hadoop之数据压缩与数据格式
* 注:本文原创,转载请注明出处,本人保留对未注明出处行为的责任追究。
a.数据压缩
优点: 1.节省本地空间 2.节省带宽
缺点: 花时间
1.MR中允许进行数据压缩的地方有三个:
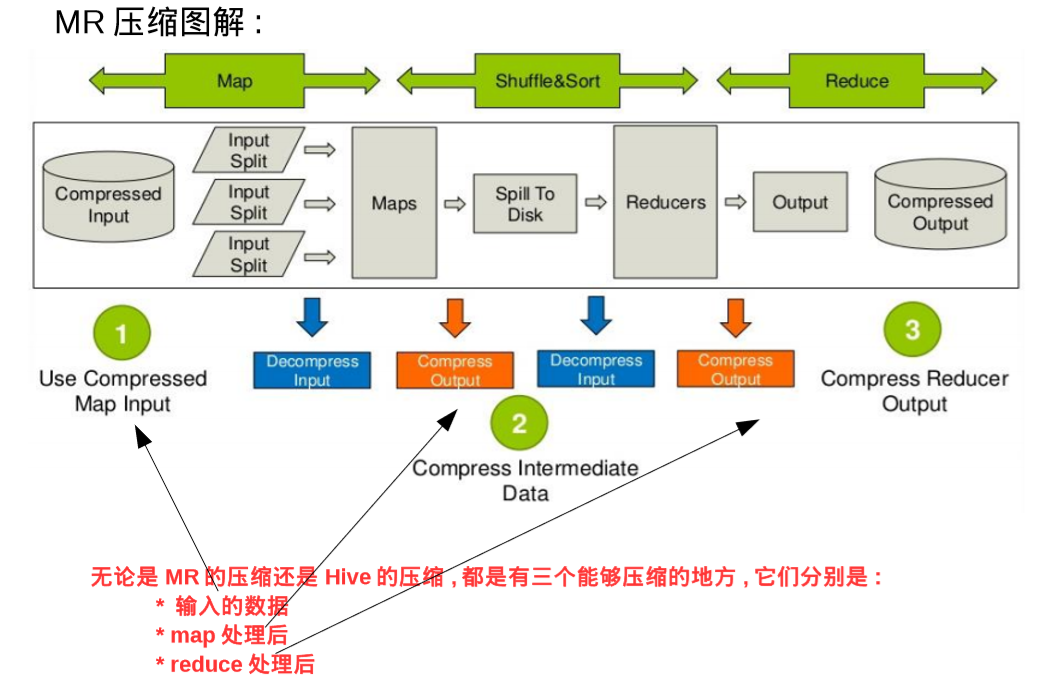
1)input起点 2)map处理之后 3)reduce处理之后进行存储
2.压缩格式
常见的压缩计数有bzip2、gzip、lzo、snappy.它们之间的性能比较如下:
压缩比 : bzip2>gzip>lzo = snappy ,bzip2最节省空间
解压速度 :lzo = snappy > gzip > bzip2 , lzo解压速度是最快的
另外Google研发的snappy的压缩格式,嵌入在hadoop中,因为其可靠性和性能的均衡性,非常受到大家欢迎。
snappy压缩格式的性能与lzo差不多,都是属于压缩解压块,但是压缩比高的类型。以下是它们的一些详细参数:
| 压缩比 | 压缩速率 | 解压速率 | |
| gzip/deflate | 13.4% | 21MB/s | 118MB/s |
| bzip2 | 13.2% | 2.4MB/s | 9.5MB/s |
| lzo | 20.5% | 135MB/s | 410MB/s |
| snappy | 22.2% | 172MB/s | 409MB/s |
(本表数据来源于博客: https://blog.csdn.net/zhouyan8603/article/details/82954459 , 感谢玉羽凌风!)
3.mr中如何使用数据压缩?
刚才谈到了三个可以进行压缩的地方,这里分别说明:
1)输入时,hadoop依据文件格式进行自动识别并解压,这个是自动的,不需要关心太多
2)在map之后有一个可以压缩的点,需要配置以下两个参数进行压缩:
mapreduce.map.output.compress - false/true - 在 map处理后是否启用压缩
mapreduce.map.output.compress.codec – 选择编解码器
3)在reduce之后有一个可以压缩的点,需要配置以下三个参数进行压缩:
mapreduce.output.fileoutputformat.compress – false/true – 在 reduce后是否压缩
mapreduce.output.fileoutputformat.compress.codc – 选择编解码器
mapreduce.output.fileoutputformat.compress.type – RECORD/BLOCK/NONE 其中RECORD是针对记录的压缩,BLOCK是针对块的压缩
其中使用RECORD压缩率比较低,因此一般使用BLOCK。
**注:hadoop支持的编解码器 - 配置中需要用到:
Zlib → org.apache.hadoop.io.compress.Default.Codec
其中Zlib是MR使用的默认压缩格式,当指定上面的bool值为true且没有指定codec的情况下,默认使用这个Codec
Gzip → org.apache.hadoop.io.compress.GzipCodec
Bzip2 → org.apache.hadoop.io.compress.BZip2Codec
Lzo → com.hadoop.compression.lzo.LzoCodec
Lz4 → org.apache.hadoop.io.coompress.Lz4Codec
Snappy → org.apache.hadoop.io.compress.SnappyCodec
其他关于压缩问题的补充: https://www.cnblogs.com/ggjucheng/archive/2012/04/22/2465580.html
4.hive中如何使用数据压缩?

(注:本图引自北风网)
1)Input处的数据压缩,需要在创建表的时候指定
2)map之后的数据压缩需要设置三个参数:
hive.exec.compress.intermediate - true
mapred.map.output.compress.codec – 选择编解码器
mapred.map.output.compress.codec - RECORD/BLOCK
3)reduce之后的数据压缩需要设置三个参数:
hive.exec.compress.output - true
mapred.output.compression.codec - 编解压器
mapred.output.compression.type - RECORD/BLOCK
b.数据存储格式
在创建Hive表的时候,我们可以用STORED AS关键字来指定数据存储格式。
Hadoop支持的常见的存储格式有以下几种:

1.hadoop支持的文件存储格式,比较典型的有(需要记住):
* 按行存储
SEQUENCEFILE TEXTFILE
* 按列存储
RCFILE ORC PARQUET
2.行式存储与列式存储的比较
1)列式存储每一列单独摘出来存放,行式存储按行存放。
这就导致行式存储进行查询时,需要把每一行完整的读进去。而列式存储只需要找到指定的几行,读这几行就可以。
2)因此列式存储不适用于更新多,整表查询的场景,适用于只查询不更新,并且查询主要集中于某几列的场景。因此其常用于OLAP业务。
行式存储在只查询几列数据的时候,性能不如列式 存储。但是它灵活可以变动,适用于修改、实时交互的场景。因此常用于OLTP业务。
* 注意:HBase 的“列式数据库”是指数据的逻辑模型是支持列可扩展的,而实际的存储模型是JSON实现的行式存储。
企业里用的比较多的列式压缩式ORC以及Apache的Parquet.

(来源:https://hortonworks.com/blog/orcfile-in-hdp-2-better-compression-better-performance/)
在上图中,我们可以看到不同存储格式,占用的存储空间不同。
3.ORCFile的存储格式
感谢 https://www.cnblogs.com/ITtangtang/p/7677912.html !
4.Parquet存储格式
TODO
hadoop之数据压缩与数据格式的更多相关文章
- Hadoop的数据压缩
一.Hadoop的数据压缩 1.概述 在进行MR程序的过程中,在Mapper和Reducer端会发生大量的数据传输和磁盘IO,如果在这个过程中对数据进行压缩处理,可以有效的减少底层存储(HDFS)读写 ...
- hive 压缩全解读(hive表存储格式以及外部表直接加载压缩格式数据);HADOOP存储数据压缩方案对比(LZO,gz,ORC)
数据做压缩和解压缩会增加CPU的开销,但可以最大程度的减少文件所需的磁盘空间和网络I/O的开销,所以最好对那些I/O密集型的作业使用数据压缩,cpu密集型,使用压缩反而会降低性能. 而hive中间结果 ...
- 【Hadoop】Hadoop的数据压缩方式
概述 压缩技术能够有效减少底层存储系统(HDFS)读写字节数.压缩提高了网络带宽和磁盘空间的效率.在Hadoop下,尤其是数据规模很大和工作负载密集的情况下,使用数据压缩显得非常重要.在这种情况下 ...
- 转载:Hadoop权威指南学习笔记
转自:http://pieux.github.io/blog/2013-05-08-learn-hadoop-the-definitive-guide.html 1 前言 Hadoop的内部工作机制: ...
- hadoop2.2编程: 数据压缩
本文主要讨论hadoop的数据压缩与解压缩代码的书写 Compressing and decompressing streams with CompressionCodec import org.ap ...
- Hadoop InputFormat
Hadoop可以处理不同数据格式(数据源)的数据,从文本文件到(非)关系型数据库,这很大程度上得益于Hadoop InputFormat的可扩展性设计,InputFormat层次结构图如下:
- 1-Spark高级数据分析-第一章 大数据分析
1.1 数据科学面临的挑战 第一,成功的分析中绝大部分工作是数据预处理. 第二,迭代与数据科学紧密相关.建模和分析经常需要对一个数据集进行多次遍历.这其中一方面是由机器学习算法和统计过程本身造成的. ...
- Java 面试知识点解析(七)——Web篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- 初学Java Web(8)——过滤器和监听器
什么是过滤器 过滤器就是 Servlet 的高级特性之一,就是一个具有拦截/过滤功能的一个东西,在生活中过滤器可以是香烟滤嘴,滤纸,净水器,空气净化器等,在 Web 中仅仅是一个实现了 Filter ...
随机推荐
- MySQL学习——标识符语法和命名规则
转自:http://blog.csdn.net/notbaron/article/details/50868485 欢迎转载,转载请标明出处:http://blog.csdn.net/notbaron ...
- kendo upload必填验证
@using Kendo.Mvc.UI @using StudentManage.Common.Helper @model StudentManage.Models.Home.ImportDataFr ...
- codeforces-2
B.chocolates #include<iostream> #include<algorithm> #include<string.h> long long b ...
- https://blog.csdn.net/uftjtt/article/details/79044186
https://blog.csdn.net/uftjtt/article/details/79044186
- vscode小程序代码高亮
vscode无法识别wxml,wxss语法: wxml文件设置: (1)任意打开一wxml文件,点击下方语言模式选择,这里已关联wxm所以当前显示wxml.默认关联为纯文本或者html或其他语法,点击 ...
- SQL kaggle learn with as excercise
rides_per_year_query = """ SELECT EXTRACT(YEAR FROM trip_start_timestamp) AS year ,CO ...
- 阿里云 SSL 证书 总结
历时2天左右的证书上传部署,终于结束了! 因为公司要开发小程序,小程序部署到开发环境必须支持https证书行. 阿里云目前的证书还是比较多的额,大致分为2类,一类是支持单域名,一类是支持泛域名. 自己 ...
- html-webpack-plugin 遇到 throw new Error('Cyclic dependency' + nodeRep)
今天遇到了 html-webpack-plugin 遇到 throw new Error('Cyclic dependency' + nodeRep) 错. 刚查到一篇文章,<手摸手,带你用合理 ...
- springmvc 配置之 mvc:default-servlet-handler
配置dispatchServlet的方法一般是: <servlet> <servlet-name>mvc-servlet</servlet-name> <se ...
- Java 必须掌握的 20+ 种 Spring 常用注解
Spring部分 1.声明bean的注解 @Component 组件,没有明确的角色 @Service 在业务逻辑层使用(service层) @Repository 在数据访问层使用(dao层) @C ...