim学习教程--《Vim 练级手册》
非常不错的vim学习资源,讲解的简单明了,可以作为速查工具,在忘记时就翻下.地址如下: <Vim 练级手册>
- Linux网络文件系统的实现与调试
NFS协议 NFS (网络文件系统)不是传统意义上的文件系统,而是访问远程文件系统的网络协议.整个NFS服务的TCP/IP协议栈如下图所示,NFS是应用层协议,表示层是XDR,会话层是RPC,传输层同 ...
- Linux-1.Windows远程连接Linux的工具
1.下载工具 想要链接远程Linux服务器,就需要工具来进行连接. 工具一:连接远端Linux工具--putty(可以用xshell啥的,我懒,就弄了个这个,建议还是xshell哈,功能多,还好看) ...