传统 BI 如何转大数据数仓
前几天建了一个数据仓库方向的小群,收集了大家的一些问题,其中有个问题,一哥很想去谈一谈——现在做传统数仓,如何快速转到大数据数据呢?其实一哥知道的很多同事都是从传统数据仓库转到大数据的,今天就结合身边的同事经历来一起分享一下。
数据仓库
数据仓库:数据仓库系统的主要应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。也就是说,数据仓库汇总有可能有很多维度数据的统计分析结果,取百家之长(各个数据源的数据),成就自己的一方天地(规划各种业务域的模型,指标)。可以参考之前的文章《数据仓库的前世今生》
传统数据仓库开发
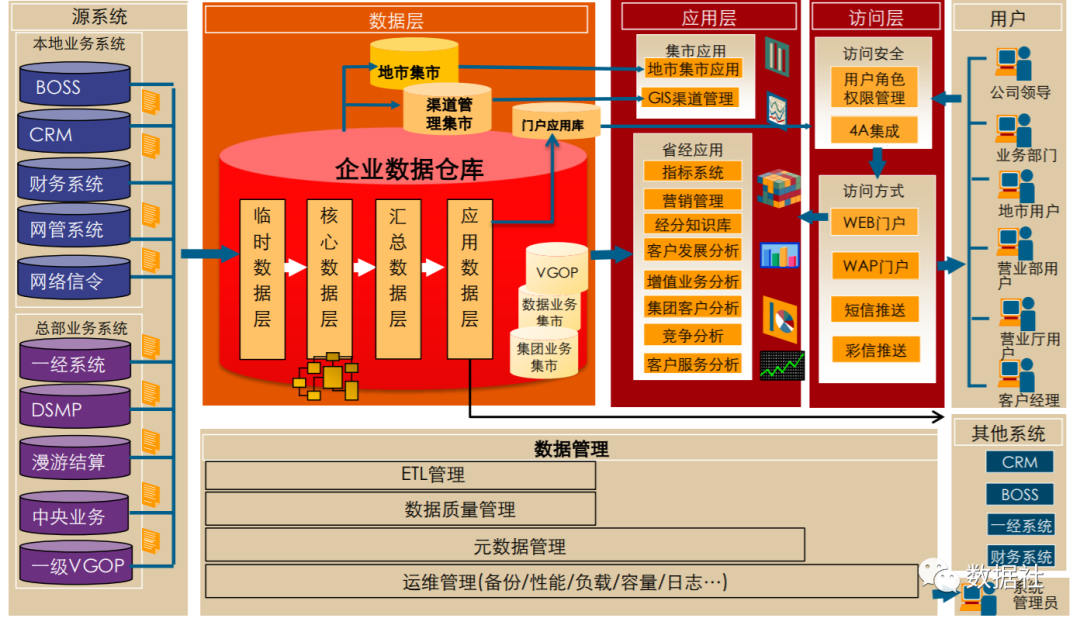
传统的数据仓库用Oracle的居多,多半是单机或者一个双机环境运行。本身硬件,系统都容易形成单点故障。慢慢发展,应该会开始通过存储形成容灾的一个环境。
我了解的传统的数据开发一般分为3个岗位:数据工程师、ETL工程师、数据仓库架构师,大多数人属于前两者。
数据工程师:根据业务人员提交的逻辑来编写“存储过程”,他们能够很轻松的编写上千行的复杂逻辑SQL。在编写SQL多年经验中,掌握了各种关联查询、聚合查询、窗口函数,甚至还可以用SQL自己编写一些Function,最终组合成了存储过程。
ETL工程师:传统数据仓库只有在大型企业中一般才会有,比如电信、银行、保险等行业。他们都会采购一些ETL工具,比如Informatica或者和第三方共建ETL工具,比如和华为、亚信等。这些ETL工具功能非常强大。ETL工程师可以通过在平台上拖拉拽的形式进行数据加工处理,同时ETL平台的组件还可以支撑一些脚本的上传,所以ETL工程师结合数据工程师开发的复杂存储过程,在平台上进行加工设计,最终形成一个个定时任务。然后他们还负责每天监控这些定时任务的状态,对于重要部门的ETL人员还经常会熬夜值班监控。
数据仓库架构师:数据仓库是依靠规范来有序进行的,架构师就是来建立这些规范的,包括数据仓库的分层、模型命名、指标命名、ETL任务命名、ETL任务编排规范、存储过程开发规范等等,最终形成《XX数据仓库建设规范》,然后数据工程师和ETL工程师按照规范进行任务开发。如果遇到重大业务变更,比如主数据变更,需要和数据仓库架构师评审后修改完善。
大数据开发
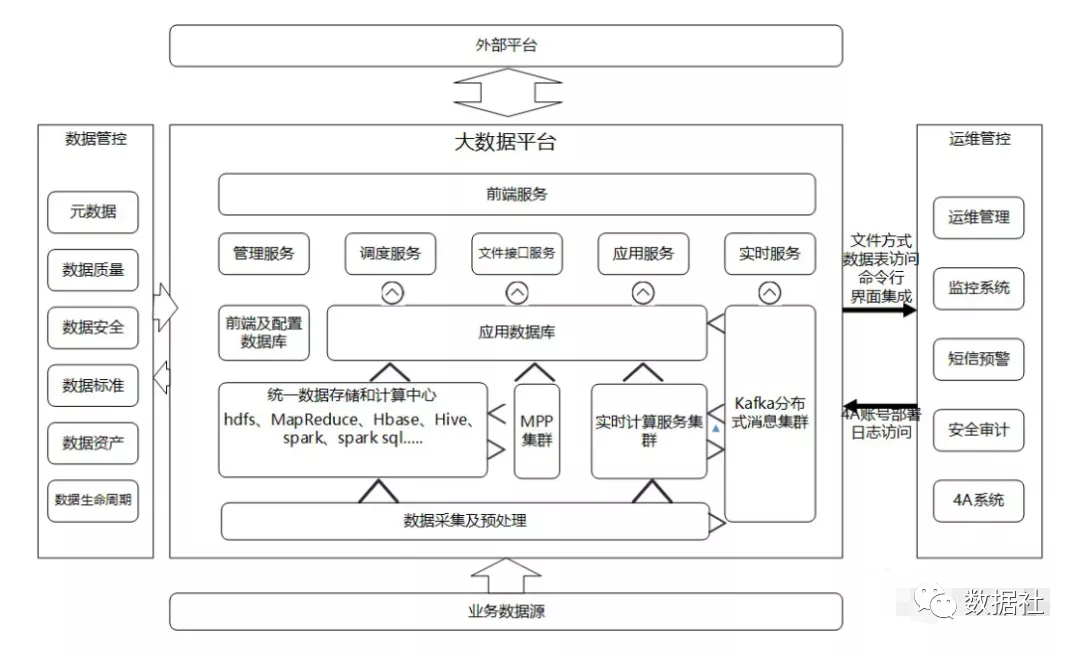
现在的大数据架构多了一些东西,比如数据采集Flume、消息对垒kafka、计算引擎MR、Spark以及实时计算框架,这些都是以前传统数据仓库架构下没有的。
Flume
Flume是一种分布式、高可靠和高可用的服务,用于高效地收集、聚合和移动大量日志数据。它有一个简单而灵活的基于流数据流的体系结构。它具有可调的可靠性机制、故障转移和恢复机制,具有强大的容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。Flume的设计宗旨是向Hadoop集群批量导入基于事件的海量数据。系统中最核心的角色是agent,Flume采集系统就是由一个个agent所连接起来形成。每一个agent相当于一个数据传递员,内部有三个组件:
source: 采集源,用于跟数据源对接,以获取数据
sink:传送数据的目的地,用于往下一级agent或者最终存储系统传递数据
channel:agent内部的数据传输通道,用于从source传输数据到sink
详细配置参考:《日志收集组件—Flume、Logstash、Filebeat对比》
kafka
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
同时支持离线数据处理和实时数据处理。
Scale out:支持在线水平扩展
大数据计算引擎
近几年出现了很多热门的开源社区,其中著名的有 Hadoop、Storm,以及后来的Spark、Flink,他们都有着各自专注的应用场景。Spark掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark的火热或多或少的掩盖了其他分布式计算的系统身影。不过目前Flink在阿里的力推之下,也逐渐占领着实时处理的市场。其实大数据的计算引擎分成了三代:
第一代计算引擎
无疑就是Hadoop承载的 MapReduce。这里大家应该都不会对MapReduce陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。MR每次计算都会和HDFS交互,和磁盘交互意味着产生更多的IO,也就会更慢。由于这样的弊端,催生了支持 DAG 框架和基于内存计算的产生。
第二代计算引擎
Spark的特点主要是 Job 内部的 DAG 支持(不跨越 Job),同时支持基于内存的计算。这样的话每次计算到中间步报错了,就不会再从头开始计算一遍,而是接着上一个成功的状态,同时中间计算结果数据也可以放在内存中,大大提高了计算速度。另外,Spark还支持了实时计算,满足了大家维护一套集群,既可以搞离线计算也可以搞实时计算。
第三代计算引擎
促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink开始崭露头角。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
转型
有了传统数据仓库转型大数据是一个好的开端,但是路并不会那么顺利,也许并没有你想想的那么快速。
从身边的同事来看,大家都是经历了很多项目经验之后,才真正转型成功的。
首先,作为传统的数据仓库工程师,你已经对SQL掌握的非常熟练,这是你的优势。可以看到,现在所有的大数据计算引擎都在支持着SQL,从最早的Hive到现在的Flink。他们大多和标准SQL语法近似,很快能够快速掌握,现在很多离线数据仓库还是建立在Hive之上,从这一点上,你能很快开发HiveSQL脚本。你可以把之前数据仓库架构的那一套方法论拿过啦借鉴,数据仓库这东西建了几十年,还是最初的那几套方法,足够了。只是你会遇到很大的数据量问题,要根据实际情况进行合理的分层,合理的使用临时表。但是,既然你选择了转型,相信你并不只是满足换个环境写SQL吧。所以你要学习Hadoop、学习Spark,身边曾有一个同事从传统数仓转大数据后,就是换个环境写SQL,写了两年了还不知道HDFS常用命令,不知道Spark的计算原理,每次SQL调优的时候,都去问平台开发的同事,怎么修改参数。所以趁着你还在转型的兴头上,学一下这方面的知识。如果之前没有java开发经验,那不建议你学习MR,直接上手Spark吧,python也很好用的,使用pyspark能够解决很多SQL解决不了的问题。
另外,学一学kafka吧,离线数仓搞完了,不想搞实时数仓吗?现在物联网行业,每天有几亿数据上传到平台,每条消息有几千个字段,我们无法选择传统的数据库进行存储。网关直接转发数据到kafka,然后存储到HDFS和HBase。其他行业也一样,电商。搜索,每天那么多人访问,访问数据也都是消息缓存的方式发送到HDFS落地分析的。
最后,推荐两本书吧,帮助你快速转型成功——《阿里大数据之路》、《大数据日知录》。
传统 BI 如何转大数据数仓的更多相关文章
- 论各类BI工具的“大数据”特性!
市面上的BI工具形形色色,功能性能包装得十分亮丽,但实际应用中我们往往更关注的是朴实的技术特性和解决方案.对于大数据,未来的应用趋势不可抵挡,很多企业也正存在大数据分析处理展现的需求,以下我们列举市面 ...
- 关于BI商业智能的“8大问”|一文读懂大数据BI
这里不再阐述商业智能的概念了,关于BI,就从过往的了解,搜索以及知乎的一些问答,大家困惑的点主要集中于大数据与BI的关系,BI的一些技术问题,以及BI行业和个人职业前景的发展.这里归纳成8个问题点,每 ...
- 敏捷BI比传统BI功能强大是否属实?
关于大数据的资讯铺天盖地而来,让人眼花缭乱.虽然资讯很精彩,我们也看到了大数据背后的价值,很多企业选择了商业智能BI产品.商业智能在使用上可分为敏捷BI与传统BI,从名字来看敏捷BI要比传统BI显得利 ...
- BI与大数据
微博的诞生.云计算.物联网.移动互联网等各种爆炸式数据,给商业智能的蓬勃发展提供了良好的“大数据”环境.大数据为BI带来了海量数据.对挖掘来说,大数据量要更容易对比.抢夺大数据市场,需要具备一定的实力 ...
- 大数据和BI商业智能有何区别?有何相关?
大数据 ≠BI商业智能,大数据也不是传统商业智能的简单升级. 1.大数据和BI两者的区别 BI(BusinessIntelligence)即商业智能,它是企业数据化管理的一整套的方案,用来将企业中现有 ...
- 民生银行十五年的数据体系建设,深入解读阿拉丁大数据生态圈、人人BI 是如何养成的?【转】
早在今年的上半年我应邀参加了由 Smartbi 主办的一个小型数据分析交流活动,在活动现场第一次了解到了民生银行的阿拉丁项目.由于时间关系,嘉宾现场分享的内容非常有限.凭着多年对行业研究和对解决方案的 ...
- 大数据时代的新BI系统架构发展趋势
商业智能(BI,Business Intelligence).它是一套完整的解决方式,用来将企业中现有的数据进行有效的整合,高速准确的提供报表并提出决策根据.帮助企业做出明智的业务经营决策. ...
- 大数据和BI商业智能有何区别?有何相关
大数据和BI商业智能有何区别?有何相关 大数据 ≠BI商业智能,大数据也不是传统商业智能的简单升级. 1.大数据和BI两者的区别 BI(BusinessIntelligence)即商业智能,它是企业数 ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
随机推荐
- C语言结构体及其内存布局
code[class*="language-"], pre[class*="language-"] { color: rgba(51, 51, 51, 1); ...
- PAT (Advanced Level) Practice 1027 Colors in Mars (20 分) 凌宸1642
PAT (Advanced Level) Practice 1027 Colors in Mars (20 分) 凌宸1642 题目描述: People in Mars represent the c ...
- IndentationError:unexpected indent”、“IndentationError:unindent does not match any outer indetation level”以及“IndentationError:expected an indented block Python常见错误
错误的使用缩进量 记住缩进增加只用在以:结束的语句之后,而之后必须恢复到之前的缩进格式. 经典错误,一定要注意缩进,尤其是在非界面化下环境的代码修改
- TypeError: 'str' object does not support item assignment Python常见错误
1.string是一种不可变的数据类型 2.尝试使用 range()创建整数列 有时你想要得到一个有序的整数列表,所以 range() 看上去是生成此列表的不错方式. 需要记住 range() 返回的 ...
- 第28 章 : 理解容器运行时接口 CRI
理解容器运行时接口 CRI CRI 是 Kubernetes 体系中跟容器打交道的一个非常重要的部分.本文将主要分享以下三方面的内容: CRI 介绍 CRI 实现 相关工具 CRI 介绍 在 CRI ...
- [.net] 关于Exception的几点思考和在项目中的使用(一)
本文链接 https://www.cnblogs.com/hubaijia/p/about-exceptions-1.html 关于exception的基本语法和作用,这里不再赘述,下面记录一下我在项 ...
- 数据库MySQL六
介绍什么是JDBC JAVA SE也有 提高综合篇 JDBC(Java Database Connectivity) :java和数据库的连接技术,sun公司推出的一套java应用程序访问数据库的技术 ...
- JavaScript课程——Day01
1.网页由三部分组成: 1.1.HTML:超文本标记语言,专门编写网页内容的语言.(结构) 1.2.CSS:层叠样式表.(样式) 1.3.javaScript:网页交互的解释性脚本语言,专门编写客户端 ...
- adb下载安装
下载地址:https://www.androiddevtools.cn/# 首页tab工具栏: 选择Android SDK工具-- SDK Tools 下载任一版本即可 安装 :将下载的安装包解压到D ...
- 基于MATLAB的手写公式识别(9)
基于MATLAB的手写公式识别(9) 1.2图像的二值化 close all; clear all; Img=imread('drink.jpg'); %灰度化 Img_Gray=rgb2gray(I ...