Bag of Tricks for Image Classification with Convolutional Neural Networks论文笔记
一、高效的训练
1、Large-batch training
使用大的batch size可能会减小训练过程(收敛的慢?我之前训练的时候挺喜欢用较大的batch size),即在相同的迭代次数下,
相较于使用小的batch size,使用较大的batch size会导致在验证集上精度下降。文中介绍了四种方法。
Linear scaling learning rate
梯度下降是一个随机过程,增大batch size不会改变随机梯度的期望,但是减小了方差(variance)。换句话说,增大batch size
可以减小梯度中的噪声,所以,此时应该增大学习率来进行调整:随着batch size的增加,线性增加学习率。比如,初始学习率0.1,
batch size=256,当batch size增加为b时,学习率为0.1×b/256
Learning rate warmup
开始使用一个较小的学习率,当训练稳定后,再切换回初始学习率。例如使用5个epochs来warm up,初始学习率为n,在第i个batch,
1<=i<=m,学习率lr=i*n/m
Zero γ
在残差模块中,最后一层为BN层,先对x标准化输出为x̂, 再做一个尺度变换γ x̂ + β。γ和β都为可学习参数,被初始化为1和0。Zero γ
策略是,对于残差模块最后的BN层,γ设为0,相当于网络有更少的层数,在初始阶段更容易训练。
No bias decay
weight decay一般应用在所有可学习参数上,包括weight和bias。为了防止过拟合,只在weights上做正则化,其他参数,包括bias,BN中的
γ和β都不做正则化。
2、Low-precision training
用FP16对所有的parameters和activations进行存储和梯度的计算,与此同时使用FP32对参数进行拷贝用于参数的更新。另外,在损失函数上
乘以一个标量来将梯度的范围更好的对齐到FP16也是一个实用的做法
3、实验
很奇怪的对比实验,应该再加上相同的batch size才更有说服力啊。

二、Model Tweaks
Model Tweaks是指修改模型的结构,比如某个卷基层的stride。本文以resnet为例,探讨这些tweak对精度的影响。
1、ResNet Architecture
一个典型的resnet50结构如下,其中input stem首先使用7*7卷积,stride=2,接着一个3*3的maxpool,stride=2。
input stem将特征减小至1/4,维度增加至64。从state2开始,每个stage包括down sampling和2个residual模块,如图。
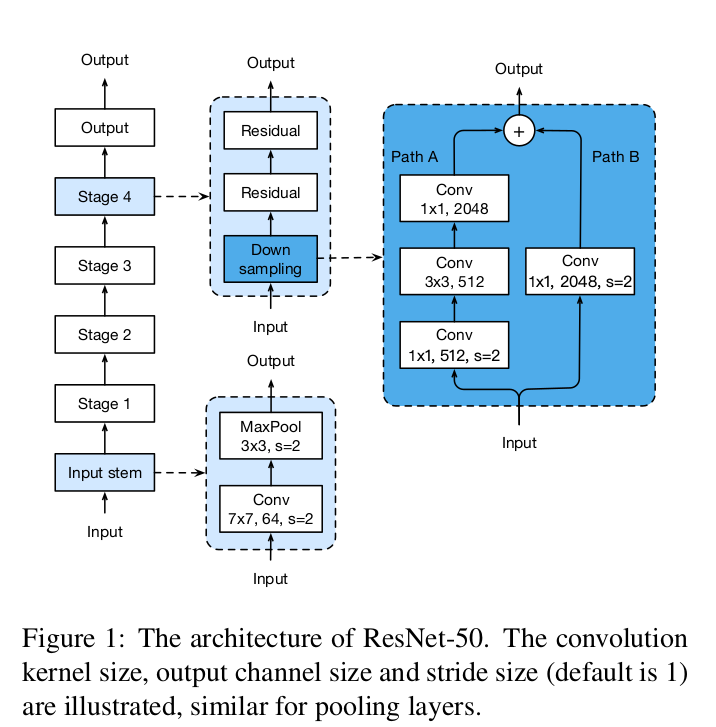
2、ResNet Tweaks
resnet-B更改了down sampling中 stride=2的位置,不让1*1的stride=2,
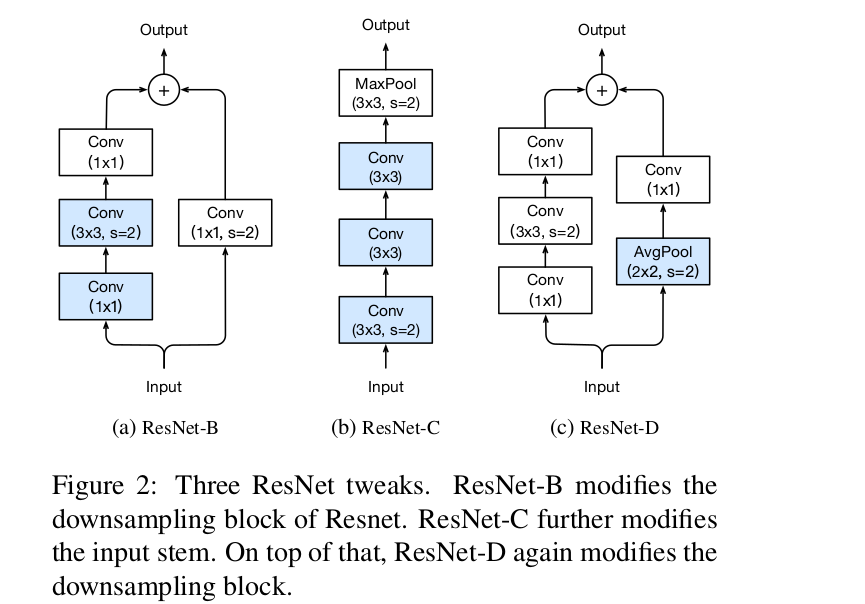
resnet-C将input stem中的7×7卷积用3个3*3代替(节省参数),前两个c=32,最后一个为64.。
为了减小stride=2,1*1卷积的损失,增加avg pool,conv stride=1(这样就不损失吗。。。)对比发现,
resnet-D效果最好。

三、Training Refinements
通过介绍训练中的策略,进一步提高模型准确率
Cosine Learning Rate Decay
其中η是学习率(不包括warm up阶段),不过看validation accur,step decay并不差于cosine decay啊

Label Smoothing
正常的交叉熵损失在预测的时候,对于给定的数据集的label,将正例设为1,负例设为0,是一个one-hot向量。这样子会有一些问题,
模型对于标签过于依赖,当数据出现噪声的时候,会导致训练结果出现偏差。增加一个变量ϵ,对类别进行平滑,此时loss变为,其中p(y)为真是标签,
p(c)为输出类别概率。
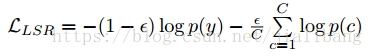
参考: https://zhuanlan.zhihu.com/p/53849733
https://www.cnblogs.com/zyrb/p/9699168.html
Knowledge Distillation
主要用于将大网络压缩为小网络,损失函数为,其中z和r分别是student model和teacher model的输出,p是真实标签的分布
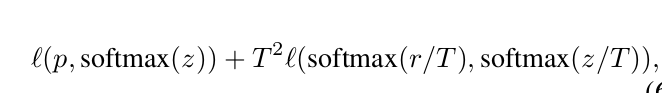
Mixup Training
使用线性插值混合两个样本,构成新的样本,并使用新样本进行训练(没用过知识蒸馏,这意思是teacher model和student model一起训练?)。
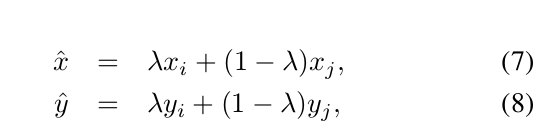
实验
知识蒸馏对mobilnet,inception-v3并没有提升,因为teacher model是resnet,与它们不同。

Bag of Tricks for Image Classification with Convolutional Neural Networks论文笔记的更多相关文章
- Bag of Tricks for Image Classification with Convolutional Neural Networks笔记
以下内容摘自<Bag of Tricks for Image Classification with Convolutional Neural Networks>. 1 高效训练 1.1 ...
- 训练技巧详解【含有部分代码】Bag of Tricks for Image Classification with Convolutional Neural Networks
训练技巧详解[含有部分代码]Bag of Tricks for Image Classification with Convolutional Neural Networks 置顶 2018-12-1 ...
- Bag of Tricks for Image Classification with Convolutional Neural Networks
这篇文章来自李沐大神团队,使用各种CNN tricks,将原始的resnet在imagenet上提升了四个点.记录一下,可以用到自己的网络上.如果图片显示不了,点击链接观看 baseline mode ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- Notes on Large-scale Video Classification with Convolutional Neural Networks
Use bigger datasets for CNN in hope of better performance. A new data set for sports video classific ...
- ImageNet Classification with Deep Convolutional Neural Networks 论文解读
这个论文应该算是把深度学习应用到图片识别(ILSVRC,ImageNet large-scale Visual Recognition Challenge)上的具有重大意义的一篇文章.因为在之前,人们 ...
- Learning local feature descriptors with triplets and shallow convolutional neural networks 论文阅读笔记
题目翻译:学习 local feature descriptors 使用 triplets 还有浅的卷积神经网络.读罢此文,只觉收获满满,同时另外印象最深的也是一个浅(文章中会提及)字. 1 Cont ...
- cs231n spring 2017 lecture5 Convolutional Neural Networks听课笔记
1. 之前课程里,一个32*32*3的图像被展成3072*1的向量,左乘大小为10*3072的权重矩阵W,可以得到一个10*1的得分,分别对应10类标签. 在Convolution Layer里,图像 ...
- Deep learning_CNN_Review:A Survey of the Recent Architectures of Deep Convolutional Neural Networks——2019
CNN综述文章 的翻译 [2019 CVPR] A Survey of the Recent Architectures of Deep Convolutional Neural Networks 翻 ...
随机推荐
- java基础-开发工具IDEA
常用快捷键 查找 查找:Ctrl + F Find In Path: Ctrl + F + Shift (比普通查找多了一个shift) Search EveryWhere : 双击Shift 视图 ...
- T66099 小xzy的数对 题解
T66099 小xzy的数对 题目背景 老师带同学参加表演,要求学生两两一组表演,但有些学生一起会发生冲突,现在老师想知道有多少组学生分到一起时不会发生冲突. 题目描述 学生发生冲突当且仅当他们身上的 ...
- AJAX异步、sweetalert、Cookie和Session初识
一.AJAX的异步示例 1. urls.py from django.conf.urls import url from apptest import views urlpatterns = [ ur ...
- linux 定时下载github最新代码
场景:网站的代码在github上托管,静态网站部署在服务器上,每次自己修改完本地代码后,提交到github上,需要自己去服务器上执行git pull 拉取最新代码, 为了解决这种操作,自己再服务器上 ...
- 单链表&双链表的头插入&尾插入
#include<stdio.h> #include"stdlib.h" struct student { int data; struct student *pnex ...
- java 11 值得关注的新特性
JEP 181: Nest-Based Access Control 基于嵌套的访问控制 JEP 309: Dynamic Class-File Constants 动态类文件 JEP 315: Im ...
- Ajax与JSON共同使用的小实例
实现的效果: 点击“点击”按钮,可以通过Ajax从服务器调过来相应的文档文件,而不需重新加载页面. 通过json可以将调过来的文档(String)转换为相应的json对象,从而对文档中数据进行操作. ...
- 前端工程师必须要知道的HTTP部分
1. IETF组织制定的标准 rfc7234: https://tools.ietf.org/html/rfc7234 --- 原来的2616以被废弃 2. 格式 HTTP分为 请求Request 和 ...
- Java计算文件MD5值(支持大文件)
import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.securit ...
- java树形菜单实现
java树形菜单实现 公司表: 部门表: 实体类: public class Node { private Integer companyId;//公司id private String compan ...