如何确定Kafka的分区数、key和consumer线程数
【原创】如何确定Kafka的分区数、key和consumer线程数
def partition(key: Any, numPartitions: Int): Int = {
Utils.abs(key.hashCode) % numPartitions
}
这就保证了相同key的消息一定会被路由到相同的分区。如果你没有指定key,那么Kafka是如何确定这条消息去往哪个分区的呢?

if(key == null) { // 如果没有指定key
val id = sendPartitionPerTopicCache.get(topic) // 先看看Kafka有没有缓存的现成的分区Id
id match {
case Some(partitionId) =>
partitionId // 如果有的话直接使用这个分区Id就好了
case None => // 如果没有的话,
val availablePartitions = topicPartitionList.filter(_.leaderBrokerIdOpt.isDefined) //找出所有可用分区的leader所在的broker
if (availablePartitions.isEmpty)
throw new LeaderNotAvailableException("No leader for any partition in topic " + topic)
val index = Utils.abs(Random.nextInt) % availablePartitions.size // 从中随机挑一个
val partitionId = availablePartitions(index).partitionId
sendPartitionPerTopicCache.put(topic, partitionId) // 更新缓存以备下一次直接使用
partitionId
}
}
可以看出,Kafka几乎就是随机找一个分区发送无key的消息,然后把这个分区号加入到缓存中以备后面直接使用——当然了,Kafka本身也会清空该缓存(默认每10分钟或每次请求topic元数据时)
val nPartsPerConsumer = curPartitions.size / curConsumers.size // 每个consumer至少保证消费的分区数
val nConsumersWithExtraPart = curPartitions.size % curConsumers.size // 还剩下多少个分区需要单独分配给开头的线程们
...
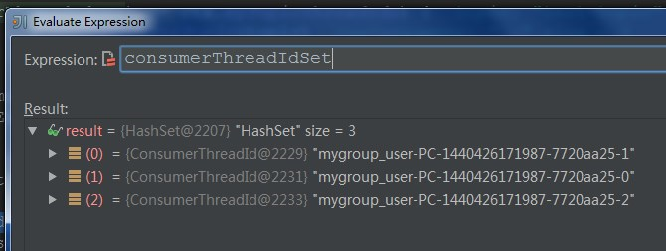
for (consumerThreadId <- consumerThreadIdSet) { // 对于每一个consumer线程
val myConsumerPosition = curConsumers.indexOf(consumerThreadId) //算出该线程在所有线程中的位置,介于[0, n-1]
assert(myConsumerPosition >= 0)
// startPart 就是这个线程要消费的起始分区数
val startPart = nPartsPerConsumer * myConsumerPosition + myConsumerPosition.min(nConsumersWithExtraPart)
// nParts 就是这个线程总共要消费多少个分区
val nParts = nPartsPerConsumer + (if (myConsumerPosition + 1 > nConsumersWithExtraPart) 0 else 1)
...
}
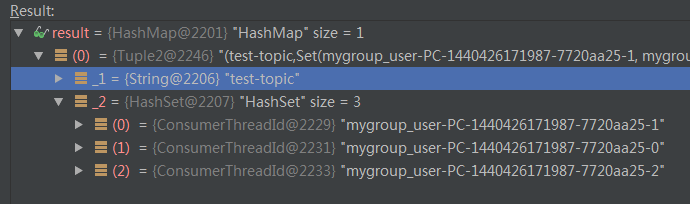
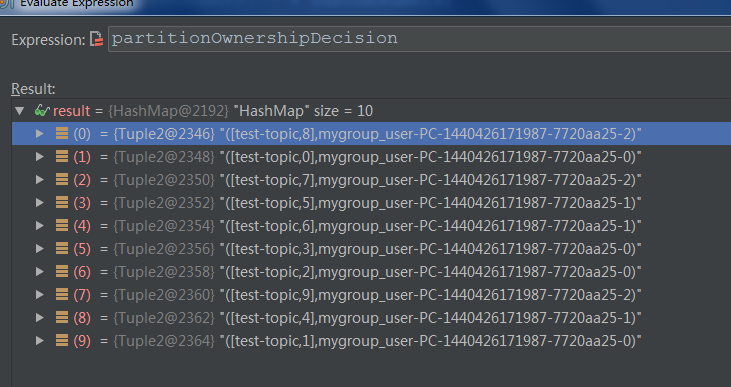
针对于这个例子,nPartsPerConsumer就是10/3=3,nConsumersWithExtraPart为10%3=1,说明每个线程至少保证3个分区,还剩下1个分区需要单独分配给开头的若干个线程。这就是为什么C0消费4个分区,后面的2个线程每个消费3个分区,具体过程详见下面的Debug截图信息:




如何确定Kafka的分区数、key和consumer线程数的更多相关文章
- 【原创】如何确定Kafka的分区数、key和consumer线程数
在Kafak中国社区的qq群中,这个问题被提及的比例是相当高的,这也是Kafka用户最常碰到的问题之一.本文结合Kafka源码试图对该问题相关的因素进行探讨.希望对大家有所帮助. 怎么确定分区数? ...
- 【转】如何确定Kafka的分区数、key和consumer线程数
文章来源:http://www.cnblogs.com/huxi2b/p/4583249.html -------------------------------------------------- ...
- springboot kafka集成(实现producer和consumer)
本文介绍如何在springboot项目中集成kafka收发message. 1.先解决依赖 springboot相关的依赖我们就不提了,和kafka相关的只依赖一个spring-kafka集成包 &l ...
- Apache Kafka - KIP-42: Add Producer and Consumer Interceptors
kafka 0.10.0.0 released Interceptors的概念应该来自flume 参考,http://blog.csdn.net/xiao_jun_0820/article/det ...
- kafka producer自定义partitioner和consumer多线程
为了更好的实现负载均衡和消息的顺序性,Kafka Producer可以通过分发策略发送给指定的Partition.Kafka Java客户端有默认的Partitioner,平均的向目标topic的各个 ...
- Kafka 学习笔记之 Producer/Consumer (Scala)
既然Kafka使用Scala写的,最近也在慢慢学习Scala的语法,虽然还比较生疏,但是还是想尝试下用Scala实现Producer和Consumer,并且用HashPartitioner实现消息根据 ...
- kafka 创建消费者报错 consumer zookeeper is not a recognized option
在做kafka测试的时候,使用命令bin/kafka-console-consumer.sh --zookeeper 192.168.0.140:2181,192.168.0.141:2181 --t ...
- Apache Samza流处理框架介绍——kafka+LevelDB的Key/Value数据库来存储历史消息+?
转自:http://www.infoq.com/cn/news/2015/02/apache-samza-top-project Apache Samza是一个开源.分布式的流处理框架,它使用开源分布 ...
- Kafka 0.10.0.1 consumer get earliest partition offset from Kafka broker cluster - scala code
Return: Map[TopicPartition, Long] Code: val props = new Properties() props.put(ConsumerConfig.BOOTST ...
随机推荐
- django入门与实践 - 关于升级到django 3.7,三种模板超链接配置(编辑中)
第一种方法: 在myblog/urls.py模块中: from django.contrib import admin from django.urls import path, include ur ...
- 如何给win7自带的截图工具设置快捷键
win7自带的截图工具很好,很强大,比从网上下载的截图工具好用多了,很少会出现问题.但是它能不能像QQ截图工具一样可以使用快捷键呢?今天小编和大家分享下心得,希望能够给你的工作带来快捷. 工具/原料 ...
- C++ 浅拷贝与深拷贝探究
C++浅拷贝与深拷贝探究 浅拷贝与深拷贝的概念是在类的复制/拷贝构造函数中出现的. 拷贝构造函数使用场景 对象作为参数,以值传递方式传入函数(要调用拷贝构造函数将实参拷贝给函数栈中的形参) 对象作为返 ...
- Error: Invoke-customs are only supported starting with Android O (--min-api 26)
项目报错: 完美解决: 在App下 gradle.build中Android标签中 添加以下内容: compileOptions { sourceCompatibility JavaVersion.V ...
- Django2.0 正则表示匹配的简单例子
在Django中,使用正则表达式,匹配Url 默认情况下,url固定格式如下: urlpatterns = [ path('admin/', admin.site.urls), ] 如果需要使用正则表 ...
- Git使用入门笔记
1. 创建并初始化一个 代码仓库 (repository) $ git init 2.查看当前状态 $ git status 3. 将修改后的文件推入缓冲区 $ git add <filenam ...
- [20190401]跟踪dbms_lock.sleep调用.txt
[20190401]跟踪dbms_lock.sleep调用.txt --//自己在semtimedop函数调用理解错误,加深理解,跟踪dbms_lock.sleep调用的情况. 1.环境:SCOTT@ ...
- SQL Server 索引碎片产生原理重建索引和重新组织索引
数据库存储本身是无序的,建立了聚集索引,会按照聚集索引物理顺序存入硬盘.既键值的逻辑顺序决定了表中相应行的物理顺序 多数情况下,数据库读取频率远高于写入频率,索引的存在 为了读取速度牺牲写入速度 页 ...
- 通过apt-get安装JDK8
安装python-software-properties $sudo apt-get install python-software-properties $sudo apt-get install ...
- CORS——跨域请求那些事儿
在日常的项目开发时会不可避免的需要进行跨域操作,而在实际进行跨域请求时,经常会遇到类似 No 'Access-Control-Allow-Origin' header is present on th ...