LINUX 文件系统JBD ----深入理解Fsync
http://www.cnblogs.com/hustcat/p/3283955.html
http://www.cnblogs.com/zengkefu/p/5639200.html
http://www.cnblogs.com/zengkefu/p/4943836.html
http://www.cnblogs.com/zengkefu/p/5639200.html
http://blog.sina.com.cn/s/blog_8308bc810102uxhz.html
深入理解Fsync
1 介绍
数据库系统从诞生那天开始,就面对一个很棘手的问题,fsync的性能问题。组提交(group commit)就是为了解决fsync的问题。最近,遇到一个业务反映MySQL创建分区表很慢,仔细分析了一下,发现InnoDB在创建表的时候有很多fsync——每个文件会有4个fsync的调用。当然,并不每个fsync的开销都很大。
这里引出几个问题:
(1)问题1:为什么fsync开销相对都比较大?它到底做了什么?
(2)问题2:细心的人可以发现,第一次open数据文件后,第二次fsync的时间远远小于第1次调用fsync的时间,为什么?
(3)问题3:能否优化fsync?
来着这些疑问,一起来了解一下fsync。
2 原因分析
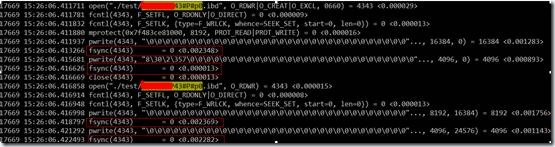
我们先通过一个测试程序来学习一下fsync在块层的基本流程。
2.1 测试程序1
|
Write page 0 Sleep 5 Fsync |
用blktrace跟踪结果如下:
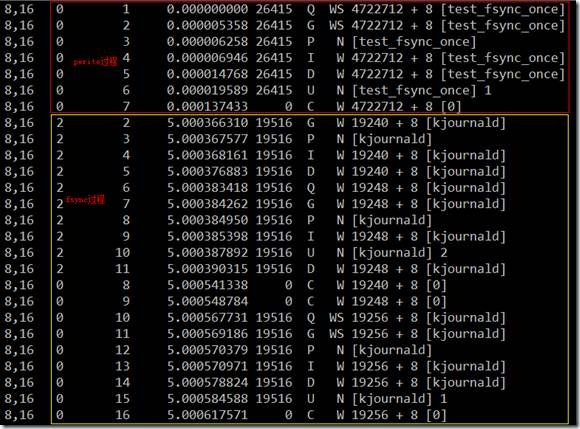
上半部红色框内为pwrite在块层的流程,下半部黄色框内为fsync在块层流程,中间刚好相差5秒。
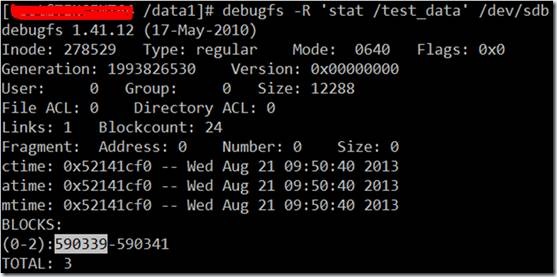
4722712为测试文件的第1个block对应的扇区号,590339(block号) * 8=4722712(扇区号)。
无论是pwrite,还是fsync,主要的开销都发生IO请求提交给驱动和IO完成之间,也就是说开自设备驱动。差不多占了整个系统调用的1/2的开销。
另外,可以看到调用fsync时,发生了3次块层IO,起始扇区分别是19240、19248和19256,物理上3个连续的块。实际上这3个块为内核线程kjournald写的日志,分别描述块(2405)、数据块(2406)和提交块(2407)。为了验证,不妨看一下这三个块的实际数据。
19240/8=2405
19248/8=2406
19256/8=2407
块2405:

|
#define JFS_MAGIC_NUMBER 0xc03b3998U #define JFS_DESCRIPTOR_BLOCK 1 #define JFS_COMMIT_BLOCK 2 |
开始的4个字节为JFS_MAGIC_NUMBER,然后是block type:JFS_DESCRIPTOR_BLOCK。
块2407:

的确是提交块。
2.2 fsync的实现
既然fsync的开销很大,就来看看代码吧。
函数ext3_sync_file:
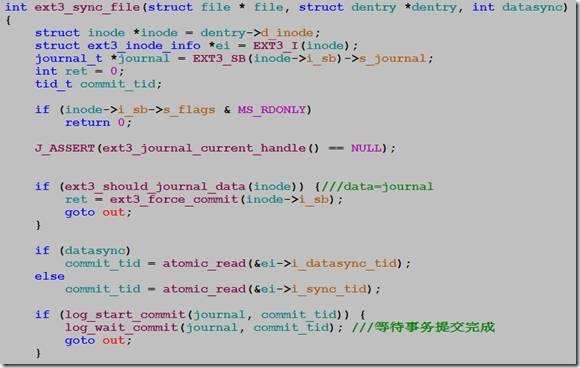
函数log_start_commit负责唤醒kjounald内核线程,log_wait_commit等待jbd事务提交完成。
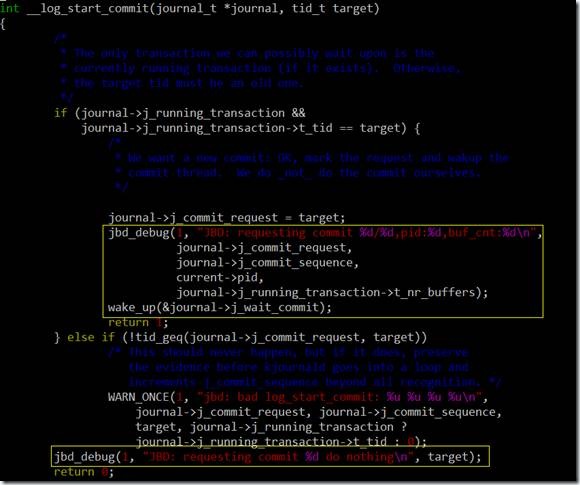
从代码来看,fsync的主要开销在于调用log_wait_commit后的等待。也就是说fsync要等待kjournald把事务提交完成,才会返回。
到这里,我们已经知道了fsync开销的主要来源:(1)硬件驱动层的开销;(2)ext3写日志。
另外,当log_start_commit返回0时,fsync就不会等待事务提交完成。到这里已经基本可以确认第2次fsync的开销为什么那么小了——没有wait事务提交。
下面验证这一想法。为了方便调试,打开了内核jbd debug日志。
2.3 测试程序2
|
Write page 0 Fsync Write page 0 Fsync Write page 1 Fsync Write page 2 Fsync |
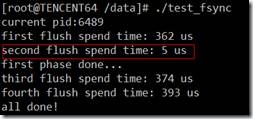
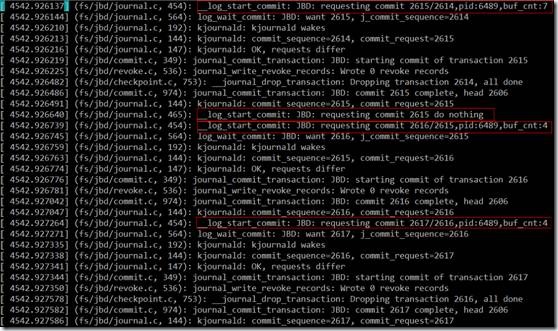
从第2个红框的日志来看,第2次fsync时,的确是没有wait的,所以开销这么小,而其它3次fsync都调用了log_wait_commit函数。
问题4:第2次fsync为什么不会调用log_wait_commit?
因为挂载文件系统的时候,data=writeback,即写数据本身不会写jbd日志。第2次pwrite没有引起文件扩展,只会修改ext3 inode的i_mtime,而i_mtime只精确到second,也就是说第2次pwrite不会引起inode信息改变,所以,不会生成jbd日志,也就不需要等待事务提交完成。
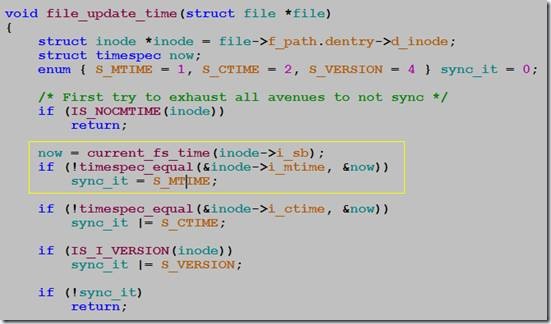
下面验证一下该想法。
2.4 测试程序3
|
Write page 0 Fsync Sleep 1 second Write page 0 Fsync Write page 1 Fsync Write page 2 Fsync |
在第2次pwrite之前,sleep 1秒钟,保证ext3 inode的i_mtime修改。
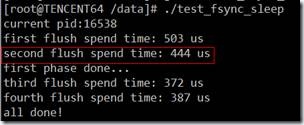
想法被证实了,第2次fsync的时间回到正常水平。
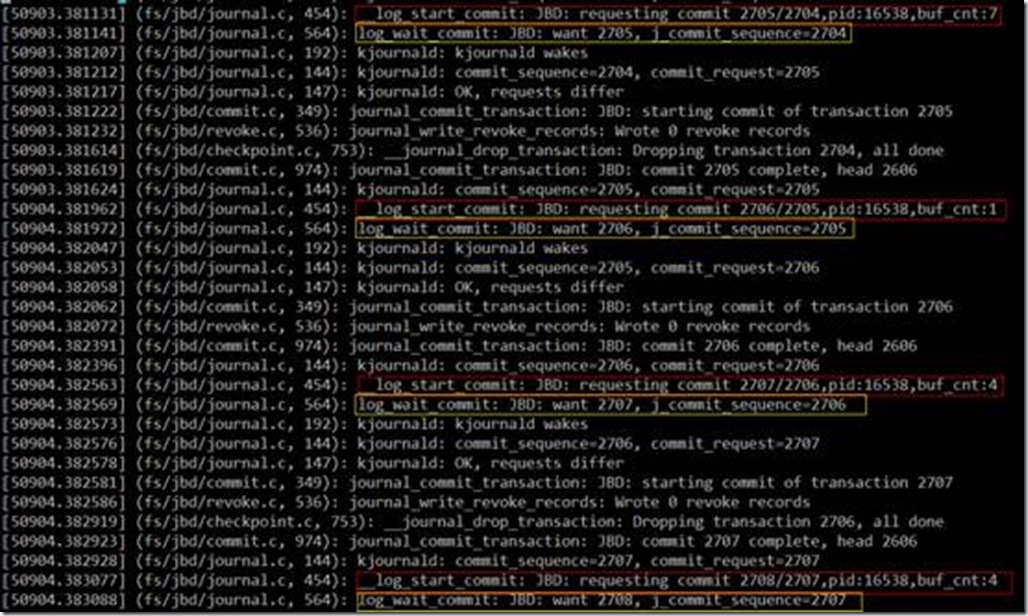
可以看到,第2次fsync调用提交了新的事务,并调用了log_wait_commit等待事务完成。
3 优化
如何优化fsync?是个难题。
(1)系统减少对fsync的调用。
(2)ext3日志放在更快的存储介质,参考http://insights.oetiker.ch/linux/external-journal-on-ssd/
作者:YY哥
出处:http://www.cnblogs.com/hustcat/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
[root@localhost ~]# debugfs -R "stat ./test" /dev/sda2
debugfs 1.39 (-May-)
Inode: Type: directory Mode: Flags: 0x0 Generation:
User: Group: Size:
File ACL: Directory ACL:
Links: Blockcount:
Fragment: Address: Number: Size:
ctime: 0x5768c427 -- Mon Jun ::
atime: 0x57725a43 -- Tue Jun ::
mtime: 0x5768c427 -- Mon Jun ::
BLOCKS:
():
TOTAL:
[root@localhost fs]# find / -name "*.c" | xargs grep "void file_update_time" -rn
/usr/src/debug/kernel-2.6./linux-2.6..x86_64/fs/inode.c::void file_update_time(struct file *file)
/usr/src/kernels/linux-2.6./fs/inode.c::void file_update_time(struct file *file)
void file_update_time(struct file *file)
{
struct inode *inode = file->f_path.dentry->d_inode;
struct timespec now;
enum { S_MTIME = , S_CTIME = , S_VERSION = } sync_it = ; /* First try to exhaust all avenues to not sync */
if (IS_NOCMTIME(inode))
return; now = current_fs_time(inode->i_sb);
if (!timespec_equal(&inode->i_mtime, &now))
sync_it = S_MTIME; if (!timespec_equal(&inode->i_ctime, &now))
sync_it |= S_CTIME; if (IS_I_VERSION(inode))
sync_it |= S_VERSION; if (!sync_it)
return; /* Finally allowed to write? Takes lock. */
if (mnt_want_write_file(file))
return; /* Only change inode inside the lock region */
if (sync_it & S_VERSION)
inode_inc_iversion(inode);
if (sync_it & S_CTIME)
inode->i_ctime = now;
if (sync_it & S_MTIME)
inode->i_mtime = now;
mark_inode_dirty_sync(inode);
mnt_drop_write(file->f_path.mnt);
}
EXPORT_SYMBOL(file_update_time);
[root@localhost jbd]# find / -name "*.c" | xargs grep "int __log_start_commit" -rn
/usr/src/debug/kernel-2.6./linux-2.6..x86_64/fs/jbd/journal.c::int __log_start_commit(journal_t *journal, tid_t target)
/usr/src/kernels/linux-2.6./fs/jbd/journal.c::int __log_start_commit(journal_t *journal, tid_t target)
int __log_start_commit(journal_t *journal, tid_t target)
{
/*
* Are we already doing a recent enough commit?
*/
if (!tid_geq(journal->j_commit_request, target)) {
/*
* We want a new commit: OK, mark the request and wakup the
* commit thread. We do _not_ do the commit ourselves.
*/ journal->j_commit_request = target;
jbd_debug(, "JBD: requesting commit %d/%d\n",
journal->j_commit_request,
journal->j_commit_sequence);
wake_up(&journal->j_wait_commit);
return ;
}
return ;
}
[root@localhost ~]# strace -f -F -T -r -p -e trace=write,open,read,fsync
Process attached with threads - interrupt to quit
[pid ] 0.000000 open("./test/h.frm", O_RDONLY) = <0.000049>
[pid ] 0.000492 read(, "\376\1\t\f\3\0\0\20\1\0\0000\0\0\20\0\5\0\0\0\0\0\0\0\0\0\0\2\10\0\10\0"..., ) = <0.000062>
[pid ] 0.000312 read(, "//\0\0 \0\0", ) = <0.000019>
[pid ] 0.000120 read(, "j\1\0\20\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., ) = <0.000019>
[pid ] 0.000154 read(, "\0\0\0\0\2\0\377\0", ) = <0.000020>
[pid ] 0.000299 read(, "5\0\2\1\2\24) "..., ) = <0.000018>
[pid ] 0.202203 fsync() = <0.003163>
[pid ] 0.003619 write(, "P\262yW\2\1\0\0\0O\0\0\0'\1\0\0\10\0\1\0\0\0\0\0\0\0\4\0\0!\0"..., ) = <0.000050>
[pid ] 0.060908 fsync() = <0.003123>
[pid ] 1.117089 fsync() = <0.005403>
[pid ] 0.008428 fsync() = <0.000019>
[pid ] 0.001892 fsync() = <0.000019>
[pid ] 0.001509 fsync() = <0.002887>
[pid ] 0.004133 fsync() = <0.000020>
[pid ] 0.002916 fsync() = <0.000021>
[pid ] 0.872229 fsync() = <0.005205>
[] EXT4 debugging support [ ] JBD (ext3) debugging support JDB调试支持 如果你正在使用Ext3日志文件系统(或者其他文件系统/设备可能会潜在使用JBD),这个选项可以让你在系统运行时开启调试输出,以便追踪任何错误。默认地这些调试输出是关闭的。 如果选Y,将可打开调试,使用echo N > /sys/kernel/debug/bd/jbd-debug,其中N是从1-5的数字,越高产生的调试输出越多。要再次关闭,使用echo > /sys/kernel/debug/jbd/jbd-debug [ ] JBD2 (ext4) debugging support JDB2调试支持 如果你正在使用Ext4日志文件系统(或者其他文件系统/设备可能会潜在使用JBD2),这个选项可以让你在系统运行时开启调试输出,以便追踪任何错误。默认地这些调试输出是关闭的。 如果选Y,将可打开调试,使用echo N > /sys/kernel/debug/bd2/jbd2-debug,其中N是从1-5的数字,越高产生的调试输出越多。要再次关闭,使用echo > /sys/kernel/debug/jbd2/jbd2-debug
journal block device代码分析
进入此门的肯定都对journal block device有一定了解,需要对ext3文件系统有了解,多余的就不赘述。
为什么要设计JBD?
普通数据是存在硬盘上的,文件系统也是作为普通数据存在硬盘上,类似如果碰到突然断电的情况,硬盘就可能损坏,硬件损坏,还是要硬件设计保证,软件设计(JBD)就是解决软件错误,断电可能会导致软件错误,举个例子,文件系统相当于常用的压缩文件,普通数据则是其中一个txt中的文字,如果压缩到一半被杀掉,如果txt中的文字损坏,压缩文件仍能解压,只是txt内容不同而已,但如果压缩文件的结构被损坏,很可能解压不来任何文件。而JBD就是防止文件系统的结构数据(元数据)被损坏,它作为一个缓存块先缓存所有的元数据,如果磁盘数据异常后,就从缓存块中恢复。

JBD的具体工作流程:
如上图示,kernel正常读写磁盘,读磁盘直接获取,写磁盘则走两条路,每个IO群(即事务),先写到jbd里面,然后在写磁盘,如果写磁盘被中断,则从jbd恢复,如果jbd被中断,OK,没影响。jbd本身数据存储到磁盘的一个用户态不可见位置,即日志空间,日志空间本身是一个文件系统结构的存储空间,有超级块,组描述符,位图等,估计所有数据系统都是类似结构。
基本原理就不说了,下面就以ext3_mkdir为例,描述jbd工作机制。
首先通过ext3_journal_start获取原子操作handle,(原子操作即操作不可分割的,只有完成态和未开始状态,不会停留在中间态,和atomic_inc不同,atomic加减是限制多线程冲突,handle则是保证完整性),具体细节可以参考ext3_journal_start函数,我对此的理解是,ext3_journal_start对handle进行了初始化,获取当前journal空间的数据,比如,空闲字节的开始位置。
|
1
2
3
|
handle = ext3_journal_start(dir, EXT3_DATA_TRANS_BLOCKS(dir->i_sb) +
EXT3_INDEX_EXTRA_TRANS_BLOCKS + 3 +
EXT3_MAXQUOTAS_INIT_BLOCKS(dir->i_sb));
|
在后面ext3_new_inode函数中见handle传递进入,在ext3_new_inode中申请新inode,需要修改位图,当然还有超级块和组描述符等,下面截取位图的写入作为一个描述:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
bitmap_bh = read_inode_bitmap(sb, group);
if (!bitmap_bh)
goto fail;
ino = 0;
repeat_in_this_group:
ino = ext3_find_next_zero_bit((unsigned long *)
bitmap_bh->b_data, EXT3_INODES_PER_GROUP(sb), ino);
if (ino < EXT3_INODES_PER_GROUP(sb)) {
BUFFER_TRACE(bitmap_bh, "get_write_access");
err = ext3_journal_get_write_access(handle, bitmap_bh);
if (err)
goto fail;
if (!ext3_set_bit_atomic(sb_bgl_lock(sbi, group),
ino, bitmap_bh->b_data)) {
/* we won it */
BUFFER_TRACE(bitmap_bh,
"call ext3_journal_dirty_metadata");
err = ext3_journal_dirty_metadata(handle,
bitmap_bh);
if (err)
goto fail;
goto got;
}
|
通过read_inode_bitmap获取位图数据bitmap_bh,用ext3_find_next_zero_bit算出空闲ino位置,用ext3_journal_get_write_access获取日志的写权限,更多的是将handle加入事务transaction管理,或者说将bitmap_bh加入到journal管理中,然后才开始进行具体的数据修改,也就是ext3_set_bit_atomic修改位图,修改完成使用ext3_journal_dirty_metadata标记为脏,即告诉journal本次handle操作结束,可以进行提交了。
ext3_new_inode下的组描述符也是类似,包括后面的目录项修改都是如此,也不赘述了。
需要提到的是,此处标记为脏的是元数据,非元数据使用ext3_journal_dirty_data函数,在ext3里面,如果发现当前数据是脏页,则直接进行刷新到磁盘,原因在注释中有描述。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
/*
* This buffer may be undergoing writeout in commit. We
* can't return from here and let the caller dirty it
* again because that can cause the write-out loop in
* commit to never terminate.
*/
if (buffer_dirty(bh)) {
get_bh(bh);
spin_unlock(&journal->j_list_lock);
jbd_unlock_bh_state(bh);
need_brelse = 1;
sync_dirty_buffer(bh);
jbd_lock_bh_state(bh);
spin_lock(&journal->j_list_lock);
/* Since we dropped the lock... */
if (!buffer_mapped(bh)) {
JBUFFER_TRACE(jh, "buffer got unmapped");
goto no_journal;
}
/* The buffer may become locked again at any
time if it is redirtied */
}
|
至此,一个使用journal的标准写入过程结束,后续的就是提交了。
jbd有常驻线程kjournald负责提交transaction,kjournald线程每个ext系列的分区分一个,主要部分通过调用journal_commit_transaction完成。需要插播一下,如果编译内核的时候打开CONFIG_JBD_DEBUG或者CONFIG_JBD2_DEBUG开关,就可以根据jbd-debug跟踪jbd的执行过程,有更直接的感觉,在代码实现上就是jbd_debug函数。
具体流程我建议打开debug开关后,对比着看,具体代码不梳理了,直接上图:
![]()
jbd前面所有设计都是为了此时的提交,需要留意的是此时设计的普通数据在元数据前进行提交,来保证ordered执行顺序。另外在之前写文件流程中提到ext3_ordered_write_end,中调用walk_page_buffers中journal_dirty_data_fn标记普通数据为脏,会将已脏的数据先用sync_dirty_buffer刷磁盘一下,可以对比参看。
最后则是出问题之后日志进行恢复:
journal恢复是在mount挂载磁盘的时候,ext3_fill_super()一直调用到journal_recover,判断是否进行日志恢复也是如下判断。
|
1
2
3
4
5
6
|
if (!sb->s_start) {
jbd_debug(1, "No recovery required, last transaction %dn",
be32_to_cpu(sb->s_sequence));
journal->j_transaction_sequence = be32_to_cpu(sb->s_sequence) + 1;
return 0;
}
|
即根据日志的超级块s_start参数是否为0判断。
整个恢复过程有3部分组成,都是调用do_one_pass,只是传参不同,第一步获取recovery_info信息,journal的起点和终点,journal是一个循环利用的环状存储介质。第二步获取REVOKE块,第三步PASS_REPLAY则根据描述符块将日志信息写到磁盘上。
另外提一下在工作中碰到一个案例:内核在写文件的时候发生了多次复位,根据内核黑匣子记录的信息,看到journal_bmap获取信息为0,日志被__journal_abort_soft中断 了,再写journal出现了panic。当时看以为bmap出现异常,中间读取有问题,后来把journal日志块倒出来看,对应的一个间接索引块里面全为0,在普通文件中是正常的,称为文件的洞,而日志则是格式化一开始就全分配了,而且顺序读取利用不应产生文件的洞。具体原因再也没找到,但是发现fsck不支持修改journal出现洞的问题,导致重复复位,后来找到社区高版本fsck比对一下,改了一个补丁,勉强算解决了问题。
以上都是开胃小菜,更多的请读代码,文章描述不细致的地方请参考jdb代码分析
—结束—
LINUX 文件系统JBD ----深入理解Fsync的更多相关文章
- 理解Linux文件系统之inode
很少转发别人的文章,但是这篇写的太好了. 理解inode 作者: 阮一峰 inode是一个重要概念,是理解Unix/Linux文件系统和硬盘储存的基础. 我觉得,理解inode,不仅有助于提高系统 ...
- 理解与学习linux 文件系统的目录结构
1. linux文件系统的结构 linux文件系统是以一种树形结构存在,Linux的文件系统的入口就是/,所有的目录.文件.设备都在/之下,/就是Linux文件系统的组织者,也是最上级的领导者. 2. ...
- [转]理解Linux文件系统之inode
很少转发别人的文章,但是这篇写的太好了. 理解inode 作者: 阮一峰 inode是一个重要概念,是理解Unix/Linux文件系统和硬盘储存的基础. 我觉得,理解inode,不仅有助于提高系统 ...
- Linux文件系统十问---深入理解文件存储方式(rhel6.5,EXT4)【转】
本文转载自:https://blog.csdn.net/tongyijia/article/details/52832236 前几天在红黑联盟上看了一篇博客<Linux文件系统十问—深入理解文件 ...
- Linux就这个范儿 第15章 七种武器 linux 同步IO: sync、fsync与fdatasync Linux中的内存大页面huge page/large page David Cutler Linux读写内存数据的三种方式
Linux就这个范儿 第15章 七种武器 linux 同步IO: sync.fsync与fdatasync Linux中的内存大页面huge page/large page David Cut ...
- Linux文件系统及常用命令
Linux文件系统介绍: 一 .Linux文件结构 文件结构是文件存放在磁盘等存贮设备上的组织方法.主要体现在对文件和目录的组织上.目录提供了管理文件的一个方便而有效的途径. Linux使用树状目录结 ...
- Linux文件系统应用---系统数据备份和迁移(用户角度)
1 前言 首先承诺:对于从Windows系统迁移过来的用户,困扰大家的 “Linux系统下是否可以把系统文件和用户文件分开到C盘和D盘中” 的问题也可以得到完满解决. 之前的文章对Linux的文 ...
- 【转】Linux 概念架构的理解
转:http://mp.weixin.qq.com/s?__biz=MzA3NDcyMTQyNQ==&mid=400583492&idx=1&sn=3b18c463dcc451 ...
- Linux文件系统的barrier:启用还是禁用
大多数当前流行的Linux文件系统,包括EXT3和EXT4,都将文件系统barrier作为一个增强的安全特性.它保护数据不被写入日记.但 是,在许多情况下,我们并不清楚这些barrier是否有用.本文 ...
随机推荐
- 布局(layout)文件图形界面不能显示:An error has occurred. See error log for more details. java.lang.NullPointe
#问题解析# Android工程中Layout文件夹下的布局文件图形界面无法显示,一般发生这种情况在导入工程操作后极易出现,因为可能eclipse使用的sdk版本不同,target类型不同,所用And ...
- Investigation of Different Nets and Layers
Investigation of Different Nets and Layers Overview of AlexNet (MIT Places | Flickr Finetuned | Oxfo ...
- QLGame 2d Engine源码地址
QLGame 2d Engine源码地址已经提交到github上,地址为:https://github.com/wsgzxl/QLGame2dEngine
- DDD领域驱动设计和实践(转载)
-->目录导航 一. DDD领域驱动设计介绍 1. 什么是领域驱动设计(DDD) 2. 领域驱动设计的特点 3. 如果不使用DDD? 4. 领域驱动设计的分层架构和构成要素 5. 事务脚本和领域 ...
- 使用php-emoji类让网页显示emoji表情
需要的材料: php-emoji类库的下载地址:https://github.com/iamcal/php-emoji 代码示例:(该代码来自官网) <?php include('emoji.p ...
- IIS中的Application.CommonAppDataPath
C:\ProgramData\Microsoft Corporation\Internet Information Services\7.5.7600.16385
- Apache / PHP 5.x Remote Code Execution Exploit
测试方法: 本站提供程序(方法)可能带有攻击性,仅供安全研究与教学之用,风险自负! /* Apache Magica by Kingcope */ /* gcc apache-magika.c -o ...
- python 默认的系统编码 sys.setdefaultencoding
python2.x的编码问题有时让人很头疼,一会ascii,一会unicode. 在脚本里多见这样的操作: import sys reload(sys) sys.setdefaultencoding( ...
- ARM学习笔记3——数据处理指令
一.数据处理指令概述 1.概念 数据处理指令是指对存放在寄存器中的数据进行处理的指令.主要包括算术指令.逻辑指令.比较与测试指令以及乘法指令 如果在数据处理指令前使用S前缀,指令的执行结果将会影响CP ...
- 洛谷1440 求m区间内的最小值
洛谷1440 求m区间内的最小值 本题地址:http://www.luogu.org/problem/show?pid=1440 题目描述 一个含有n项的数列(n<=2000000),求出每一项 ...