第05讲:Flink SQL & Table 编程和案例
Flink系列文章
- 第01讲:Flink 的应用场景和架构模型
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
- 第03讲:Flink 的编程模型与其他框架比较
- 第04讲:Flink 常用的 DataSet 和 DataStream API
- 第05讲:Flink SQL & Table 编程和案例
- 第06讲:Flink 集群安装部署和 HA 配置
- 第07讲:Flink 常见核心概念分析
- 第08讲:Flink 窗口、时间和水印
- 第09讲:Flink 状态与容错
我们在第 02 课时中使用 Flink Table & SQL 的 API 实现了最简单的 WordCount 程序。在这一课时中,将分别从 Flink Table & SQL 的背景和编程模型、常见的 API、算子和内置函数等对 Flink Table & SQL 做一个详细的讲解和概括,最后模拟了一个实际业务场景使用 Flink Table & SQL 开发。
Flink Table & SQL 概述
背景
我们在前面的课时中讲过 Flink 的分层模型,Flink 自身提供了不同级别的抽象来支持我们开发流式或者批量处理程序,下图描述了 Flink 支持的 4 种不同级别的抽象。
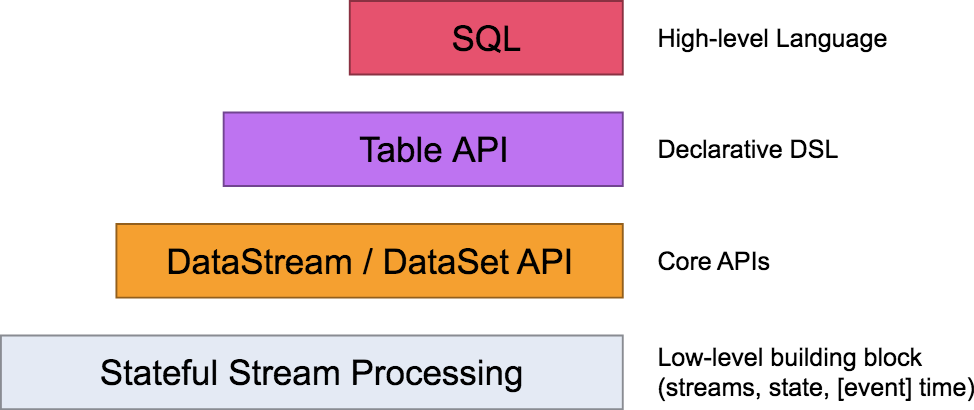
Table API 和 SQL 处于最顶端,是 Flink 提供的高级 API 操作。Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
我们在第 04 课时中提到过,Flink 在编程模型上提供了 DataStream 和 DataSet 两套 API,并没有做到事实上的批流统一,因为用户和开发者还是开发了两套代码。正是因为 Flink Table & SQL 的加入,可以说 Flink 在某种程度上做到了事实上的批流一体。
原理
你之前可能都了解过 Hive,在离线计算场景下 Hive 几乎扛起了离线数据处理的半壁江山。它的底层对 SQL 的解析用到了 Apache Calcite,Flink 同样把 SQL 的解析、优化和执行交给了 Calcite。
下图是一张经典的 Flink Table & SQL 实现原理图,可以看到 Calcite 在整个架构中处于绝对核心地位。

从图中可以看到无论是批查询 SQL 还是流式查询 SQL,都会经过对应的转换器 Parser 转换成为节点树 SQLNode tree,然后生成逻辑执行计划 Logical Plan,逻辑执行计划在经过优化后生成真正可以执行的物理执行计划,交给 DataSet 或者 DataStream 的 API 去执行。
在这里我们不对 Calcite 的原理过度展开,有兴趣的可以直接在官网上学习。一个完整的 Flink Table & SQL Job 也是由 Source、Transformation、Sink 构成:
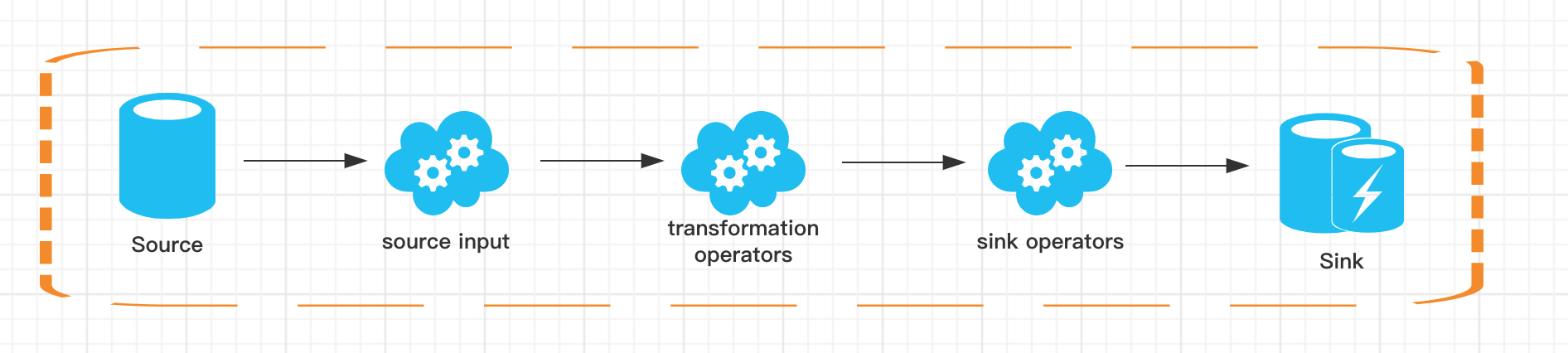
- Source 部分来源于外部数据源,我们经常用的有 Kafka、MySQL 等;
- Transformation 部分则是 Flink Table & SQL 支持的常用 SQL 算子,比如简单的 Select、Groupby 等,当然在这里也有更为复杂的多流 Join、流与维表的 Join 等;
- Sink 部分是指的结果存储比如 MySQL、HBase 或 Kakfa 等。
动态表
与传统的表 SQL 查询相比,Flink Table & SQL 在处理流数据时会时时刻刻处于动态的数据变化中,所以便有了一个动态表的概念。动态表的查询与静态表一样,但是,在查询动态表的时候,SQL 会做连续查询,不会终止。
我们举个简单的例子,Flink 程序接受一个 Kafka 流作为输入,Kafka 中为用户的购买记录:
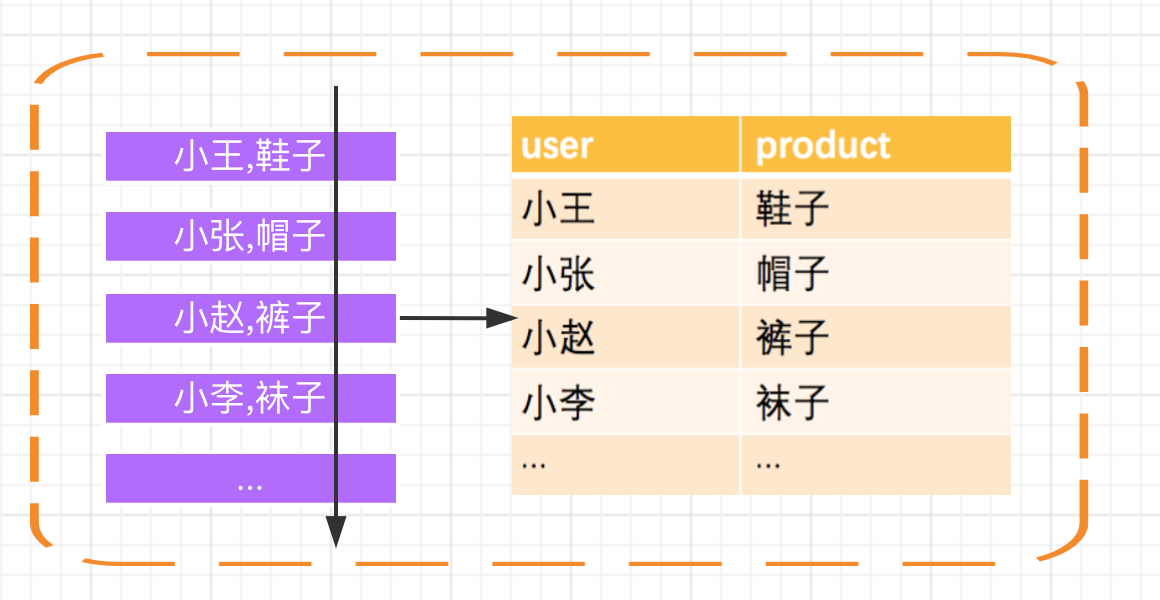
首先,Kafka 的消息会被源源不断的解析成一张不断增长的动态表,我们在动态表上执行的 SQL 会不断生成新的动态表作为结果表。
Flink Table & SQL 算子和内置函数
我们在讲解 Flink Table & SQL 所支持的常用算子前,需要说明一点,Flink 自从 0.9 版本开始支持 Table & SQL 功能一直处于完善开发中,且在不断进行迭代。我们在官网中也可以看到这样的提示:
Please note that the Table API and SQL are not yet feature complete and are being actively developed. Not all operations are supported by every combination of [Table API, SQL] and [stream, batch] input.
Flink Table & SQL 的开发一直在进行中,并没有支持所有场景下的计算逻辑。从我个人实践角度来讲,在使用原生的 Flink Table & SQL 时,务必查询官网当前版本对 Table & SQL 的支持程度,尽量选择场景明确,逻辑不是极其复杂的场景。
常用算子
目前 Flink SQL 支持的语法主要如下:
query:
values
| {
select
| selectWithoutFrom
| query UNION [ ALL ] query
| query EXCEPT query
| query INTERSECT query
}
[ ORDER BY orderItem [, orderItem ]* ]
[ LIMIT { count | ALL } ]
[ OFFSET start { ROW | ROWS } ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY]
orderItem:
expression [ ASC | DESC ]
select:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
FROM tableExpression
[ WHERE booleanExpression ]
[ GROUP BY { groupItem [, groupItem ]* } ]
[ HAVING booleanExpression ]
[ WINDOW windowName AS windowSpec [, windowName AS windowSpec ]* ]
selectWithoutFrom:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
projectItem:
expression [ [ AS ] columnAlias ]
| tableAlias . *
tableExpression:
tableReference [, tableReference ]*
| tableExpression [ NATURAL ] [ LEFT | RIGHT | FULL ] JOIN tableExpression [ joinCondition ]
joinCondition:
ON booleanExpression
| USING '(' column [, column ]* ')'
tableReference:
tablePrimary
[ matchRecognize ]
[ [ AS ] alias [ '(' columnAlias [, columnAlias ]* ')' ] ]
tablePrimary:
[ TABLE ] [ [ catalogName . ] schemaName . ] tableName
| LATERAL TABLE '(' functionName '(' expression [, expression ]* ')' ')'
| UNNEST '(' expression ')'
values:
VALUES expression [, expression ]*
groupItem:
expression
| '(' ')'
| '(' expression [, expression ]* ')'
| CUBE '(' expression [, expression ]* ')'
| ROLLUP '(' expression [, expression ]* ')'
| GROUPING SETS '(' groupItem [, groupItem ]* ')'
windowRef:
windowName
| windowSpec
windowSpec:
[ windowName ]
'('
[ ORDER BY orderItem [, orderItem ]* ]
[ PARTITION BY expression [, expression ]* ]
[
RANGE numericOrIntervalExpression {PRECEDING}
| ROWS numericExpression {PRECEDING}
]
')'
...
可以看到 Flink SQL 和传统的 SQL 一样,支持了包含查询、连接、聚合等场景,另外还支持了包括窗口、排序等场景。下面我就以最常用的算子来做详细的讲解。
SELECT/AS/WHERE
SELECT、WHERE 和传统 SQL 用法一样,用于筛选和过滤数据,同时适用于 DataStream 和 DataSet。
SELECT * FROM Table;
SELECT name,age FROM Table;
当然我们也可以在 WHERE 条件中使用 =、<、>、<>、>=、<=,以及 AND、OR 等表达式的组合:
SELECT name,age FROM Table where name LIKE '%小明%';
SELECT * FROM Table WHERE age = 20;
SELECT name, age
FROM Table
WHERE name IN (SELECT name FROM Table2)
GROUP BY / DISTINCT/HAVING
GROUP BY 用于进行分组操作,DISTINCT 用于结果去重。HAVING 和传统 SQL 一样,可以用来在聚合函数之后进行筛选。
SELECT DISTINCT name FROM Table;
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name;
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name HAVING
SUM(score) > 300;
JOIN
JOIN 可以用于把来自两个表的数据联合起来形成结果表,目前 Flink 的 Join 只支持等值连接。Flink 支持的 JOIN 类型包括:
JOIN - INNER JOIN
LEFT JOIN - LEFT OUTER JOIN
RIGHT JOIN - RIGHT OUTER JOIN
FULL JOIN - FULL OUTER JOIN
例如,用用户表和商品表进行关联:
SELECT *
FROM User LEFT JOIN Product ON User.name = Product.buyer
SELECT *
FROM User RIGHT JOIN Product ON User.name = Product.buyer
SELECT *
FROM User FULL OUTER JOIN Product ON User.name = Product.buyer
LEFT JOIN、RIGHT JOIN 、FULL JOIN 相与我们传统 SQL 中含义一样。
WINDOW
根据窗口数据划分的不同,目前 Apache Flink 有如下 3 种:
- 滚动窗口,窗口数据有固定的大小,窗口中的数据不会叠加;
- 滑动窗口,窗口数据有固定大小,并且有生成间隔;
- 会话窗口,窗口数据没有固定的大小,根据用户传入的参数进行划分,窗口数据无叠加;
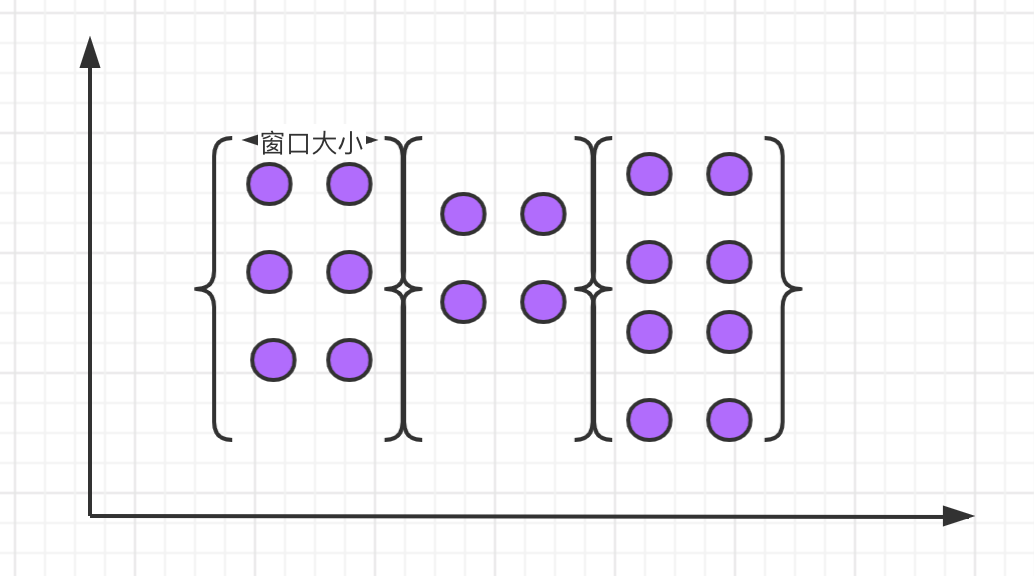
滚动窗口
滚动窗口的特点是:有固定大小、窗口中的数据不会重叠,如下图所示:
滚动窗口的语法:
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
举例说明,我们需要计算每个用户每天的订单数量:
SELECT user, TUMBLE_START(timeLine, INTERVAL '1' DAY) as winStart, SUM(amount) FROM Orders GROUP BY TUMBLE(timeLine, INTERVAL '1' DAY), user;
其中,TUMBLE_START 和 TUMBLE_END 代表窗口的开始时间和窗口的结束时间,TUMBLE (timeLine, INTERVAL '1' DAY) 中的 timeLine 代表时间字段所在的列,INTERVAL '1' DAY 表示时间间隔为一天。
滑动窗口
滑动窗口有固定的大小,与滚动窗口不同的是滑动窗口可以通过 slide 参数控制滑动窗口的创建频率。需要注意的是,多个滑动窗口可能会发生数据重叠,具体语义如下:
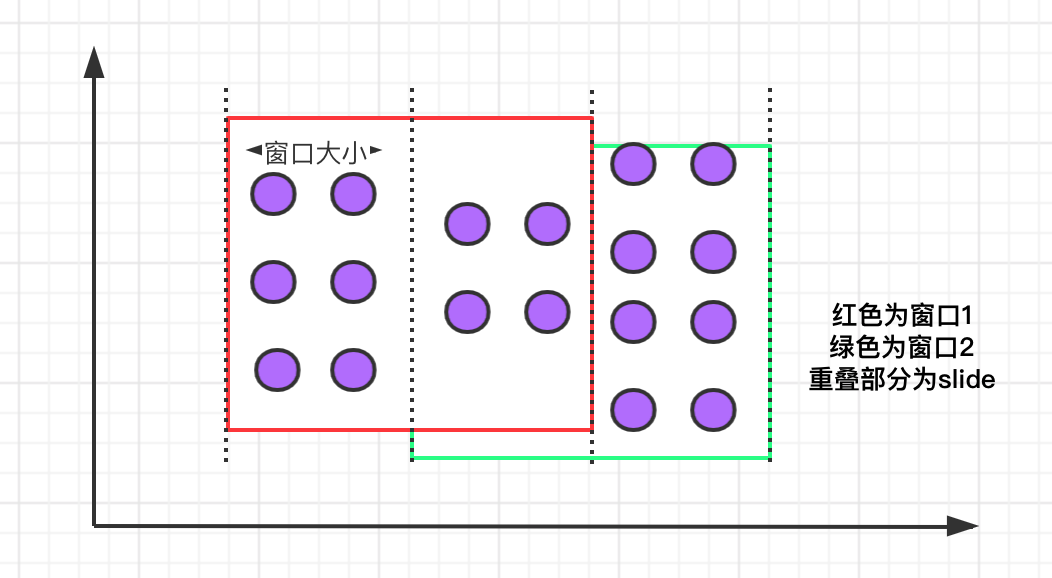
滑动窗口的语法与滚动窗口相比,只多了一个 slide 参数:
复制代码
SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
...
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
例如,我们要每间隔一小时计算一次过去 24 小时内每个商品的销量:
复制代码
SELECT product, SUM(amount) FROM Orders GROUP BY HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '1' DAY), product
上述案例中的 INTERVAL '1' HOUR 代表滑动窗口生成的时间间隔。
会话窗口
会话窗口定义了一个非活动时间,假如在指定的时间间隔内没有出现事件或消息,则会话窗口关闭。
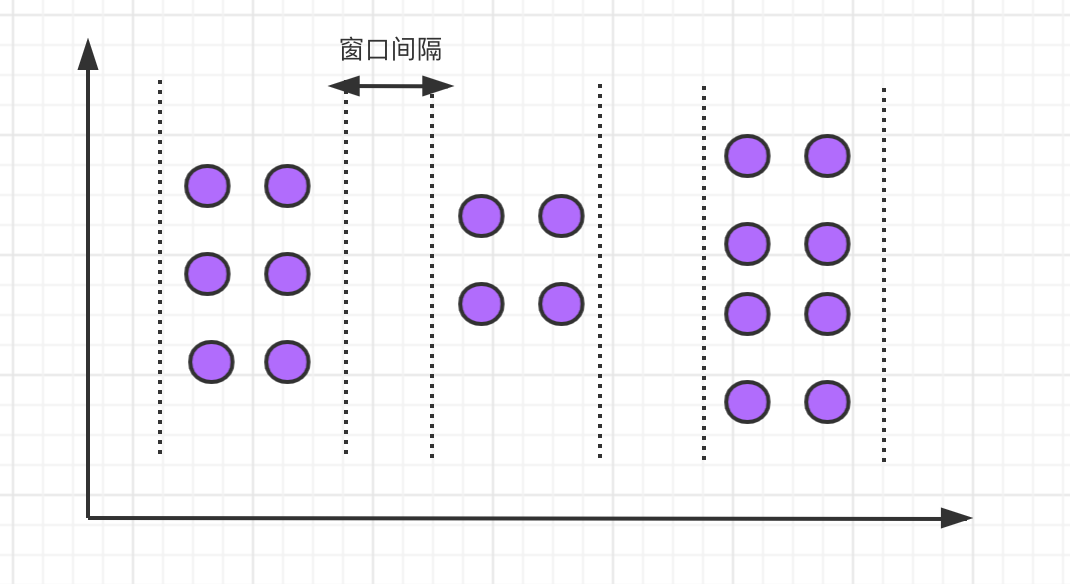
会话窗口的语法如下:
SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
举例,我们需要计算每个用户过去 1 小时内的订单量:
SELECT user, SESSION_START(rowtime, INTERVAL '1' HOUR) AS sStart, SESSION_ROWTIME(rowtime, INTERVAL '1' HOUR) AS sEnd, SUM(amount) FROM Orders GROUP BY SESSION(rowtime, INTERVAL '1' HOUR), user
内置函数
Flink 中还有大量的内置函数,我们可以直接使用,将内置函数分类如下:
- 比较函数
- 逻辑函数
- 算术函数
- 字符串处理函数
- 时间函数
比较函数

逻辑函数

算术函数
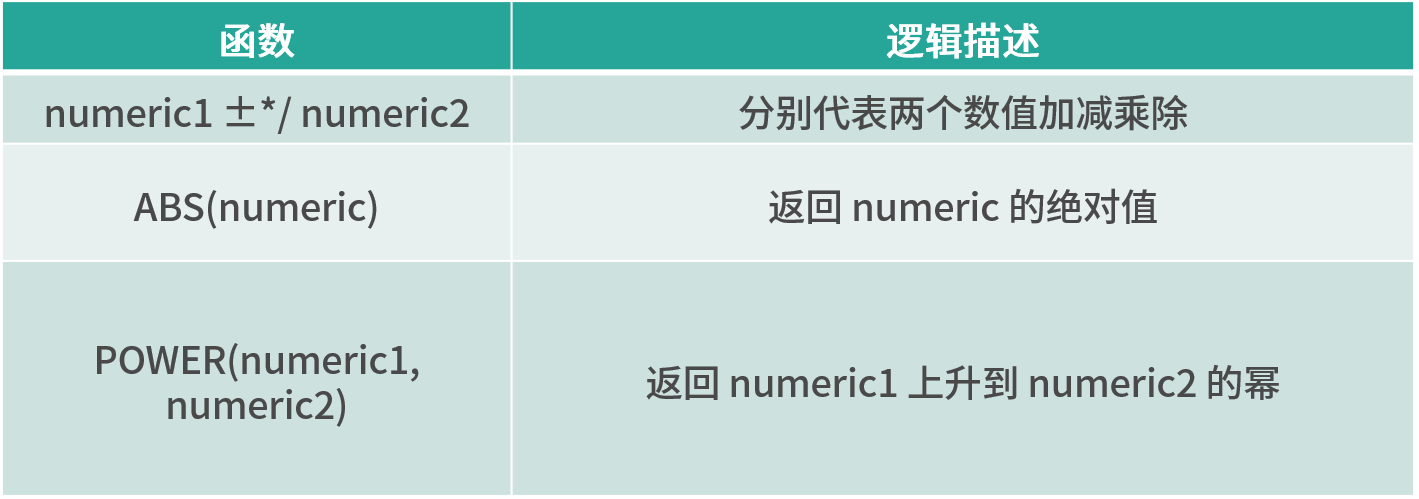
字符串处理函数

时间函数

Flink Table & SQL 案例
上面分别介绍了 Flink Table & SQL 的原理和支持的算子,我们模拟一个实时的数据流,然后讲解 SQL JOIN 的用法。
在上一课时中,我们利用 Flink 提供的自定义 Source 功能来实现一个自定义的实时数据源,具体实现如下:
复制代码
public class MyStreamingSource implements SourceFunction<Item> {
private boolean isRunning = true;
/**
* 重写run方法产生一个源源不断的数据发送源
*
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<Item> ctx) throws Exception {
while (isRunning) {
Item item = generateItem();
ctx.collect(item);
//每秒产生一条数据
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
}
//随机产生一条商品数据
private Item generateItem() {
int i = new Random().nextInt(100);
ArrayList<String> list = new ArrayList();
list.add("HAT");
list.add("TIE");
list.add("SHOE");
Item item = new Item();
item.setName(list.get(new Random().nextInt(3)));
item.setId(i);
return item;
}
}
我们把实时的商品数据流进行分流,分成 even 和 odd 两个流进行 JOIN,条件是名称相同,最后,把两个流的 JOIN 结果输出。
public class JoinDemo extends StreamJavaJob {
public static void main(String[] args) throws Exception {
initStreamJob(null, true);
SingleOutputStreamOperator<Item> source = env.addSource(new MyStreamingSource()).map(new MapFunction<Item, Item>() {
@Override
public Item map(Item item) throws Exception {
return item;
}
});
DataStream<Item> evenSelect = source.split(new OutputSelector<Item>() {
@Override
public Iterable<String> select(Item value) {
List<String> output = new ArrayList<>();
if (value.getId() % 2 == 0) {
output.add("even");
} else {
output.add("odd");
}
return output;
}
}).select("even");
DataStream<Item> oddSelect = source.split(new OutputSelector<Item>() {
@Override
public Iterable<String> select(Item value) {
List<String> output = new ArrayList<>();
if (value.getId() % 2 == 0) {
output.add("even");
} else {
output.add("odd");
}
return output;
}
}).select("odd");
stEnv.createTemporaryView("evenTable", evenSelect, "name,id");
stEnv.createTemporaryView("oddTable", oddSelect, "name,id");
Table queryTable = stEnv.sqlQuery("select a.id,a.name,b.id,b.name from evenTable as a join oddTable as b on a.name = b.name");
queryTable.printSchema();
stEnv.toRetractStream(queryTable, TypeInformation.of(new TypeHint<Tuple4<Integer,String,Integer,String>>(){})).print();
startStreaming();
}
}
直接右键运行,在控制台可以看到输出:
总结
我们在这一课时中讲解了 Flink Table & SQL 的背景和原理,并且讲解了动态表的概念;同时对 Flink 支持的常用 SQL 和内置函数进行了讲解;最后用一个案例,讲解了整个 Flink Table & SQL 的使用。
关注公众号:
大数据技术派,回复资料,领取1024G资料。
第05讲:Flink SQL & Table 编程和案例的更多相关文章
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- 从"UDF不应有状态" 切入来剖析Flink SQL代码生成
从"UDF不应有状态" 切入来剖析Flink SQL代码生成 目录 从"UDF不应有状态" 切入来剖析Flink SQL代码生成 0x00 摘要 0x01 概述 ...
- [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版)
[源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版) 目录 [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码 ...
- 使用flink Table &Sql api来构建批量和流式应用(3)Flink Sql 使用
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- 8、Flink Table API & Flink Sql API
一.概述 上图是flink的分层模型,Table API 和 SQL 处于最顶端,是 Flink 提供的高级 API 操作.Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时 ...
- Flink SQL 核心概念剖析与编程案例实战
本次,我们从 0 开始逐步剖析 Flink SQL 的来龙去脉以及核心概念,并附带完整的示例程序,希望对大家有帮助! 本文大纲 一.快速体验 Flink SQL 为了快速搭建环境体验 Flink SQ ...
- [Note] Apache Flink 的数据流编程模型
Apache Flink 的数据流编程模型 抽象层次 Flink 为开发流式应用和批式应用设计了不同的抽象层次 状态化的流 抽象层次的最底层是状态化的流,它通过 ProcessFunction 嵌入到 ...
- Oracle SQL高级编程——分析函数(窗口函数)全面讲解
Oracle SQL高级编程--分析函数(窗口函数)全面讲解 注:本文来源于:<Oracle SQL高级编程--分析函数(窗口函数)全面讲解> 概述 分析函数是以一定的方法在一个与当前行相 ...
- OPPO数据中台之基石:基于Flink SQL构建实数据仓库
小结: 1. OPPO数据中台之基石:基于Flink SQL构建实数据仓库 https://mp.weixin.qq.com/s/JsoMgIW6bKEFDGvq_KI6hg 作者 | 张俊编辑 | ...
随机推荐
- 【LeetCode】1408. 数组中的字符串匹配 String Matching in an Array
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 暴力遍历 日期 题目地址:https://leetco ...
- Android 控件使用教程(二)—— RecyclerView 展示图片
简介 在上一篇博文中,介绍了大家已经很熟悉的布局控件ListView,在这篇文章中,我将使用比较新.功能也更强大的RecyclerView. RecyclerView 首先,要用这个控件,你需要在gr ...
- KISS原则
Keep It Simple, Stupid 1. 模块性原则:写简单的,通过干净的接口可被连接的部件:2. 清楚原则:清楚要比小聪明好.3. 合并原则:设计能被其它程序连接的程序.4. 分离原则:从 ...
- CS5262设计DP转HDMI 4K60HZ +VGA 1080P方案芯片
CS5262是一款带嵌入式MCU的4通道DisplayPort1.4到HDMI2.0/VGA转换器芯片,设计用于将DP1.4信号源连接到HDMI2.0接收器.CS5262集成了DP1.4兼容接收机和H ...
- JDK Httpclient 使用和性能测试
Httpclient 使用和性能测试 上篇,通过简介和架构图,我们对HttpClient有了初步的了解. 本篇我们展示HttpClient的简单使用,同时为了说明httpclient的使用性能,我们将 ...
- 『无为则无心』Python函数 — 34、lambda表达式
目录 1.lambda的应用场景 2.lambda语法 3.快速入门 4.示例:计算a + b 5.lambda的参数形式 6.lambda的应用 lambda表达式的主要作用就是化简代码. 匿名函数 ...
- Linux shell 脚本中使用 alias 定义的别名
https://www.cnblogs.com/chenjo/p/11145021.html 核心知识点: 用 shopt 开启和关闭 alias 扩展 交互模式下alias 扩展默认是开启的,脚本模 ...
- Linux查看进程启动时间和运行多长时间
Linux 查看进程启动时间和运行多长时间 启动时间 ps -eo lstart 运行多长时间 ps -eo etime -bash-4.1$ ps -eo pid,lstart,etime | gr ...
- LC 二叉树的最大深度
https://leetcode-cn.com/leetbook/read/top-interview-questions-easy/xnd69e/ Recursion /** * Definitio ...
- Golang中Label的用法
在Golang中能使用Label的有goto, break, continue.,这篇文章就介绍下Golang中Label使用和注意点. 注意点: Label在continue, break中是可选的 ...