dubbo基础学习总结
http://www.imooc.com/article/21638
https://www.cnblogs.com/xhj123/p/8971131.html
Dubbo基本原理机制
- 分布式服务框架:
- –高性能和透明化的RPC远程服务调用方案
- –SOA服务治理方案
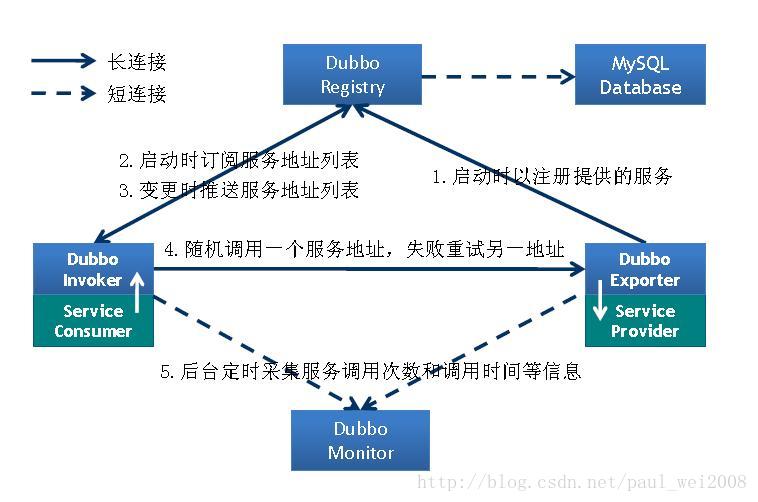
- -Apache MINA 框架基于Reactor模型通信框架,基于tcp长连接
- Dubbo缺省协议采用单一长连接和NIO异步通讯,
- 适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况
- 分析源代码,基本原理如下:
- client一个线程调用远程接口,生成一个唯一的ID(比如一段随机字符串,UUID等),Dubbo是使用AtomicLong从0开始累计数字的
- 将打包的方法调用信息(如调用的接口名称,方法名称,参数值列表等),和处理结果的回调对象callback,全部封装在一起,组成一个对象object
- 向专门存放调用信息的全局ConcurrentHashMap里面put(ID, object)
- 将ID和打包的方法调用信息封装成一对象connRequest,使用IoSession.write(connRequest)异步发送出去
- 当前线程再使用callback的get()方法试图获取远程返回的结果,在get()内部,则使用synchronized获取回调对象callback的锁, 再先检测是否已经获取到结果,如果没有,然后调用callback的wait()方法,释放callback上的锁,让当前线程处于等待状态。
- 服务端接收到请求并处理后,将结果(此结果中包含了前面的ID,即回传)发送给客户端,客户端socket连接上专门监听消息的线程收到消息,分析结果,取到ID,再从前面的ConcurrentHashMap里面get(ID),从而找到callback,将方法调用结果设置到callback对象里。
- 监听线程接着使用synchronized获取回调对象callback的锁(因为前面调用过wait(),那个线程已释放callback的锁了),再notifyAll(),唤醒前面处于等待状态的线程继续执行(callback的get()方法继续执行就能拿到调用结果了),至此,整个过程结束。
- 当前线程怎么让它“暂停”,等结果回来后,再向后执行?
答:先生成一个对象obj,在一个全局map里put(ID,obj)存放起来,再用synchronized获取obj锁,再调用obj.wait()让当前线程处于等待状态,然后另一消息监听线程等到服 务端结果来了后,再map.get(ID)找到obj,再用synchronized获取obj锁,再调用obj.notifyAll()唤醒前面处于等待状态的线程。
- 正如前面所说,Socket通信是一个全双工的方式,如果有多个线程同时进行远程方法调用,这时建立在client server之间的socket连接上会有很多双方发送的消息传递,前后顺序也可能是乱七八糟的,server处理完结果后,将结果消息发送给client,client收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的?
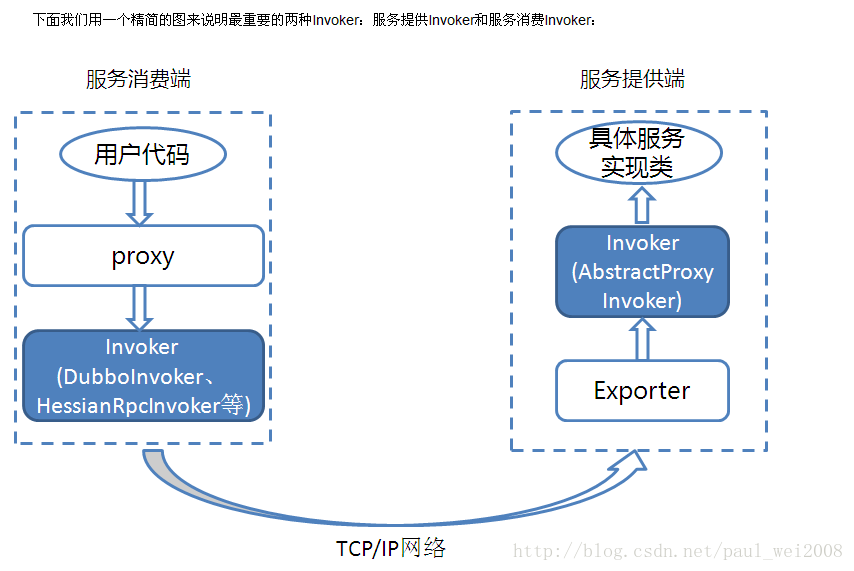
zookeeper入门
zookeeper可谓是目前使用最广泛的分布式组件了。其功能和职责单一,但却非常重要。
在现今这个年代,介绍zookeeper的书和文章可谓多如牛毛,本人不才,试图通过自己的理解来介绍zookeeper,希望通过一个初学者的视角来学习zookeeper,以期让人更加深入和平稳的理解zookeeper。其中参考了不少教程和书,相关书目列在文末,也感谢这些作者。
学习新的框架,先让我们搞清楚他是什么,这是它的内涵,然后再介绍它能做什么,这是它的外延,内涵和外延共同来定义框架本身,会对框架有较为深刻的理解,在应用层面上知道如何用。其次再搞清楚zookeeper相关的理论基础,其目的是知道zookeeper是如何被发明的,是否能够借鉴以便今后自己能够用到其他地方。最后搞清楚zookeeper中一些设计的原理和细节,目的也是搞清来龙去脉,学会“术”从而应用到别的地方。当然了,加深的理解同样能够帮助认识zookeeper本身,在使用时才知道为什么这样用。
首先,
zookeeper到底是什么?
zookeeper实际上是yahoo开发的,用于分布式中一致性处理的框架。最初其作为研发hadoop时的副产品。由于分布式系统中一致性处理较为困难,其他的分布式系统没有必要 费劲重复造轮子,故随后的分布式系统中大量应用了zookeeper,以至于zookeeper成为了各种分布式系统的基础组件,其地位之重要,可想而知。著名的hadoop,kafka,dubbo 都是基于zookeeper而构建。
要想理解zookeeper到底是做啥的,那首先得理解清楚,什么是一致性。
所谓的一致性,实际上就是围绕着“看见”来的。谁能看见?能否看见?什么时候看见?举个例子:淘宝后台卖家,在后台上架一件大促的商品,通过服务器A提交到主数据库,假设刚提交后立马就有用户去通过应用服务器B去从数据库查询该商品,就会出现一个现象,卖家已经更新成功了,然而买家却看不到;而经过一段时间后,主数据库的数据同步到了从数据库,买家就能查到了。
假设卖家更新成功之后买家立马就能看到卖家的更新,则称为强一致性;
如果卖家更新成功后买家不能看到卖家更新的内容,则称为弱一致性;
而卖家更新成功后,买家经过一段时间最终能看到卖家的更新,则称为最终一致性。
更多的一致性例子可以参考文献2,里面列举了10种一致性的例子,如果要给一致性下个定义,可以是分布式系统中状态或数据保持同步和一致。特别需要注意一致性跟事务的区别,可以记得学习数据库时特别强调ACID,故而满足ACID的数据库能够做事务,其中C即是一致性,因此,事务是一致性的一种特例,比起一致性更难达成。

如何保证在分布式环境下数据的最终一致,这个就是zookeeper需要解决的问题。对于这些问题,有哪些挑战,zookeeper又是如何解决这些挑战的,下一篇文章将会主要涉及这个主题。
一些常见的解决一致性问题的方式:
1. 查询重试补偿。对于分布式应用中不确定的情况,先使用查询接口查询到当前状态,如果当前状态不一致则采用补偿接口对状态进行重试推进,或者回滚接口对业务做回滚。典型的场景如银行跟支付宝之间的交互。支付宝发送一个转账请求到银行,如一直未收到响应,则可以通过银行的查询接口查询该笔交易的状态,如该笔交易对方未收到,则采取补偿的模式进行推送。
2. 定时任务推送。对于上面的情况,有可能一次推送搞不定,于是需要2次,3次推送。不要怀疑,支付宝内最初掉单率很高,全靠后续不断的定时任务推送增加成功率。
3. TCC。try-confirm-cancel。实际上是两阶段协议,第二阶段的可以实现提交操作或是逆操作。
zookeeper到底能做什么?
在业界的实际应用是什么?了解这些应用,会对zookeeper能够做的事有更直观的认识。
hadoop:
鼻祖级应用,ResourceManager在整个hadoop中算是单点,为了实现其高可用,分为主备ResourceManager,zookeeper在其中管理整个ResourceManager。
可以想象,主备ResourceManager最初是主RM提供服务,如果一切安好,则zookeeper无用武之地。然而,总归会出现主RM提供不了服务的情况。于是会出现主备切换的情况,而zookeeper正是为主备切换保驾护航。
先来推理一下,主备切换会出现什么问题。传统的主备切换,可以让主备之间维持心跳连接,一旦备机发现主机心跳检测不到了,则自己切换为主机,原来的主机等待救援。这种方式有两个问题,一是由于网络抖动,负载过大等问题,备机检测不到心跳并不能说明主机一定挂了,有可能一定时间后主机或网络恢复,这时候主机并不知道备机已经切换为主机,2台主机互相争用,可能造成脑裂;二是如果一些数据集中在主机上面,则备机切换时由于同步延时势必会损失掉一部分的数据。
如何解决这些问题?早期的方式提供了不少解决方案,比如备机一旦切换为主机,则通过电源控制直接切断主机电源,简单粗暴,但是此刻备机已经是单点,如果主机是因为量撑不住而挂,那备机有可能会重蹈覆辙,最终导致整个服务不可用。
zookeeper又是如何解决这个问题的呢?
1. zookeeper作为第三方集群参与到主备节点中去,当主备启动时会在zookeeper上竞争创建一个临时锁节点,争用成功者则充当主机,其余备机
2. 所有备机会监听该临时锁节点,一旦主机与zookeeper间session失效,则临时节点被删除
3. 一旦临时节点被删除,备机开始重新申请创建临时锁节点,重新争用为主机;
4. 用zookeeper如何解决脑裂?实际上主机争用到节点后通过对根节点做一个ACL权限控制,则其他抢占的机器由于无法更新临时锁节点,只有放弃成为备机。
zookeeper使用了非常简单又现成的方式来解决的这个问题,比起其他方案方便不少,这也是为啥zookeeper流行的原因。说白了,就是把复杂操作封装化精简化
dubbo:
作为业界知名的分布式soa框架,dubbo的主要的服务注册发现功能便是由zookeeper来提供的。
对于一个服务框架,注册中心是其核心中的核心,虽然暂时挂掉并不会导致整个服务出问题,但是一旦挂掉,整体风险就很高。考虑一般情况,注册中心就是单台机器的时候,其实现很容易,所有机器起来都去注册服务给它,并且所有调用方都跟它保持长连接,一旦服务有变,即通过长连接来通知到调用方。但是当服务集群规模扩大时,这事情就不简单了,单机保持连接数有限,而且容易故障。
作为一个稳定的服务化框架,dubbo可以选择并推荐zookeeper作为注册中心。其底层将zookeeper常用的客户端zkclient和curator封装成为ZookeeperClient。
1. 当服务提供者服务启动时,向zookeeper注册一个节点
2. 服务消费者则订阅其父节点的变化,诸如启动停止都能够通过节点创建删除得知,异常情况比如被调用方掉线也可以通过临时节点session 断开自动删除得知
3. 服务消费方同时也会将自己订阅的服务以节点创建的方式放到zookeeper
4. 于是可以得到映射关系,诸如谁提供了服务,谁订阅了谁提供的服务,基于这层关系再做监控,就能轻易得知整个系统情况。
zookeeper的基本数据模型
一句话,类似linux文件系统的节点模型
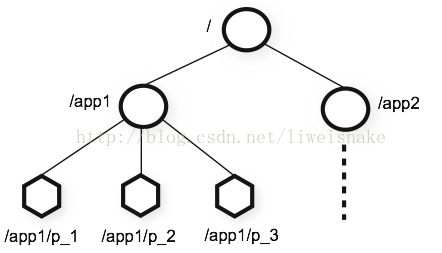
其节点有如下有趣而又重要的特性:
1. 同一时刻多台机器创建同一个节点,只有一个会争抢成功。利用这个特性可以做分布式锁。
2. 临时节点的生命周期与会话一致,会话关闭则临时节点删除。这个特性经常用来做心跳,动态监控,负载等动作
3. 顺序节点保证节点名全局唯一。这个特性可以用来生成分布式环境下的全局自增长id
通过zookeeper提供的原语服务,可以对zookeeper能做的事情有个精确和直观的认识
zookeeper提供的原语服务
1. 创建节点。
2. 删除节点
3. 更新节点
4. 获取节点信息
5. 权限控制
6. 事件监听
实际上,就是对节点的增删查改加上权限控制与事件监听,但是通过对这些原语的组合以及不同场景的使用,可以实现很多用法。参考文献5
1. 数据发布订阅。即注册中心,见上面dubbo用法。主要通过对节点管理做到发布以及事件监听做到订阅
2. 负载均衡。见上面kafka用法
3. 命名服务。zookeeper的节点结构天然支持命名服务,即把信息集中存储,并以树状管理,方便统一查阅
4. 分布式协调通知。协调通知实际上与发布订阅类似,由于引入的第三方的zookeeper,实际上对很多种协调通知做了解耦,比如参考文献4中提到的消息推送,心跳检测等
5. 集群管理与master选举。通过上面的第二点特性,可以轻易得知集群机器存活状况,从而轻松管理集群;通过上面第一点特性,可以做出master争抢。
6. 分布式锁。实际上就是第一点特性的应用。
7. 分布式队列。实际上就是第三点特性的应用。
8. 分布式的并发等待。类似于多线程的join问题,主任务的执行依赖于其他子任务全部执行完毕,在单机多线程里可以用join,但是分布式环境下如何实现呢。利用zookeeper,可以创建一个主任务节点,旗下子任务一旦执行完毕,则在主任务节点下挂一个子任务节点,等节点数量足够,则认为主任务可以开始执行。
可以发现,所有的原语就是zookeeper的基础,而其他的用法总结无非是将原语放到不同场景下的归类罢了。
相信到这里你对zookeeper应该有个初步的了解和大致的印象了。
本系列文章分为:
zookeeper入门系列-理论基础-zab协议
zookeeper入门系列-理论基础-raft协议
zookeeper入门系列-设计细节
参考文献:
保证分布式系统数据一致性的6种方案 http://weibo.com/ttarticle/p/show?id=2309403965965003062676
解决分布式系统的一致性问题,我们需要了解哪些理论? http://mp.weixin.qq.com/s/hGnpHfn7a7yxjPBP78i4bg
分布式系统的事务处理 http://coolshell.cn/articles/10910.html
ZooKeeper典型应用场景一览 http://jm.taobao.org/2011/10/08/1232/
zookeeper中的基本概念 http://www.hollischuang.com/archives/1280
zookeeper入门使用 http://www.importnew.com/23025.html
安装和配置详解
本文介绍的 Zookeeper 是以 3.2.2 这个稳定版本为基础,最新的版本可以通过官网 http://hadoop.apache.org/zookeeper/来获取,Zookeeper 的安装非常简单,下面将从单机模式和集群模式两个方面介绍 Zookeeper 的安装和配置。
单机模式
单机安装非常简单,只要获取到 Zookeeper 的压缩包并解压到某个目录如:/home/zookeeper-3.2.2 下,Zookeeper 的启动脚本在 bin 目录下,Linux 下的启动脚本是 zkServer.sh,在 3.2.2 这个版本 Zookeeper 没有提供 windows 下的启动脚本,所以要想在 windows 下启动 Zookeeper 要自己手工写一个,如清单 1 所示:
清单 1. Windows 下 Zookeeper 启动脚本
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
setlocal set ZOOCFGDIR=%~dp0%..\conf set ZOO_LOG_DIR=%~dp0%.. set ZOO_LOG4J_PROP=INFO,CONSOLE set CLASSPATH=%ZOOCFGDIR% set CLASSPATH=%~dp0..\*;%~dp0..\lib\*;%CLASSPATH% set CLASSPATH=%~dp0..\build\classes;%~dp0..\build\lib\*;%CLASSPATH% set ZOOCFG=%ZOOCFGDIR%\zoo.cfg set ZOOMAIN=org.apache.zookeeper.server.ZooKeeperServerMain java "-Dzookeeper.log.dir=%ZOO_LOG_DIR%" "-Dzookeeper.root.logger=%ZOO_LOG4J_PROP%" -cp "%CLASSPATH%" %ZOOMAIN% "%ZOOCFG%" %* endlocal |
在你执行启动脚本之前,还有几个基本的配置项需要配置一下,Zookeeper 的配置文件在 conf 目录下,这个目录下有 zoo_sample.cfg 和 log4j.properties,你需要做的就是将 zoo_sample.cfg 改名为 zoo.cfg,因为 Zookeeper 在启动时会找这个文件作为默认配置文件。下面详细介绍一下,这个配置文件中各个配置项的意义。
|
1
2
3
|
tickTime=2000 dataDir=D:/devtools/zookeeper-3.2.2/build clientPort=2181 |
- tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
- dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
- clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
当这些配置项配置好后,你现在就可以启动 Zookeeper 了,启动后要检查 Zookeeper 是否已经在服务,可以通过 netstat – ano 命令查看是否有你配置的 clientPort 端口号在监听服务。
集群模式
Zookeeper 不仅可以单机提供服务,同时也支持多机组成集群来提供服务。实际上 Zookeeper 还支持另外一种伪集群的方式,也就是可以在一台物理机上运行多个 Zookeeper 实例,下面将介绍集群模式的安装和配置。
Zookeeper 的集群模式的安装和配置也不是很复杂,所要做的就是增加几个配置项。集群模式除了上面的三个配置项还要增加下面几个配置项:
|
1
2
3
4
|
initLimit=5 syncLimit=2 server.1=192.168.211.1:2888:3888 server.2=192.168.211.2:2888:3888 |
- initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
- syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
- server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
除了修改 zoo.cfg 配置文件,集群模式下还要配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面就有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是那个 server。
数据模型
Zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统,如图 1 所示:
图 1 Zookeeper 数据结构

Zookeeper 这种数据结构有如下这些特点:
- 每个子目录项如 NameService 都被称作为 znode,这个 znode 是被它所在的路径唯一标识,如 Server1 这个 znode 的标识为 /NameService/Server1
- znode 可以有子节点目录,并且每个 znode 可以存储数据,注意 EPHEMERAL 类型的目录节点不能有子节点目录
- znode 是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据
- znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效,znode 也就删除了
- znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2
- znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基于这个特性实现的,后面在典型的应用场景中会有实例介绍
如何使用
Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储,但是 Zookeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理,后面将会详细介绍 Zookeeper 能够解决的一些典型问题,这里先介绍一下,Zookeeper 的操作接口和简单使用示例。
常用接口列表
客户端要连接 Zookeeper 服务器可以通过创建 org.apache.zookeeper. ZooKeeper 的一个实例对象,然后调用这个类提供的接口来和服务器交互。
前面说了 ZooKeeper 主要是用来维护和监控一个目录节点树中存储的数据的状态,所有我们能够操作 ZooKeeper 的也和操作目录节点树大体一样,如创建一个目录节点,给某个目录节点设置数据,获取某个目录节点的所有子目录节点,给某个目录节点设置权限和监控这个目录节点的状态变化。
这些接口如下表所示:
表 1 org.apache.zookeeper. ZooKeeper 方法列表
| 方法名 | 方法功能描述 |
|---|---|
| Stringcreate(String path, byte[] data, List<ACL> acl, CreateMode createMode) | 创建一个给定的目录节点 path, 并给它设置数据,CreateMode 标识有四种形式的目录节点,分别是 PERSISTENT:持久化目录节点,这个目录节点存储的数据不会丢失;PERSISTENT_SEQUENTIAL:顺序自动编号的目录节点,这种目录节点会根据当前已近存在的节点数自动加 1,然后返回给客户端已经成功创建的目录节点名;EPHEMERAL:临时目录节点,一旦创建这个节点的客户端与服务器端口也就是 session 超时,这种节点会被自动删除;EPHEMERAL_SEQUENTIAL:临时自动编号节点 |
| Statexists(String path, boolean watch) | 判断某个 path 是否存在,并设置是否监控这个目录节点,这里的 watcher 是在创建 ZooKeeper 实例时指定的 watcher,exists方法还有一个重载方法,可以指定特定的 watcher |
| Statexists(String path, Watcher watcher) | 重载方法,这里给某个目录节点设置特定的 watcher,Watcher 在 ZooKeeper 是一个核心功能,Watcher 可以监控目录节点的数据变化以及子目录的变化,一旦这些状态发生变化,服务器就会通知所有设置在这个目录节点上的 Watcher,从而每个客户端都很快知道它所关注的目录节点的状态发生变化,而做出相应的反应 |
| void delete(String path, int version) | 删除 path 对应的目录节点,version 为 -1 可以匹配任何版本,也就删除了这个目录节点所有数据 |
| List<String> getChildren(String path, boolean watch) | 获取指定 path 下的所有子目录节点,同样 getChildren方法也有一个重载方法可以设置特定的 watcher 监控子节点的状态 |
| StatsetData(String path, byte[] data, int version) | 给 path 设置数据,可以指定这个数据的版本号,如果 version 为 -1 怎可以匹配任何版本 |
| byte[] getData(String path, boolean watch, Stat stat) | 获取这个 path 对应的目录节点存储的数据,数据的版本等信息可以通过 stat 来指定,同时还可以设置是否监控这个目录节点数据的状态 |
| void addAuthInfo(String scheme, byte[] auth) | 客户端将自己的授权信息提交给服务器,服务器将根据这个授权信息验证客户端的访问权限。 |
| StatsetACL(String path, List<ACL> acl, int version) | 给某个目录节点重新设置访问权限,需要注意的是 Zookeeper 中的目录节点权限不具有传递性,父目录节点的权限不能传递给子目录节点。目录节点 ACL 由两部分组成:perms 和 id。 Perms 有 ALL、READ、WRITE、CREATE、DELETE、ADMIN 几种 而 id 标识了访问目录节点的身份列表,默认情况下有以下两种: ANYONE_ID_UNSAFE = new Id("world", "anyone") 和 AUTH_IDS = new Id("auth", "") 分别表示任何人都可以访问和创建者拥有访问权限。 |
| List<ACL> getACL(String path, Stat stat) | 获取某个目录节点的访问权限列表 |
除了以上这些上表中列出的方法之外还有一些重载方法,如都提供了一个回调类的重载方法以及可以设置特定 Watcher 的重载方法,具体的方法可以参考 org.apache.zookeeper. ZooKeeper 类的 API 说明。
基本操作
下面给出基本的操作 ZooKeeper 的示例代码,这样你就能对 ZooKeeper 有直观的认识了。下面的清单包括了创建与 ZooKeeper 服务器的连接以及最基本的数据操作:
清单 2. ZooKeeper 基本的操作示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// 创建一个与服务器的连接ZooKeeper zk = new ZooKeeper("localhost:" + CLIENT_PORT, ClientBase.CONNECTION_TIMEOUT, new Watcher() { // 监控所有被触发的事件 public void process(WatchedEvent event) { System.out.println("已经触发了" + event.getType() + "事件!"); } }); // 创建一个目录节点zk.create("/testRootPath", "testRootData".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); // 创建一个子目录节点zk.create("/testRootPath/testChildPathOne", "testChildDataOne".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT); System.out.println(new String(zk.getData("/testRootPath",false,null))); // 取出子目录节点列表System.out.println(zk.getChildren("/testRootPath",true)); // 修改子目录节点数据zk.setData("/testRootPath/testChildPathOne","modifyChildDataOne".getBytes(),-1); System.out.println("目录节点状态:["+zk.exists("/testRootPath",true)+"]"); // 创建另外一个子目录节点zk.create("/testRootPath/testChildPathTwo", "testChildDataTwo".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT); System.out.println(new String(zk.getData("/testRootPath/testChildPathTwo",true,null))); // 删除子目录节点zk.delete("/testRootPath/testChildPathTwo",-1); zk.delete("/testRootPath/testChildPathOne",-1); // 删除父目录节点zk.delete("/testRootPath",-1); // 关闭连接zk.close(); |
输出的结果如下:
|
1
2
3
4
5
6
7
8
|
已经触发了 None 事件! testRootData [testChildPathOne] 目录节点状态:[5,5,1281804532336,1281804532336,0,1,0,0,12,1,6] 已经触发了 NodeChildrenChanged 事件! testChildDataTwo 已经触发了 NodeDeleted 事件!已经触发了 NodeDeleted 事件! |
当对目录节点监控状态打开时,一旦目录节点的状态发生变化,Watcher 对象的 process 方法就会被调用。
ZooKeeper 典型的应用场景
Zookeeper 从设计模式角度来看,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式,关于 Zookeeper 的详细架构等内部细节可以阅读 Zookeeper 的源码
下面详细介绍这些典型的应用场景,也就是 Zookeeper 到底能帮我们解决那些问题?下面将给出答案。
统一命名服务(Name Service)
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。说到这里你可能想到了 JNDI,没错 Zookeeper 的 Name Service 与 JNDI 能够完成的功能是差不多的,它们都是将有层次的目录结构关联到一定资源上,但是 Zookeeper 的 Name Service 更加是广泛意义上的关联,也许你并不需要将名称关联到特定资源上,你可能只需要一个不会重复名称,就像数据库中产生一个唯一的数字主键一样。
Name Service 已经是 Zookeeper 内置的功能,你只要调用 Zookeeper 的 API 就能实现。如调用 create 接口就可以很容易创建一个目录节点。
配置管理(Configuration Management)
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。
像这样的配置信息完全可以交给 Zookeeper 来管理,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
图 2. 配置管理结构图

集群管理(Group Membership)
Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让“总管”知道。
Zookeeper 不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个“总管”,让这个总管来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。
它们的实现方式都是在 Zookeeper 上创建一个 EPHEMERAL 类型的目录节点,然后每个 Server 在它们创建目录节点的父目录节点上调用 getChildren(String path, boolean watch) 方法并设置 watch 为 true,由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 getChildren上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 也是同样的原理。
Zookeeper 如何实现 Leader Election,也就是选出一个 Master Server。和前面的一样每台 Server 创建一个 EPHEMERAL 目录节点,不同的是它还是一个 SEQUENTIAL 目录节点,所以它是个 EPHEMERAL_SEQUENTIAL 目录节点。之所以它是 EPHEMERAL_SEQUENTIAL 目录节点,是因为我们可以给每台 Server 编号,我们可以选择当前是最小编号的 Server 为 Master,假如这个最小编号的 Server 死去,由于是 EPHEMERAL 节点,死去的 Server 对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点,我们就选择这个节点为当前 Master。这样就实现了动态选择 Master,避免了传统意义上单 Master 容易出现单点故障的问题。
图 3. 集群管理结构图

这部分的示例代码如下,完整的代码请看附件:
清单 3. Leader Election 关键代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
void findLeader() throws InterruptedException { byte[] leader = null; try { leader = zk.getData(root + "/leader", true, null); } catch (Exception e) { logger.error(e); } if (leader != null) { following(); } else { String newLeader = null; try { byte[] localhost = InetAddress.getLocalHost().getAddress(); newLeader = zk.create(root + "/leader", localhost, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); } catch (Exception e) { logger.error(e); } if (newLeader != null) { leading(); } else { mutex.wait(); } } } |
共享锁(Locks)
共享锁在同一个进程中很容易实现,但是在跨进程或者在不同 Server 之间就不好实现了。Zookeeper 却很容易实现这个功能,实现方式也是需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
图 4. Zookeeper 实现 Locks 的流程图

同步锁的实现代码如下,完整的代码请看附件:
清单 4. 同步锁的关键代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
void getLock() throws KeeperException, InterruptedException{ List<String> list = zk.getChildren(root, false); String[] nodes = list.toArray(new String[list.size()]); Arrays.sort(nodes); if(myZnode.equals(root+"/"+nodes[0])){ doAction(); } else{ waitForLock(nodes[0]); } } void waitForLock(String lower) throws InterruptedException, KeeperException { Stat stat = zk.exists(root + "/" + lower,true); if(stat != null){ mutex.wait(); } else{ getLock(); } } |
队列管理
Zookeeper 可以处理两种类型的队列:
- 当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
- 队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。
同步队列用 Zookeeper 实现的实现思路如下:
创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 / synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。
用下面的流程图更容易理解:
图 5. 同步队列流程图

同步队列的关键代码如下,完整的代码请看附件:
清单 5. 同步队列
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
void addQueue() throws KeeperException, InterruptedException{ zk.exists(root + "/start",true); zk.create(root + "/" + name, new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); synchronized (mutex) { List<String> list = zk.getChildren(root, false); if (list.size() < size) { mutex.wait(); } else { zk.create(root + "/start", new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } } } |
当队列没满是进入 wait(),然后会一直等待 Watch 的通知,Watch 的代码如下:
|
1
2
3
4
5
6
7
8
|
public void process(WatchedEvent event) { if(event.getPath().equals(root + "/start") && event.getType() == Event.EventType.NodeCreated){ System.out.println("得到通知"); super.process(event); doAction(); } } |
FIFO 队列用 Zookeeper 实现思路如下:
实现的思路也非常简单,就是在特定的目录下创建 SEQUENTIAL 类型的子目录 /queue_i,这样就能保证所有成员加入队列时都是有编号的,出队列时通过 getChildren( ) 方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证 FIFO。
下面是生产者和消费者这种队列形式的示例代码,完整的代码请看附件:
清单 6. 生产者代码
|
1
2
3
4
5
6
7
8
9
|
boolean produce(int i) throws KeeperException, InterruptedException{ ByteBuffer b = ByteBuffer.allocate(4); byte[] value; b.putInt(i); value = b.array(); zk.create(root + "/element", value, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL); return true; } |
清单 7. 消费者代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
int consume() throws KeeperException, InterruptedException{ int retvalue = -1; Stat stat = null; while (true) { synchronized (mutex) { List<String> list = zk.getChildren(root, true); if (list.size() == 0) { mutex.wait(); } else { Integer min = new Integer(list.get(0).substring(7)); for(String s : list){ Integer tempValue = new Integer(s.substring(7)); if(tempValue < min) min = tempValue; } byte[] b = zk.getData(root + "/element" + min,false, stat); zk.delete(root + "/element" + min, 0); ByteBuffer buffer = ByteBuffer.wrap(b); retvalue = buffer.getInt(); return retvalue; } } } } |
总结
Zookeeper 作为 Hadoop 项目中的一个子项目,是 Hadoop 集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理 Hadoop 集群中的 NameNode,还有 Hbase 中 Master Election、Server 之间状态同步等。
本文介绍的 Zookeeper 的基本知识,以及介绍了几个典型的应用场景。这些都是 Zookeeper 的基本功能,最重要的是 Zoopkeeper 提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管理模型,而不仅仅局限于上面提到的几个常用应用场景。
认识Netty
什么是Netty?
Netty 是一个利用 Java 的高级网络的能力,隐藏其背后的复杂性而提供一个易于使用的 API 的客户端/服务器框架。
Netty 是一个广泛使用的 Java 网络编程框架(Netty 在 2011 年获得了Duke's Choice Award,见https://www.java.net/dukeschoice/2011)。它活跃和成长于用户社区,像大型公司 Facebook 和 Instagram 以及流行 开源项目如 Infinispan, HornetQ, Vert.x, Apache Cassandra 和 Elasticsearch 等,都利用其强大的对于网络抽象的核心代码。
以上是摘自《Essential Netty In Action》这本书,本文的内容也是本人读了这本书之后的一些整理心得,如有不当之处欢迎大虾们指正
Netty和Tomcat有什么区别?
Netty和Tomcat最大的区别就在于通信协议,Tomcat是基于Http协议的,他的实质是一个基于http协议的web容器,但是Netty不一样,他能通过编程自定义各种协议,因为netty能够通过codec自己来编码/解码字节流,完成类似redis访问的功能,这就是netty和tomcat最大的不同。
有人说netty的性能就一定比tomcat性能高,其实不然,tomcat从6.x开始就支持了nio模式,并且后续还有arp模式——一种通过jni调用apache网络库的模式,相比于旧的bio模式,并发性能得到了很大提高,特别是arp模式,而netty是否比tomcat性能更高,则要取决于netty程序作者的技术实力了。
为什么Netty受欢迎?
如第一部分所述,netty是一款收到大公司青睐的框架,在我看来,netty能够受到青睐的原因有三:
- 并发高
- 传输快
- 封装好
Netty为什么并发高
Netty是一款基于NIO(Nonblocking I/O,非阻塞IO)开发的网络通信框架,对比于BIO(Blocking I/O,阻塞IO),他的并发性能得到了很大提高,两张图让你了解BIO和NIO的区别:


从这两图可以看出,NIO的单线程能处理连接的数量比BIO要高出很多,而为什么单线程能处理更多的连接呢?原因就是图二中出现的Selector。
当一个连接建立之后,他有两个步骤要做,第一步是接收完客户端发过来的全部数据,第二步是服务端处理完请求业务之后返回response给客户端。NIO和BIO的区别主要是在第一步。
在BIO中,等待客户端发数据这个过程是阻塞的,这样就造成了一个线程只能处理一个请求的情况,而机器能支持的最大线程数是有限的,这就是为什么BIO不能支持高并发的原因。
而NIO中,当一个Socket建立好之后,Thread并不会阻塞去接受这个Socket,而是将这个请求交给Selector,Selector会不断的去遍历所有的Socket,一旦有一个Socket建立完成,他会通知Thread,然后Thread处理完数据再返回给客户端——这个过程是阻塞的,这样就能让一个Thread处理更多的请求了。
下面两张图是基于BIO的处理流程和netty的处理流程,辅助你理解两种方式的差别:


除了BIO和NIO之外,还有一些其他的IO模型,下面这张图就表示了五种IO模型的处理流程:

- BIO,同步阻塞IO,阻塞整个步骤,如果连接少,他的延迟是最低的,因为一个线程只处理一个连接,适用于少连接且延迟低的场景,比如说数据库连接。
- NIO,同步非阻塞IO,阻塞业务处理但不阻塞数据接收,适用于高并发且处理简单的场景,比如聊天软件。
- 多路复用IO,他的两个步骤处理是分开的,也就是说,一个连接可能他的数据接收是线程a完成的,数据处理是线程b完成的,他比BIO能处理更多请求,但是比不上NIO,但是他的处理性能又比BIO更差,因为一个连接他需要两次system call,而BIO只需要一次,所以这种IO模型应用的不多。
- 信号驱动IO,这种IO模型主要用在嵌入式开发,不参与讨论。
- 异步IO,他的数据请求和数据处理都是异步的,数据请求一次返回一次,适用于长连接的业务场景。
以上摘自Linux IO模式及 select、poll、epoll详解
Netty为什么传输快
Netty的传输快其实也是依赖了NIO的一个特性——零拷贝。我们知道,Java的内存有堆内存、栈内存和字符串常量池等等,其中堆内存是占用内存空间最大的一块,也是Java对象存放的地方,一般我们的数据如果需要从IO读取到堆内存,中间需要经过Socket缓冲区,也就是说一个数据会被拷贝两次才能到达他的的终点,如果数据量大,就会造成不必要的资源浪费。
Netty针对这种情况,使用了NIO中的另一大特性——零拷贝,当他需要接收数据的时候,他会在堆内存之外开辟一块内存,数据就直接从IO读到了那块内存中去,在netty里面通过ByteBuf可以直接对这些数据进行直接操作,从而加快了传输速度。
下两图就介绍了两种拷贝方式的区别,摘自Linux 中的零拷贝技术,第 1 部分


上文介绍的ByteBuf是Netty的一个重要概念,他是netty数据处理的容器,也是Netty封装好的一个重要体现,将在下一部分做详细介绍。
为什么说Netty封装好?
要说Netty为什么封装好,这种用文字是说不清的,直接上代码:
- 阻塞I/O
public class PlainOioServer {public void serve(int port) throws IOException {final ServerSocket socket = new ServerSocket(port); //1try {for (;;) {final Socket clientSocket = socket.accept(); //2System.out.println("Accepted connection from " + clientSocket);new Thread(new Runnable() { //3@Overridepublic void run() {OutputStream out;try {out = clientSocket.getOutputStream();out.write("Hi!\r\n".getBytes(Charset.forName("UTF-8"))); //4out.flush();clientSocket.close(); //5} catch (IOException e) {e.printStackTrace();try {clientSocket.close();} catch (IOException ex) {// ignore on close}}}}).start(); //6}} catch (IOException e) {e.printStackTrace();}}}
- 非阻塞IO
public class PlainNioServer {public void serve(int port) throws IOException {ServerSocketChannel serverChannel = ServerSocketChannel.open();serverChannel.configureBlocking(false);ServerSocket ss = serverChannel.socket();InetSocketAddress address = new InetSocketAddress(port);ss.bind(address); //1Selector selector = Selector.open(); //2serverChannel.register(selector, SelectionKey.OP_ACCEPT); //3final ByteBuffer msg = ByteBuffer.wrap("Hi!\r\n".getBytes());for (;;) {try {selector.select(); //4} catch (IOException ex) {ex.printStackTrace();// handle exceptionbreak;}Set<SelectionKey> readyKeys = selector.selectedKeys(); //5Iterator<SelectionKey> iterator = readyKeys.iterator();while (iterator.hasNext()) {SelectionKey key = iterator.next();iterator.remove();try {if (key.isAcceptable()) { //6ServerSocketChannel server =(ServerSocketChannel)key.channel();SocketChannel client = server.accept();client.configureBlocking(false);client.register(selector, SelectionKey.OP_WRITE |SelectionKey.OP_READ, msg.duplicate()); //7System.out.println("Accepted connection from " + client);}if (key.isWritable()) { //8SocketChannel client =(SocketChannel)key.channel();ByteBuffer buffer =(ByteBuffer)key.attachment();while (buffer.hasRemaining()) {if (client.write(buffer) == 0) { //9break;}}client.close(); //10}} catch (IOException ex) {key.cancel();try {key.channel().close();} catch (IOException cex) {// 在关闭时忽略}}}}}}
- Netty
public class NettyOioServer {public void server(int port) throws Exception {final ByteBuf buf = Unpooled.unreleasableBuffer(Unpooled.copiedBuffer("Hi!\r\n", Charset.forName("UTF-8")));EventLoopGroup group = new OioEventLoopGroup();try {ServerBootstrap b = new ServerBootstrap(); //1b.group(group) //2.channel(OioServerSocketChannel.class).localAddress(new InetSocketAddress(port)).childHandler(new ChannelInitializer<SocketChannel>() {//3@Overridepublic void initChannel(SocketChannel ch)throws Exception {ch.pipeline().addLast(new ChannelInboundHandlerAdapter() { //4@Overridepublic void channelActive(ChannelHandlerContext ctx) throws Exception {ctx.writeAndFlush(buf.duplicate()).addListener(ChannelFutureListener.CLOSE);//5}});}});ChannelFuture f = b.bind().sync(); //6f.channel().closeFuture().sync();} finally {group.shutdownGracefully().sync(); //7}}}
从代码量上来看,Netty就已经秒杀传统Socket编程了,但是这一部分博大精深,仅仅贴几个代码岂能说明问题,在这里给大家介绍一下Netty的一些重要概念,让大家更理解Netty。
Channel
数据传输流,与channel相关的概念有以下四个,上一张图让你了解netty里面的Channel。 Channel一览
Channel一览- Channel,表示一个连接,可以理解为每一个请求,就是一个Channel。
- ChannelHandler,核心处理业务就在这里,用于处理业务请求。
- ChannelHandlerContext,用于传输业务数据。
- ChannelPipeline,用于保存处理过程需要用到的ChannelHandler和ChannelHandlerContext。
- ByteBuf
ByteBuf是一个存储字节的容器,最大特点就是使用方便,它既有自己的读索引和写索引,方便你对整段字节缓存进行读写,也支持get/set,方便你对其中每一个字节进行读写,他的数据结构如下图所示:

他有三种使用模式:
- Heap Buffer 堆缓冲区
堆缓冲区是ByteBuf最常用的模式,他将数据存储在堆空间。 - Direct Buffer 直接缓冲区
直接缓冲区是ByteBuf的另外一种常用模式,他的内存分配都不发生在堆,jdk1.4引入的nio的ByteBuffer类允许jvm通过本地方法调用分配内存,这样做有两个好处- 通过免去中间交换的内存拷贝, 提升IO处理速度; 直接缓冲区的内容可以驻留在垃圾回收扫描的堆区以外。
- DirectBuffer 在 -XX:MaxDirectMemorySize=xxM大小限制下, 使用 Heap 之外的内存, GC对此”无能为力”,也就意味着规避了在高负载下频繁的GC过程对应用线程的中断影响.
- Composite Buffer 复合缓冲区
复合缓冲区相当于多个不同ByteBuf的视图,这是netty提供的,jdk不提供这样的功能。
除此之外,他还提供一大堆api方便你使用,在这里我就不一一列出了,具体参见ByteBuf字节缓存。
- Codec
Netty中的编码/解码器,通过他你能完成字节与pojo、pojo与pojo的相互转换,从而达到自定义协议的目的。
在Netty里面最有名的就是HttpRequestDecoder和HttpResponseEncoder了。
Netty入门教程2——动手搭建HttpServer
Netty入门教程3——Decoder和Encoder
Netty入门教程4——如何实现长连接
参考:
https://blog.csdn.net/paul_wei2008/article/details/19355681
https://blog.csdn.net/liweisnake/article/details/63251252
https://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/
https://www.jianshu.com/p/b9f3f6a16911
https://www.cnblogs.com/xuwc/p/8975776.html
dubbo基础学习总结的更多相关文章
- Dubbo -- 系统学习 笔记 -- 配置参考手册
Dubbo -- 系统学习 笔记 -- 目录 配置参考手册 <dubbo:service/> <dubbo:reference/> <dubbo:protocol/> ...
- Dubbo -- 系统学习 笔记 -- 入门
Dubbo -- 系统学习 笔记 -- 目录 入门 背景 需求 架构 用法 入门 背景 随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行, ...
- 死磕面试 - Dubbo基础知识37问(必须掌握)
作为一个JAVA工程师,出去项目拿20k薪资以上,dubbo绝对是面试必问的,即使你对dubbo在项目架构上的作用不了解,但dubbo的基础知识也必须掌握. 整理分享一些面试中常会被问到的dubbo基 ...
- salesforce 零基础学习(五十二)Trigger使用篇(二)
第十七篇的Trigger用法为通过Handler方式实现Trigger的封装,此种好处是一个Handler对应一个sObject,使本该在Trigger中写的代码分到Handler中,代码更加清晰. ...
- 如何从零基础学习VR
转载请声明转载地址:http://www.cnblogs.com/Rodolfo/,违者必究. 近期很多搞技术的朋友问我,如何步入VR的圈子?如何从零基础系统性的学习VR技术? 本人将于2017年1月 ...
- IOS基础学习-2: UIButton
IOS基础学习-2: UIButton UIButton是一个标准的UIControl控件,UIKit提供了一组控件:UISwitch开关.UIButton按钮.UISegmentedContro ...
- HTML5零基础学习Web前端需要知道哪些?
HTML零基础学习Web前端网页制作,首先是要掌握一些常用标签的使用和他们的各个属性,常用的标签我总结了一下有以下这些: html:页面的根元素. head:页面的头部标签,是所有头部元素的容器. b ...
- python入门到精通[三]:基础学习(2)
摘要:Python基础学习:列表.元组.字典.函数.序列化.正则.模块. 上一节学习了字符串.流程控制.文件及目录操作,这节介绍下列表.元组.字典.函数.序列化.正则.模块. 1.列表 python中 ...
- python入门到精通[二]:基础学习(1)
摘要:Python基础学习: 注释.字符串操作.用户交互.流程控制.导入模块.文件操作.目录操作. 上一节讲了分别在windows下和linux下的环境配置,这节以linux为例学习基本语法.代码部分 ...
随机推荐
- Java SE中的Synchronized
1 引言 在多线程并发的编程中Synchronized一直是元老级的角色,很多人会称呼它为重量级锁,但是随着Java SE1.6对Synchronized进行了各种优化以后,有些情况下它并不那么重了. ...
- axios中post传参方式
最近做vue项目,做图片上传的功能,使用get给后台发送数据,后台能收到,使用post给后台发送图片信息的时候,vue axios post请求发送图片base64编码给后台报错HTTP 错误 414 ...
- 多态 鸭子类型 反射 内置方法(__str__,__del__) 异常处理
''' 1什么是多态 多态指的是同一种/类事物的不同形态 2 为何要有多态 多态性:在多态的背景下,可以在不用考虑对象具体类型的前提下而直接使用对象 多态性的精髓:统一 多态性的好处: 1增加了程序的 ...
- Windows10 引导修复
[问题]最近遇到一些用户使用的操作系统为Win10,但是使用过程中由于错误系统优化.卸载软件错误.误删系统文件.windows更新错误等,影响系统BCD引导文件,造成开机出现该BCD蓝屏报错,如下图所 ...
- 解决ping不通win7主机
之前在路由器上ping笔记本发现ping不通,但是笔记本ping路由器通,也没多想.今天想起来可能是win7的防火墙作怪,以前上课虚拟机好像也是ping不通宿主机,但是宿主机能ping通虚拟机. 简单 ...
- axure原型设计
在上一个学期的学习中,我们已经初步学习了axure的使用方法,它可以为负责定义需求设计,功能和界面的人员能快速设计出所需产品. 引入:在我们想为软件设计原型的时候,纸质原型很难表达交互的界面,与此同时 ...
- 原生js移除或添加样式
样式效果如下,点击商品详情 添加样式active 代码 <!doctype html> <html lang="en"> <head> < ...
- Pycharm在运行过程中,查看每个变量的方法(show variables)跟终端一样显示变量
点击运行栏的这个灰色向下剪头: 在出现的窗口上,勾选上: 点击OK,重启Pycharm:接着点击Run窗口: 将Run的show variables图标勾选: 然后你就会发现,在右边出现了变量的窗口:
- 容器中的诊断与分析4——live diagnosis——LTTng
官网地址 LTTng 简介&使用实战 使用LTTng链接内核和用户空间应用程序追踪 简介: LTTng: (Linux Trace Toolkit Next Generation),它是用于跟 ...
- fusion使用——程序集绑定冲突工具
1.以管理员身份运行vs命令提示符 2.运行 fuslogvw 3.以管理员身份运行Powershell To Enable:(确保fusion日志的文件夹D:\FusionLog\的存在) Set- ...