如何从0到1设计一个类Dubbo的RPC框架

之前分享了如何从0到1设计一个MQ消息队列,今天谈谈“如何从0到1设计一个Dubbo的RPC框架”,重点考验:
- 你对RPC框架的底层原理掌握程度。
- 以及考验你的整体RPC框架系统设计能力。
RPC和RPC框架
1.RPC(Remote Procedure Call)
即远程过程调用, 主要解决远程通信间的问题,不需要了解底层网络的通信机制。
2.RPC框架
RPC框架负责屏蔽底层的传输方式(TCP或者UDP)、序列化方式、以及通信细节。
实际使用中,并不需要关心底层通信细节和调用过程,让业务端专注于业务代码的实现。
国内大家熟知的PRC框架,阿里的HSF和Dubbo(开源)
Dubbo的发展由来
1. 业务规模小
比如早期一个应用Java War包,将所有功能都打包,部署在一个单机服务器,调用接口也比较方便,不涉及到任何分布式场景。

2.业务规模变大
随着业务的快速发展,业务越来越多、子系统也越来越多时。比如:淘宝的交易系统、商品系统、用户系统、评价系统…上百个系统的出现。

系统变得越来越复杂,业务代码依然耦合在一起。比如最早期的淘宝denali工程,包含所有业务系统的代码,就仅打包部署都需要很长的时间。
并且,随着每个业务线的快速发展,业务代码耦合在一起,上线后出现问题急需要回滚代码,拉分支、大量的代码merge工作,这个过程极其痛苦。
这个时候,你会发现技术已经成了业务的瓶颈,急需把业务单独抽离出来,各自单独部署。
3.Dubbo和HSF的出现
应用系统一旦涉及到拆分部署,问题就来了,急需一种高效的应用程序间的通讯手段来完成这种需求,这就会涉及到分布式远程调用。
于是,淘宝就把denali按照业务为单位拆分成了类似这样的系统:UM(UserManger)、SM(ShopManager)..等等几十个工程代码。
再按照业务为单位,把所有调用相关的接口以业务为单元进行拆分:UIC(用户中心服务)、SIC(店铺中心服务)…等等以业务为单位集群部署,按照业务提供服务。

所以,RPC的框架来了,阿里内部使用HSF,以及开源的RPC 框架:Dubbo。
RPC框架的核心设计
前面mikechen提到了RPC的核心目标:主要是解决分布式系统中服务之间的调用问题。
其实,走到这一步涉及的知识体系非常的多:要求对通信、远程调用、消息机制等有深入的理解和掌握,要求的都是从理论、硬件级、操作系统级以及所采用的语言的实现都有清楚的理解。
1.RPC框架三个核心角色
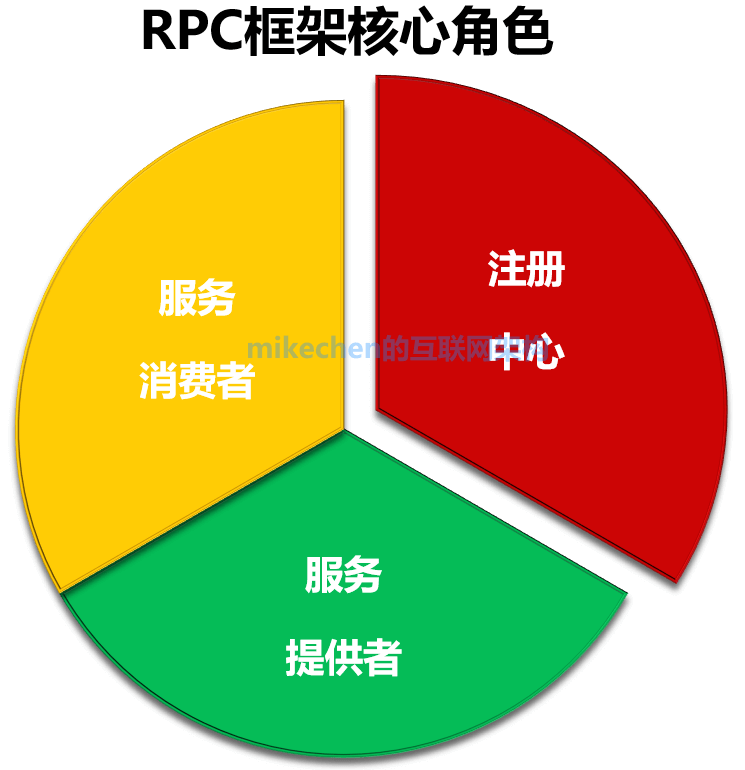
1)服务提供者(Server)
对外提供后台服务,将自己的服务信息,注册到注册中心
2)注册中心(Registry)
用于服务端注册远程服务以及客户端发现服务。
目前主要的注册中心可以借由 zookeeper,eureka,consul,etcd 等开源框架实现。
比如:阿里的Dubbo就是采用zookeeper实现注册中心。
3)服务消费者(Client)
从注册中心获取远程服务的注册信息,然后进行远程过程调用。
2.RPC远程调用过程

1)服务调用方(client)调用以本地调用方式调用服务;
2)client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;在Java里就是序列化的过程
3)client stub找到服务地址,并将消息通过网络发送到服务端;
4)server stub收到消息后进行解码,在Java里就是反序列化的过程;
5)server stub根据解码结果调用本地的服务;
6)本地服务执行处理逻辑;
7)本地服务将结果返回给server stub;
8)server stub将返回结果打包成消息,Java里的序列化;
9)server stub将打包后的消息通过网络并发送至消费方
10)client stub接收到消息,并进行解码, Java里的反序列化;
11)服务调用方(client)得到最终结果。
RPC框架的目标就是要2~10这些步骤都封装起来。
RPC框架涉及技术
1.建立通信
首先,要解决通讯的问题,主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。
2.服务寻址
1)服务注册
首先需要把服务注册到服务中心。其实就是在注册中心进行一个登记,注册中心存储了该服务的IP、端口、调用方式(协议、序列化方式)等。在zookeeper中,进行服务注册,实际上就是在zookeeper中创建了一个znode节点,该节点存储了上面所说的服务信息。
2)服务发现
服务消费者在第一次调用服务时,会通过注册中心找到相应的服务的IP地址列表,并缓存到本地,以供后续使用。当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从IP列表中取一个服务提供者的服务器调用服务。
3)注册服务
可靠的寻址方式(主要是提供服务的发现)是RPC的实现基石,比如可以zookeeper来实现注册服务等等。

- 服务提供者启动后主动向服务(注册)中心注册机器ip、端口以及提供的服务列表。
- 服务消费者启动时向服务(注册)中心获取服务提供方地址列表,可实现软负载均衡和Failover。
- 提供者需要定时向注册中心发送心跳,一段时间未收到来自提供者的心跳后,认为提供者已经停止服务,从注册中心上摘取掉对应的服务等等。
3.网络传输
数据传输采用什么协议,数据该如何序列化和反序列化
4.NIO通信
当前很多RPC框架都直接基于netty这一IO通信框架,比如阿里巴巴的HSF、dubbo,Hadoop Avro,推荐使用Netty 作为底层通信框架。
5.服务调用
比如:B机器进行本地调用(通过代理Proxy)之后得到了返回值,此时还需要再把返回值发送回A机器,同样也需要经过序列化操作,然后再经过网络传输将二进制数据发送回A机器,而当A机器接收到这些返回值之后,则再次进行反序列化操作
总之,要实现一个RPC不算难,难的是实现一个高性能高可靠的RPC框架,如果还想更加深入了解请查看Dubbo源码剖析,看看Dubbo是如何来解决这些难题。
关于作者:mikechen,十余年BAT架构经验,资深技术专家,曾任职阿里、淘宝、百度。
关注作者公众号:回复【架构】,即可查看mikechen互联网架构原创的300期+BAT架构技术系列文章与1000+大厂面试题答案合集。

如何从0到1设计一个类Dubbo的RPC框架的更多相关文章
- 高并发架构系列:如何从0到1设计一个类Dubbo的RPC框架
在过去持续分享的几十期阿里Java面试题中,几乎每次都会问到Dubbo相关问题,比如:“如何从0到1设计一个Dubbo的RPC框架”,这个问题主要考察以下几个方面: 你对RPC框架的底层原理掌握程度. ...
- 8.如何自己设计一个类似 Dubbo 的 RPC 框架?
作者:中华石杉 面试题 如何自己设计一个类似 Dubbo 的 RPC 框架? 面试官心理分析 说实话,就这问题,其实就跟问你如何自己设计一个 MQ 一样的道理,就考两个: 你有没有对某个 rpc 框架 ...
- 面试系列 30 如何自己设计一个类似dubbo的rpc框架
其实一般问到你这问题,你起码不能认怂,因为既然咱们这个课程是短期的面试突击训练课程,那我不可能给你深入讲解什么kafka源码剖析,dubbo源码剖析,何况我就算讲了,你要真的消化理解和吸收,起码个把月 ...
- 如何自己设计一个类似dubbo的rpc框架?
(1)上来你的服务就得去注册中心注册吧,你是不是得有个注册中心,保留各个服务的信息,可以用zookeeper来做,对吧 (2)然后你的消费者需要去注册中心拿对应的服务信息吧,对吧,而且每个服务可能会存 ...
- 第五十九届冠军(使用C++设计一个类不能被继承)
称号:使用C++设计一个类不能被继承. 分析:这是Adobe 公司2007 的笔试题最新校园招聘. 应聘者的C++基本功底外,还能考察反应能力,是一道非常好的题目. 分析:C++中父类的构造函数会调用 ...
- C++中如何设计一个类只能在堆或者栈上创建对象,面试题
设计一个类,该类只能在堆上创建对象 将类的构造函数私有,拷贝构造声明成私有.防止别人调用拷贝在栈上生成对象. 提供一个静态的成员函数,在该静态成员函数中完成堆对象的创建 注意 在堆和栈上创建对象都会调 ...
- 全图文分析:如何利用Google的protobuf,来思考、设计、实现自己的RPC框架
目录 一.前言 二.RPC 基础概念 1. RPC 是什么? 2. 需要解决什么问题? 3. 有哪些开源实现? 三.protobuf 基本使用 1. 基本知识 2. 使用步骤 四.libevent 1 ...
- 如何从0到1设计一个MQ消息队列
消息队列作为系统解耦,流量控制的利器,成为分布式系统核心组件之一. 如果你对消息队列背后的实现原理关注不多,其实了解消息队列背后的实现非常重要. 不仅知其然还要知其所以然,这才是一个优秀的工程师需要具 ...
- 手写一个类SpringBoot的HTTP框架:几十行代码基于Netty搭建一个 HTTP Server
本文已经收录进 : https://github.com/Snailclimb/netty-practical-tutorial (Netty 从入门到实战:手写 HTTP Server+RPC 框架 ...
随机推荐
- JDBC 处理sql查询多个不确定参数
JDBC程序,为了防止SQL注入,通常需要进行参数化查询,但是如果存在多个不确定参数,就比较麻烦了,查阅了一些资料,最后解决了这个问题,现在这里记录一下: public List<TabDl ...
- 金融云原生漫谈(三)|银行云原生基础设施构建:裸金属VS虚拟机
在金融行业数字化转型的驱动下,国有银行.股份制银行和各级商业银行也纷纷步入容器化的进程. 如果以容器云上生产为目标,那么整个容器云平台的设计.建设和优化对于银行来说是一个巨大的挑战.如何更好地利用 ...
- orleans集群及负载均衡实现
netcore6项目,微服务框架选orleans ,国内似乎没什么项目在用,坑多无资料.orleans文档可以解决几乎,只能看官方资料. Introduction | Microsoft Orlean ...
- Windows 和 Ubuntu 的网络能互相 ping 通之后,linux无法上网原因:①路由没设置好,②DNS 没设置好
确保 Windows 和 Ubuntu 的网络能互相 ping 通之后,如果 Ubuntu 无法上网,原因通常有 2 个:路由没设置好,DNS 没设置好. 如果执行以下命令不成功,表示路由没设置好: ...
- [ARM汇编]常用ARM汇编指令
- 基于World Wind的数据可视化插件
基于开源数据可视化类库(MSChart.VTK.D3)实现的组件样例,并基于World Wind实现调用上述组件的功能插件. GitHub下载地址:https://github.com/hujiuli ...
- c#操作符详解
操作符概览 操作符(Operator)也译为"运算符" 操作符是用来操作数据的,被操作符操作的数据称为操作数(Operand) 操作符的本质 操作符的本质是函数(即算法)的&quo ...
- VUE3 之 组件传参
1. 概述 韦奇定律告诉我们:大部分人都很容易被别人的话所左右,从而开始动摇.怀疑,最终迷失自我.因此我们要努力的坚定信念,相信自己,才不会被周围的环境所左右,才能取得最终的胜利. 言归正传,之前我们 ...
- Linux 学习2
1.配置好阿里云yum源生成yum缓存下载nginx,并且启动nginx服务,使用浏览器访问,nginx页面 yum源的工作目录是? https://www.cnblogs.com/dlh-lmsh/ ...
- pycharm 安装插件
1.使用pip安装插件 pip安装指定版本的插件: pip install openpyxl==2.6.2 -i https://pypi.doubanio.com/simple/ -i后面跟的是&q ...