使用 DataX 增量同步数据(转)
关于 DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
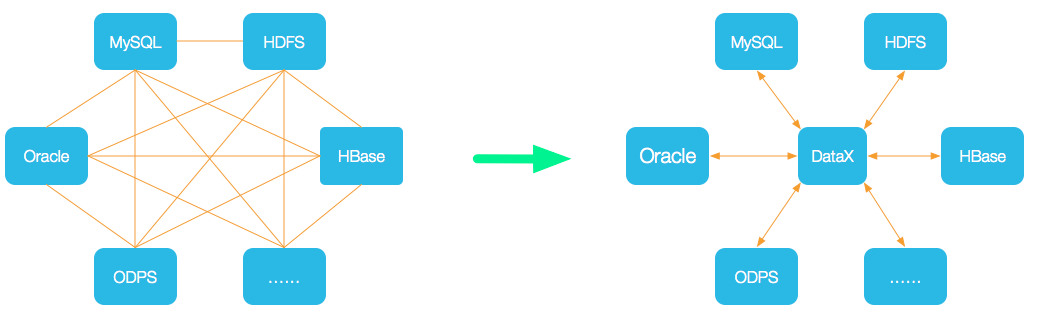
如果想进一步了解 DataX ,请进一步查看 DataX 详细介绍 。
关于增量更新
DataX 支持多种数据库的读写, json 格式配置文件很容易编写, 同步性能很好, 通常可以达到每秒钟 1 万条记录或者更高, 可以说是相当优秀的产品, 但是缺乏对增量更新的内置支持。
其实增量更新非常简单, 只要从目标数据库读取一个最大值的记录, 可能是 DateTime 或者 RowVersion 类型, 然后根据这个最大值对源数据库要同步的表进行过滤, 然后再进行同步即可。
由于 DataX 支持多种数据库的读写, 一种相对简单并且可靠的思路就是:
- 利用 DataX 的 DataReader 去目标数据库读取一个最大值;
- 将这个最大值用 TextFileWriter 写入到一个 CSV 文件;
- 用 Shell 脚本来读取 CSV 文件, 并动态修改全部同步的配置文件;
- 执行修改后的配置文件, 进行增量同步。
接下来就用 shell 脚本来一步一步实现增量更新。
增量更新的 shell 实现
我的同步环境是从 SQLServer 同步到 PostgreSQL , 部分配置如下:
{
"job": {
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"username": "...",
"password": "...",
"connection": [
{
"jdbcUrl": [
"jdbc:sqlserver://[source_server];database=[source_db]"
],
"querySql": [
"SELECT DataTime, PointID, DataValue FROM dbo.Minutedata WHERE 1=1"
]
}
]
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"username": "...",
"password": "...",
"connection": [
{
"jdbcUrl": "jdbc:postgresql://[target_server]:5432/[target_db]",
"table": [
"public.minute_data"
]
}
],
"column": [
"data_time",
"point_id",
"data_value"
],
"preSql": [
"TRUNCATE TABLE @table"
]
}
}
}
],
"setting": { }
}
}
更多的配置可以参考 SqlServerReader 插件文档以及 PostgresqlWriter 插件文档。
要实现增量更新, 首先要 PostgresqlReader 从目标数据库读取最大日期, 并用 TextFileWriter 写入到一个 csv 文件, 这一步我的配置如下所示:
{
"job": {
"content": [
{
"reader": {
"name": "postgresqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:postgresql://[target_server]:5432/[target_db]"
],
"querySql": [
"SELECT max(data_time) FROM public.minute_data"
]
}
],
"password": "...",
"username": "..."
}
},
"writer": {
"name": "txtfilewriter",
"parameter": {
"dateFormat": "yyyy-MM-dd HH:mm:ss",
"fileName": "minute_data_max_time_result",
"fileFormat": "csv",
"path": "/scripts/",
"writeMode": "truncate"
}
}
}
],
"setting": { }
}
}
更多的配置可以看考 PostgresqlDataReader 插件文档以及 TextFileWriter 插件文档
有了这两个配置文件, 现在可以编写增量同步的 shell 文件, 内容如下:
#!/bin/bash
### every exit != 0 fails the script
set -e # 获取目标数据库最大数据时间,并写入一个 csv 文件
docker run --interactive --tty --rm --network compose --volume $(pwd):/scripts \
beginor/datax:3.0 \
/scripts/minute_data_max_time.json
if [ $? -ne 0 ]; then
echo "minute_data_sync.sh error, can not get max_time from target db!"
exit 1
fi
# 找到 DataX 写入的文本文件,并将内容读取到一个变量中
RESULT_FILE=`ls minute_data_max_time_result_*`
MAX_TIME=`cat $RESULT_FILE`
# 如果最大时间不为 null 的话, 修改全部同步的配置,进行增量更新;
if [ "$MAX_TIME" != "null" ]; then
# 设置增量更新过滤条件
WHERE="DataTime > '$MAX_TIME'"
sed "s/1=1/$WHERE/g" minute_data.json > minute_data_tmp.json
# 将第 45 行的 truncate 语句删除;
sed '45d' minute_data_tmp.json > minute_data_inc.json
# 增量更新
docker run --interactive --tty --rm --network compose --volume $(pwd):/scripts \
beginor/datax:3.0 \
/scripts/minute_data_inc.json
# 删除临时文件
rm ./minute_data_tmp.json ./minute_data_inc.json
else
# 全部更新
docker run --interactive --tty --rm --network compose --volume $(pwd):/scripts \
beginor/datax:3.0 \
/scripts/minute_data.json
fi
在上面的 shell 文件中, 使用我制作的 DataX docker 镜像, 使用命令 docker pull beginor/datax:3.0 即可获取该镜像, 当也可以修改这个 shell 脚本直接使用 datax 命令来执行。
为什么用 shell 来实现
因为 DataX 支持多种数据库的读写, 充分利用 DataX 读取各种数据库的能力, 减少了很多开发工作, 毕竟 DataX 的可靠性是很好的。
文章来源:https://beginor.github.io/2018/06/29/incremental-sync-with-datax.html
使用 DataX 增量同步数据(转)的更多相关文章
- 实现从Oracle增量同步数据到GreenPlum
简介: GreenPlum是一个基于PostgreSQL数据库开发的MPP架构的数据库仓库,适用于OLAP系统,支持50PB(1PB=1000TB)级海量数据的存储和处理. 背景: 目前有一个业务是需 ...
- Clickhouse单机部署以及从mysql增量同步数据
背景: 随着数据量的上升,OLAP一直是被讨论的话题,虽然druid,kylin能够解决OLAP问题,但是druid,kylin也是需要和hadoop全家桶一起用的,异常的笨重,再说我也搞不定,那只能 ...
- datax实例——全量、增量同步
一.全量同步 本文以mysql -> mysql为示例: 本次测试的表为mysql的系统库-sakila中的actor表,由于不支持目的端自动建表,此处预先建立目的表: CREATE TABLE ...
- Rsync + Sersync 实现数据增量同步
部分引用自:https://blog.csdn.net/tmchongye/article/details/68956808 一.什么是Rsync? Rsync(Remote Synchronize) ...
- MySQL数据实时增量同步到Kafka - Flume
转载自:https://www.cnblogs.com/yucy/p/7845105.html MySQL数据实时增量同步到Kafka - Flume 写在前面的话 需求,将MySQL里的数据实时 ...
- orcale增量全量实时同步mysql可支持多库使用Kettle实现数据实时增量同步
1. 时间戳增量回滚同步 假定在源数据表中有一个字段会记录数据的新增或修改时间,可以通过它对数据在时间维度上进行排序.通过中间表记录每次更新的时间戳,在下一个同步周期时,通过这个时间戳同步该时间戳以后 ...
- 数据源管理 | 基于DataX组件,同步数据和源码分析
本文源码:GitHub·点这里 || GitEE·点这里 一.DataX工具简介 1.设计理念 DataX是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDF ...
- Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一.使用Logstash将mysql数据导入elasticsearch 1.在mysql中准备数据: mysql> show tables; +----------------+ | Table ...
- 实战!Spring Boot 整合 阿里开源中间件 Canal 实现数据增量同步!
大家好,我是不才陈某~ 数据同步一直是一个令人头疼的问题.在业务量小,场景不多,数据量不大的情况下我们可能会选择在项目中直接写一些定时任务手动处理数据,例如从多个表将数据查出来,再汇总处理,再插入到相 ...
随机推荐
- 如何安装selenium以及scrapy,最重要的是pip?
一般的步骤: # Selenium安装配置 # 1. 安装python的selenium包:pip install selenium# 2. Selenium驱动(Chrome)下载: ...
- Redis(二) 数据类型操作指令以及对应的RedisTemplate方法
1.Redis key值操作以及RedisTemplate对应的API 本文默认使用RedisTemplate,关于RedisTemplate和StringRedisTemplate的区别如下 Red ...
- 目标检测中的anchor-based 和anchor free
目标检测中的anchor-based 和anchor free 1. anchor-free 和 anchor-based 区别 深度学习目标检测通常都被建模成对一些候选区域进行分类和回归的问题.在 ...
- 稀疏自编码器及TensorFlow实现
自动编码机更像是一个识别网络,只是简单重构了输入.而重点应是在像素级重构图像,施加的唯一约束是隐藏层单元的数量. 有趣的是,像素级重构并不能保证网络将从数据集中学习抽象特征,但是可以通过添加更多的约束 ...
- Docker系列——Grafana+Prometheus+Node-exporter微信推送(三)
在之前博文中,已经成功的实现了邮件推送.目前主流的办公终端,就是企业微信.钉钉.飞书.今天来分享下微信推送,我们具体来看. 企业微信 在配置企业微信推送时,需要有微信企业,具体如何注册.使用,另外百度 ...
- 将DataTable转成Json字符串
1 public string ToJson(DataTable tbl) 2 { 3 if (tbl.Rows.Count > 0) 4 { 5 DataRowCollection rows ...
- 深入Netty逻辑架构,从Reactor线程模型开始
本文是Netty系列第6篇 上一篇文章我们从一个Netty的使用Demo,了解了用Netty构建一个Server服务端应用的基本方式.并且从这个Demo出发,简述了Netty的逻辑架构,并对Chann ...
- Python跨域问题解决集合
Flask 安装插件 pip install flask-cors 使用 CORS函数配置全局路由 from flask_cors import * app = Flask(__name__) COR ...
- 一张图理清计算机常见编码的关系。ASCII、Unicode都不是事儿
编码按适用范围可以简单分为:(本人自定义) 美国编码(ASCII)ASCII为基础编码,来源于美国:其它编码都兼容ASCII编码: 欧盟编码(ISO8859-1.WINDOWS-1252)先是ISO- ...
- Python3中列表、字典、元组、集合的看法
文首,我先强调一下我是一个弱鸡码农,这个随笔是在我学习完Python3中的元组.字典.列表,集合这四种常见数据的数据类型的一些感想,如果有什么不对的地方欢迎大家予以指正.谢谢大家啦 回归正题:这篇随笔 ...