Golang语言系列-11-goroutine并发
goroutine 并发
概念
package main
import (
"fmt"
"time"
)
/*
[Go语言中的并发编程 goroutine]
[并发与并行]
并发:同一 时间段 内执行多个任务(你在用微信和两个女朋友聊天)
并行:同一 时刻 执行多个任务(你和你朋友都在用微信和女朋友聊天)
[goroutine]
Go语言的并发通过goroutine实现,goroutine类似于线程,属于用户态的线程,比内核态线程更轻量级,是由Go语言的运行时(runtime)调度的
Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。
Go语言之所以被称为现代化的编程语言,就是因为它在语言层面已经内置了调度和上下文切换的机制。
Go语言还提供channel在多个goroutine间进行通信。
Go语言中使用goroutine非常简单,只需要在调用函数的时候在前面加上go关键字,就可以为一个函数创建一个goroutine。
一个goroutine必定对应一个函数,可以创建多个goroutine去执行相同的函数
goroutine什么结束?
goroutine 对应的函数结束了,goroutine结束了。
main函数执行完了,由main函数创建的那些goroutine都结束了
*/
func hello(i int) {
fmt.Println("hello ", i)
}
// 在程序启动时,Go程序就会为main()函数创建一个默认的goroutine
func main() {
// 启动多个goroutine
for i := 0; i < 10; i++ {
go hello(i) //开启一个单独的goroutine去执行hello函数(任务)
}
fmt.Println("main")
// 如果main函数结束,那么由main函数启动的goroutine也都结束了
// 所以在这里等待1s,等其他的goroutine执行完毕在结束
time.Sleep(time.Second)
}
WaitGroup
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// WaitGroup goroutine的计数器
// 声明一个计数器变量
var wg sync.WaitGroup
func f() {
rand.Seed(time.Now().UnixNano()) //保证每次执行的时候获取的随机数都不一样
for i := 0; i < 5; i++ {
r1 := rand.Int() //int64
r2 := rand.Intn(10) //0 <= r2 < 10
fmt.Println(r1, r2)
}
}
func f1(i int) {
defer wg.Done() //计数器 -1
time.Sleep(time.Second * time.Duration(rand.Intn(3))) //睡 [0-3) 秒
fmt.Println(i)
}
func main() {
//f()
//wg.Add(10) //也可以这样写,直接告诉计数器我要开启10个goroutine
for i := 0; i < 10; i++ { //启动多个goroutine
wg.Add(1) //每开启一个goroutine,计数器就自动+1
go f1(i)
}
//time.Sleep(1 * time.Second) //现在还用time.sleep来等待 goroutine 结束就不好用了,不知道要等待多久 goroutine 才结束
wg.Wait() //等待wg的计数器为0的时候就结束main函数
}
GOMAXPROCS
package main
import (
"fmt"
"sync"
)
/*
[GOMAXPROCS]
Go运行时的调度器使用GOMAXPROCS参数来确定需要使用多少个OS线程来同时执行Go代码
默认值是机器上的CPU核心数
例如在一个8核心的机器上,调度器会把Go代码同时调度到8个OS线程上
Go1.5版本之前,默认使用的是单核心执行
Go1.5版本之后,默认使用全部的CPU逻辑核心数
Go语言中可以通过runtime.GOMAXPROCS()函数设置当前程序并发时占用的CPU逻辑核心数
Go语言中的操作系统线程和goroutine的关系:
一个操作系统线程对应用户态多个goroutine。
go程序可以同时使用多个操作系统线程。
goroutine和OS线程是多对多的关系,即m:n
*/
var wg sync.WaitGroup
func a() {
defer wg.Done()
for i := 0; i < 50; i++ {
fmt.Printf("A:%d ", i)
}
}
func b() {
defer wg.Done()
for i := 0; i < 50; i++ {
fmt.Printf("B:%d ", i)
}
}
func main() {
/*
默认为CPU的逻辑核心数,跑满整个CPU,见 图pc2 的结果可以知道,是多个线程同时执行,所以打印的次序乱了
由于只有一个终端输出,所以多个线程打印的时候,会争抢资源,打印次序就混乱
当设置为1的时候,就只使用1个线程,此时程序是串行的,打印也是有顺序的,见 图pc1
*/
//runtime.GOMAXPROCS(1)
//runtime.GOMAXPROCS(2)
//fmt.Println(runtime.NumCPU()) //获取本机物理机线程个数 4
wg.Add(2)
go a()
go b()
wg.Wait()
}
图pc1

图pc2

package main
import "runtime"
func task() {
for {
}
}
func main() {
//runtime.GOMAXPROCS(1) //如果不设置这个值,默认会跑满所有的cpu,见图1
runtime.GOMAXPROCS(1) //设置只使用1个cpu,这里不会跑满所有的cpu
go task()
go task()
go task()
go task()
select {}
}
channel通道
channel定义
package main
import (
"fmt"
"sync"
)
/*
[为什么要使用channel?]
单纯地将函数并发执行是没有意义的,函数与函数间需要交换数据才能体现并发执行函数的意义
虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题
为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题
[channel] 别名:管道、通道
通道channel是一种类型,一种引用类型,通道类型的空值是nil
通道channel必须要使用 make函数 初始化以后才能使用。和slice,map一样
Go语言的并发模型是CSP,提倡通过 通信共享内存; 而不是 通过共享内存而实现通信
如果说goroutine是Go程序并发的执行体,那么channel就是它们之间的连接
channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制
Go 语言中的通道(channel)是一种特殊的类型
通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。
每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型
[channel操作]
1.发送:发送数字1到ch1通道 ch1 <- 1 写入
2.接收:x读取通道ch1中的数字1 x := <- ch1 读取
3.关闭:close(ch1)
*/
var a []int
var b chan int //需要指定通道中元素的类型
var wg sync.WaitGroup
// noBufChannel 无缓冲区的通道
func noBufChannel() {
fmt.Println("无缓冲区通道b: ", b) //nil
b = make(chan int) //初始化,但是不带缓冲区。如果没有设置缓冲区,那么必须先有读取者,才能往通道中写入数据
wg.Add(1)
go func() {
defer wg.Done()
x := <-b //从通道b中读取数据
fmt.Println("无缓冲区 后台goroutine从通道b中取到了", x)
}()
b <- 10 //10 写入到通道中。如果没有上面的匿名函数接收数据,那么此处会hang住
fmt.Println("无缓冲区 10发送到通道b中了...") //后台goroutine从通道b中取到了 10
wg.Wait()
}
// bufChannel 有缓冲区通道
func bufChannel() {
fmt.Println(b) //nil
b = make(chan int, 10) //带有缓冲区的通道,容量为10
b <- 10 //10写入到通道
fmt.Println("10发送到通道b中了...")
b <- 20 //20写入到通道
fmt.Println("20发送到通道b中了...")
x := <-b
fmt.Println("从通道中取到了", x)
x = <-b
fmt.Println("从通道中取到了", x)
close(b)
}
func main() {
//noBufChannel()
bufChannel()
}
channel练习
package main
import (
"fmt"
"sync"
)
// channel 练习
// 1.启动一个goroutine,生成100个数发送到ch1
// 2.启动一个goroutine,从ch1中取值,计算其平方放到ch2中
// 3.在main中,从ch2取值打印出来
var wg sync.WaitGroup
var once sync.Once
// 生成100个数发送到ch1
func f1(ch1 chan<- int) { //ch1 chan<- int 只能往ch1里面写入
defer wg.Done()
for i := 0; i < 100; i++ {
ch1 <- i
}
close(ch1) //关闭通道以后,还可以读取数据,但是不能写入了
}
// 计算其平方放到ch2中
func f2(ch1 <-chan int, ch2 chan<- int) {
defer wg.Done()
for {
//没有关闭的通道,最后不会返回false,会一直hang住,然后导致死锁
x, ok := <-ch1
if !ok {
break
}
ch2 <- x * x
}
once.Do(func() { close(ch2) }) //确保某个操作只执行一次
}
func main() {
a := make(chan int, 100)
b := make(chan int, 100)
wg.Add(4)
go f1(a)
go f2(a, b)
go f2(a, b)
go f2(a, b)
wg.Wait()
// 用range读取通道的时候,需要关闭通道,不然会出现死锁
for ret := range b {
fmt.Println(ret)
}
}
package main
import (
"fmt"
"sync"
)
/*
1、定义三个函数,分别可以打印cat、dog、fish
2、要求每个函数都起一个Goroutine
3、要求按照cat->dog->fish的顺序打印,每个50次
*/
var (
wgp sync.WaitGroup
catChan chan string
dogChan chan string
fishChan chan string
)
func main() {
catChan = make(chan string, 1)
dogChan = make(chan string, 1)
fishChan = make(chan string, 1)
fishChan <- "fish"
for i := 0; i < 50; i++ {
print()
}
}
func print() {
wgp.Add(3)
go cat()
go dog()
go fish()
wgp.Wait()
}
func cat() {
defer wgp.Done()
for {
select {
case tag := <-fishChan:
if tag == "fish" {
fmt.Printf("cat ")
catChan <- "cat"
return
}
}
}
}
func dog() {
defer wgp.Done()
for {
select {
case tag := <-catChan:
if tag == "cat" {
fmt.Print("dog ")
dogChan <- "dog"
return
}
}
}
}
func fish() {
defer wgp.Done()
for {
select {
case tag := <-dogChan:
if tag == "dog" {
fmt.Print("fish ")
fishChan <- "fish"
return
}
}
}
}
close channel
package main
import "fmt"
/*
[close() 关闭通道]
关于关闭通道需要注意的事情
只有在通知接收方goroutine所有的数据都发送完毕的时候才需要关闭通道
(如果一个通道没有关闭,那么通道中数据读取到最后会出现死锁,如果关闭了则不会)
通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的
关闭后的通道有以下特点:
对一个关闭的通道再发送值就会导致panic
对一个关闭的通道进行接收会一直获取值直到通道为空
对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值
关闭一个已经关闭的通道会导致panic
*/
func main() {
ch1 := make(chan int, 2)
ch1 <- 1
ch1 <- 2
close(ch1)
//for x := range ch1 {
// fmt.Println(x)
//}
<-ch1
<-ch1
x, ok := <-ch1
fmt.Println(x, ok) //0 false 关闭通道以后,通道的值如果取完了,还可以再取,但是返回的是该类型的零值和一个false
x, ok = <-ch1
fmt.Println(x, ok)
x, ok = <-ch1
fmt.Println(x, ok)
}
channel总结图
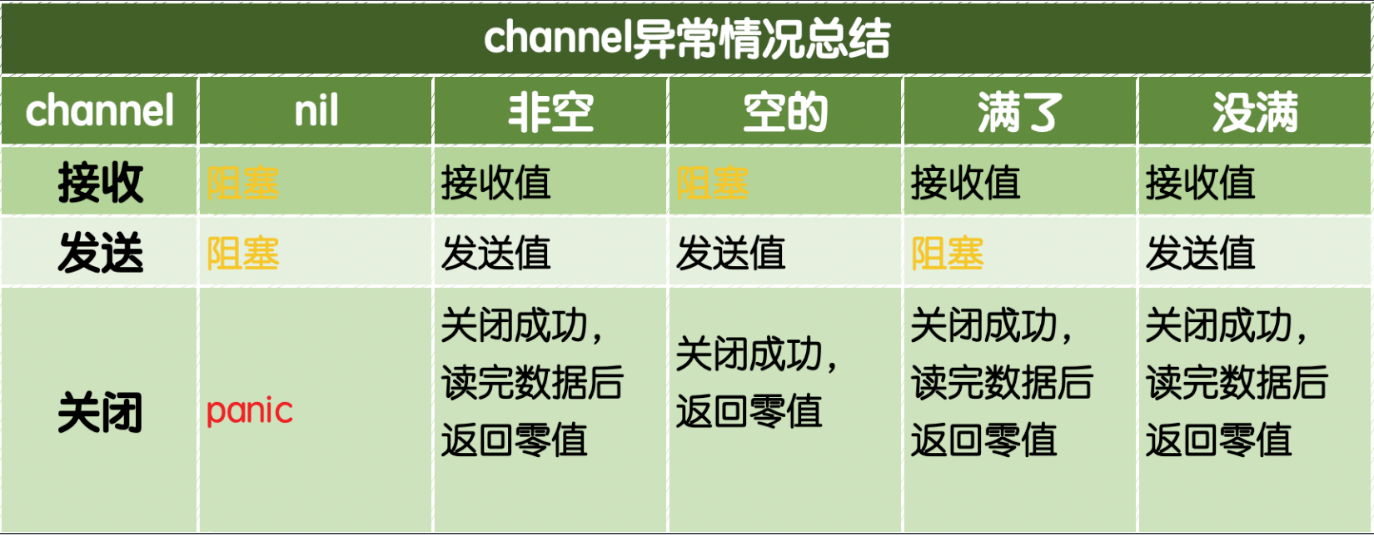
工作池理念 worker pool
package main
import (
"fmt"
"sync"
"time"
)
/*
worker pool(goroutine池)
在工作中我们通常会使用可以指定启动的goroutine数量,worker pool模式,
控制goroutine的数量,防止goroutine泄漏和暴涨
*/
var wg sync.WaitGroup
// worker 处理任务的goroutine
func worker(id int, jobs <-chan int, result chan<- int) {
defer wg.Done()
for j := range jobs {
//fmt.Printf("goroutine:%d start job:%d\n", id, j)
time.Sleep(time.Second)
fmt.Printf("goroutine:%d end job:%d\n", id, j)
result <- j * 2
}
}
func main() {
// 1.声明2个通道并初始化
jobs := make(chan int, 100)
result := make(chan int, 100)
// 2.开启3个goroutine 模拟goroutine池
wg.Add(3)
for w := 1; w <= 3; w++ {
go worker(w, jobs, result)
}
// 3.往jobs通道写入5个任务内容 模拟任务
for j := 1; j <= 5; j++ {
jobs <- j
}
close(jobs) //关闭jobs通道
// 4.等待goroutine结束
wg.Wait()
// 5.从通道中取值
for a := 1; a <= 5; a++ {
fmt.Println(<-result)
}
}
goroutine_channel练习
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
/*
使用goroutine和channel实现一个计算int64随机数 各个位数和 的程序。
1. 开启一个goroutine循环生成int64类型的随机数,发送到jobChan
2. 开启24个goroutine从jobChan中取出随机数计算各位数的和,将结果发送到resultChan
3. 主goroutine从resultChan取出结果并打印到终端输出
*/
// job ...
type job struct {
value int64
}
// result ...
type result struct {
job *job
sum int64
}
// 这个例子中,因为一直死循环接收通道中的值,所以无缓冲区也可以。不过建议还是要设置合理的缓冲区
var jobChan = make(chan *job)
var resultChan = make(chan *result)
var wg sync.WaitGroup
// 生产随机数
func zhoulin(zl chan<- *job) { //接收一个通道,这个通道的类型是 *job
defer wg.Done()
// 循环生成int64类型的随机数,发送到jobChan
for {
x := rand.Int63() //获取一个随机数 类型为int64
newJob := &job{value: x} //把job类型的结构体的指针值给newjob
zl <- newJob //把newjob这个指针存放到zl这个同道中人
time.Sleep(time.Millisecond * 500)
}
}
// 消费随机数
func baodelu(zl <-chan *job, resultChan chan<- *result) {
defer wg.Done()
// 从jobChan中取出随机数计算 个位数 的和,将结果发送到resultChan通道
for {
job := <-zl //取出来的是一个 *job结构体
sum := int64(0)
n := job.value
for n > 0 {
sum += n % 10
n = n / 10
}
newResult := &result{
job: job,
sum: sum,
}
resultChan <- newResult //把结果存入到通道
}
}
func main() {
// 开启一个goroutine,生产随机数
wg.Add(1)
go zhoulin(jobChan) //jobChan是一个通道,通道的值类型是 *job
// 开启24个goroutine从通道中取值
wg.Add(24)
for i := 0; i < 24; i++ {
go baodelu(jobChan, resultChan)
}
// 主goroutine从resulteChan取出结果并打印到终端
for result := range resultChan {
fmt.Printf("value:%d sum:%d\n", result.job.value, result.sum)
}
wg.Wait()
}
select多路复用
package main
import "fmt"
/*
[select多路复用]
在某些场景下我们需要同时从多个通道接收数据
通道在接收数据时,如果没有数据接收可能将会发生阻塞
Go内置了select关键字,可以同时响应多个通道的操作
select的使用类似于switch语句,它有一系列case分支和一个默认的分支
每个case会对应一个通道的通信(接收或发送)过程
select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句
使用select语句能提高代码的可读性
可处理一个或多个channel的发送/接收操作
如果多个case同时满足,select会随机选择一个
对于没有case的select{}会一直等待,可用于阻塞main函数
*/
func f1() {
ch := make(chan int, 1)
for i := 0; i < 10; i++ {
select {
case x := <-ch:
fmt.Println("x:", x)
case ch <- i:
}
}
/*
结果:0 2 4 6 8
分析:
第一次i=0时候,通道可以放进数据,所以走case x := <-ch:
第二次i=1时候,通道不可以放进数据,所以走case ch <- i:
依次类推
*/
}
func f2() {
ch := make(chan int, 1)
for i := 0; i < 10; i++ {
select {
case ch <- i:
fmt.Printf("%d send channel\n", i)
default:
fmt.Printf("get channel %d\n", <-ch)
}
}
/*
0 send channel
get channel 0
2 send channel
get channel 2
4 send channel
get channel 4
6 send channel
get channel 6
8 send channel
get channel 8
*/
}
func main() {
//f1()
f2()
}
并发安全和锁lock
互斥锁 sync.Mutex
package main
import (
"fmt"
"sync"
)
/*
[并发安全和锁]
[互斥锁 sync.Mutex]
互斥锁是完全互斥的
为什么需要锁?
有时候在Go代码中可能会存在多个goroutine同时操作一个资源(临界区),这种情况会发生竞态问题(数据竞态)
类比现实生活中的例子有十字路口被各个方向的的汽车竞争;还有火车上的卫生间被车厢里的人竞争
使用互斥锁能够保证同一时间有且只有一个goroutine进入临界区,其他的goroutine则在等待锁
当互斥锁释放后,等待的goroutine才可以获取锁进入临界区,
多个goroutine同时等待一个锁时,唤醒的策略是随机的
*/
var x int64
var wg sync.WaitGroup
var lock sync.Mutex
func add() {
for i := 0; i < 50000; i++ {
//有锁的情况
lock.Lock() // 加锁
x = x + 1
lock.Unlock() // 解锁
//没锁的情况
//x = x + 1
}
wg.Done()
}
func main() {
// 启用2个goroutine计算
wg.Add(2)
go add()
go add()
wg.Wait()
// 打印结果
fmt.Println(x)
}
/*
不加锁多次运算的结果:51630 51769 51284
加锁多次运算的结果:100000 100000 100000
*/
读写互斥锁 sync.RWMutex
package main
import (
"fmt"
"sync"
"time"
)
/*
[sync.RWMutex 读写互斥锁]
互斥锁是完全互斥的,但是有很多实际的场景下是读多写少的
当我们并发的去读取一个资源不涉及资源修改的时候是没有必要加锁的,这种场景下使用读写锁是更好的一种选择
读写锁在Go语言中使用sync包中的RWMutex类型
读写锁分为两种:读锁和写锁
当一个goroutine获取读锁之后,其他的goroutine如果是获取读锁会继续获得锁,如果是获取写锁就会等待;
当一个goroutine获取写锁之后,其他的goroutine无论是获取读锁还是写锁都会等待
读的goroutine来了获取的是读锁,后续的goroutine能读不能写
写的goroutine来了获取的是写锁,后续的goroutine不管是读还是写都要等待获取锁
需要注意的是读写锁非常适合读多写少的场景,如果读和写的操作差别不大,读写锁的优势就发挥不出来
*/
var (
x = 0
wg sync.WaitGroup
lock sync.Mutex //互斥锁
rwLock sync.RWMutex //读写互斥锁
)
// 读操作
func read() {
defer wg.Done()
//lock.Lock() //互斥锁
rwLock.RLock() //读写锁的读锁
time.Sleep(time.Millisecond * 2)
//lock.Unlock() //互斥锁
rwLock.RUnlock() //读写锁的读锁
}
// 写操作
func write() {
defer wg.Done()
//lock.Lock() //互斥锁
rwLock.Lock() //读写锁的写锁
x = x + 1
time.Sleep(time.Millisecond * 20)
//lock.Unlock() //互斥锁
rwLock.Unlock() //读写锁的写锁
}
func main() {
// 模拟读多写少的操作,写操作耗时多,但是次数少;读操作耗时少,但是次数多
start := time.Now() //开始时间
// 读的量是写的量的100倍
// 写操作
for i := 0; i < 10; i++ {
wg.Add(1)
go write()
}
time.Sleep(time.Second * 1) //由于写太慢了,等写入完成以后再去读
//读操作
for i := 0; i < 1000; i++ {
wg.Add(1)
go read()
}
wg.Wait()
fmt.Printf("总耗时:%s\n", time.Now().Sub(start))
}
/*
结果
使用互斥锁耗时 总耗时:3.416285879 s
使用读写互斥锁耗时 总耗时:1.008857085s
*/
sync.Once
package main
import (
"fmt"
"sync"
)
/*
sync.Once
在编程的很多场景下我们需要确保某些操作在高并发的场景下只执行一次,例如只加载一次配置文件、只关闭一次通道等
Go语言中的sync包中提供了一个针对只执行一次场景的解决方案sync.Once
sync.Once只有一个Do方法,其签名如下:
func (o *Once) Do(f func()) {}
*/
var wg sync.WaitGroup
var once sync.Once
func f1(ch1 chan<- int) {
defer wg.Done()
for i := 0; i < 100; i++ {
ch1 <- i
}
close(ch1) //关闭通道ch1
}
func f2(ch1 <-chan int, ch2 chan<- int) {
defer wg.Done()
for {
x, ok := <-ch1
if !ok {
break //这里不能用return,要用break结束循环,然后调用wg.Done(),不然会出现死锁
}
ch2 <- x * 2
}
// 多次关闭通道会报错
//func() {
// close(ch2)
//}()
//确保只关闭一次通道ch2
once.Do(func() {
close(ch2)
})
}
func main() {
a := make(chan int, 100)
b := make(chan int, 100)
wg.Add(3)
go f1(a)
go f2(a, b)
go f2(a, b)
wg.Wait()
for ret := range b {
fmt.Println(ret)
}
}
sync.Map
package main
import (
"fmt"
"strconv"
"sync"
)
// Go语言中内置的map不是并发安全的,超过一定个数的并发写入肯定报错
var m = make(map[string]int)
var lock sync.Mutex
var wg sync.WaitGroup
func get(key string) int {
return m[key]
}
func set(key string, value int) {
m[key] = value
}
func main() {
for i := 0; i < 100; i++ {
wg.Add(1)
go func(n int) {
key := strconv.Itoa(n) //转换成字符串类型的数字
lock.Lock() //互斥锁
set(key, n) //调用set函数
lock.Unlock() //互斥锁
fmt.Printf("k=%v, v=%v\n", key, get(key))
wg.Done()
}(i)
}
wg.Wait()
}
/*
执行结果会报错
*/
package main
import (
"fmt"
"strconv"
"sync"
)
/*
[sync.Map]
Go语言的sync包中提供了一个开箱即用的并发安全版map, sync.Map
开箱即用表示不用像内置的map一样使用make函数初始化就能直接使用。
同时sync.Map内置了诸如Store、Load、LoadOrStore、Delete、Range等操作方法
*/
var (
m2 = sync.Map{}
wg1 sync.WaitGroup
)
func main() {
for i := 0; i < 200; i++ {
wg1.Add(1)
go func(n int) {
key := strconv.Itoa(n) //int --> string
m2.Store(key, n) //写入
value, _ := m2.Load(key) //读取
fmt.Printf("k=%#v, v=%#v\n", key, value)
wg1.Done()
}(i)
}
wg1.Wait()
}
自定义日志库练习
目录结构
├── README
├── logs
│ ├── test.log
│ └── test.log.err
├── main.go
└── mylog
├── README
├── conlog.go
├── filelog.go
└── mylog.go
README需求
### 需求分析
1. 支持往不同的地方输出日志(日志文件和终端)
2. 日志分级别
1. Debug
2. Trace
3. Info
4. Warning
5. Error
6. Fatal
3. 日志要支持开关控制,比如说开发的时候什么级别都能输出,但是上线之后只有INFO级别往下的才能输出
4. 完整的日志记录要包含有时间、行号、文件名、日志级别、日志信息
4.1 格式化输出
5. 日志文件要切割
1. 按文件大小切割
1. 每次记录日志之前都判断一下当前写的这个文件的文件大小
2. 按日期切割 ***未完成
1. 在日志结构体中设置一个字段记录上一次切割的小时数
2. 在写日志之前检查一下当前时间的小时数和之前保存的是否一致,不一致就要切割
main.go
package main
import (
"code.oldboyedu.com/gostudy/day07/99homework/mylog"
)
//终端输出日志
//参数1: 日志等级[debug trace info warning error fatal]
//参数2: 是否记录日志 true:记录
var conlog mylog.ConLog = mylog.NewConLog("debug", true)
//往文件写日志
//参数1: 日志等级[debug trace info warning error fatal]
//参数2: 目录名称
//参数3: 文件名称
//参数4: 每个日志文件保存大小(单位:B)
//参数5: 是否记录日志 true:记录
var fileLog mylog.FileLog = *mylog.NewFileLog("Debug", "./logs", "test.log", 5*1024*1024, true)
func f1() {
id := 1
name := "alnk"
conlog.Debug("f1(debug) id:%d name:%s", id, name)
conlog.Trace("f1(Trace).......")
conlog.Info("f1(Info).......")
conlog.Warning("f1(Warning).......")
conlog.Error("f1(Error).......")
conlog.Fatal("f1(Fatal).......")
}
func f2() {
conlog.Debug("f2(debug).......")
conlog.Trace("f2(Trace).......")
conlog.Info("f2(Info).......")
conlog.Warning("f2(Warning).......")
conlog.Error("f2(Error).......")
conlog.Fatal("f2(Fatal).......")
}
func f3() {
for {
id := 1
name := "alnk"
fileLog.Debug("f3(debug)..id: %d name: %s", id, name)
fileLog.Trace("f3(Trace).......")
fileLog.Info("f3(Info).......")
fileLog.Warning("f3(Warning).......")
fileLog.Error("f3(Error).......")
fileLog.Fatal("f3(Fatal).......")
}
}
func main() {
//f1()
//f2()
f3()
}
mylog/README
//终端输出日志
//参数1: 日志等级[debug trace info warning error fatal]
//参数2: 是否记录日志 true:记录
var conlog mylog.ConLog = mylog.NewConLog("error", false)
//往文件写日志
//参数1: 日志等级[debug trace info warning error fatal]
//参数2: 目录名称
//参数3: 文件名称
//参数4: 每个日志文件保存大小(单位:B)
//参数5: 是否记录日志 true:记录
var fileLog mylog.FileLog = *mylog.NewFileLog("Debug", "./logs", "test.log", 1*1024*1024, true)
//示例
conlog.Debug("f1(debug).......")
conlog.Trace("f1(Trace).......")
conlog.Info("f1(Info).......")
conlog.Warning("f1(Warning).......")
conlog.Error("f1(Error).......")
conlog.Fatal("f1(Fatal).......")
fileLog.Debug("f3(debug).......")
fileLog.Trace("f3(Trace).......")
fileLog.Info("f3(Info).......")
fileLog.Warning("f3(Warning).......")
fileLog.Error("f3(Error).......")
fileLog.Fatal("f3(Fatal).......")
mylog/mylog.go
package mylog
import (
"errors"
"path"
"runtime"
"strings"
)
/*
思路:直接通过 通道 当做中间件临时存储日志信息
一个主线程往里面写日志内容,另外一个线程负责从通道中把日志信息拿出来写入到文件
//var conlog mylog.ConLog = mylog.NewConLog("error", false)
//终端输出日志
//参数1: 日志等级[debug trace info warning error fatal]
//参数2: 是否记录日志 true:记录
//var fileLog mylog.FileLog = *mylog.NewFileLog("Debug", "./logs", "test.log", 5*1024*1024, true)
//往文件写日志(异步写入)
//参数1: 日志等级[debug trace info warning error fatal]
//参数2: 目录名称
//参数3: 文件名称
//参数4: 每个日志文件保存大小(单位:B)
//参数5: 是否记录日志 true:记录
//使用方法示例
1.往终端
var conlog mylog.ConLog = mylog.NewConLog("error", false)
conlog.Debug("f1(debug).......")
2.往文件
var fileLog mylog.FileLog = *mylog.NewFileLog("Debug", "./logs", "test.log", 5*1024*1024, true)
fileLog.Debug("f3(debug)..id: %d name: %s", id, name)
fileLog.Trace("f3(Trace).......")
*/
//日志等级常量
const (
UNKNOW uint8 = iota
DEBUG
TRACE
INFO
WARNING
ERROR
FATAL
)
//parseLogLevelToUint8 解析日志等级参数,把字符串转换为unit8类型
func parseLogLevelToUint8(s string) (uint8, error) {
switch strings.ToLower(s) {
case "debug":
return DEBUG, nil
case "trace":
return TRACE, nil
case "info":
return INFO, nil
case "warning":
return WARNING, nil
case "error":
return ERROR, nil
case "fatal":
return FATAL, nil
default:
err := errors.New("无效的日志级别!")
return UNKNOW, err
}
}
//parseLogLevelToString 把日志等级从uint8转为string
func parseLogLevelToInt8(lv uint8) (level string) {
switch lv {
case DEBUG:
return "DEBUG"
case TRACE:
return "TRACE"
case INFO:
return "INFO"
case WARNING:
return "WARNING"
case ERROR:
return "ERROR"
case FATAL:
return "FATAL"
default:
return "UNKNOW"
}
}
//获取打印日志时的行号和文件名称信息
func getLogInfo(skip int) (fileName, funcName string, lineNo int) {
pc, file, line, ok := runtime.Caller(skip)
if !ok {
return
}
funcName = runtime.FuncForPC(pc).Name() //函数名
fileName = path.Base(file) //文件名
lineNo = line //行号
return
}
mylog/conlog.go
package mylog
import (
"fmt"
"time"
)
//终端日志结构体
type ConLog struct {
Level string //日志级别[debug trace info warning error fatal]
Tag bool //是否在终端输出日志 true:输出
}
//NewConLog 结构体构造函数
func NewConLog(s string, t bool) ConLog {
return ConLog{
Level: s,
Tag: t,
}
}
//log 往终端输出日志的方法
func (c ConLog) log(lvl uint8, msg string, a ...interface{}) {
msg = fmt.Sprintf(msg, a...)
level, err := parseLogLevelToUint8(c.Level)
if err != nil {
fmt.Println(err)
return
}
//转换日志级别的数据类型,用于终端输出
lvlString := parseLogLevelToInt8(lvl)
// 获取行号文件名函数名等信息
fileName, funcName, lineNo := getLogInfo(3)
//日志等级判断和是否终端打印
if level <= lvl && c.Tag {
//获取当前格式化时间
dateString := time.Now().Format("2006/01/02 15:04:05")
//[时间][级别][文件名:函数名:行号][日志内容]
fmt.Printf("[%s] [%s] [%s:%s:%d] [%s]\n", dateString, lvlString, fileName, funcName, lineNo, msg)
}
}
//Debug 方法
func (c ConLog) Debug(msg string, a ...interface{}) {
c.log(DEBUG, msg, a...)
}
//Trace 方法
func (c ConLog) Trace(msg string, a ...interface{}) {
c.log(TRACE, msg, a...)
}
//Info 方法
func (c ConLog) Info(msg string, a ...interface{}) {
c.log(INFO, msg, a...)
}
//Warning 方法
func (c ConLog) Warning(msg string, a ...interface{}) {
c.log(WARNING, msg, a...)
}
//Error 方法
func (c ConLog) Error(msg string, a ...interface{}) {
c.log(ERROR, msg, a...)
}
//
func (c ConLog) Fatal(msg string) {
c.log(FATAL, msg)
}
mylog/filelog.go
package mylog
import (
"fmt"
"os"
"path"
"time"
)
//logMsg 通道中的日志结构体
type logMsg struct {
level uint8 //日志等级
fileName string //日志名称
dateString string //日志时间
funcName string //函数名
lineNo int //行号
msg string //日志内容
}
//FileLog 用户调用日志包时候的结构体
type FileLog struct {
Level string //日志级别[debug trace info warning error fatal]
Tag bool //是否在文件输出日志 true:输出
PathName string //日志文件路径
FileName string //日志文件名称
FileObj *os.File //日志文件句柄
FileObjErr *os.File //错误日志文件句柄
FileSize int64 //日志文件大小
logChan chan *logMsg //日志通道
}
//NewFileLog 结构体构造函数
func NewFileLog(level, pathName, fileName string, fileSize int64, t bool) *FileLog {
//1.程序包被调用的时候,就要创建日志文件目录和日志文件错误文件
fileObj := openLogFile(pathName, fileName) //一般日志文件
errFileName := fileName + ".err"
fileObjErr := openLogFile(pathName, errFileName) //错误日志文件
//2.构造返回的结构体指针
fl := &FileLog{
Level: level,
Tag: t,
PathName: pathName,
FileName: fileName,
FileObj: fileObj, //文件句柄
FileObjErr: fileObjErr, //错误日志文件句柄
FileSize: fileSize, //日志文件大小
logChan: make(chan *logMsg, 5), //通道初始化
}
//2.从通道中取出数据写入文件 开启goroutine
go fl.logReadChanWriteFile()
return fl
}
//######################################################################################################################
//##################################### 往通道中写入日志内容开始 ##########################################################
//######################################################################################################################
//logWriteChan 把日志写入到通道中
func (f *FileLog) logWriteChan(selfLevel uint8, msg string, a ...interface{}) {
//1.判断日志等级,达标的写入通道
//1.1用户自己设置的日志等级转化为uint8类型,好进行比较
userLevel, err := parseLogLevelToUint8(f.Level)
if err != nil {
fmt.Printf("等级设置有问题,err:%v\n", err)
return
}
//2.写入通道
if userLevel <= selfLevel && f.Tag {
//2.1拼接日志文件具体内容
msg = fmt.Sprintf(msg, a...)
// 获取行号文件名函数名等信息
fileName, funcName, lineNo := getLogInfo(3)
//获取当前格式化时间
dateString := time.Now().Format("2006/01/02 15:04:05")
//组装结构体内容,把日志的结构体指针写入通道,节省内存空间
logTmp := &logMsg{
level: selfLevel,
fileName: fileName,
dateString: dateString,
funcName: funcName,
lineNo: lineNo,
msg: msg,
}
select {
case f.logChan <- logTmp:
default:
//如果通道中存储满了就丢掉日志
}
}
}
//6种级别的日志 写入到通道中
//Debug 方法
func (f *FileLog) Debug(msg string, a ...interface{}) {
f.logWriteChan(DEBUG, msg, a...)
}
//Trace 方法
func (f *FileLog) Trace(msg string, a ...interface{}) {
f.logWriteChan(TRACE, msg, a...)
}
//Info 方法
func (f *FileLog) Info(msg string, a ...interface{}) {
f.logWriteChan(INFO, msg, a...)
}
//Warning 方法
func (f *FileLog) Warning(msg string, a ...interface{}) {
f.logWriteChan(WARNING, msg, a...)
}
//Error 方法
func (f *FileLog) Error(msg string, a ...interface{}) {
f.logWriteChan(ERROR, msg, a...)
}
//Fatal 方法
func (f *FileLog) Fatal(msg string, a ...interface{}) {
f.logWriteChan(FATAL, msg, a...)
}
//######################################################################################################################
//##################################### 往通道中写入日志内容结束 ###########################################################
//######################################################################################################################
//######################################################################################################################
//##################################### 从通道中读取日志内容写入到日志文件中开始 ##############################################
//######################################################################################################################
//openLogFile 打开日志记录文件
func openLogFile(pathName, fileName string) *os.File {
//日志文件全路径和名称
logFileName := path.Join(pathName, fileName)
fileObj, err := os.OpenFile(logFileName, os.O_CREATE|os.O_APPEND|os.O_WRONLY, 0644)
//日志记录文件不能打开直接退出程序
if err != nil {
fmt.Println("open log file failed, err:%v\n", err)
os.Exit(1)
}
return fileObj
}
//logReadChanWriteFile 从通道中读取日志写入文件
func (f *FileLog) logReadChanWriteFile() {
for {
//日志文件即将写入的时候判断一下日志文件的大小,看是否要切割日志文件
if f.checkLogFileSize(f.FileObj) {
//切割日志文件
newFileObj, err := f.splitLogFile(f.FileObj)
if err != nil {
return
}
f.FileObj = newFileObj
//time.Sleep(time.Second)
}
select {
//从通道中读取日志
case logTmp := <-f.logChan:
//拼接要写入的日志内容
levelString := parseLogLevelToInt8(logTmp.level) //把日志等级从uint8转为字符串类型
//[时间][级别][文件名:函数名:行号][日志内容]
logInfo := fmt.Sprintf("[%s] [%s] [%s:%s:%d] [%s]\n", logTmp.dateString, levelString, logTmp.fileName, logTmp.funcName, logTmp.lineNo, logTmp.msg)
fmt.Fprintf(f.FileObj, logInfo) //写入到文件
//如果日志等级大于ERROR,还要额外的写入到 err 文件中
if logTmp.level >= ERROR {
if f.checkLogFileSize(f.FileObjErr) {
newFileObj, err := f.splitLogFile(f.FileObjErr)
if err != nil {
return
}
f.FileObjErr = newFileObj
}
//写入文件
fmt.Fprintf(f.FileObjErr, logInfo)
}
default:
//取不到日志的话,就休息500毫秒
time.Sleep(time.Millisecond * 500)
}
}
}
//checkLogFileSize 检查日志文件的大小
func (f *FileLog) checkLogFileSize(file *os.File) bool {
//获取当前日志文件的信息
fileInfo, err := file.Stat()
if err != nil {
fmt.Printf("get file info failed22222, err:%v\n", err)
return false
}
//如果当前文件大小 大于等于 日志文件的最大值,返回true
return fileInfo.Size() >= f.FileSize
}
//splitLogFile 切割日志文件
func (f *FileLog) splitLogFile(file *os.File) (*os.File, error) {
//1.获取需要切割的日志文件基础信息
fileInfo, err := file.Stat()
if err != nil {
fmt.Printf("get file info failed, err:%v\n", err)
return nil, err
}
//2.拿到当前的日志文件完整路径
logName := path.Join(f.PathName, fileInfo.Name())
//3.拼接成一个备份的名字
nowStr := time.Now().Format("200601021504050000")
newLogName := fmt.Sprintf("%s.bak%s", logName, nowStr)
//4.关闭当前的日志文件
file.Close()
//5.备份
os.Rename(logName, newLogName)
//6.打开一个新的日志文件
fileObj, err := os.OpenFile(logName, os.O_CREATE|os.O_APPEND|os.O_WRONLY, 0644)
if err != nil {
fmt.Printf("open new log file failed, err:%v\n", err)
return nil, err
}
//7.将打开的新日志文件句柄(对象、指针)赋值给fileobj
return fileObj, nil
}
//######################################################################################################################
//##################################### 从通道中读取日志内容写入到日志文件中结束 ##############################################
//######################################################################################################################
Golang语言系列-11-goroutine并发的更多相关文章
- Golang语言系列-14-单元测试
单元测试 字符串切割函数 package split_string import ( "fmt" "strings" ) // Split:切割字符串 // e ...
- Golang语言系列-07-函数
函数 函数的基本概念 package main import ( "fmt" ) // 函数 // 函数存在的意义:函数能够让代码结构更加清晰,更简洁,能够让代码复用 // 函数是 ...
- Golang语言系列-10-包
包 自定义包 package _0calc import ( "fmt" ) /* [Go语言的包] 在工程化的Go语言开发项目中,Go语言的源码复用是建立在包(package)基 ...
- Golang语言系列-01-Go语言简介和变量
Go语言简介 Go(又称Golang)是Google开发的一种静态强类型.编译型.并发型,并具有垃圾回收功能的编程语言. 罗伯特·格瑞史莫(Robert Griesemer),罗勃·派克(Rob Pi ...
- Golang语言系列-17-Gin框架
Gin框架 Gin框架简介 package main import ( "github.com/gin-gonic/gin" "io" "net/ht ...
- Golang语言系列-15-数据库
数据库 MySQL 连接数据库 package main import ( "database/sql" "fmt" _ "github.com/go ...
- Golang语言系列-12-网络编程
网络编程 互联网协议介绍 互联网的核心是一系列协议,总称为"互联网协议"(Internet Protocol Suite),正是这一些协议规定了电脑如何连接和组网.我们理解了这些协 ...
- Golang语言系列-05-数组和切片
数组和切片 数组 概念 数组是同一种数据类型元素的集合:数组的长度必须是常量,并且长度是数组类型的一部分,一旦定义,长度不能变 例如:[5]int 和 [10]int 是不同的数组类型 使用时可以修改 ...
- Golang语言系列-02-常用数据类型
Go语言常用数据类型 Go 语言中有丰富的数据类型,除了基本的整型.浮点型.布尔型.字符串.byte/rune 之外, 还有数组.切片.函数.map.通道(channel).结构体等. Go语言的基本 ...
随机推荐
- Mweb发布blog到各博客平台
Mweb发布blog到各博客平台 主流博客平台 博客平台 博客园 CSDN 51CTO 博客类型 MetaWeblog API MetaWeblog API MetaWeblog API 博客网址 h ...
- linux 之sed用法
sed:Stream Editor文本流编辑,sed是一个"非交互式的"面向字符流的编辑器.在使用sed处理时,它把当前处理的行存储在临时缓冲区中,称为"模式空间&quo ...
- python 正则表达式 初级
举例: 1.匹配hello world key = r"<h1>hello world<h1>" #源文本 p1 = r"<h1>.+ ...
- NSURLSession的简单使用
NSURLSession的简单使用(不同于NSURLConnection,仅仅支持异步请求) dataTask,简单请求直接block里面执行,不走代理 NSURLSessionDataTaskDel ...
- C语言字符串处理库函数大全(转)
一.string.h中字符串处理函数 在头文件<string.h>中定义了两组字符串函数.第一组函数的名字以str开头:第二组函数的名字以mem开头. 只有函数memmove对重叠对象间的 ...
- postgresql行列转换
--安装扩展 CREATE EXTENSION tablefunc --使用CROSSTAB函数 SELECT * FROM CROSSTAB('SELECT 主键, 需转换的列名, 需转换的列值 F ...
- DHCP工作原理
DHCP:Dynamic Host Configurtion Protocol DHCP的工作原理(UDP) 1.客户端:首先会发送给一个dhcp discovery(广播)报文,报文中的2层和3层都 ...
- NTP时间服务器配置
1.服务器端配置: #允许这些IP向自己同步时间 restrict x.x.x.x mask x.x.x.x nomodiy notrap #当和定义的所有server服务器无法同步后,和自身同步 s ...
- 关于java异常处理的思考
学习java的过程中,初学者更多的是为了实验而写代码,而不考虑实际情况中的人机交互过程中的一些问题. 在java项目中,更多的用户不会因为你给了某些限制提醒,他就一定会按照你所给的提示来输入或者操作, ...
- [刘阳Java]_MyBatis_实体关系映射_第8讲
MyBatis既然是一个ORM框架,则它也有像Hibernate那样的一对多,多对多,多对一的实体关系映射功能.下面我们就来介绍一下如何使用MyBatis的实体关系映射 1.MyBatis实体关系映射 ...