【c++ Prime 学习笔记】第10章 泛型算法
- 标准库未给容器添加大量功能,而是提供一组独立于容器的
泛型算法算法:它们实现了一些经典算法的公共接口泛型:它们可用于不同类型的容器和不同类型的元素
- 利用这些算法可实现容器基本操作很难做到的事,例如查找/替换/删除特定值、重排顺序等
10.1 概述
大多数算法定义在
algorithm头文件中,另外一组数值算法定义在numeric头文件中标准库算法不直接操作容器,而是遍历两个迭代器指定的元素范围
指针就像内置数组上的迭代器,故泛型算法也可操作内置数组和指针
find算法:- 作用:将范围中每一个元素与给定值比较,返回第一个等于给定值的元素的迭代器,如果没有匹配则返回该范围的尾后迭代器。
- 用法:有3个参数,前2个是输入范围,第3个是给定值。
auto result = find(vec.cbegin(), vec.end.end(), val);
- 实现:调用给定值类型的
==算符来比较。
算法只依赖迭代器来访问元素并在范围中推进,不依赖于容器操作。但迭代器依赖元素类型上定义的算符,如
==、<等算法不会改变容器大小。它可能改变元素值或移动元素,但不会添加或删除。
标准库定义了
插入迭代器,给它们赋值时会在容器上插入。算法操作这样的迭代器时可完成插入元素的效果。count算法:- 作用:将范围中每一个元素与给定值比较,返回给定值在范围中出现的次数。
count(ivec.cbegin(), ivec.cend(), 6)
10.2 初识泛型算法
输入范围:大多标准库算法都对一个范围内的元素操作,这个范围称为输入范围。接受输入范围的算法总是用前两个参数来表示输入范围。- 多数算法遍历输入范围的方式相似,但使用元素的方法不同(是否读,是否写,是否重排等)。
10.2.1 只读算法
只读算法只读取输入范围的元素,不改变它们。如上一节的find和count- 使用只读算法,最好用cbegin/cend
accumulate算法(定义于numeric):- 作用:对范围中元素求和,再加上给定值,返回求值结果。
- 用法:有3个参数,前2个是输入范围,第3个是给定值。
- 实现:调用给定值类型的
+算符来求和。
int sum = sum=accumulate(vec.cbegin(),vec.cend(),0);vector<string> v={"hello","world"};string sum=accumulate(v.cbegin(),v.cend(),""); //错,const char *类型未定义+算符string sum=accumulate(v.cbegin(),v.cend(),string("")); //对,string上定义了+算符
equal算法:- 作用:确定两序列的值是否相同。所有元素都相等时返回true,否则false
- 用法:有3个参数,前2个是第一个序列的输入范围,第3个是第二个范围的首迭代器。
- 实现:调用
==算符来比较,元素类型不必严格一致。
//roster2 中的元素数目至少与roster1一样多//roster1 可以是vector<string>, roster2 可以是list<string>equal(roster1.cbegin(), roster1.cend(), roster2.cbegin())
10.2.2 写容器元素的算法
可对序列中元素重新赋值,要求原序列大小不小于要写入的元素数目。算法不执行容器操作,故不可改变序列大小
fill算法:- 作用:用给定值填满输入范围
- 用法:有3个参数,前2个是输入范围,第3个是给定值。
fill(vec.begin(), vec.end(),0);//每个元素置0vec.begin(), vec.begin() + vec.size()/2, 10); //部分元素置0
关键概念:迭代器参数
- 操作两序列的算法不要求两序列的容器相同,但要求元素可操作
算法不检查写操作
fill_n算法:- 作用:用给定值填满长为n的区间
- 用法:有3个参数,第1个代表序列起始的迭代器,第2个是序列长度的计数值,第3个是填入的给定值。
- fill_n假定长为n的空间总是有效的,类似指针运算。算法不会改变容器的大小。
vector<int> vec; //空vectorfill_n(vec.begin(),vec.size(),0); //将所有元素重置为0fill_n(vec.begin(),10,0); //错,算法不可向空vector写值fill_n(back_inserter(vec),10,0); //对,在vec尾部插入10个0
介绍 back_inserter
插入迭代器:给插入迭代器赋值会向容器中插入元素,即真正改变容器的大小。- 通过给插入迭代器赋值,算法可保证容器中总有足够的空间
back_inserter函数定义于iterator头文件中,它接受一个指向容器的引用,返回该容器的一个插入迭代器。通过此迭代器赋值时,赋值符会调用容器类型的push_back来添加元素
拷贝算法
copy算法- 作用:将输入范围的值拷贝到目标序列,返回目标序列的尾后迭代器
- 用法:有3个参数,前2个是输入范围,第3个是目标序列的起始位置
int a1[] = {0,1,2,3,4,5,6,7,8,9};int a2[sizeof(a1)/sizeof(*a1)];//ret 指向拷贝到a2的尾元素之后auto ret = copy(begin(a1), end(a2), a2);
replace算法- 作用:将序列中所有等于给定值的元素换为另一个值
- 用法:有4个参数,前2个是输入范围,后2个分别是要搜索的值和新值
replace_copy算法:- 作用:将序列中所有等于给定值的元素换为另一个值,放入新序列,原序列不变。
- 用法:有5个参数,前2个是输入范围,第3个是输出序列的首迭代器,最后2个分别是要搜索的值和新值
list<int> ilst={0,1,2,3,4};vector<int> ivec;//原址版本,将ilst中的0都替换为42replace(ilst.begin(),ilst.end(),0,42);//copy版本,将ilst中的0替换为42后插入ivec,ilst不变replace_copy(ilst.cbegin(),ilst.cend(),back_inserter(ivec),0,42);
10.2.3 重排容器元素的算法
- 可对容器中元素重新排列顺序
sort算法:- 作用:重排输入序列的元素使其有序
- 用法:有2个参数,是输入范围
- 实现:调用序列元素类型的
<算符
unique算法:- 作用:重排输入序列,消除相邻重复项。返回消除后的无相邻重复值的范围的尾后迭代器
- 用法:有2个参数,是输入范围
- unique不真正删除元素,只是将后面的不重复值前移来覆盖前面的重复值,使不重复值在序列前部。
- unique将不重复元素向首部集中,尾部(返回迭代器之后)的元素值是未定义
- 真正删除元素需要使用容器操作
//将输入vector中的string元素重排并消除重复void elimDups(vector<string> &words){sort(words.begin(),words.end()); //将元素排序,使重复项相邻//将不重复元素集中到序列前端,返回不重复元素序列的尾后迭代器auto end_unique=unique(words.begin(),words.end());words.erase(end_unique,words.end()); //擦除不重复序列之后的元素}
10.3 定制操作
- 对于使用元素的==、<等算符的算法,标准库允许在执行算法时用自定义操作代替默认算符,而不需要在类型中重载。
10.3.1 向算法传递函数
谓词:是一个可调用的表达式,其返回值可用作条件(即true/false)。按照参数的数量分为一元谓词和二元谓词- 接受谓词的算法用该谓词代替默认的算符来操作元素,故元素类型必须可转为谓词接受的参数类型。例如,接受二元谓词的sort用该谓词代替
<
bool isShorter(const string &s1, const string &s2){retrun s1.size() < s2.size();}sort(words.begin(), words.end(), isShorter);
stable_sort是稳定排序,即维持相等元素的原有顺序
10.3.2 lambda 表达式
find_if算法:- 作用:对输入范围的每个元素调用给定谓词,返回第一个使谓词非0的元素的迭代器
- 用法:有3个参数,前2个是输入范围,第3个是一元谓词
介绍 lambda
可调用对象:一个对象或表达式,若能使用调用运算符(),就是可调用的- 4种可调用对象:
函数、函数指针、重载了调用算符的类、lambda表达式
- 4种可调用对象:
- lambda表达式表示一个可调用的代码单元。一个lambda具有一个返回类型、一个参数列表和一个函数体。可定义在函数内部(函数不可)
- 形式
[capture list](parameter list) -> return type {function body}capture list捕获列表,lambda所在函数中定义的局部变量(通常为空)- parameter list、return type、function body与函数一样
- lambda必须用
尾置返回 - 可忽略形参列表和返回类型,但必须有捕获列表和函数体
- 若函数体不是单一return语句,则必须指定返回类型(否则为void)
lambda应用的场景:函数接口已固定,但要传入额外的参数,可用lambda的捕获列表。例如谓词中要获取局部变量时。
auto f=[]{return 42;};cout<<f()<<endl; //用调用算符使用lambda
向 lambda 传递参数
- 调用lambda时用实参初始化形参的方式和函数相同,但
lambda不可有默认实参 - lambda将局部变量包含在捕获列表中来访问它们,只有被捕获到的局部变量才可在函数体中被使用。但只有
局部非static变量才需要捕获,lambda可直接使用定义在当前函数之外的名字和局部static变量 for_each算法:- 作用:对输入范围的每个元素调用给定的可调用对象
- 用法:有3个参数,前2个是输入范围,第3个是可调用对象
//将输入vector中的string元素重排并消除重复void elimDups(vector<string> &words){sort(words.begin(),words.end()); //将元素排序,使重复项相邻auto end_unique=unique(words.begin(),words.end()); //将不重复元素集中到序列前端,返回不重复元素序列的尾后迭代器words.erase(end_unique,words.end()); //擦除不重复序列之后的元素}//计数并按字典序打印vector<string>中长度>=给定值的stringvoid biggies(vector<string> &words, vector<string>::size_type sz){//按字典排序并消除重复elimDups(words);//对字符串长度做稳定排序,长度相同的单词维持字典序//用lambda做二元谓词比较两元素stable_sort(words.begin(),words.end(),[](const string &a, const string &b){return a.size()<b.size();});//找到第一个长度>=sz的元素//用lambda做一元谓词比较元素和变量auto wc=find_if(words.begin(),words.end(),[sz](const string &a){return a.size()>=sz;});//计算长度>=sz的元素数目auto count=words.end()-wc;cout<<count<<" "<<(count>1)?("words"):("word")<<" of length "<<sz<<" or longer"<<endl;//打印长度>=sz的元素,每个元素后接一个空格//用lambda遍历元素for_each(wc,words.end(),[](const string &s){cout<<s<<" ";});cout<<endl;}
10.3.3 lambda 捕获和返回
lambda实际是匿名类:定义lambda时,编译器生成一个与其对应的未命名的类类型- 向函数传递lambda时,同时定义了一个新类型和该类型的一个对象,传递的参数就是该对象。用auto定义一个lambda初始化的变量时,该变量也是这种对象。
- 从lambda生成的类都有一个数据成员对应捕获到的变量。lambda的数据成员在创建时被初始化,即
被捕获的变量用于初始化lambda匿名对象的成员 - lambda捕获变量的方式可用
值捕获和引用捕获值捕获存在拷贝,且值捕获的变量是在lambda创建(lambda对象构造)时被拷贝,而不是调用时拷贝,故创建lambda后修改捕获变量不影响lambda中的值。- 使用
引用捕获时必须确保lambda执行时被捕获变量存在。例如,从函数中返回lambda时不可用引用捕获。
- 最佳实践:尽量减少捕获的变量,且避免捕获指针/引用
oid fcn1(){size_t v=42;auto f1=[v]{return v;}; //值捕获,创建lambda(构造lambda对象)auto f2=[&v]{return v;}; //引用捕获,创建lambda(构造lambda对象)v=0; //改变捕获变量的值auto j1=f1(); //j1是42,因为lambda创建时保存了捕获变量的拷贝auto j2=f2(); //j2是0,因为lambda创建时未拷贝捕获变量,只是建立了引用}
隐式捕获
隐式捕获:可让编译器根据lambda函数体中的代码来推断要捕获哪些变量。- 使用隐式捕获,需在捕获列表中写
&或=,分别对应引用捕获和值捕获 - 可混合使用隐式捕获和显式捕获,只需在捕获列表中写
&或=,再写显式捕获的变量,要求:- 捕获列表第一个元素必须是
&或=,指定默认为引用/值捕获 - 显式捕获的变量必须使用与隐式捕获不同的方式。即隐式引用捕获,则显式必须为值捕获,反之亦然
- 捕获列表第一个元素必须是
void print_strings(vector<strin> &words, ostream &os=cout, char c=' '){//c为显式值捕获,其他变量(os)为隐式引用捕获for_each(words.begin(),words.end(),[&,c](const string &s){os<<s<<c;});//os为显式引用捕获,其他变量(c)为隐式值捕获,等价于上一行for_each(words.begin(),words.end(),[=,&os](const string &s){os<<s<<c;});}

可变 lambda
- 可变lambda:普通lambda不会改变值捕获的变量的copy的值,但可变lambda可改变值捕获的变量的copy的值,只需在参数列表后使用关键字mutable
- 一个引用捕获变量是否可以修改依赖于此引用指向的是一个const 类型还是非 const 类型
void fcn3(){size_t v=42;auto f=[v]() mutable {return ++v;} //mutalbe,允许改变捕获到的copy的值v=0;auto j=f(); //j是43}void fcn4(){size_t v1=42;auto f2=[&v1]() mutable {return ++v1;}v1 = 0;auto j=f2(); //j是1}
指定 lambda 返回类型
- 若lambda函数体包含return之外的任何语句,则编译器推断它返回void,返回void的函数不能返回值,除非手动指定返回类型
- 为lambda指定返回类型时,必须使用
尾置返回 transform算法:- 作用:对输入范围的每个元素调用可调用对象,将返回值依次写入目标序列
- 用法:有4个参数,前2个是输入范围,第3个是目的序列的首迭代器,第4个是可调用对象
- transform写入的目标序列和输入序列可以相同,即可以向原址写入
- transform和for_each的区别:
- transform可进行非原址写,for_each不可(除非在可调用对象内写非原址目标)
- transform通过可调用对象的返回值写入,for_each在可调用对象内部操作
vector<int> vi={0,1,2,3,4};transform(vi.begin(),vi.end(),vi.begin(),[](int i){ return i < 0 ? -i : i;}); //取绝对值transform(vi.begin(),vi.end(),vi.begin(),[](int i)->int{if(i<0) return -i; else return i;}); //取绝对值
10.3.4 参数绑定
- 对于少数地方使用的简单操作用lambda,而多次调用时应该定义函数。
- 若lambda的捕获列表为空,可用函数替换它。但对于有捕获列表的lambda,很难用函数替换。因为不能在函数中定义函数,导致不能在不修改形参的前提下使用局部变量(例如标准库算法中的可调用对象,其形参必须固定)。
标准库bind函数
在
functional头文件中定义了bind函数,可看作通用的函数适配器。它接受一个可调用对象,生成新的可调用对象来适应原对象的参数列表(即改变可调用对象的调用接口)调用bind的形式为:
auto newCallable=bind(callable,arg_list);
callable是可调用对象,arg_list是逗号分隔的参数列表,对应callable的参数- 调用newCallable时,是在用arg_list的参数调用callable
- arg_list中的参数可包含占位符,即
_n,其中n是传入newCallable的第n个参数
绑定 check_size 的 sz 参数
auto check6=bind(check_size, -1, 6);string s="hello";bool b1=check6(s); //它会调用check_size(s, 6)auto wc = find_if(words.begin(), words.end(),[sz](const string &a));auto wc = find_if(words.begin(), words.end(),bind(check_size, -1, sz); //与上面等价
使用 placeholders 名字
名字
_n都定义于placeholders命名空间中,该命名空间又定义于std命名空间。同时,placeholders命名空间定义于functional头文件使用
using namespace namespace_name来说明希望所有来自namespace_name的名字都可在程序中直接使用using std::placeholders::_1; //这种形式比较麻烦using namespace std::placeholders;
bind 的参数
auto g=bind(f,a,b,_2,c,_1); //对g的定义,abc类似于lambda的捕获列表g(_1,_2); //调用gf(a,b,_2,c,_1); //等价于调用f
用bind 重排参数顺序
sort(words.begin(),words.end(),isShorter); //isShorter(A, B)sort(words.begin(),words.end(),bind(isShorter, _2, _1)); //isShorter(B, A)
绑定引用参数
- 默认下,bind的非占位符参数被
拷贝到可调用对象中,类似lambda中的值捕获 - 用
ref函数可实现lambda中的引用捕获 ref函数返回一个对象,该对象中包含输入的引用,且可拷贝。若需要包含const引用,则应用cref函数。ref和cref也定义于functional头文件中
/* 上下文:os是局部变量,引用输出流;c是局部变量,类型为char *///lambda实现,引用捕获输出流,值捕获字符for_each(words.begin(),words.end(),[&os,c](cons string &s){os<<s<<c;});//函数实现,要被标准库算法使用,需要用bind捕获os和costream &print(ostream &os, const string &s, char c){return os<<s<<c;}//错,os不可拷贝,不能用默认方式bindfor_each(words.begin(),words.end(),bind(print,os,_1,' '));//对,用ref返回的对象包含os引用且可拷贝for_each(words.begin(),words.end(),bind(print,ref(os),_1,' '));
10.4 再探迭代器
iterator头文件中定义了额外的迭代器:插入迭代器:被绑定到一个容器,赋值时向容器中插入元素流迭代器:绑定到输入输出流,用于遍历这个流反向迭代器:向后而不是向前移动,除forward_list外的所有标准库容器都有反向迭代器移动迭代器:不是拷贝元素,而是移动元素
10.4.1 插入迭代器
插入器是一种迭代器适配器,它接受一个容器,生成一个迭代器,可通过该迭代器向容器添加元素。- 通过插入迭代器赋值时,该迭代器调用对应的容器操作来向给定位置插入元素

- 插入迭代器有3种,区别在于插入的位置:
back_inserter函数:创建一个使用push_back的迭代器。front_inserter函数:创建一个使用push_front的迭代器。inserter函数:创建一个使用insert的迭代器。它接受迭代器作为第二个参数来指定位置。使用返回的迭代器时,插入的元素在指定位置之前
- 只有容器本身支持push_back/pus*h_front/insert,才可用back_inserter/front_inserter/inserter
auto it=inserter(c,iter); //iter是it的初始位置*it=val;//上一行等价于下两行it=c.insert(it,val); //先在it前插入,之后it指向插入元素。++it; //再递增it,使其与给定位置iter一致。list<int> lst={1,2,3,4};list<int> lst2, lst3;copy(lst.cbegin(), lst.cend(), front_inserter(lst2)); //lst2包含4 3 2 1copy(lst.cbegin(), lst.cend(), inserter(lst3, lst3.begin())); //lst3包含1 2 3 4
- 反复调用front_inserter插入元素的顺序与插入顺序相反,而back_inserter/inserter插入元素的顺序与插入顺序相同
- 插入迭代器的``和
++算符不会对迭代器做任何事。
10.4.2 iostream 迭代器
- iostream类型不是容器,但也可用迭代器操作:
istream_iterator:读输入流ostream_iterator:写输出流
istream_iterator 操作

- 创建流迭代器时需在模板参数中指定读写类型,使用时调用该类型的
<<、>>算符。流迭代器将其对应的流当作该类型的元素序列处理 - 创建istream_iterator时,可将其绑定到一个流。也可默认初始化为
尾后迭代器。 - 对于绑定到流的迭代器,一旦关联的流遇到文件末尾或IO错误,则迭代器等于尾后迭代器
istream_iterator<int> in_iter(cin); //in_iter绑定到cinistream_iterator<int> eof; //eof作为输入流的尾后迭代器//法1:先创建vector再依次读取数据、插入vector<int> vec;while(in_iter!=eof)vec.push_back(*in_iter++);//用迭代器从cin中读数据//法2:直接用输入流迭代器创建vectoristream_iterator<int> in_iter(cin), eof;vector<int> vec(in_iter,eof);//等价于上面3行
使用算法操作流迭代器
istream_iterator<int> in(cin), eof;cout<<accumulate(in,eof,0)<<endl; //将输入序列读为int并累加输出
istream_iterator 允许使用懒惰求值
- 标准库只保证在第一次解引用输入流迭代器之前完成从流中读数据的操作,而不一定在绑定时立即读取。如果从两个不同对象同步地读取一个流,或是创建流迭代器还未使用就销毁,则何时读取是重要的。
ostream_iterator 操作
- 创建ostream_iterator时有可选的第二个参数,必须是C风格字符串,在输出每个元素之后都输出该字符串。
- ostream_iterator创建时必须绑定到流,不允许空的或表示尾后位置的ostream_iterator
- ostream_iterator的``和
++算符不会对迭代器做任何事,因为输出操作自动递增。

```cppostream_iterator<int> out_iter(cout," ");//显式写出解引用和递增,建议该写法,与其他迭代器保持一致for (auto e:vec)*out_iter++=e;//忽略解引用和递增for (auto e:vec)out_iter=e;//调用copy打印vec中的元素copy(vec.begin(),vec.end(),out_iter);```
使用保留迭代器处理类类型
istream_iterator<Sales_item> item_iter(cin), eof;ostream_iterator<Sales_item> out_iter(cin, "\n");//将第一笔记录存在sum中,并读取下一条记录Sales_item sum = *item_iter++;while(item_iter != eof){if(item_iter->isbn()==sum.isbn())sum+ = *item_iter++; //将其加到sum上并读取下一条else {out_iter=sum;sum = *item_iter++;}}out_iter = sum;
10.4.3 反向迭代器
反向迭代器:在容器中从尾元素向首前元素移动,++移动到前一个元素--移动到后一个元素
- 除forward_list外的容器都有反向迭代器。可通过
rbgein、crbegin、rend、crend函数来得到指向首前元素和尾元素的迭代器 - 反向迭代器的作用是让算法透明地向前或向后处理容器,例如向sort传递反向迭代器可反向排序而不需修改算法或算符
sort(vec.begin(),vec.end()); //递增序sort(vec.rbegin(),vec.rend()); //递减序
反向迭代器需要递减运算符
- 反向迭代器只能从同时支持
++和-的迭代器来产生。故forward_list和流迭代器都无反向迭代器
反向迭代器和其他迭代器间的关系
- 反向迭代器的
base成员函数返回它对应的正向迭代器。特别的,rbegin对应的正向迭代器是end,rend对应的正向迭代器是begin - 反向迭代器比它对应的正向迭代器左偏一个位置,原因是左闭右开区间的特性。
[rit1,rit2)和[rit1.base(),rit2.base())表示的元素范围相同 - 从正向迭代器初始化反向迭代器,或是给反向迭代器赋值时,结果迭代器与原迭代器指向的元素不相同。
string line="FIRST,MIDDLE,LAST";//检测第一个','并打印auto comma=find(line.cbegin(),line.cend(),','); //检测第一个`,`cout<<string(line.cbegin(),comma)<<endl; //打印"FIRST"//检测最后一个','并打印auto rcomma=find(line.crbegin(),line.crend(),','); //检测最后一个`,`,只需修改迭代器类型,不需修改算法cout<<string(line.crbegin(),rcomma)<<endl; //打印"TSAL"cout<<string(rcomma.base(),line.cend())<<endl; //打印"LAST"
10.5 泛型算法结构
算法最基本的特性是要求迭代器可提供哪些操作(即可使用何种迭代器),算法所要求的迭代器可分为5个迭代器类别,每个算法都会对它的每个迭代器参数指明须提供哪类迭代器
输入迭代器只读、不写;单遍扫描,只能递增输出迭代器只写,不读;单遍扫描,只能递增前向迭代器可读写;多遍扫描,只能递增双向迭代器可读写,多遍扫描,可递增递减随机访问迭代器可读写,多遍扫描,支持全部迭代器运算
第一种算法的分类方式是按照是否读、写或是重排序列中的元素来分类
10.5.1 5类迭代器
输入迭代器- 操作:只可读不可写
- 算符:
==、!=、++、``、> - 访问:只能顺序访问,不保证迭代器的状态有效并再次访问元素。故只能单遍扫描
- 例子:
find和accumulate要求输入迭代器,isrteam_iterator是输入迭代器
输出迭代器- 操作:只可写不可读
- 算符:
++、`` - 访问:只能赋值一次,即只能单遍扫描
- 例子:用作目的位置的迭代器通常是输出迭代器,如
copy的第三个参数,osrteam_iterator
前向迭代器- 操作:可多次读写元素
- 算符:
==、!=、++、``、> - 访问:可多次读写元素,可保存迭代器状态,可对序列多次扫描
- 例子:
replace要求前向迭代器,forward_list的迭代器是前向迭代器
双向迭代器- 操作:可正反方向多次读写元素
- 算符:
==、!=、++、-、``、> - 访问:可多次读写元素,可保存迭代器状态,可对序列多次扫描
- 例子:
reverse要求双向迭代器,除forward_list外的容器迭代器都是双向迭代器
随机访问迭代器- 操作:常量时间内随机读写任意元素
- 算符:
==、!=、++、-、、`>`、`<`、`<=`、`>`、`>=`、`+`、`+=`、、=、[] - 访问:可多次读写元素,可保存迭代器状态,可对序列多次扫描
- 例子:
sort要求随机访问迭代器,array/deque/string/vector的迭代器、数组的指针都是随机访问迭代器
10.5.2 算法形参模式
- 大多数算法的形参具有下列4种形式之一:
alg(beg,end,others);alg(beg,end,dest,other);alg(beg,end,beg2,other);alg(beg,end,beg2,end2,other);
- 参数:
- beg和end表示操作的输入范围
- dest是算法可写入目的位置的迭代器,假定写入任意多个元素都安全。因此dest经常被绑定到插入迭代器或输出流迭代器
- beg2表示操作的第二个输入范围,假定从beg2开始的序列至少和beg到end的长度一样长
- beg2和end2表示操作的第二个输入范围,对这种指定没有限制
10.5.3 算法命名规范
一些算法使用重载形式传递一个谓词
unique(beg, end); //使用 == 运算符比较元素unique(beg, end, comp); //使用 comp 比较元素
_if版本
接受一个元素值的算法通常由另一个不同名的版本,该版本接受一个谓词。
find(beg, end, val); //查找范围中val第一次出现的位置find_if(beg, end, pred); //查找第一个令pred为真的元素
区分拷贝元素的版本和不拷贝元素的版本
- 输出到目标位置,而不是原址
reverse(beg,end); //逆序写入原址reverse_copy(bed,end,dest); //逆序拷贝到dest
- 一些算法同时提供
_if和_copy版本,这些版本接受一个目的位置和一个谓词
//从v1中移除奇数remove_if(v1.begin(),v1.end(),[](int i){return i%2;});//将v1中移除奇数后剩下的拷贝到v2,v1不变remove_copy_if(v1.begin(),v1.end(),back_inserter(v2),[](int i){return i%2;});
10.6 特定容器算法
- 与其他容器不同,链表类型
list和forward_list定义了几个成员函数形式的算法,如sort、merge、remove、reverse、unuque。- 通用sort要求随机访问迭代器,不可用于
list(双向迭代器)和forward_list(前向迭代器) - 链表类型定义的其他算法的通用版本可用于链表,但交换元素代价太高。链表可交换指针而不是交换元素,可提高性能。
- 通用sort要求随机访问迭代器,不可用于

splice 成员
- 表类型特有的算法有splice,用于拼接链表,该算法没有通用版本
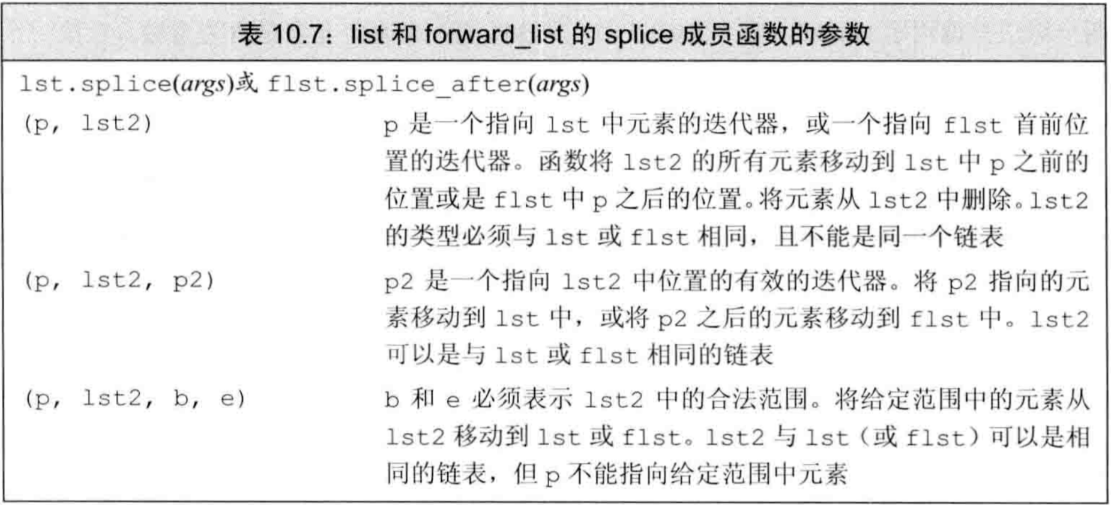
链表特有的操作会改变容器
- 链表特有算法与通用算法的一个区别是:链表特有的算法会改变底层容器,通用算法不会
【c++ Prime 学习笔记】第10章 泛型算法的更多相关文章
- 《C++ Primer》笔记 第10章 泛型算法
迭代器令算法不依赖于容器,但算法依赖于元素类型的操作. 算法永远不会执行容器的操作.算法永远不会改变底层容器的大小. accumulate定义在头文件numeric中,接受三个参数,前两个指出需要求和 ...
- <<Python基础教程>>学习笔记 | 第10章 | 充电时刻
第10章 | 充电时刻 本章主要介绍模块及其工作机制 ------ 模块 >>> import math >>> math.sin(0) 0.0 模块是程序 一个简 ...
- C++ Primer 5th 第10章 泛型算法
练习10.1:头文件algorithm中定义了一个名为count的函数,它类似find,接受一对迭代器和一个值作为参数.count返回给定值在序列中出现的次数.编写程序,读取int序列存入vector ...
- [C++ Primer] : 第10章: 泛型算法
概述 泛型算法: 称它们为"算法", 是因为它们实现了一些经典算法的公共接口, 如搜索和排序; 称它们是"泛型的", 是因为它们可以用于不同类型的元素和多种容器 ...
- HTML5与CSS3基础教程第八版学习笔记7~10章
第七章,CSS构造块 CSS里有控制基本格式的属性(font-size,color),有控制布局的属性(position,float),还有决定访问者打印时在哪里换页的打印控制元素.CSS还有很多控制 ...
- Oracle涂抹oracle学习笔记第10章Data Guard说,我就是备份
DG 是备份恢复工具,但是更加严格的意义它是灾难恢复 Data Guard是一个集合,由一个Primary数据库及一个或者多个Standby数据库组成,分两类逻辑Standby和物理Standby 1 ...
- 《机器学习实战》学习笔记第十一章 —— Apriori算法
主要内容: 一.关联分析 二.Apriori原理 三.使用Apriori算法生成频繁项集 四.从频繁项集中生成关联规则 一.关联分析 1.关联分析是一种在大规模数据集中寻找有趣关系的任务.这些关系可以 ...
- CSS3秘笈第三版涵盖HTML5学习笔记1~5章
第一部分----CSS基础知识 第1章,CSS需要的HTML HTML越简单,对搜索引擎越友好 div是块级元素,span是行内元素 <section>标签包含一组相关的内容,就像一本书中 ...
- 【c++ Prime 学习笔记】目录索引
第1章 开始 第Ⅰ部分 C++基础 第2章 变量和基本类型 第3章 字符串.向量和数组 第4章 表达式 第5章 语句 第6章 函数 第7章 类 第 Ⅱ 部分 C++标准库 第8章 IO库 第9章 顺序 ...
随机推荐
- shutdown 命令
# shutdown -h #停止系统服务并关机 -r #停止系统服务后重启 shutdown -h now #立即关机 shutdown -h 10:53 #到10:53关机,如果该时间小于当前时间 ...
- 性能测试必备命令(2)- uptime
性能测试必备的 Linux 命令系列,可以看下面链接的文章哦 https://www.cnblogs.com/poloyy/category/1819490.html 介绍 系统启动up了(运行了)多 ...
- Servlet处理带尾部斜杠/的URI
有一个需求:让一个Servlet能够同时处理形如/XXX/YYY和/XXX/YYY/的URI,即URI尾部的斜杠有没有都要能处理到. 很容易想到,做两个URL Pattern/XXX/YYY和/XXX ...
- EL-ADMIN学习笔记
一,支持接口限流,避免恶意请求导致服务层压力过大 常见的限流功能一般有两个关注点: 1.限流原则,即以什么样的条件对请求进行识别以及放行.常见的作法是给予每个调用API的系统不同的唯一编码,用于监控某 ...
- Java日期时间API系列42-----一种高效的中文日期格式化和解析方法
中文日期(2021年09月11日 和 二〇二一年九月十一日 )在生活中经常用到,2021年09月11日很好处理直接使用模板:yyyy年MM月dd日:二〇二一年九月十一日比较不好处理,需要每个数字进行转 ...
- 计算机网络-HTTP篇
目录 计算机网络-HTTP篇 HTTP的一些问题 HTTP 基本概念 常见状态码 常见字段 Get 与 Post HTTP 特性 HTTP(1.1) HTTP/1.1 HTTPS 与 HTTP HTT ...
- 动态规划精讲(一)LC 最长递增子序列的个数
最长递增子序列的个数 给定一个未排序的整数数组,找到最长递增子序列的个数. 示例 1: 输入: [1,3,5,4,7]输出: 2解释: 有两个最长递增子序列,分别是 [1, 3, 4, 7] 和[1, ...
- DP之背包经典三例
0/1背包 HDU2602 01背包(ZeroOnePack): 有N件物品和一个容量为V的背包,每种物品均只有一件.第i件物品的费用是c[i],价值是w[i].求解将哪些物品装入背包可使价值总和最大 ...
- 猪齿鱼 SaaS 版效能平台发布
日前,猪齿鱼Choerodon全场景效能平台Saas版发布,提供体系化方法论和协作.测试.DevOps及容器工具,帮助企业拉通需求.设计.开发.部署.测试和运营流程,一站式提高管理效率和质量.从团队 ...
- Java基础系列(16)- Scanner进阶使用
了解更多的sanner方法 Ctrl+鼠标左键,点击[Scanner] 点击Structure 看到了Scanner类下面的所有方法,以及具体方法实现的底层封装逻辑 拓展例子_nextInt()获取和 ...