Clickhouse Docker集群部署
写在前面
抽空来更新一下大数据的玩意儿了,起初架构选型的时候有考虑Hadoop那一套做数仓,但是Hadoop要求的服务器数量有点高,集群至少6台或以上,所以选择了Clickhouse(后面简称CH)。CH做集群的话,3台服务器起步就可以的,当然,不是硬性,取决于你的zookeeper做不做集群,其次CH性能更强大,对于量不是非常巨大的场景来说,单机已经足够应对OLAP多种场景了。
进入正题,相关环境:
| IP | 服务器名 | 操作系统 | 服务 | 备注 |
| 172.192.13.10 | server01 | Ubuntu20.04 | 两个Clickhouse实例、Zookeeper |
CH实例1端口:tcp 9000, http 8123, 同步端口9009,MySQL 9004, 类型: 主分片1 CH实例2端口:tcp 9000, http 8124, 同步端口9010,MySQL 9005, 类型: server02的副本 |
| 172.192.13.11 | server02 | Ubuntu20.04 | 两个Clickhouse实例、Zookeeper |
CH实例3端口:tcp 9000, http 8123, 同步端口9009,MySQL 9004, 类型: 主分片2 CH实例4端口:tcp 9000, http 8124, 同步端口9010,MySQL 9005, 类型: server03的副本 |
| 172.192.13.12 | server03 | Ubuntu20.04 | 两个Clickhouse实例、Zookeeper |
CH实例5端口:tcp 9000, http 8123, 同步端口9009,MySQL 9004, 类型: 主分片3 CH实例6端口:tcp 9000, http 8124, 同步端口9010,MySQL 9005, 类型: server01的副本 |
在每一台服务上都安装docker,docker里面分别安装有3个服务:ch-main,ch-sub,zookeeper_node,如图所示:

细心的已经看到,PORTS没有映射关系,这里是使用Docker host网络模式,模式简单并且性能高,避免了很多容器间或跨服务器的通信问题,这个踩了很久。
环境部署
1. 服务器环境配置
在每一台服务器上执行: vim /etc/hosts ,打开hosts之后新增配置:
172.192.13.10 server01
172.192.13.11 server02
172.192.13.12 server03
2.安装docker
太简单,略...
3.拉取clickhouse、zookeeper镜像
太简单,略...
Zookeeper集群部署
在每个服务器上你想存放的位置,新建一个文件夹来存放zk的配置信息,这里是 /usr/soft/zookeeper/ ,在每个服务器上依次运行以下启动命令:
server01执行:
docker run -d -p 2181:2181 -p 2888:2888 -p 3888:3888 --name zookeeper_node --restart always \
-v /usr/soft/zookeeper/data:/data \
-v /usr/soft/zookeeper/datalog:/datalog \
-v /usr/soft/zookeeper/logs:/logs \
-v /usr/soft/zookeeper/conf:/conf \
--network host \
-e ZOO_MY_ID=1 zookeeper
server02执行:
docker run -d -p 2181:2181 -p 2888:2888 -p 3888:3888 --name zookeeper_node --restart always \
-v /usr/soft/zookeeper/data:/data \
-v /usr/soft/zookeeper/datalog:/datalog \
-v /usr/soft/zookeeper/logs:/logs \
-v /usr/soft/zookeeper/conf:/conf \
--network host \
-e ZOO_MY_ID=2 zookeeper
server03执行:
docker run -d -p 2181:2181 -p 2888:2888 -p 3888:3888 --name zookeeper_node --restart always \
-v /usr/soft/zookeeper/data:/data \
-v /usr/soft/zookeeper/datalog:/datalog \
-v /usr/soft/zookeeper/logs:/logs \
-v /usr/soft/zookeeper/conf:/conf \
--network host \
-e ZOO_MY_ID=3 zookeeper
唯一的差别是: -e ZOO_MY_ID=* 而已。
其次,每台服务上打开 /usr/soft/zookeeper/conf 路径,找到 zoo.cfg 配置文件,修改为:
dataDir=/data
dataLogDir=/datalog
tickTime=2000
initLimit=5
syncLimit=2
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=0
maxClientCnxns=60 server.1=172.192.13.10:2888:3888
server.2=172.192.13.11:2888:3888
server.3=172.192.13.12:2888:3888
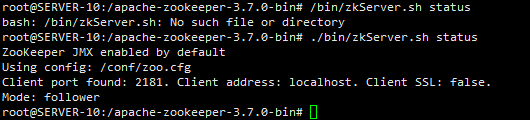
然后进入其中一台服务器,进入zk查看是否配置启动成功:
docker exec -it zookeeper_node /bin/bash
./bin/zkServer.sh status
Clickhouse集群部署
1.临时镜像拷贝出配置
运行一个临时容器,目的是为了将配置、数据、日志等信息存储到宿主机上:
docker run --rm -d --name=temp-ch yandex/clickhouse-server
拷贝容器内的文件:
docker cp temp-ch:/etc/clickhouse-server/ /etc/
//https://www.cnblogs.com/EminemJK/p/15138536.html
2.修改config.xml配置
//同时兼容IPV6,一劳永逸
<listen_host>0.0.0.0</listen_host> //设置时区
<timezone>Asia/Shanghai</timezone> //删除原节点<remote_servers>的测试信息
<remote_servers incl="clickhouse_remote_servers" /> //新增,和上面的remote_servers 节点同级
<include_from>/etc/clickhouse-server/metrika.xml</include_from> //新增,和上面的remote_servers 节点同级
<zookeeper incl="zookeeper-servers" optional="true" /> //新增,和上面的remote_servers 节点同级
<macros incl="macros" optional="true" />
其他 listen_host 仅保留一项即可,其他listen_host 则注释掉。
3.拷贝到其他文件夹
cp -rf /etc/clickhouse-server/ /usr/soft/clickhouse-server/main
cp -rf /etc/clickhouse-server/ /usr/soft/clickhouse-server/sub
main为主分片,sub为副本。
4.分发到其他服务器
#拷贝配置到server02上
scp /usr/soft/clickhouse-server/main/ server02:/usr/soft/clickhouse-server/main/
scp /usr/soft/clickhouse-server/sub/ server02:/usr/soft/clickhouse-server/sub/
#拷贝配置到server03上
scp /usr/soft/clickhouse-server/main/ server03:/usr/soft/clickhouse-server/main/
scp /usr/soft/clickhouse-server/sub/ server03:/usr/soft/clickhouse-server/sub/
SCP真香。
然后就可以删除掉临时容器: docker rm -f temp-ch
配置集群
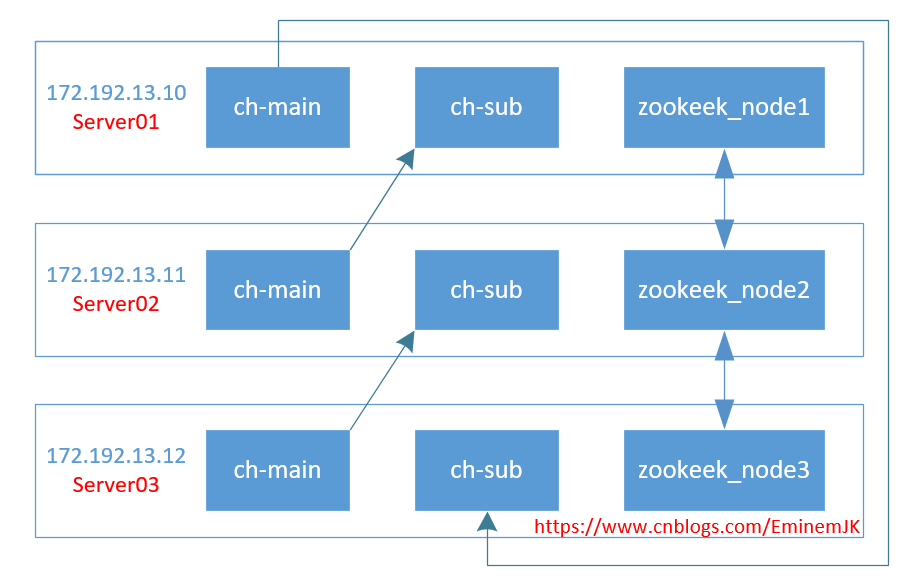
这里三台服务器,每台服务器起2个CH实例,环状相互备份,达到高可用的目的,资源充裕的情况下,可以将副本Sub实例完全独立出来,修改配置即可,这个又是Clickhouse的好处之一,横向扩展非常方便。
1.修改配置
进入server1服务器, /usr/soft/clickhouse-server/sub/conf 修改config.xml文件,主要修改内容:
原:
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<mysql_port>9004</mysql_port>
<interserver_http_port>9009</interserver_http_port> 修改为:
<http_port>8124</http_port>
<tcp_port>9001</tcp_port>
<mysql_port>9005</mysql_port>
<interserver_http_port>9010</interserver_http_port>
修改的目的目的是为了和主分片 main的配置区分开来,端口不能同时应用于两个程序。server02和server03如此修改或scp命令进行分发。
2.新增集群配置文件metrika.xml
server01,main主分片配置:
进入/usr/soft/clickhouse-server/main/conf 文件夹内,新增metrika.xml文件(文件编码:utf-8)。
<yandex>
<!-- CH集群配置,所有服务器都一样 -->
<clickhouse_remote_servers>
<cluster_3s_1r>
<!-- 数据分片1 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server01</host>
<port>9000</port>
<user>default</user>
<password></password>
</replica>
<replica>
<host>server03</host>
<port>9001</port>
<user>default</user>
<password></password>
</replica>
</shard>
<!-- 数据分片2 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server02</host>
<port>9000</port>
<user>default</user>
<password></password>
</replica>
<replica>
<host>server01</host>
<port>9001</port>
<user>default</user>
<password></password>
</replica>
</shard>
<!-- 数据分片3 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server03</host>
<port>9000</port>
<user>default</user>
<password></password>
</replica>
<replica>
<host>server02</host>
<port>9001</port>
<user>default</user>
<password></password>
</replica>
</shard>
</cluster_3s_1r>
</clickhouse_remote_servers> <!-- zookeeper_servers所有实例配置都一样 -->
<zookeeper-servers>
<node index="1">
<host>172.16.13.10</host>
<port>2181</port>
</node>
<node index="2">
<host>172.16.13.11</host>
<port>2181</port>
</node>
<node index="3">
<host>172.16.13.12</host>
<port>2181</port>
</node>
</zookeeper-servers> <!-- marcos每个实例配置不一样 -->
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-1</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks> <!-- 数据压缩算法 -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
<macros>节点每个服务器每个实例不同,其他节点配置一样即可,下面仅列举<macros>节点差异的配置。
server01,sub副本配置:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-2</replica>
</macros>
server02,main主分片配置:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-1</replica>
</macros>
server02,sub副本配置:
<macros>
<layer>01</layer>
<shard>03</shard>
<replica>cluster01-03-2</replica>
</macros>
server03,main主分片配置:
<macros>
<layer>01</layer>
<shard>03</shard>
<replica>cluster01-03-1</replica>
</macros>
server03,sub副本配置:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-01-2</replica>
</macros>
至此,已经完成全部配置,其他的比如密码等配置,可以按需增加。
集群运行及测试
在每一台服务器上依次运行实例,zookeeper前面已经提前运行,没有则需先运行zk集群。
运行main实例:
docker run -d --name=ch-main -p 8123:8123 -p 9000:9000 -p 9009:9009 --ulimit nofile=262144:262144 \
-v /usr/soft/clickhouse-server/main/data:/var/lib/clickhouse:rw \
-v /usr/soft/clickhouse-server/main/conf:/etc/clickhouse-server:rw \
-v /usr/soft/clickhouse-server/main/log:/var/log/clickhouse-server:rw \
--add-host server01:172.192.13.10 \
--add-host server02:172.192.13.11 \
--add-host server03:172.192.13.12 \
--hostname server01 \
--network host \
--restart=always \
yandex/clickhouse-server
运行sub实例:
docker run -d --name=ch-sub -p 8124:8124 -p 9001:9001 -p 9010:9010 --ulimit nofile=262144:262144 \
-v /usr/soft/clickhouse-server/sub/data:/var/lib/clickhouse:rw \
-v /usr/soft/clickhouse-server/sub/conf:/etc/clickhouse-server:rw \
-v /usr/soft/clickhouse-server/sub/log:/var/log/clickhouse-server:rw \
--add-host server01:172.192.13.10 \
--add-host server02:172.192.13.11 \
--add-host server03:172.192.13.12 \
--hostname server01 \
--network host \
--restart=always \
yandex/clickhouse-server
在每台服务器执行命令,唯一不同的参数是hostname,因为我们前面已经设置了hostname来指定服务器,否则在执行 select * from system.clusters 查询集群的时候,将 is_local 列全为0,则表示找不到本地服务,这是需要注意的地方。在每台服务器的实例都启动之后,这里使用正版DataGrip来打开:

在任一实例上新建一个查询:
create table T_UserTest on cluster cluster_3s_1r
(
ts DateTime,
uid String,
biz String
)
engine = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/T_UserTest', '{replica}')
PARTITION BY toYYYYMMDD(ts)
ORDER BY ts
SETTINGS index_granularity = 8192;
cluster_3s_1r是前面配置的集群名称,需一一对应上, /clickhouse/tables/ 是固定的前缀,相关语法可以查看官方文档了。
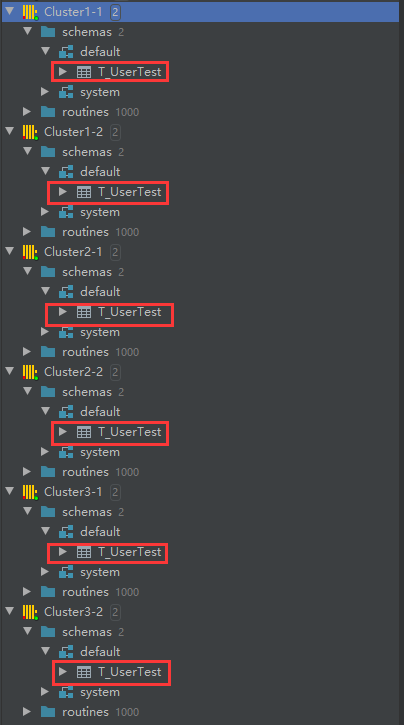
刷新每个实例,即可看到全部实例中都有这张T_UserTest表,因为已经搭建zookeeper,很容易实现分布式DDL。
继续新建Distributed分布式表:
CREATE TABLE T_UserTest_All ON CLUSTER cluster_3s_1r AS T_UserTest ENGINE = Distributed(cluster_3s_1r, default, T_UserTest, rand())
每个主分片分别插入相关信息:
--server01
insert into T_UserTest values ('2021-08-16 17:00:00',1,1)
--server02
insert into T_UserTest values ('2021-08-16 17:00:00',2,1)
--server03
insert into T_UserTest values ('2021-08-16 17:00:00',3,1)
然后查询分布式表 select * from T_UserTest_All ,

查询对应的副本表或者关闭其中一台服务器的docker实例,查询也是不受影响,时间关系不在测试。
最后
下班。
Clickhouse Docker集群部署的更多相关文章
- 27.Docker集群部署
对于scrapy的部署方式 1.Scrapyd 安装扩展组件,远程控制scrapy任务,包括部署源代码,启动任务,监听任务.scrapy-client .scrapyd api 协助完成部署和监听操作 ...
- RocketMQ(2)---Docker集群部署RocketMQ
RocketMQ(2)-Docker集群部署RocketMQ =前言= 1.因为自己只买了一台阿里云服务器,所以RocketMQ集群都部署在单台服务器上只是端口不同,如果实际开发,可以分别部署在多台服 ...
- Docker集群部署SpringCloud应用
整体架构 docker环境准备 # linux下的安装,自行百度 # windows docker toolbox下载地址 https://download.docker.com/win/stable ...
- Spring Eureka 本地Docker集群部署
故事背景 最近因为产线使用的服务与发现服务,使用的是Spring Cloud Eureka集群部署,为了以后调试产线的问题,想在本地搭建和产线一样的环境.产线的所有服务都是基于K8s和Docker部署 ...
- Kubernetes&Docker集群部署
集群环境搭建 搭建kubernetes的集群环境 环境规划 集群类型 kubernetes集群大体上分为两类:一主多从和多主多从. 一主多从:一台Master节点和多台Node节点,搭建简单,但是有单 ...
- docker集群部署
一.使用自定义网桥连接跨主机容器 要是Linux可以工作在网桥模式,必须安装网桥工具bridge-utils,运行命令:# yum install bridge-utils 查看桥连状态:# brct ...
- Nacos Docker集群部署
参考文档:https://nacos.io/zh-cn/docs/quick-start-docker.html 1.从git上下载nacos-docker项目,本地目录为/docksoft/naco ...
- 使用Docker构建持续集成与自动部署的Docker集群
为什么使用Docker " 从我个人使用的角度讲的话 部署来的更方便 只要构建过一次环境 推送到镜像仓库 迁移起来也是分分钟的事情 虚拟化让集群的管理和控制部署都更方便 hub.docke ...
- Clickhouse集群部署
1.集群节点信息 10.12.110.201 ch201 10.12.110.202 ch202 10.12.110.203 ch203 2. 搭建一个zookeeper集群 在这三个节点搭建一个zo ...
随机推荐
- java 的 IO简单理解
首先要先理解什么是 stream ? stream代表的是任何有能力产出数据的数据源,或是任何有能力接收数据的接收源. 一.不同导向的 stream 1)以字节为单位从 stream 中读取或往 st ...
- PDO之MySql持久化自动重连导致内存溢出
前言 最近项目需要一个常驻内存的脚本来执行队列程序,脚本完成后发现Mysql自动重连部分存在内存溢出,导致运行一段时间后,会超出PHP内存限制退出 排查 发现脚本存在内存溢出后排查了一遍代码,基本确认 ...
- 2013年第四届蓝桥杯C/C++程序设计本科B组省赛 第39级台阶
题目描述: 第39级台阶 小明刚刚看完电影<第39级台阶>,离开电影院的时候,他数了数礼堂前的台阶数,恰好是39级! 站在台阶前,他突然又想着一个问题: 如果我每一步只能迈上1个或2个台阶 ...
- fasthttp:比net/http快十倍的Go框架(server 篇)
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/574 我们在上一篇文章中讲解了 Go HTTP 标准库的实现原理,这 ...
- PYTHON找色不变移动
import cv2 import aircv as ac import numpy as np def wmhd(sjh): bzz0=0 bzz1=0 bzz2=0 xxa=0 yya=0 xxb ...
- LeetCode 847. Shortest Path Visiting All Nodes
题目链接:https://leetcode.com/problems/shortest-path-visiting-all-nodes/ 题意:已知一条无向图,问经过所有点的最短路径是多长,边权都为1 ...
- Map集合笔记
一.Map集合的特点 Map集合是一个双列集合 Map中的元素,key和value的数据类型可以相同,也可以不同. Map中的元素,key是允许重复的,value是可以重复的 Map中的元素,key和 ...
- Python+Requests+Re(正则)爬取某糗事百科图片(数据分析一)
1.博客目前在学习爬虫课程,使用正则表达式来爬取网页的图片信息 2.下面我们一起来回归下Python中的正则使用方式/方法 3.糗事百科图片爬取源码如下: import requestsimport ...
- PHP 多进程下载必应壁纸
手里拿着锤子,看什么都像是钉子 在放假的这几天,断断续续的看了老李关于 PHP 多进程的文章. PHP多进程初探 --- 开篇 PHP多进程初探 --- 孤儿和僵尸 PHP多进程初探 --- 信号 P ...
- 如何使用Scala的ClassTag
Scala官方文档中对于ClassTag的定义如下: ClassTag[T]保存着在运行时被JVM擦除的类型T的信息.当我们在运行时想获得被实例化的Array的类型信息的时候,这个特性会比较有用. 下 ...