ClickHouse 存算分离架构探索
背景
ClickHouse 作为开源 OLAP 引擎,因其出色的性能表现在大数据生态中得到了广泛的应用。区别于 Hadoop 生态组件通常依赖 HDFS 作为底层的数据存储,ClickHouse 使用本地盘来自己管理数据,官方推荐使用 SSD 作为存储介质来提升性能。但受限于本地盘的容量上限以及 SSD 盘的价格,用户很难在容量、成本和性能这三者之间找到一个好的平衡。JuiceFS 的某个客户近期就遇到了这样的难题,希望将 ClickHouse 中的温冷数据从 SSD 盘迁移到更大容量、更低成本的存储介质,更好地支撑业务查询更长时间数据的需求。
JuiceFS 是基于对象存储实现并完全兼容 POSIX 的开源分布式文件系统,同时 JuiceFS 的数据缓存特性可以智能管理查询热点数据,非常适合作为 ClickHouse 的存储系统,下面将详细介绍这个方案。
MergeTree 存储格式简介
在介绍具体方案之前先简单了解一下 MergeTree 的存储格式。MergeTree 是 ClickHouse 最主要使用的存储引擎,当创建表时可以通过 PARTITION BY 语句指定以某一个或多个字段作为分区字段,数据在磁盘上的目录结构类似如下形式:
$ ls -l /var/lib/clickhouse/data/<database>/<table>
drwxr-xr-x 2 test test 64B Mar 8 13:46 202102_1_3_0
drwxr-xr-x 2 test test 64B Mar 8 13:46 202102_4_6_1
drwxr-xr-x 2 test test 64B Mar 8 13:46 202103_1_1_0
drwxr-xr-x 2 test test 64B Mar 8 13:46 202103_4_4_0
以 202102_1_3_0 为例,202102 是分区的名称,1 是最小的数据块编号,3 是最大的数据块编号,0 是 MergeTree 的深度。可以看到 202102 这个分区不止一个目录,这是因为 ClickHouse 每次在写入的时候都会生成一个新的目录,并且一旦写入以后就不会修改(immutable)。每一个目录称作一个「part」,当 part 逐渐变多以后 ClickHouse 会在后台对多个 part 进行合并(compaction),通常的建议是不要保留过多 part,否则会影响查询性能。
每个 part 目录内部又由很多大大小小的文件组成,这里面既有数据,也有一些元信息,一个典型的目录结构如下所示:
$ ls -l /var/lib/clickhouse/data/<database>/<table>/202102_1_3_0
-rw-r--r-- 1 test test ?? Mar 8 14:06 ColumnA.bin
-rw-r--r-- 1 test test ?? Mar 8 14:06 ColumnA.mrk
-rw-r--r-- 1 test test ?? Mar 8 14:06 ColumnB.bin
-rw-r--r-- 1 test test ?? Mar 8 14:06 ColumnB.mrk
-rw-r--r-- 1 test test ?? Mar 8 14:06 checksums.txt
-rw-r--r-- 1 test test ?? Mar 8 14:06 columns.txt
-rw-r--r-- 1 test test ?? Mar 8 14:06 count.txt
-rw-r--r-- 1 test test ?? Mar 8 14:06 minmax_ColumnC.idx
-rw-r--r-- 1 test test ?? Mar 8 14:06 partition.dat
-rw-r--r-- 1 test test ?? Mar 8 14:06 primary.idx
其中比较重要的文件有:
primary.idx:这个文件包含的是主键信息,但不是当前 part 全部行的主键,默认会按照 8192 这个区间来存储,也就是每 8192 行存储一次主键。
ColumnA.bin:这是压缩以后的某一列的数据,ColumnA 只是这一列的代称,实际情况会是真实的列名。压缩是以 block 作为最小单位,每个 block 的大小从 64KiB 到 1MiB 不等。
ColumnA.mrk:这个文件保存的是对应的 ColumnA.bin 文件中每个 block 压缩后和压缩前的偏移。
partition.dat:这个文件包含的是经过分区表达式计算以后的分区 ID。
minmax_ColumnC.idx:这个文件包含的是分区字段对应的原始数据的最小值和最大值。
基于 JuiceFS 的存算分离方案
因为 JuiceFS 完全兼容 POSIX,所以可以把 JuiceFS 挂载的文件系统直接作为 ClickHouse 的磁盘来使用。这种方案下数据会直接写入 JuiceFS,结合为 ClickHouse 节点配置的缓存盘,查询时涉及的热数据会自动缓存在 ClickHouse 节点本地。整体方案如下图所示。
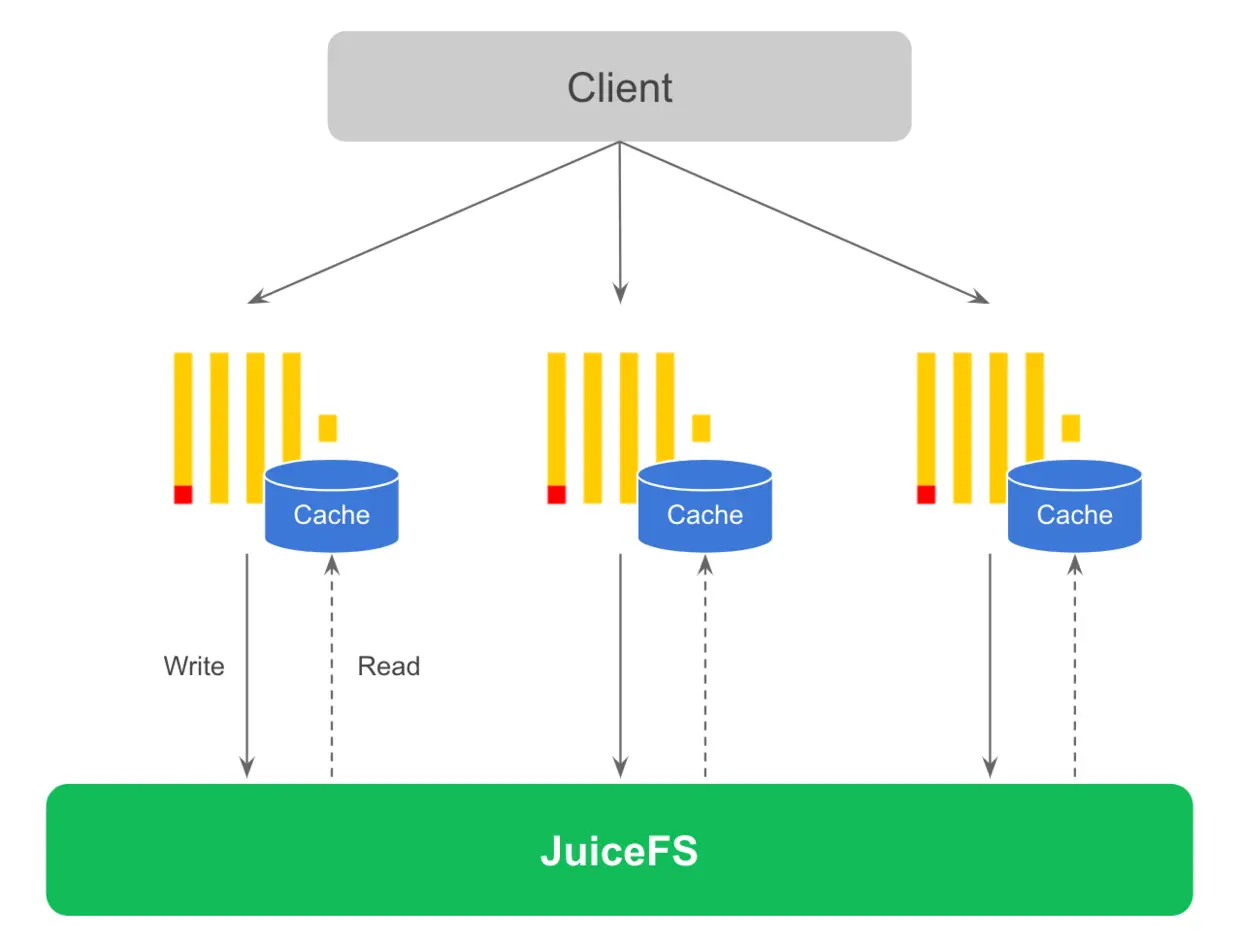
ClickHouse 在写入时会产生大量的小文件,因此如果写入压力较大这个方案对写入和查询性能都会有一定影响。建议在写入数据时增大写入缓存,尽量一次写入更多数据来避免这个小文件过多的问题。最简单的做法是使用 ClickHouse 的 Buffer 表,基本上不需要修改应用代码就可以解决小文件过多的问题,适合当 ClickHouse 宕机时允许少量数据丢失的场景。这样做的好处是存储和计算完全分离,ClickHouse 节点完全无状态,如果节点故障可以很快恢复,不涉及任何数据拷贝。未来可以让 ClickHouse 感知到底层存储是共享的,实现自动的无数据拷贝迁移。
同时由于 ClickHouse 通常应用在实时分析场景,这个场景对于数据实时更新的要求比较高,在分析时也需要经常性地查询新数据。因此数据具有比较明显的冷热特征,即一般新数据是热数据,随着时间推移历史数据逐渐变为冷数据。利用 ClickHouse 的存储策略(storage policy)来配置多块磁盘,通过一定条件可以实现自动迁移冷数据到 JuiceFS。整体方案如下图所示。
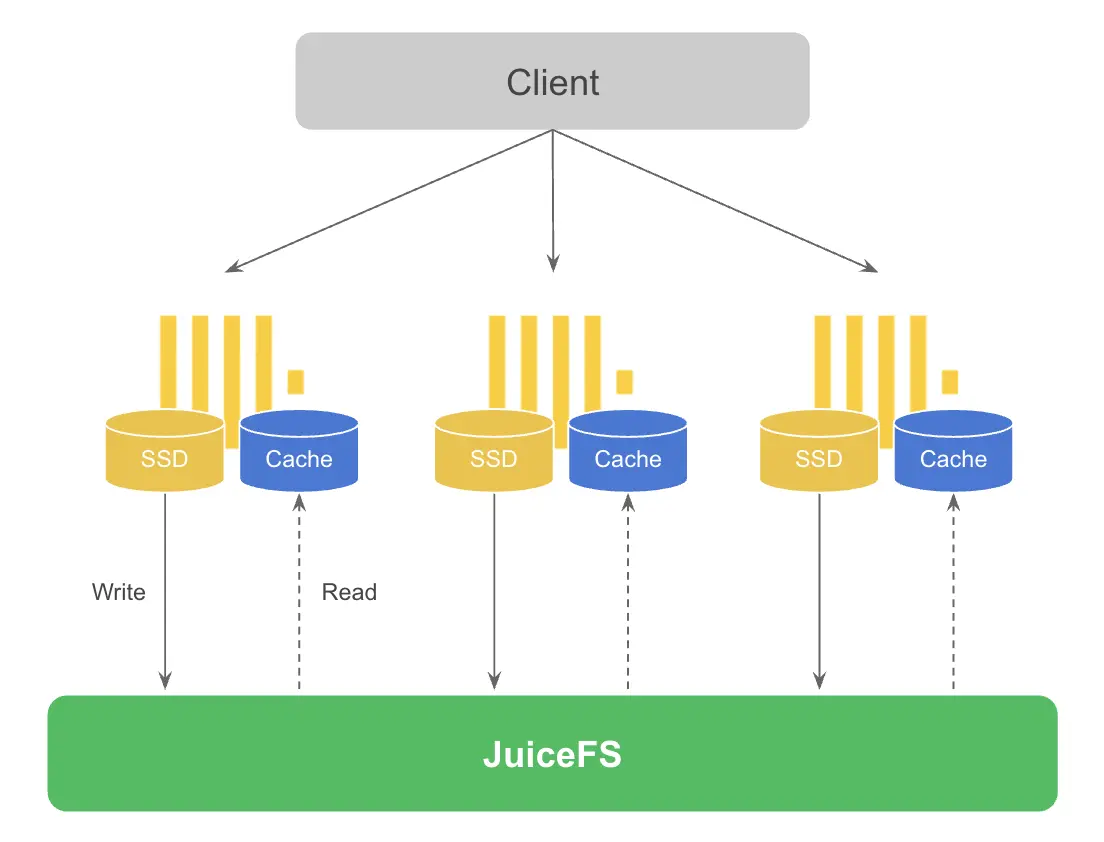
这个方案中数据会先写入本地磁盘,当满足一定条件时 ClickHouse 的后台线程会异步把数据从本地磁盘迁移到 JuiceFS 上。和第一个方案一样,查询时也会自动缓存热数据。注意图中为了区分写和读因此画了两块磁盘,实际使用中没有这个限制,可以使用同一个盘。虽然这个方案不是完全的存储计算分离,但是可以满足对写入性能要求特别高的场景需求,也保留一定的存储资源弹性伸缩能力。下面会详细介绍这个方案在 ClickHouse 中如何配置。
ClickHouse 支持配置多块磁盘用于数据存储,下面是示例的配置文件:
<storage_configuration>
<disks>
<jfs>
<path>/jfs</path>
</jfs>
</disks>
</storage_configuration>
上面的 /jfs 目录即是 JuiceFS 文件系统挂载的路径。在把以上配置添加到 ClickHouse 的配置文件中,并成功挂载 JuiceFS 文件系统以后,就可以通过 MOVE PARTITION 命令将某个 partition 移动到 JuiceFS 上,例如:
ALTER TABLE test MOVE PARTITION 'xxx' TO DISK 'jfs';
当然这种手动移动的方式只是用于测试,ClickHouse 支持通过配置存储策略的方式来将数据自动从某个磁盘移动到另一个磁盘。下面是示例的配置文件:
<storage_configuration>
<disks>
<jfs>
<path>/jfs</path>
</jfs>
</disks>
<policies>
<hot_and_cold>
<volumes>
<hot>
<disk>default</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</hot>
<cold>
<disk>jfs</disk>
</cold>
</volumes>
<move_factor>0.1</move_factor>
</hot_and_cold>
</policies>
</storage_configuration>
上面的配置文件中有一个名为 hot_and_cold 的存储策略,其中定义了两个 volume,名为 hot 的 volume 是默认的 SSD 盘,名为 cold 的 volume 即是上一步 disks 中定义的 JuiceFS 盘。这些 volume 在配置文件中的顺序很重要,数据会首先存储到第一个 volume 中,而 max_data_part_size_bytes 这个配置表示当数据 part 超过指定的大小时(示例中是 1GiB)自动从当前 volume 移动到下一个 volume,也就是把数据从 SSD 盘移动到 JuiceFS。最后的 move_factor 配置表示当 SSD 盘的磁盘容量超过 90% 时也会触发数据移动到 JuiceFS。
最后在创建表时需要显式指定要用到的存储策略:
CREATE TABLE test (
...
) ENGINE = MergeTree
...
SETTINGS storage_policy = 'hot_and_cold';
当满足数据移动的条件时,ClickHouse 就会启动后台线程去执行移动数据的操作,默认会有 8 个线程同时工作,这个线程数量可以通过 background_move_pool_size配置调整。
除了配置存储策略以外,还可以在创建表时通过 TTL 将超过一段时间的数据移动到 JuiceFS 上,例如:
CREATE TABLE test (
d DateTime,
...
) ENGINE = MergeTree
...
TTL d + INTERVAL 1 DAY TO DISK 'jfs'
SETTINGS storage_policy = 'hot_and_cold';
上面的例子是将超过 1 天的数据移动到 JuiceFS 上,结合存储策略一起可以非常灵活地管理数据的生命周期。
写入性能测试
采用冷热数据分离方案以后数据并不会直接写入 JuiceFS,而是先写入 SSD 盘,再通过后台线程异步迁移到 JuiceFS 上。但是我们希望直接评估不同存储介质在写数据的场景有多大的性能差异,因此这里在测试写入性能时没有配置冷热数据分离的存储策略,而是让 ClickHouse 直接写入不同的存储介质。
具体测试方法是将真实业务中的某一张 ClickHouse 表作为数据源,然后使用 INSERT INTO 语句批量插入千万级行数的数据,比较直接写入 SSD 盘、JuiceFS 以及对象存储的吞吐。最终的测试结果如下图:
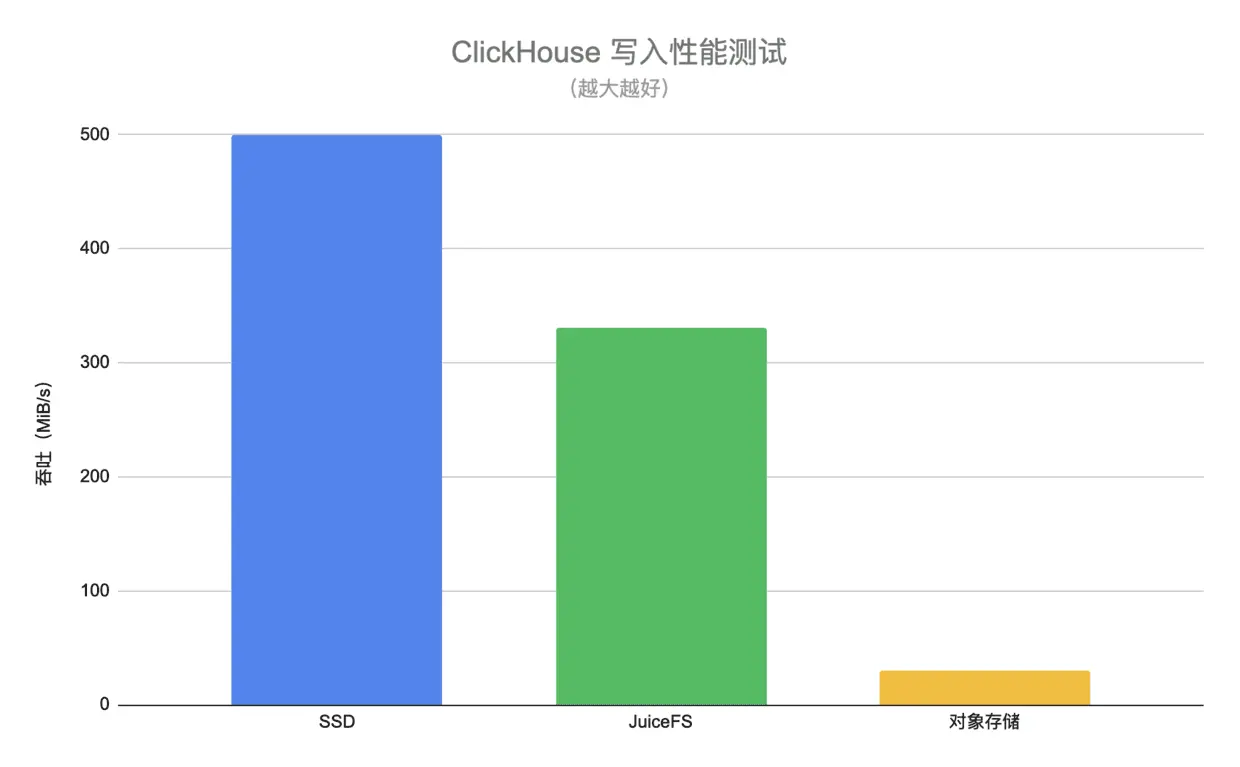
以 SSD 盘作为基准,可以看到 JuiceFS 的写入性能与 SSD 盘有 30% 左右的性能差距,但是相比对象存储有 11 倍的性能提升。这里 JuiceFS 的测试中开启了 writeback 选项,这是因为 ClickHouse 在写入时每个 part 会产生大量的小文件(KiB 级),客户端采用异步写入的方式能明显提升性能,同时大量的小文件对于查询性能也会造成一定影响。
在了解了直接写入不同介质的性能以后,接下来测试冷热数据分离方案的写入性能。经过实际业务测试,基于 JuiceFS 的冷热数据分离方案表现稳定,因为新数据都是直接写入 SSD 盘,因此写入性能与上面测试中的 SSD 盘性能相当。SSD 盘上的数据可以很快迁移到 JuiceFS 上,在 JuiceFS 上对数据 part 进行合并也都是没有问题的。
查询性能测试
查询性能测试使用真实业务中的数据,并选取几个典型的查询场景进行测试。其中 q1-q4 是扫描全表的查询,q5-q7 是命中主键索引的查询。测试结果如下图:
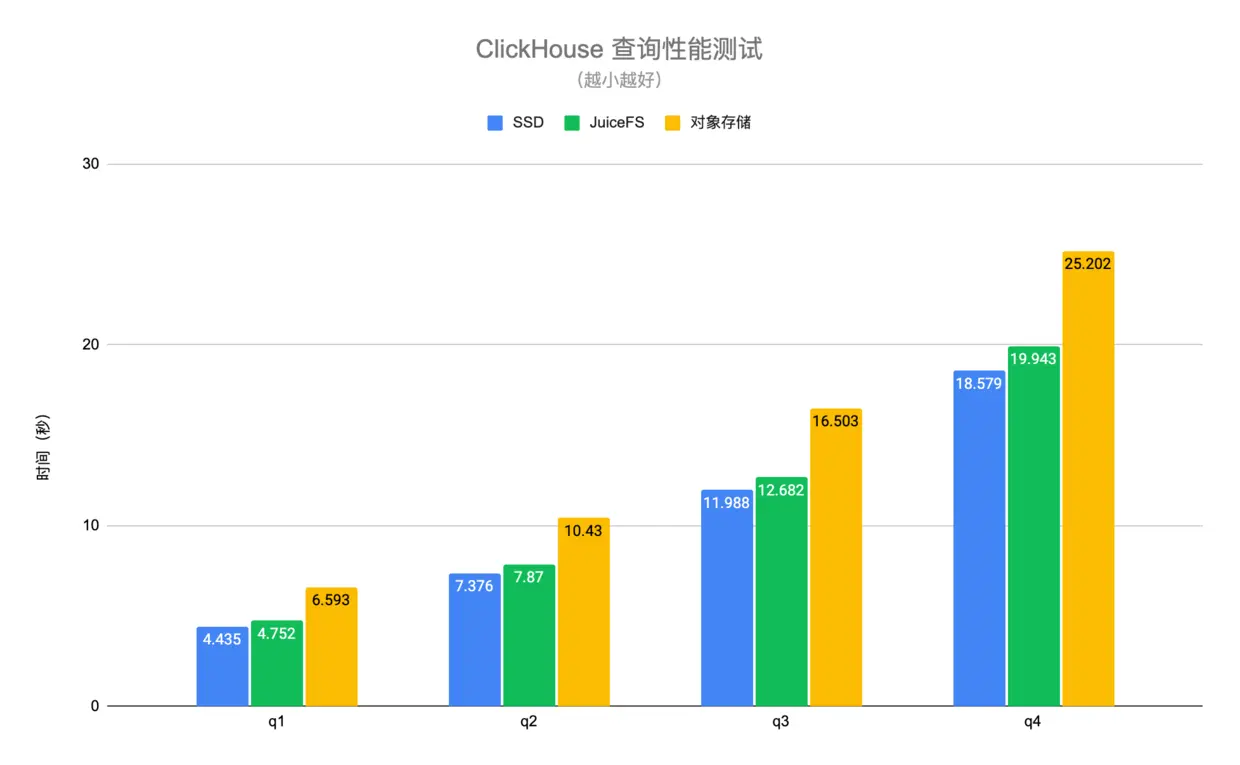
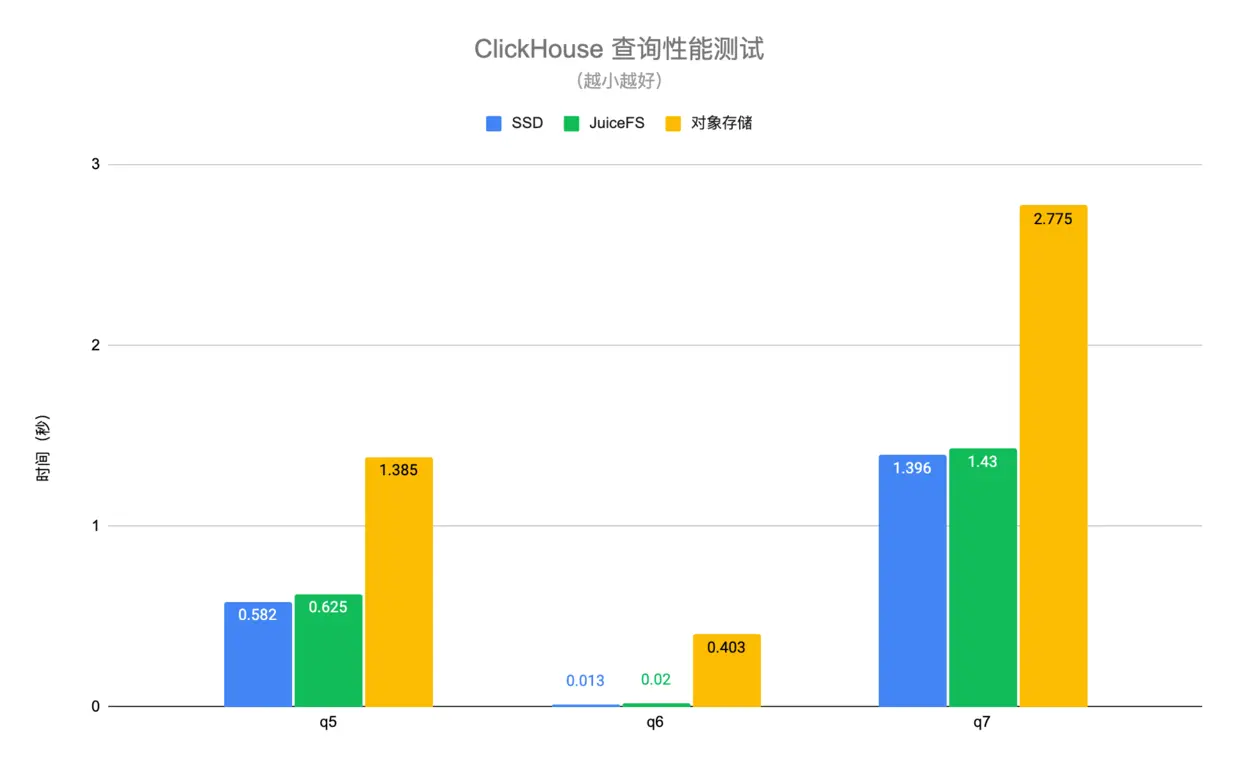
可以看到 JuiceFS 与 SSD 盘的查询性能基本相当,平均差异在 6% 左右,但是对象存储相比 SSD 盘有 1.4 至 30 倍的性能下降。得益于 JuiceFS 高性能的元数据操作以及本地缓存特性,可以自动将查询请求需要的热数据缓存在 ClickHouse 节点本地,大幅提升了 ClickHouse 的查询性能。需要注意的是以上测试中对象存储是通过 ClickHouse 的 S3 磁盘类型进行访问,这种方式只有数据是存储在对象存储上,元数据还是在本地磁盘。如果通过类似 S3FS 的方式把对象存储挂载到本地,性能会有进一步的下降。
在完成基础的查询性能测试以后,接下来测试冷热数据分离方案下的查询性能。区别于前面的测试,当采用冷热数据分离方案时,并不是所有数据都在 JuiceFS 中,数据会优先写入 SSD 盘。
首先选取一个固定的查询时间范围,评估 JuiceFS 缓存对性能的影响,测试结果如下图:
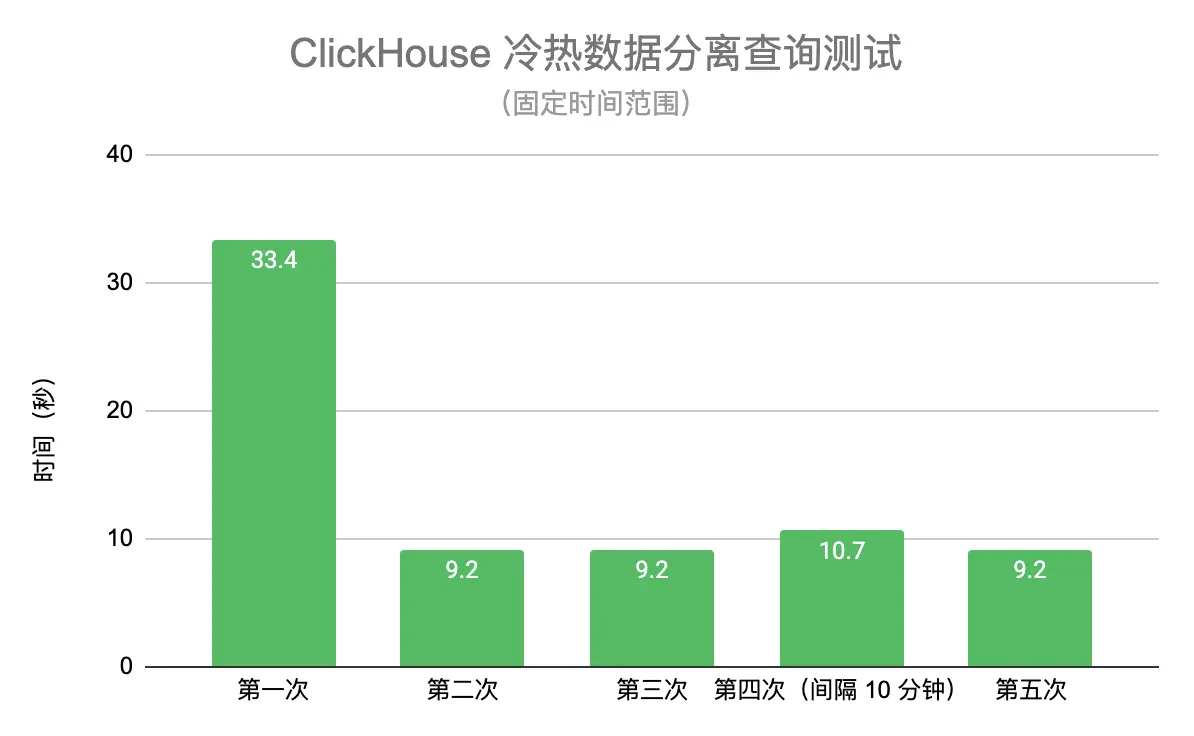
跟固定时间范围的查询一样,从第二次查询开始因为缓存的建立带来了 78% 左右的性能提升。不同的地方在于第四次查询因为涉及到查询新写入或者合并后的数据,而 JuiceFS 目前不会在写入时缓存大文件,会对查询性能造成一定影响,之后会提供参数允许缓存写入数据来改善新数据的查询性能。
总结
通过 ClickHouse 的存储策略可以很简单地将 SSD 和 JuiceFS 结合使用,实现性能与成本的两全方案。从写入和查询性能测试的结果上来看 JuiceFS 完全可以满足 ClickHouse 的使用场景,用户不必再担心容量问题,在增加少量成本的情况下轻松应对未来几倍的数据增长需求。JuiceFS 目前已经支持超过 20 家公有云的对象存储,结合完全兼容 POSIX 的特性,不需要改动 ClickHouse 任何一行代码就可以轻松接入云上的对象存储。
展望
在当前越来越强调云原生的环境下,存储计算分离已经是大势所趋。ClickHouse 2021 年的 roadmap 上已经明确把存储计算分离作为了主要目标,虽然目前 ClickHouse 已经支持把数据存储到 S3 上,但这个实现还比较粗糙。未来 JuiceFS 也会与 ClickHouse 社区紧密合作共同探索存算分离的方向,让 ClickHouse 更好地识别和支持共享存储,实现集群伸缩时不需要做任何数据拷贝。
其他:
Elasticsearch 存储成本省 60%,稿定科技干货分享
ClickHouse 存算分离架构探索的更多相关文章
- 从 Hadoop 到云原生, 大数据平台如何做存算分离
Hadoop 的诞生改变了企业对数据的存储.处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变:随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hado ...
- 存算分离下写性能提升10倍以上,EMR Spark引擎是如何做到的?
引言 随着大数据技术架构的演进,存储与计算分离的架构能更好的满足用户对降低数据存储成本,按需调度计算资源的诉求,正在成为越来越多人的选择.相较 HDFS,数据存储在对象存储上可以节约存储成本,但与此 ...
- 腾讯云 CHDFS — 云端大数据存算分离的基石
随着网络性能提升,云端计算架构逐步向存算分离转变,AWS Aurora 率先在数据库领域实现了这个转变,大数据计算领域也迅速朝此方向演化. 存算分离在云端有明显优势,不但可以充分发挥弹性计算的灵活,同 ...
- 一文读懂GaussDB(for Mongo)的计算存储分离架构
摘要:IDC认为,目前阶段来看,企业亟待解决的是数字化能力提升,包括:与业务的深入结合能力:数据处理和挖掘能力:以及IT技术运营和管理能力.特别是数据处理和挖掘能力,因为数字化转型推进企业从以流程为核 ...
- 突破冯·诺依曼架构瓶颈!全球首款存算一体AI芯片诞生
过去70年,计算机一直遵循冯·诺依曼架构设计,运行时数据需要在处理器和内存之间来回传输. 随着时代发展,这一工作模式面临较大挑战:在人工智能等高并发计算场景中,数据来回传输会产生巨大的功耗:目前内存系 ...
- QQ音乐PB级ClickHouse实时数据平台架构演进之路
导语 | OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值.本文基于QQ音乐海量大数据实时分析场景,通过Q ...
- Sentry(v20.12.1) K8S 云原生架构探索,SENTRY FOR JAVASCRIPT SDK 配置详解
系列 Sentry-Go SDK 中文实践指南 一起来刷 Sentry For Go 官方文档之 Enriching Events Snuba:Sentry 新的搜索基础设施(基于 ClickHous ...
- Sentry(v20.12.1) K8S 云原生架构探索,JavaScript Enriching Events(丰富事件信息)
系列 Sentry-Go SDK 中文实践指南 一起来刷 Sentry For Go 官方文档之 Enriching Events Snuba:Sentry 新的搜索基础设施(基于 ClickHous ...
- Flink不止于计算,存算一体才是未来
"伴随着实时化浪潮的发展和深化,Flink 已逐步演进为实时流处理的领军技术和事实标准.Flink 一方面持续优化其流计算核心能力,不断提高整个行业的流计算处理标准,另一方面沿着流批一体 ...
随机推荐
- 一种封装Retrofit的方法,可以自动解析Gson,回避Method return type must not include a type variable or wildcard: retrofit2.Call<T>的问题
封装目的:屏蔽底层实现,提供统一接口,并支持Gson自动转化 最初封装: //请求方法 interface RequestListener { interface PostListener { @PO ...
- JVM加载class文件的一些理解
Java是一种动态解释型语言,类(class)只有被加载到JVM中后才能运行.每当一个Java程序运行时,都会有一个对应的JVM实例,只有当程序运行结束后,这个JVM才会退出.JVM实例通过调用类的m ...
- Linux核心知识
电脑:辅助人脑的工具 现在的人们几乎无时无刻都会碰电脑!不管是桌上型电脑(桌机).笔记型电脑(笔电).平板电脑.智慧型手机等等,这些东西都算是电脑.虽然接触的这么多,但是,你了解电脑里面的元件有什么吗 ...
- 使用Mosquitto实现MQTT客服端C语言
上一篇文章已经将mosquitto移植到了arm平台上,现在将使用mosquitto完成mqtt客服端的demo,了解过mqtt协议的小伙伴都知道,mqtt主要分为代理服务器.发布者.订阅者三部分 ...
- Mysql常用sql语句(4)- distinct 去重数据
测试必备的Mysql常用sql语句系列 https://www.cnblogs.com/poloyy/category/1683347.html 前言 我们使用select进行数据查询时是会返回所有匹 ...
- C#开源类库SimpleTCP
目录 简介 使用方法 实现客户端 实现服务端 总结 简介 工作中经常遇到需要实现TCP客户端或服务端的时候,如果每次都自己写会很麻烦且无聊,使用SuperSocket库又太大了.这时候就可以使用Sim ...
- Python - poetry(3)配置项详解
config 命令 poetry 通过 config 命令进行配置 也可以直接在 config.toml 文件中进行配置,该文件将在首次运行该命令时自动创建 文件目录 macOS:~/Library/ ...
- 管理后台界面 详细分析(内含代码 |【前端】)RuoYi
最近在做的一个后台管理 因为关于隐私原因 只方便展示个别页面代码 不会上传项目 注意是前端代码 我把项目代码地址放在最后了 如有需要可自取学习 我会为各位兄弟详细的介绍其中各个属性的含义和用法,记 ...
- python中字典按键、值进行排序
看到排序,就不禁想起python中的sort和sorted sort是列表中的方法,用于对列表进行排序(改变的是原列表,不返回新列表) 用法: list.sort(key=None,reverse=T ...
- PHP的Mcrypt加密扩展知识了解
今天我们来学习的是 PHP 中的一个过时的扩展 Mcrypt .在 PHP7 之前,这个扩展是随 PHP 安装包一起内置发布的,但是现在新版本的 PHP 中已经没有了,需要使用这个扩展的话我们需要单独 ...