数据集成工具—Sqoop
数据集成/采集/同步工具

@
Sqoop简介
sqoop将关系型数据库(mysql、oracle等)数据与hadoop数据进行转换的工具。
sqoop1.4.x与sqoop1.99.x完全不兼容
Sqoop安装
安装包资源主页自取
1、上传并解压
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local/soft/
2、修改文件夹名字
mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop-1.4.7
3、修改配置文件
# 切换到sqoop配置文件目录
cd /usr/local/soft/sqoop-1.4.7/conf
# 复制配置文件并重命名
cp sqoop-env-template.sh sqoop-env.sh
# vim sqoop-env.sh 编辑配置文件,并加入以下内容
export HADOOP_COMMON_HOME=/usr/local/soft/hadoop-2.7.6
export HADOOP_MAPRED_HOME=/usr/local/soft/hadoop-2.7.6/share/hadoop/mapreduce
export HBASE_HOME=/usr/local/soft/hbase-1.4.6
export HIVE_HOME=/usr/local/soft/hive-1.2.1
export ZOOCFGDIR=/usr/local/soft/zookeeper-3.4.6/conf
export ZOOKEEPER_HOME=/usr/local/soft/zookeeper-3.4.6
# 切换到bin目录
cd /usr/local/soft/sqoop-1.4.7/bin
# vim configure-sqoop 修改配置文件,注释掉没用的内容(就是为了去掉警告信息)

4、修改环境变量
vim /etc/profile
# 将sqoop的目录加入环境变量
export SQOOP_HOME=/usr/local/soft/sqoop-1.4.7
5、添加MySQL连接驱动
# 从HIVE中复制MySQL连接驱动到$SQOOP_HOME/lib
cp /usr/local/soft/hive-1.2.1/lib/mysql-connector-java-5.1.49.jar /usr/local/soft/sqoop-1.4.7/lib/
6、测试
# 打印sqoop版本
sqoop version
# 测试MySQL连通性
sqoop list-databases -connect jdbc:mysql://master:3306?useSSL=false -username root -password 123456
准备MySQL数据
登录MySQL数据库
mysql -u root -p123456;
创建student数据库
create database student;
切换数据库并导入数据
# mysql shell中执行
use student;
source /root/student.sql;
source /root/score.sql;
另外一种导入数据的方式
# linux shell中执行
mysql -u root -p123456 student</root/student.sql
mysql -u root -p123456 student</root/score.sql
使用Navicat运行SQL文件
也可以通过Navicat导入
导出MySQL数据库
mysqldump -u root -p123456 数据库名>/路径/任意一个文件名.sql
import
从传统的关系型数据库导入HDFS、HIVE、HBASE......
MySQLToHDFS
编写脚本,保存为MySQLToHDFS.conf
将下面内容写进脚本
import
--connect
jdbc:mysql://master:3306/student?useSSL=false
--username
root
--password
123456
--table
student
--m
2
--split-by
age
--target-dir
/sqoop/data/student1
--fields-terminated-by
','
属性解析
--m mapr任务
2 两个
--split-by 按照age切分
age
--target-dir hdfs路径
/sqoop/data/student1
--fields-terminated-by ',' 列之间的分隔符为,

运行方式一: 执行脚本
sqoop --options-file MySQLToHDFS.conf
运行方式二:直接在shell运行
sqoop import \
--connect \
jdbc:mysql://master:3306/student?useSSL=false \
--username \
root \
--password \
123456 \
--table \
student \
--m \
2 \
--split-by \
age \
--target-dir \
/sqoop/data/student1 \
--fields-terminated-by \
','

注意事项:
1、--m 表示指定生成多少个Map任务,不是越多越好,因为MySQL Server的承载能力有限。
2、当指定的Map任务数>1,那么需要结合--split-by参数,指定分割键,以确定每个map任务到底读取哪一部分数据,最好指定数值型的列,最好指定主键(或者分布均匀的列=>避免每个map任务处理的数据量差别过大),如果mysql建表时,设置了主键,并且是数值型,就会默认是按照主键切分,如果没有设置主键,报错。
3、如果指定的分割键数据分布不均,可能导致map端“数据倾斜”问题。
4、分割的键最好指定数值型的,而且字段的类型为int、bigint这样的数值型
5、编写脚本的时候,注意:例如:--username参数,参数值不能和参数名同一行
--username root // 错误的
// 应该分成两行
--username
root
6、运行的时候会报错InterruptedException,hadoop2.7.6自带的问题,忽略即可
21/01/25 14:32:32 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:716)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:476)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:652)
7、实际上sqoop在读取mysql数据的时候,用的是JDBC的方式,所以当数据量大的时候,效率不是很高。
8、sqoop底层通过MapReduce完成数据导入导出,只需要Map任务,不需要Reduce任务
9、每个Map任务会生成一个文件。
MySQLToHive
Sqoop 导入数据到 Hive 是通过先将数据导入到 HDFS 上的临时目录,然后再将数据从 HDFS 上 Load 到 Hive 中,最后将临时目录删除。可以使用 target-dir 来指定临时目录。
在Hive中创建testsqoop库
hive> create database testsqoop;
编写脚本,并保存为MySQLToHIVE.conf文件
import
--connect
jdbc:mysql://master:3306/student?useSSL=false
--username
root
--password
123456
--table
score
--fields-terminated-by
"\t"
--lines-terminated-by
"\n"
--m
3
--split-by
student_id
--hive-import
--hive-overwrite
--create-hive-table
--hive-database
testsqoop
--hive-table
score
--delete-target-dir
直接运行报错

将HADOOP_CLASSPATH加入环境变量中
vim /etc/profile
# 加入如下内容
export HADOOP_CLASSPATH=$HADOOP_HOME/lib:$HIVE_HOME/lib/*
# 重新加载环境变量
source /etc/profile
将hive-site.xml放入SQOOP_HOME/conf/
cp /usr/local/soft/hive-1.2.1/conf/hive-site.xml /usr/local/soft/sqoop-1.4.7/conf/
执行脚本
sqoop --options-file MySQLToHIVE.conf
--direct
加上这个参数,可以在导出MySQL数据的时候,使用MySQL提供的导出工具mysqldump,加快导出速度,提高效率
直接加上--direct,运行后报错
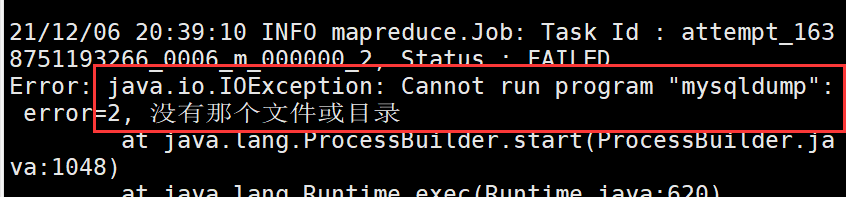
需要将master上的/usr/bin/mysqldump分发至 node1、node2的/usr/bin目录下
mapreduce任务在nodeManager上面执行的
scp /usr/bin/mysqldump node1:/usr/bin/
scp /usr/bin/mysqldump node2:/usr/bin/
-e参数的使用
-e 可以在后面加上sql语句
"select * from score where student_id=1500100011 and $CONDITIONS"
import
--connect
jdbc:mysql://master:3306/student
--username
root
--password
123456
--fields-terminated-by
"\t"
--lines-terminated-by
"\n"
--m
2
--split-by
student_id
--e
"select * from score where student_id=1500100011 and $CONDITIONS"
--target-dir
/testQ
--hive-import
--hive-overwrite
--create-hive-table
--hive-database
testsqoop
--hive-table
score2
MySQLToHBase
编写脚本,并保存为MySQLToHBase.conf
import
--connect
jdbc:mysql://master:3306/student?useSSL=false
--username
root
--password
123456
--table
student
--hbase-table
student
--hbase-create-table
--hbase-row-key
id
--m
1
--column-family
cf1
在HBase中创建student表
create 'student','cf1'
执行脚本
sqoop --options-file MySQLToHBase.conf
export
HDFSToMySQL
编写脚本,并保存为HDFSToMySQL.conf
export
--connect
jdbc:mysql://master:3306/student?useSSL=false
--username
root
--password
123456
--table
student
-m
1
--columns
id,name,age,gender,clazz
--export-dir
/sqoop/data/student1/
--fields-terminated-by
','
先清空MySQL student表中的数据,不然会造成主键冲突
执行脚本
sqoop --options-file HDFSToMySQL.conf
查看sqoop help
sqoop help
21/04/26 15:50:36 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command.
# 查看import的详细帮助
sqoop import --help
sqoop官网:
数据集成工具—Sqoop的更多相关文章
- 数据集成工具Kettle、Sqoop、DataX的比较
数据集成工具很多,下面是几个使用比较多的开源工具. 1.阿里开源软件:DataX DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).H ...
- 数据集成工具Teiid Designer的环境搭建
由于实验室项目要求的关系,看了些数据汇聚工具 Teiid 的相关知识.这里总结下 Teiid 的可视化配置工具 Teiid Designer 的部署过程. 背景知识 数据集成是把不同来源.格式.特点性 ...
- 数据集成工具:Teiid实践
数据集成是把不同来源.格式.特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享.数据集成的方式多种多样,这里介绍的 Teiid 是其中的一种:通过抽象和联邦技术,实现分布式数据源的 ...
- 数据同步工具Sqoop和DataX
在日常大数据生产环境中,经常会有集群数据集和关系型数据库互相转换的需求,在需求选择的初期解决问题的方法----数据同步工具就应运而生了.此次我们选择两款生产环境常用的数据同步工具进行讨论 Sqoop ...
- 数据集成工具—FlinkX
@ 目录 FlinkX的安装与简单使用 FlinkX的安装 FlinkX的简单使用 读取mysql中student表中数据 FlinkX本地运行 MySQLToHDFS MySQLToHive MyS ...
- 【ODI】| 数据ETL:从零开始使用Oracle ODI完成数据集成(一)
0. 环境说明及软件准备 ODI(Oracle Data Integrator)是Oracle公司提供的一种数据集成工具,能高效地实现批量数据的抽取.转换和加载.ODI可以实现当今大多数的主流关系型数 ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- Hadoop和大数据:60款顶级大数据开源工具
一.Hadoop相关工具 1. Hadoop Apache的Hadoop项目已几乎与大数据划上了等号.它不断壮大起来,已成为一个完整的生态系统,众多开源工具面向高度扩展的分布式计算. 支持的操作系统: ...
- 【转载】Hadoop和大数据:60款顶级大数据开源工具
一.Hadoop相关工具 1. Hadoop Apache的Hadoop项目已几乎与大数据划上了等号.它不断壮大起来,已成为一个完整的生态系统,众多开源工具面向高度扩展的分布式计算. 支持的操作系统: ...
随机推荐
- JAVA笔记__窗体类/Panel类/Toolkit类
/** * 窗体类 */ public class Main { public static void main(String[] args) { MyFrame m1 = new MyFrame() ...
- C#写TXT文档
//C#写TXT文档 String strDir = System.IO.Path.GetDirectoryName(System.Reflection.Assembly.GetExecutingAs ...
- hdu 5057 Argestes and Sequence (数状数组+离线处理)
题意: 给N个数.a[1]....a[N]. M种操作: S X Y:令a[X]=Y Q L R D P:查询a[L]...a[R]中满足第D位上数字为P的数的个数 数据范围: 1<=T< ...
- Windows内核基础知识-5-调用门(32-Bit Call Gate)
Windows内核基础知识-5-调用门(32-Bit Call Gate) 调用门有一个关键的作用,就是用来提权.调用门其实就是一个段. 调用门: 这是段描述符的结构体,里面的s字段用来标记是代码段还 ...
- SimpleNVR流媒体服务系统录像功能解析
录像的回放与观看是许多人在使用视频监控时必不可少的需求.人不可能每时每刻都观看视频,而录像能对摄像机的视频信息进行存储,方便用户的后期回放查看,因此,SimpleNVR的录像功能应运而生. ...
- C++ new 运算符 用法总结
C++ new 运算符 用法总结 使用 new 运算符 分配内存 并 初始化 1.分配内存初始化标量类型(如 int 或 double),在类型名后加初始值,并用小括号括起,C++11中也支持大括号. ...
- Merge into用法总结
简单的说就是,判断表中有没有符合on()条件中的数据,有了就更新数据,没有就插入数据. 有一个表T,有两个字段a.b,我们想在表T中做Insert/Update,如果条件满足,则更新T中b的值,否则在 ...
- 大一C语言学习笔记(5)---函数篇-定义函数需要了解注意的地方;定义函数的易错点;详细说明函数的每个组合部分的功能及注意事项
博主学习C语言是通过B站上的<郝斌C语言自学教程>,对于C语言初学者来说,我认为郝斌真的是在全网C语言学习课程中讲的最全面,到位的一个,这个不是真不是博主我吹他哈,大家可以去B站去看看,C ...
- Dapr-绑定构建块
前言: 前篇-发布订阅文章对Dapr的订阅/发布进行了解,本篇继续对 绑定 构建块进行了解. 一.简介: Dapr 资源绑定使服务能够跨即时应用程序外部的外部资源集成业务操作. 来自外部系统的事件可能 ...
- [hdu5379]Mahjong tree
一棵子树的每一个儿子相当于划分一个区间,同时这些区间一定要存在一个点连续(直接的儿子),因此每一棵树最多只有两个儿子存在子树,并且这两个儿子所分到的区间一定是该区间最左和最右两段,所以ans*=(so ...