DL4J实战之三:经典卷积实例(LeNet-5)
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
- 作为《DL4J》实战的第三篇,目标是在DL4J框架下创建经典的LeNet-5卷积神经网络模型,对MNIST数据集进行训练和测试,本篇由以下内容构成:
- LeNet-5简介
- MNIST简介
- 数据集简介
- 关于版本和环境
- 编码
- 验证
LeNet-5简介
- 是Yann LeCun于1998年设计的卷积神经网络,用于手写数字识别,例如当年美国很多银行用其识别支票上的手写数字,LeNet-5是早期卷积神经网络最有代表性的实验系统之一
- LeNet-5网络结构如下图所示,一共七层:C1 -> S2 -> C3 -> S4 -> C5 -> F6 -> OUTPUT
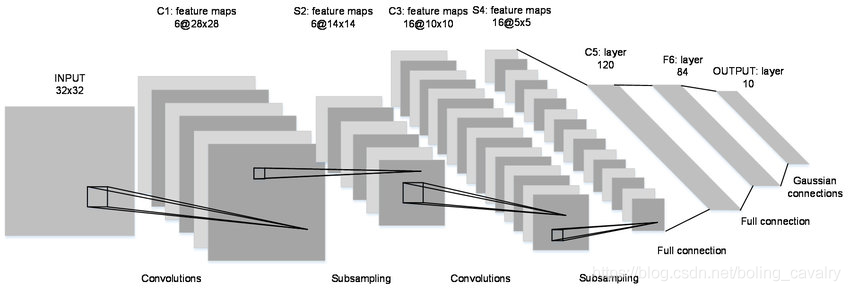
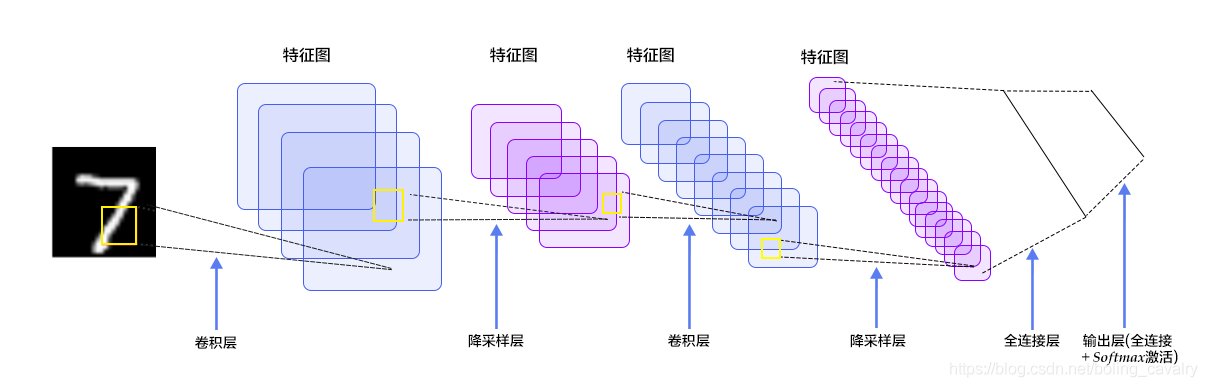
- 按照上图简单分析一下,用于指导接下来的开发:
- 每张图片都是28*28的单通道,矩阵应该是[1, 28,28]
- C1是卷积层,所用卷积核尺寸5*5,滑动步长1,卷积核数目20,所以尺寸变化是:28-5+1=24(想象为宽度为5的窗口在宽度为28的窗口内滑动,能滑多少次),输出矩阵是[20,24,24]
- S2是池化层,核尺寸2*2,步长2,类型是MAX,池化操作后尺寸减半,变成了[20,12,12]
- C3是卷积层,所用卷积核尺寸5*5,滑动步长1,卷积核数目50,所以尺寸变化是:12-5+1=8,输出矩阵[50,8,8]
- S4是池化层,核尺寸2*2,步长2,类型是MAX,池化操作后尺寸减半,变成了[50,4,4]
- C5是全连接层(FC),神经元数目500,接relu激活函数
- 最后是全连接层Output,共10个节点,代表数字0到9,激活函数是softmax
MNIST简介
- MNIST是经典的计算机视觉数据集,来源是National Institute of Standards and Technology (NIST,美国国家标准与技术研究所),包含各种手写数字图片,其中训练集60,000张,测试集 10,000张,
- MNIST来源于250 个不同人的手写,其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员.,测试集(test set) 也是同样比例的手写数字数据
- MNIST官网:http://yann.lecun.com/exdb/mnist/
数据集简介
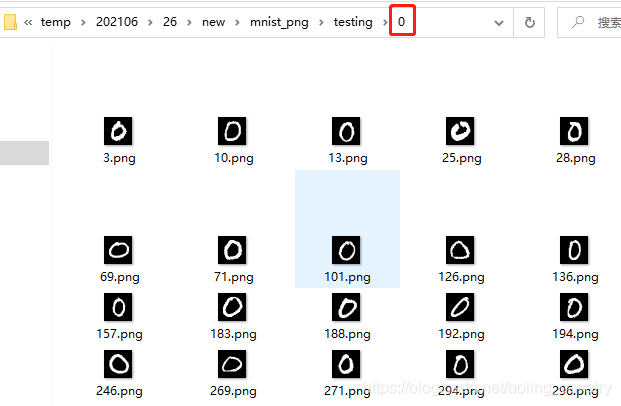
- 从MNIST官网下载的原始数据并非图片文件,需要按官方给出的格式说明做解析处理才能转为一张张图片,这些事情显然不是本篇的主题,因此咱们可以直接使用DL4J为我们准备好的数据集(下载地址稍后给出),该数据集中是一张张独立的图片,这些图片所在目录的名字就是该图片具体的数字,如下图,目录0里面全是数字0的图片:
- 上述数据集的下载地址有两个:
- 可以在CSDN下载(0积分):https://download.csdn.net/download/boling_cavalry/19846603
- github:https://raw.githubusercontent.com/zq2599/blog_download_files/master/files/mnist_png.tar.gz
- 下载之后解压开,是个名为mnist_png的文件夹,稍后的实战中咱们会用到它
关于DL4J版本
- 《DL4J实战》系列的源码采用了maven的父子工程结构,DL4J的版本在父工程dlfj-tutorials中定义为1.0.0-beta7
- 本篇的代码虽然还是dlfj-tutorials的子工程,但是DL4J版本却使用了更低的1.0.0-beta6,之所以这么做,是因为下一篇文章,咱们会把本篇的训练和测试工作交给GPU来完成,而对应的CUDA库只有1.0.0-beta6
- 扯了这么多,可以开始编码了
源码下载
- 本篇实战中的完整源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
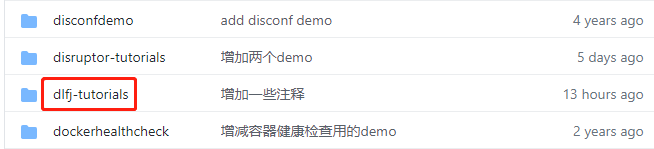
- 这个git项目中有多个文件夹,《DL4J实战》系列的源码在dl4j-tutorials文件夹下,如下图红框所示:
- dl4j-tutorials文件夹下有多个子工程,本次实战代码在simple-convolution目录下,如下图红框:
编码
- 在父工程 dl4j-tutorials下新建名为 simple-convolution的子工程,其pom.xml如下,可见这里的dl4j版本被指定为1.0.0-beta6:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>dlfj-tutorials</artifactId>
<groupId>com.bolingcavalry</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>simple-convolution</artifactId>
<properties>
<dl4j-master.version>1.0.0-beta6</dl4j-master.version>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>${dl4j-master.version}</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>${nd4j.backend}</artifactId>
<version>${dl4j-master.version}</version>
</dependency>
</dependencies>
</project>
- 接下来按照前面的分析实现代码,已经添加了详细注释,就不再赘述了:
package com.bolingcavalry.convolution;
import lombok.extern.slf4j.Slf4j;
import org.datavec.api.io.labels.ParentPathLabelGenerator;
import org.datavec.api.split.FileSplit;
import org.datavec.image.loader.NativeImageLoader;
import org.datavec.image.recordreader.ImageRecordReader;
import org.deeplearning4j.datasets.datavec.RecordReaderDataSetIterator;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.inputs.InputType;
import org.deeplearning4j.nn.conf.layers.ConvolutionLayer;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.conf.layers.SubsamplingLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.deeplearning4j.util.ModelSerializer;
import org.nd4j.evaluation.classification.Evaluation;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.DataNormalization;
import org.nd4j.linalg.dataset.api.preprocessor.ImagePreProcessingScaler;
import org.nd4j.linalg.learning.config.Nesterovs;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import org.nd4j.linalg.schedule.MapSchedule;
import org.nd4j.linalg.schedule.ScheduleType;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
@Slf4j
public class LeNetMNISTReLu {
// 存放文件的地址,请酌情修改
// private static final String BASE_PATH = System.getProperty("java.io.tmpdir") + "/mnist";
private static final String BASE_PATH = "E:\\temp\\202106\\26";
public static void main(String[] args) throws Exception {
// 图片像素高
int height = 28;
// 图片像素宽
int width = 28;
// 因为是黑白图像,所以颜色通道只有一个
int channels = 1;
// 分类结果,0-9,共十种数字
int outputNum = 10;
// 批大小
int batchSize = 54;
// 循环次数
int nEpochs = 1;
// 初始化伪随机数的种子
int seed = 1234;
// 随机数工具
Random randNumGen = new Random(seed);
log.info("检查数据集文件夹是否存在:{}", BASE_PATH + "/mnist_png");
if (!new File(BASE_PATH + "/mnist_png").exists()) {
log.info("数据集文件不存在,请下载压缩包并解压到:{}", BASE_PATH);
return;
}
// 标签生成器,将指定文件的父目录作为标签
ParentPathLabelGenerator labelMaker = new ParentPathLabelGenerator();
// 归一化配置(像素值从0-255变为0-1)
DataNormalization imageScaler = new ImagePreProcessingScaler();
// 不论训练集还是测试集,初始化操作都是相同套路:
// 1. 读取图片,数据格式为NCHW
// 2. 根据批大小创建的迭代器
// 3. 将归一化器作为预处理器
log.info("训练集的矢量化操作...");
// 初始化训练集
File trainData = new File(BASE_PATH + "/mnist_png/training");
FileSplit trainSplit = new FileSplit(trainData, NativeImageLoader.ALLOWED_FORMATS, randNumGen);
ImageRecordReader trainRR = new ImageRecordReader(height, width, channels, labelMaker);
trainRR.initialize(trainSplit);
DataSetIterator trainIter = new RecordReaderDataSetIterator(trainRR, batchSize, 1, outputNum);
// 拟合数据(实现类中实际上什么也没做)
imageScaler.fit(trainIter);
trainIter.setPreProcessor(imageScaler);
log.info("测试集的矢量化操作...");
// 初始化测试集,与前面的训练集操作类似
File testData = new File(BASE_PATH + "/mnist_png/testing");
FileSplit testSplit = new FileSplit(testData, NativeImageLoader.ALLOWED_FORMATS, randNumGen);
ImageRecordReader testRR = new ImageRecordReader(height, width, channels, labelMaker);
testRR.initialize(testSplit);
DataSetIterator testIter = new RecordReaderDataSetIterator(testRR, batchSize, 1, outputNum);
testIter.setPreProcessor(imageScaler); // same normalization for better results
log.info("配置神经网络");
// 在训练中,将学习率配置为随着迭代阶梯性下降
Map<Integer, Double> learningRateSchedule = new HashMap<>();
learningRateSchedule.put(0, 0.06);
learningRateSchedule.put(200, 0.05);
learningRateSchedule.put(600, 0.028);
learningRateSchedule.put(800, 0.0060);
learningRateSchedule.put(1000, 0.001);
// 超参数
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(seed)
// L2正则化系数
.l2(0.0005)
// 梯度下降的学习率设置
.updater(new Nesterovs(new MapSchedule(ScheduleType.ITERATION, learningRateSchedule)))
// 权重初始化
.weightInit(WeightInit.XAVIER)
// 准备分层
.list()
// 卷积层
.layer(new ConvolutionLayer.Builder(5, 5)
.nIn(channels)
.stride(1, 1)
.nOut(20)
.activation(Activation.IDENTITY)
.build())
// 下采样,即池化
.layer(new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build())
// 卷积层
.layer(new ConvolutionLayer.Builder(5, 5)
.stride(1, 1) // nIn need not specified in later layers
.nOut(50)
.activation(Activation.IDENTITY)
.build())
// 下采样,即池化
.layer(new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build())
// 稠密层,即全连接
.layer(new DenseLayer.Builder().activation(Activation.RELU)
.nOut(500)
.build())
// 输出
.layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(outputNum)
.activation(Activation.SOFTMAX)
.build())
.setInputType(InputType.convolutionalFlat(height, width, channels)) // InputType.convolutional for normal image
.build();
MultiLayerNetwork net = new MultiLayerNetwork(conf);
net.init();
// 每十个迭代打印一次损失函数值
net.setListeners(new ScoreIterationListener(10));
log.info("神经网络共[{}]个参数", net.numParams());
long startTime = System.currentTimeMillis();
// 循环操作
for (int i = 0; i < nEpochs; i++) {
log.info("第[{}]个循环", i);
net.fit(trainIter);
Evaluation eval = net.evaluate(testIter);
log.info(eval.stats());
trainIter.reset();
testIter.reset();
}
log.info("完成训练和测试,耗时[{}]毫秒", System.currentTimeMillis()-startTime);
// 保存模型
File ministModelPath = new File(BASE_PATH + "/minist-model.zip");
ModelSerializer.writeModel(net, ministModelPath, true);
log.info("最新的MINIST模型保存在[{}]", ministModelPath.getPath());
}
}
- 执行上述代码,日志输出如下,训练和测试都顺利完成,准确率达到0.9886:
21:19:15.355 [main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 1110 is 0.18300625613640034
21:19:15.365 [main] DEBUG org.nd4j.linalg.dataset.AsyncDataSetIterator - Manually destroying ADSI workspace
21:19:16.632 [main] DEBUG org.nd4j.linalg.dataset.AsyncDataSetIterator - Manually destroying ADSI workspace
21:19:16.642 [main] INFO com.bolingcavalry.convolution.LeNetMNISTReLu -
========================Evaluation Metrics========================
# of classes: 10
Accuracy: 0.9886
Precision: 0.9885
Recall: 0.9886
F1 Score: 0.9885
Precision, recall & F1: macro-averaged (equally weighted avg. of 10 classes)
=========================Confusion Matrix=========================
0 1 2 3 4 5 6 7 8 9
---------------------------------------------------
972 0 0 0 0 0 2 2 2 2 | 0 = 0
0 1126 0 3 0 2 1 1 2 0 | 1 = 1
1 1 1019 2 0 0 0 6 3 0 | 2 = 2
0 0 1 1002 0 5 0 1 1 0 | 3 = 3
0 0 2 0 971 0 3 2 1 3 | 4 = 4
0 0 0 3 0 886 2 1 0 0 | 5 = 5
6 2 0 1 1 5 942 0 1 0 | 6 = 6
0 1 6 0 0 0 0 1015 1 5 | 7 = 7
1 0 1 1 0 2 0 2 962 5 | 8 = 8
1 2 1 3 5 3 0 2 1 991 | 9 = 9
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
==================================================================
21:19:16.643 [main] INFO com.bolingcavalry.convolution.LeNetMNISTReLu - 完成训练和测试,耗时[27467]毫秒
21:19:17.019 [main] INFO com.bolingcavalry.convolution.LeNetMNISTReLu - 最新的MINIST模型保存在[E:\temp\202106\26\minist-model.zip]
Process finished with exit code 0
关于准确率
前面的测试结果显示准确率为0.9886,这是1.0.0-beta6版本DL4J的训练结果,如果换成1.0.0-beta7,准确率可以达到0.99以上,您可以尝试一下;
至此,DL4J框架下的经典卷积实战就完成了,截止目前,咱们的训练和测试工作都是CPU完成的,工作中CPU使用率的上升十分明显,下一篇文章,咱们把今天的工作交给GPU执行试试,看能否借助CUDA加速训练和测试工作;
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
DL4J实战之三:经典卷积实例(LeNet-5)的更多相关文章
- DL4J实战之四:经典卷积实例(GPU版本)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 经典卷积网络模型 — LeNet模型笔记
LeNet-5包含于输入层在内的8层深度卷积神经网络.其中卷积层可以使得原信号特征增强,并且降低噪音.而池化层利用图像相关性原理,对图像进行子采样,可以减少参数个数,减少模型的过拟合程度,同时也可以保 ...
- DL4J实战之六:图形化展示训练过程
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本篇是<DL4J实战>系列的第六 ...
- TensorFlow实战之实现AlexNet经典卷积神经网络
本文根据最近学习TensorFlow书籍网络文章的情况,特将一些学习心得做了总结,详情如下.如有不当之处,请各位大拿多多指点,在此谢过. 一.AlexNet模型及其基本原理阐述 1.关于AlexNet ...
- 经典卷积神经网络(LeNet、AlexNet、VGG、GoogleNet、ResNet)的实现(MXNet版本)
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现. 其中 文章 详解卷 ...
- 五大经典卷积神经网络介绍:LeNet / AlexNet / GoogLeNet / VGGNet/ ResNet
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! LeNet / AlexNet / GoogLeNet / VGG ...
- DL4J实战之二:鸢尾花分类
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 经典卷积神经网络结构——LeNet-5、AlexNet、VGG-16
经典卷积神经网络的结构一般满足如下表达式: 输出层 -> (卷积层+ -> 池化层?)+ -> 全连接层+ 上述公式中,“+”表示一个或者多个,“?”表示一个或者零个,如“卷积层+ ...
- Flink的sink实战之三:cassandra3
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- Android开发,缺少权限导致无法修改原文件,获取所有文件访问权限的方法
在Android 11开发中,app会遇到使用绝对路径无法打开某文件的情况(文件存在根目录下,获取到的路径为:/storage/emulated/0/XXX.txt),而使用相对路径打开文件后(获取到 ...
- MySQL双主+Keepalived高可用
原文转自:https://www.cnblogs.com/itzgr/p/10233932.html作者:木二 目录 一 基础环境 二 实际部署 2.1 安装MySQL 2.2 初始化MySQL 2. ...
- MySQL-存储引擎-MERGE
MERGE存储引擎是一组Myisam表的组合,这些Myisam表必须结构完全相同,MERGE表本身并没有数据,对MERGE类型的表可以进行查询.更新.删除操作,这些操作实际上是对内部的Myisam表进 ...
- Linux centos7 nginx 的安装
2021-08-18 1. 环境 # 操作系统[root@test007 /]# uname -aLinux test007 3.10.0-862.el7.x86_64 #1 SMP Fri Apr ...
- 菜鸟入门Linux之路(方法论浅谈)
Linux是为人熟知的OS之王,已"统治"世界.要想学好绝非易事. 作为菜鸟,可以与Linux亲密接触的方法很多,如视频.书籍.各种企培资料等等,如今的在线教育也如火如荼. 总结说 ...
- input 只可以输入时分秒
在html5的time中,只有时.分,没有秒. 例如<input type="time" name="user_date" /> 属性加上 step ...
- Expression 表达式动态生成
http://blog.csdn.net/duan1311/article/details/51769119 以上是拼装和调用GroupBy的方法,是不是很简单,只要传入分组列与合计列就OK了! 下面 ...
- 使用 mysql 的 Docker 镜像
使用 mysql 的 Docker 镜像 前言 之前搞了很多都是手工在操作系统的镜像中安装使用 mysql,作为自己折腾也就算了,作为实际使用实为不妥:Docker最重要的特性就是可扩展性,把各种程序 ...
- 动态规划精讲(一)LC最长公共子序列
P1439 [模板]最长公共子序列 题目描述 给出1,2,-,n 的两个排列P1 和P2 ,求它们的最长公共子序列. 输入格式 第一行是一个数 n. 接下来两行,每行为 n 个数,为自然数 1,2 ...
- webpack线上和线下模式
区别: 1 线下模式代码没有压缩,source-map是全的,比较容易定位错误,调试方便 2 线上模式的代码是压缩的,文件小, 分开打包: 方式一:有点麻烦 在package.json文件 " ...