hashmap专题
hashmap重要变量
源码中定义了很多常量,有几个是特别重要的。
DEFAULT_INITIAL_CAPACITY: Table数组的初始化长度: 1 << 4,即 2^4=16(这里可能会问为什么要是2的n次方?)MAXIMUM_CAPACITY:Table数组的最大长度: 1<<30, 即 2^30=1073741824DEFAULT_LOAD_FACTOR: 负载因子:默认值为0.75。 当元素的总个数>当前数组的长度 * 负载因子。数组会进行扩容,扩容为原来的两倍(这里可能会问为什么是两倍?这个问题与上述2的n次方相关联)TREEIFY_THRESHOLD: 链表树化的阈值,默认为8,表示载一个node(table)节点下的值的长度大于8时就会转变为红黑树UNTREEIFY_THRESHOLD: 红黑树链化阈值,默认为6,表示载一个node(table)节点下的值的长度小于6时就会转变为链表MIN_TREEIFY_CAPACITY = 64:最小树化阈值,当Table所有元素超过该值,才会进行树化(为了防止前期阶段频繁扩容和树化过程冲突)。
构造器
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
空参构造器中对属性loadFactor(加载因子)进行了赋值操作,初始值为16。
注意:JDK8中创建完HashMap对象后并没有立即创建长度为16的数组。
最显而易见的区别
- JDK 1.7 : Table数组+ Entry链表;
- JDK1.8 : Table数组+ Entry链表 ==> 红黑树;(可能会问为什么要使用红黑树?)

为什么使用链表+数组?
因为为了避免hash冲突的问题。由于我们的数组的值是限制死的,我们在对key值进行散列取到下标以后,放入到数组中时,难免出现两个key值不同,但是却放入到下标相同的格子中,此时我们就可以使用链表来对其进行链式的存放。
我⽤LinkedList代替数组结构可以吗?
可以
那既然可以使用进行替换处理,为什么有偏偏使用到数组呢?
因为用数组效率最高! 在HashMap中,定位节点的位置是利用元素的key的哈希值对数组长度取模得到。此时,我们已得到节点的位置。显然数组的查找效率比LinkedList大(底层是链表结构)。
ArrayList,底层也是数组,查找也快,为啥不⽤ArrayList?
因为采用基本数组结构,扩容机制可以自己定义,HashMap中数组扩容刚好是2的次幂,在做取模运算的效率高。⽽ArrayList的扩容机制是1.5倍扩容。
当两个对象的 hashCode 相同会发生什么?
因为 hashCode 相同,不一定就是相等的(equals方法比较),所以两个对象所在数组的下标相同,"碰撞"就此发生。又因为 HashMap 使用链表存储对象,这个 Node 会存储到链表中。
你知道 hash 的实现吗?为什么要这样实现?
JDK 1.8 中,是通过 hashCode() 的高 16 位异或低 16 位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度,功效和质量来考虑的,减少系统的开销,也不会造成因为高位没有参与下标的计算,从而引起的碰撞。
为什么要用异或运算符?
保证了对象的 hashCode 的 32 位值只要有一位发生改变,整个 hash() 返回值就会改变。尽可能的减少碰撞。
为什么是2的幂次?与数字2的关系
首先为什么长度要是2的n次方?
这依然关系到hash冲突。

简单来说,就是如果是2的幂,就能减少hash冲突的出现
因为这个key存放到数组中哪个位置,,源码中有个按位与来判断,即hash & (length - 1),如果是2的幂,那么这个减一的操作会让最后4个位数都是1111,进而保证哈希值能分布早0-15之间。如果不是2的幂的话,有可能出现某个哈希桶(可以理解为数组中某个位置)是一直为空的,不能完全利用好数组。
注意: hash值是个32位的int型
那么如果不是容量不是2的幂呢?
源码中有个静态方法private static int roundUpToPowerOf2,这个方法会将容量扩充为2的幂。
int rounded = number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY
: (rounded = Integer.highestOneBit(number)) != 0 ?
(Integer.bitCount(number) > 1) ? rounded << 1 : rounded
: 1;
流程图如下:

hashmap为什么是二倍扩容?
容量n为2的幂次方,n-1的二进制会全为1,位运算时可以充分散列,避免不必要的哈希冲突。所以扩容必须2倍就是为了维持容量始终为2的幂次方。
阶段总结
Hashmap的结构,1.7和1.8有哪些区别
- JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
- 扩容后数据存储位置的计算方式也不一样:
- 在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行按位与
hash & (length-1)(这里就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时最后一位二进制数才一定是1,这样能最大程度减少hash碰撞)(hash值 & length-1) - 而在JDK1.8的时候直接用了JDK1.7的时候计算的规律,也就是扩容前的原始位置+扩容的大小值=JDK1.8的计算方式,而不再是JDK1.7的那种异或的方法。但是这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。
- 在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行按位与
- JDK1.7的时候使用的是数组+ 单链表的数据结构。但是在JDK1.8及之后时,使用的是数组+链表+红黑树的数据结构(当链表的深度达到8的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(n)变成O(logN)提高了效率)
浓缩版:
- jdk7 数组+单链表 jdk8 数组+(单链表+红黑树)
- jdk7 链表头插 jdk8 链表尾插
- 头插: resize后transfer数据时不需要遍历链表到尾部再插入
- 头插: 最近put的可能等下就被get,头插遍历到链表头就匹配到了
- 头插: resize后链表可能倒序; 并发resize可能产生循环链
- jdk7 先扩容再put jdk8 先put再扩容 (why?有什么区别吗?)
- jdk7 计算hash运算多 jdk8 计算hash运算少
- jdk7 受rehash影响 jdk8 调整后是(原位置)or(原位置+旧容量)
为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者不是20呢(面试蘑菇街问过)?
- 如果选择6和8(如果链表小于等于6树还原转为链表,大于等于8转为树),中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
- 还有一点重要的就是由于treenodes的大小大约是常规节点的两倍,因此我们仅在容器包含足够的节点以保证使用时才使用它们,当它们变得太小(由于移除或调整大小)时,它们会被转换回普通的node节点,容器中节点分布在hash桶中的频率遵循泊松分布,桶的长度超过8的概率非常非常小。所以作者应该是根据概率统计而选择了8作为阀值
哈希表如何解决Hash冲突?

总结一些特点
为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键

讲讲HashMap的get/put过程
常见问题:
- 知道HashMap的put元素的过程是什么样吗?
- 知道get过程是是什么样吗?
- 你还知道哪些的hash算法?
- 说一说String的hashcode的实现
添加方法:put()
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
} // 因为有些数据计算出的哈希值差异主要在高位,而 HashMap 里的哈希寻址是忽略容量以上的高位的
// 那么这种处理就可以有效避免类似情况下的哈希碰撞
static final int hash(Object key) {
int h;
// 如果key不为null,就让key的高16位和低16位取异或
// 和Java 7 相比,hash算法确实简单了不少
// 使用异或尽可能的减少碰撞
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
} // 放入元素的操作
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// tab相当于哈希表
Node<K,V>[] tab;
Node<K,V> p;// n保存了桶的个数
// i保存了应放在哪个桶中
int n, i; // 如果还没初始化哈希表,就调用resize方法进行初始化操作
// resize()方法在后面分析
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // 这里的 (n - 1) & hash 相当于 Java 7 中的indexFor()方法,用于确定元素应该放在哪个桶中
// (n - 1) & hash 有以下两个好处:1、放入的位置不会大于桶的个数(n-1全为1) 2、用到了hash值,确定其应放的对应的位置
if ((p = tab[i = (n - 1) & hash]) == null)
// 如果桶中没有元素,就将该元素放到对应的桶中
// 把这个元素放到桶中,目前是这个桶里的第一个元素
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e;
// 创建和键类型一致的变量
K k; // 如果该元素已近存在于哈希表中,就覆盖它
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果采用了红黑树结构,就是用红黑树的插入方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 否则,采用链表的扩容方式
else {
// binCount用于计算桶中元素的个数
for (int binCount = 0; ; ++binCount) {
// 找到插入的位置(链表最后)
if ((e = p.next) == null) {
// 尾插法插入元素
p.next = newNode(hash, key, value, null);
// 如果桶中元素个数大于阈值,就会调用treeifyBin()方法将其结构改为红黑树(但不一定转换成功)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 如果遇到了相同的元素,就覆盖它
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
} if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
} ++modCount; // 如果size大于阈值,就进行扩容操作
if (++size > threshold)
resize(); afterNodeInsertion(evict);
return null;
}
总结
- 对key的hashCode()做hash运算,计算index;
- 如果没碰撞直接放到bucket(哈希桶)里;
- 如果碰撞了,以链表的形式存在buckets后;
- 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树(JDK1.8中的改动);
- 如果节点已经存在就替换old value(保证key的唯一性)
- 如果bucket满了(超过load factor*current capacity),就要resize
同时 对于Key 和Value 也要经历以下的步骤
- 通过 Key 散列获取到对于的Table;
- 遍历Table 下的Node节点,做更新/添加操作;
- 扩容检测;
扩容方法:resize()
HashMap 的扩容实现机制是将老table数组中所有的链表取出来,重新对其Hashcode做Hash散列到新的Table中,resize表示的是对数组进行初始化或
进行Double处理。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;// 原容量大于0(已近执行了put操作以后的扩容)
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 原容量扩大一倍后小于最大容量,那么newCap就为原容量扩大一倍,同时新阈值为老阈值的一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 调用了含参构造方法的扩容
// 原容量小于等于0,但是阈值大于0,那么新容量就位原来的阈值(阈值在调用构造函数时就会确定,但容量不会)
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr; // 调用了无参构造方法的扩容操作
else {
// zero initial threshold signifies using defaults
// 如果连阈值也为0,那就调用的是无参构造方法,就执行初始化操作
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
} // 如果新阈值为0,就初始化它
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
} // 阈值改为新阈值
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"}) // 创建新的表,将旧表中的元素进行重新放入
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 为空就直接放入
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e; // 如果是树节点,就调用红黑树的插入方式
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // 链表的插入操作
else { // preserve order
// lo 和 hi 分别为两个链表,保存了原来一个桶中元素被拆分后的两个链表
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
获取数据:get()方法
- 对key的hashCode()做hash运算,计算index;
- 如果在bucket里的第一个节点里直接命中,则直接返回;
- 如果有冲突,则通过key.equals(k)去查找对应的Entry;
- 若为树,则在树中通过key.equals(k)查找,O(logn);
- 若为链表,则在链表中通过key.equals(k)查找,O(n)。
代码如下
public V get(Object key) {
Node<K,V> e;
// 通过key的哈希值和key来进行查找
return (e = getNode(hash(key), key)) == null ? null : e.value;
} final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;// 哈希表不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { // 如果第一个元素就是要查找的元素,就返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first; // 如果第一个元素不是,就继续往后找。找到就返回,没至找到就返回null
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
还知道哪些hash算法
先说⼀下hash算法⼲嘛的,Hash函数是指把⼀个⼤范围映射到⼀个⼩范围。把⼤范围映射到⼀个⼩范围的⽬的往往是为了 节省空间,使得数据容易保存。
String中hashcode的实现
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
String类中的hashCode计算⽅法还是⽐较简单的,就是以31为权,每⼀位为字符的ASCII值进⾏运算,⽤⾃然溢出来等效 取模。
为什么hashmap的在链表元素数量超过8时候改为红黑树
- 知道jdk1.8中hashmap改了什么吗。
- 说一下为什么会出现线程的不安全性
- 为什么在解决hash冲突时候,不直接用红黑树,而是先用链表,再用红黑树
知道jdk1.8中hashmap改了什么吗。
- 由数组+链表的结构改为数组+链表+红⿊树。
- 优化了⾼位运算的hash算法:h^(h>>>16)
- 扩容后,元素要么是在原位置,要么是在原位置再移动2次幂的位置,且链表顺序不变。
注意: 最后⼀条是重点,因为最后⼀条的变动,hashmap在1.8中,不会在出现死循环问题。
线程不安全问题
HashMap 在jdk1.7中 使用 数组加链表的方式,并且在进行链表插入时候使用的是头结点插入的方法。
注 :这里为什么使用 头插法的原因是我们若是在散列以后,判断得到值是一样的,使用头插法,不用每次进行遍历链表的长度。但是这样会有一个缺点,在进行扩容时候,会导致进入新数组时候出现倒序的情况,也会在多线程时候出现线程的不安全性。
但是对与 jdk1.8 而言,还是要进行阈值的判断,判断在什么时候进行红黑树和链表的转换。所以无论什么时候都要进行遍历,于是插入到尾部,防止出现扩容时候还会出现倒序情况。
简而言之:
- 在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
- 在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
为什么不一开始就使用红黑树,不是效率很高吗?
因为红⿊树需要进行左旋,右旋,变⾊这些操作来保持平衡,而单链表不需要。
当元素小于8个当时候,此时做查询操作,链表结构已经能保证查询性能。
当元素大于8个的时候,此时需要红黑树来加快查询速度,但是新增节点的效率变慢了。因此,如果一开始就用红黑树结构,元素太少,新增效率又比较慢,无疑这是浪费性能的。
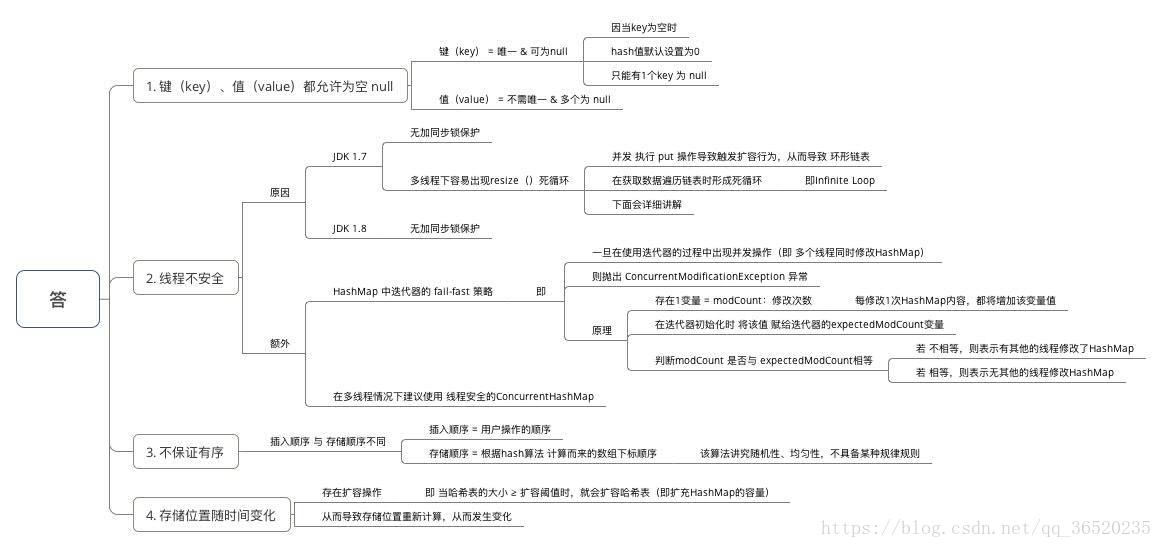
HashMap的并发问题
- HashMap在并发环境下会有什么问题
- 一般是如何解决的
问题的出现:
(1)多线程扩容,引起的死循环问题
(2)多线程put的时候可能导致元素丢失
(3)put非null元素后get出来的却是null
不安全性的解决方案
concurrentHashmap
你一般用什么作为HashMap的key值
- key可以是null吗,value可以是null吗
- 一般用什么作为key值
- 用可变类当Hashmap的Key会有什么问题
- 让你实现一个自定义的class作为HashMap的Key该如何实现
key可以是null吗,value可以是null吗
当然都是可以的,但是对于 key来说只能运行出现一个key值为null,但是可以出现多个value值为null
一般用什么作为key值
⼀般⽤Integer、String这种不可变类当HashMap当key,⽽且String最为常⽤。
详见上面的问题:为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键
用可变类当Hashmap的Key会有什么问题
hashcode可能会发生变化,导致put进行的值,无法get出来
实现一个自定义的class作为Hashmap的key该如何实现
- 重写hashcode和equals方法需要注意什么?
- 如何设计一个不变的类。
针对问题一,记住下面四个原则即可
(1)两个对象相等,hashcode一定相等
(2)两个对象不等,hashcode不一定不等
(3)hashcode相等,两个对象不一定相等
(4)hashcode不等,两个对象一定不等
针对问题二,记住如何写一个不可变类
(1)类添加final修饰符,保证类不被继承。 如果类可以被继承会破坏类的不可变性机制,只要继承类覆盖父类的方法并且继承类可以改变成员变量值,那么一旦⼦类 以⽗类的形式出现时,不能保证当前类是否可变。
(2)保证所有成员变量必须私有,并且加上final修饰 通过这种方式保证成员变量不可改变。但只做到这一步还不够,因为如果是对象成员变量有可能再外部改变其值。所以第4点弥补这个不足。
(3)不提供改变成员变量的方法,包括setter 避免通过其他接⼝改变成员变量的值,破坏不可变特性。
(4)通过构造器初始化所有成员,进行深拷贝(deep copy)
(5) 在getter方法中,不要直接返回对象本身,而是克隆对象,并返回对象的拷贝。这种做法也是防⽌对象外泄,防止通过getter获得内部可变成员对象后对成员变量直接操作,导致成员变量发生改变
补充一些面试题
能否使用任何类作为Map 的key?
可以使用任何类作为Map 的key , 然而在使用之前,需要考虑以下几点
- 如果类重写了equals() 方法,也应该重写hashCode()方法。如果一个类没有使用equals(), 不应该在hashCode() 中使用它。
- 类的所有实例需要遵循与equals() 和hashCode() 相关的规则。
- 最好还是使用不可变类
HashMap 为什么不直接使用hashCode()处理后的哈希值直接作为table 的下标?
首先hashcode方法返回的是int整数类型,其范围太大,且存在负数,无法匹配存储位置。二是hashmap的容量范围是从16开始的,也就是他的初始化默认值
解决
- HashMap实现了自己的hash()方法, 通过两次扰动使得它自己的哈希值高低位自行进行异或运算, 降低哈希碰撞概率,也使得数据分布更平均;
- 回顾一下hashmap长度为2的幂次方问题
补充: 为什么是两次扰动
这样就是加大哈希值低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性和均匀性,最终减少Hash冲突,两次就够了, 已经达到了高位低位同时参与运算的目的;
HashMap 与HashTable 有什么区别?
- 线程安全:HashMap 是非线程安全的, HashTable 是线程安全的。
- 效率:hashmap比hashtable效率更高(HashTable内部经过synchronize修饰,效率差了点)
- 对Null key 和Null value的支持:HashMap 中,null可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为null。但是在HashTable中put 进的键值只要有一个null, 直接抛异常.
- 初始容量大小和每次扩充容量大小的不同:Hashtable 默认的初始大小为11 , 之后每次扩充, 容量变为原来的2n+1 。HashMap 默认的初始化大小为16。之后每次扩充, 容量变为原来的2 倍。如果指定了容量,Hashtable 会直接使用你给定的大小,而HashMap会将其扩充为2 的幂次方大小。
- 底层结构:jdk1.8中hashmap会在链表长度大于8时将链表转化为红黑树,但是hashtable没有这个机制
hashmap专题的更多相关文章
- HashMap、HashTable、ConcurrentHashMap、HashSet区别 线程安全类
HashMap专题:HashMap的实现原理--链表散列 HashTable专题:Hashtable数据存储结构-遍历规则,Hash类型的复杂度为啥都是O(1)-源码分析 Hash,Tree数据结构时 ...
- java后端知识点梳理——java集合
集合概览 Java中的集合,从上层接口上看分为了两类,Map和Collection.Map是和Collection并列的集合上层接口,没有继承关系. Java中的常见集合可以概括如下. Map接口和C ...
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- 专题-集合-HashMap
集合中的HashMap几乎是面试时必问的知识点,下面就从原理上剖析以下这个集合,看完了这一块的知识点应该就没问题了. 一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供 ...
- java集合专题 (ArrayList、HashSet等集合底层结构及扩容机制、HashMap源码)
一.数组与集合比较 数组: 1)长度开始时必须指定,而且一旦指定,不能更改 2)保存的必须为同一类型的元素 3)使用数组进行增加/删除元素-比较麻烦 集合: 1)可以动态保存任意多个对象,使用比较方便 ...
- LeetCode算法题-Design HashMap(Java实现)
这是悦乐书的第299次更新,第318篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第167题(顺位题号是706).在不使用任何内置哈希表库的情况下设计HashMap.具体 ...
- JDK7,8,JD9的hashmap,hashtable,concurrenthashmap及他们的区别
1:hashmap简介(如下,数组-链表形式) HashMap的存储结构 图中,紫色部分即代表哈希表,也称为哈希数组(默认数组大小是16,每对key-value键值对其实是存在map的内部类entry ...
- JVM性能调优监控工具专题一:JVM自带性能调优工具(jps,jstack,jmap,jhat,jstat,hprof)
性能分析工具jstatjmapjhatjstack 前提概要: JDK本身提供了很多方便的JVM性能调优监控工具,除了集成式的VisualVM和jConsole外,还有jps.jsta ...
- java集合框架(一):HashMap
有大半年没有写博客了,虽然一直有在看书学习,但现在回过来看读书基本都是一种知识“输入”,很多时候是水过无痕.而知识的“输出”会逼着自己去找出没有掌握或者了解不深刻的东西,你要把一个知识点表达出来,自己 ...
随机推荐
- Dubbo原理剖析 之 @DubboReference.version设置为*
原文链接 Dubbo原理剖析 之 @DubboReference.version设置为* 1 背景 Dubbo在消费端提供了一个功能,即将消费者的版本号指定为*,那么不管服务端的接口版本是啥,都可以调 ...
- Mac使用brew搭建LNMP
一. brew常用命令 安装brew /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/in ...
- thinkphp中常用到的sql操作
1.清空某表数据: $sql = 'truncate table table_name'; Db::execute($sql );
- Mybatis学习之自定义持久层框架(四) 自定义持久层框架:生产sqlSession
前言 上一回我们完成了数据库配置文件的读取和解析工作,有了这些准备工作,我们就可以与数据库创建连接和会话了,所谓sqlSession就是数据库的会话,一切增删查改操作都是在与数据库的会话中完成,下面我 ...
- [并发编程 - socketserver模块实现并发、[进程查看父子进程pid、僵尸进程、孤儿进程、守护进程、互斥锁、队列、生产者消费者模型]
[并发编程 - socketserver模块实现并发.[进程查看父子进程pid.僵尸进程.孤儿进程.守护进程.互斥锁.队列.生产者消费者模型] socketserver模块实现并发 基于tcp的套接字 ...
- mitrproxy抓包微信小程序
mitmproxy mitmproxy is a set of tools that provide an interactive, SSL/TLS-capable intercepting prox ...
- 风变编程(Python自学笔记)第12关-我们都是中国人
1.类的个例叫做实例:类,是对某个群体的统称(类是某个特定的群体),实例是群体中某个具体的个体. 2.Python中的对象等于类和实例的集合. 3. 类的创建:class+类名+冒号,后面语句要缩进. ...
- 16.分类和static
1.案例驱动模式 1.1案例驱动模式概述 (理解) 通过我们已掌握的知识点,先实现一个案例,然后找出这个案例中,存在的一些问题,在通过新知识点解决问题 1.2案例驱动模式的好处 (理解) 解决重复代码 ...
- vmware快捷键大全
初学linux的朋友往往需要使用VMware这个软件 与其打交道多了 越来越觉得快捷键的重要性 特将搜集到的快捷键记录以便查阅记忆 Ctrl-Alt-Enter 进入全屏模式 ctrl+alt+ins ...
- ceph总结复习
一.ceph概念 Ceph是一种为优秀的性能.可靠性和可扩展性而设计的统一的.分布式文件系统.ceph 的统一体现在可以提供文件系统.块存储和对象存储,分布式体现在可以动态扩展. 什么是块存储/对象存 ...