Flink的窗口处理机制(一)
一、为什么需要 window ?
在流处理应用中,数据是连续不断的,即数据是没有边界的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
流上的聚合需要由 window 来划定范围,比如 “计算过去的5分钟” ,或者 “最后100个元素的和” 。
window是一种可以把无限数据流切割为有限数据块的手段。
Flink 认为 Batch 是 Streaming 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。
而窗口(window)就是从 Streaming 到 Batch 的一个桥梁。
二、窗口的生命周期
窗口的生命周期,就是指窗口从创建、触发执行、到销毁的过程。
那么这个时候需要思考四个问题
1、数据元素是如何分配到对应窗口中的(也就是窗口的分配器)?
2、元素分配到对应窗口之后什么时候会触发计算(也就是窗口的触发器)?
3、在窗口内我们能够进行什么样的操作(也就是窗口内的操作)?
4、当窗口过期后是如何处理的(也就是窗口的销毁关闭)?
其实这四个问题从大体上可以理解为窗口的整个生命周期过程。接下来我们对每个环节进行讲解
创建:当属于该窗口的第一个元素到达时就会创建该窗口
销毁:当时间(事件或处理时间)超过窗口的结束时间戳加上用户指定的允许延迟时间,窗口将被完全删除。 Flink保证仅删除基于时间的窗口而不是其他类型的窗口,例如全局窗口。
例如,使用基于事件时间的窗口策略,每5分钟创建一个不重叠(或翻滚)的窗口并允许延迟1分钟,当具有落入该间隔的时间戳的第一个元素到达时,Flink将为12:00到12:05之间的间隔创建一个新窗口,当水位线(watermark)到12:06时间戳时它将删除它。【这里同时我们也可以明白watermark的作用】
Trigger触发器:指定了窗口函数在什么条件下可被触发,触发器还可以决定在创建和删除窗口之间的任何时间清除窗口的内容。在这种情况下,清除仅限于窗口中的元素,而不是窗口元数据。这意味着新数据仍然可以添加到该窗口中。
例如:当窗口中的元素个数超过4个时 或者 当水印达到窗口的边界时―触发计算
Window的函数:函数里定义了应用于窗口(Window)内容的计算逻辑
Evictor(驱逐器):将在触发器触发之后或者在函数被应用前后,清除窗口中的元素
三、Keyed vs Non-Keyed Windows
在定义窗口之前,首先要指定你的流是否应该被keyBy()分区,这个必须要窗口定义前确定。使用 keyBy(...) 后,不同的 key 会被划分到不同的流里面,每个流可以被一个单独的 task 处理。而相同的key将会被分配到同一个keyed Stream,被同一个task处理。
如果 不使用 keyBy ,所有数据会被划分到一个窗口里,汇总到一个task处理,并行度是1.
PS:最大并行度=container个数 * 每个container上最大slot数
api调用如下:
Keyed Windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
四、Window Assigners 窗口指派器
数据经过控制流的处理之后,无论是keyed Stream还是Non-keyed Stream,两种控制流都需要指定一个window Assinger,负责将每个传入的元素分配给一个或多个窗口,有了window Assinger,才会创建出各种形式的window来覆盖我们所需的各种场景,对我们开发来说不需要关注window本身,只需要关注Window Assinger的分类即可,所以很多关于Flink的视频都没有讲解控制流的概念,只讲了Window的分类。
Flink中的窗口从大体上划分有以下几个大类:
第一种是基于时间划分的窗口,叫TimeWindow。(比如每30秒)
第二种是基于数据数量划分的窗口,叫CountWindow。(比如每100个元素)
第三种是全局窗口,不划分的。
还有就是自定义窗口类型。(通过继承WindowAssigner类来实现自定义窗口分配器逻辑)
api介绍:
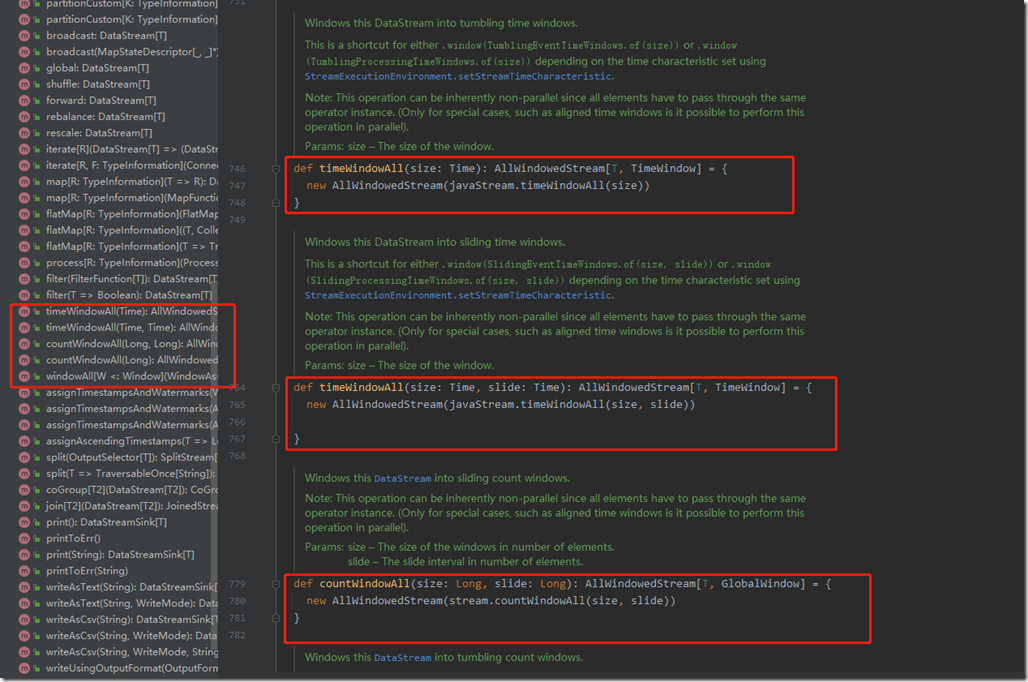
当input的Stream进行keyBy()之后,就会生成一个KeyedStream,而KeyedStream实现了timeWindow()、countWindow()、window()等方法。源码如下图:
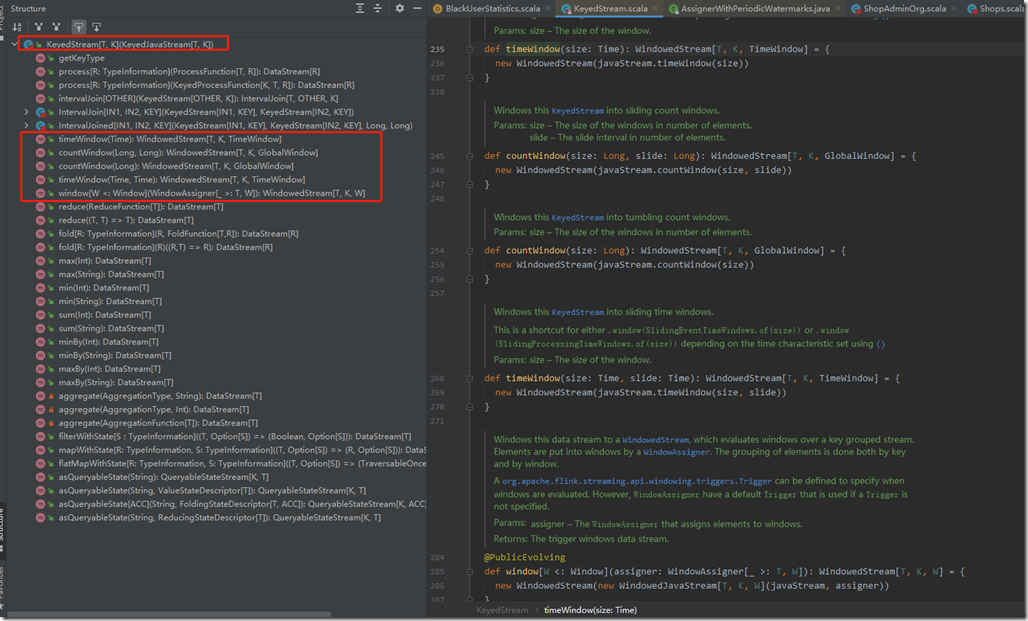
如果dataStream没有经过keyBy(),就是Non-keyed Stream,就是原生的dataStream的话,其实它也可以调用窗口函数。api源码如下:
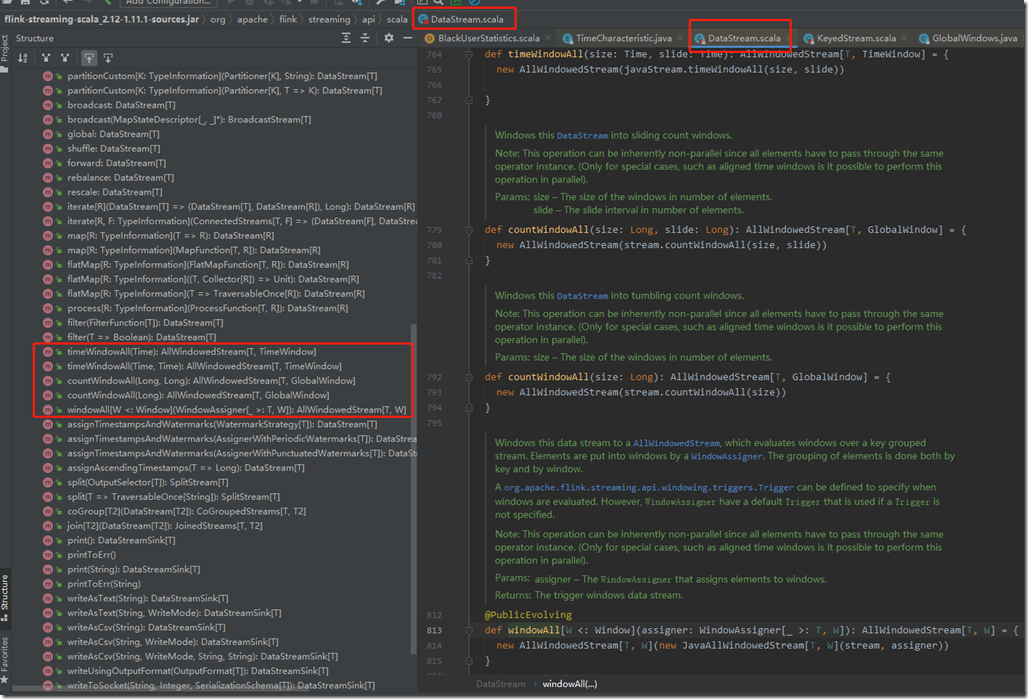
我们发现Non-keyed Stream相比keyed Stream,Window Assigner的调用方式上,只是多了个All。
下面先基于常用的KeyedStream来介绍常用的window Assigner
1、TimeWindow
TimeWindow按照时间来生成窗口。每个时间窗口都有一个开始时间和结束时间,表示一个左闭右开的时间段,表示了窗口的区间大小。
(编程技巧:可以通过TimeWindow对象的getStart()、getEnd()方法来获取窗口的开始时间和结束时间的时间戳,也可以通过maxTimestamp() 方法来获取窗口内的最大时间戳。)
根据不同的业务场景,Time Window 也可以分为三种类型,
分别是滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)和会话窗口(Session Window)
我们知道Flink中的时间类型可以划分为三种:
1、Event Time:事件时间,即事件产生的时间
2、IngestionTime:摄入时间,事件进入流处理系统的时间,也就是数据进入flink的时间
3、Processing Time:处理时间,消息被flink计算框架处理的时间
这里主要考虑事件时间和处理时间,所以上面的每种窗口又可分别基于processing time和event time。
首先,我们来查看TimeWindow的api,这个窗口指派器需要紧跟在数据流后面。它是KeyedStream下的方法。
方式一:直接使用KeyedStream下的timeWindow()方法。
里面接一个参数的就表示是滚动时间窗口,接两个参数的就表示是滑动时间窗口。
在这里处理的是事件时间还是处理时间,取决于env设置的TimeCharacteristic参数。
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
调用如下:
// Stream of (sensorId, carCnt )
val vehicleCnts: DataStream[(Int, Int)] = ... // timeWindow后面接一个参数就表示是滚动时间窗口
val tumblingCnts: DataStream[ (Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling time window of 1 minute length
.timeWindow(Time.minutes(1))
// compute sum over carCnt
.sum(1) // timeWindow后面接两个参数就表示是滑动时间窗口
val slidingCnts: DataStream[ (Int, Int)] = vehicleCnts
.keyBy(0)
// sliding time window of 1 minute Length and 30 secs trigger interval
.timeWindow(Time.minutes(1), Time.seconds(30))
.sum(1 )
方式二:使用KeyedStream下的window()方法
需要在参数里指明使用哪种时间窗口类型。
这也是官方文档指定的方式。
支持滚动窗口、滑动窗口、会话窗口和全局窗口。
inputStream.keyBy()
.window(TumblingEventTimeWindows.of(Time.seconds(5))) // window里面的窗口类型可以换成:
1、TumblingEventTimeWindows() 滚动事件时间窗口
2、TumblingProcessingTimeWindows() 滚动处理时间窗口
3、SlidingEventTimeWindows() 滑动事件时间窗口
4、SlidingProcessingTimeWindows() 滑动处理时间窗口
5、EventTimeSessionWindows() 事件时间会话窗口
6、ProcessingTimeSessionWindows() 处理时间会话窗口
7、GlobalWindows.create() 全局窗口
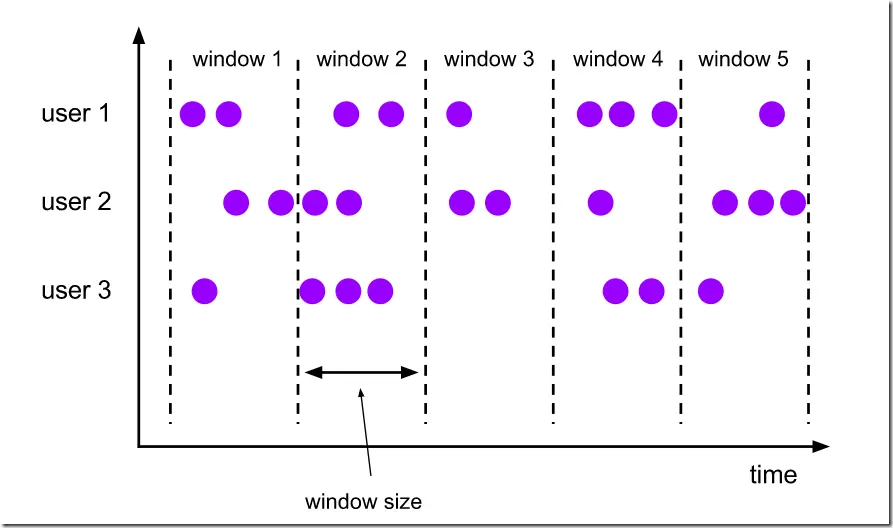
1.1、Tumbling Window(滚动窗口)
滚动窗口的概念:
- 滚动窗口能将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口
- 滚动窗具有固定的尺寸,不重叠。
滚动窗口的划分,可以基于时间戳来进行划分窗口,也可以基于到来的事件元素数量来划分窗口。
因为我们这里考虑的是TimeWindow,所以这里考虑基于时间戳来进行窗口划分。
例如,如果您指定了一个大小为5分钟的滚动窗口,那么每5分钟将会启动一个新窗口,
如下图:
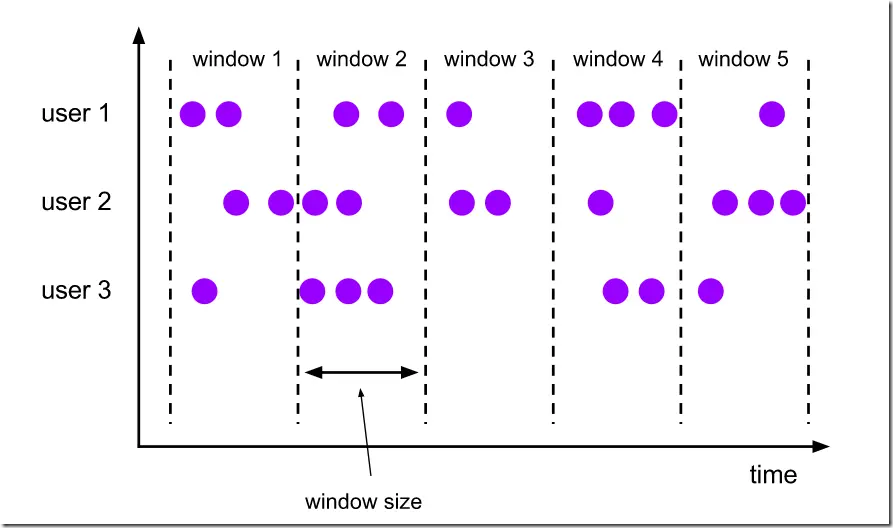
滚动时间窗口api。
方式一:直接使用.timeWindow()
// inputStream进行keyby后,调用.timeWindow方法,
// 滚动timeWindow里面就一个参数,指明每10秒划分一个时间窗口
keyedStream.timeWindow(Time.seconds(10));
注意:这种方式,如果需要按照处理时间划分窗口,需要在env指明TimeCharacteristic时间类型。
例如:
// 默认就是EventTime,ProcessingTime需要显式指定
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
方式二:使用window()
使用window()的方式,就不需要在env里单独指定TimeCharacteristic时间类型,因为在window()的参数里需要传入指定的参数。
val input: DataStream[T] = ... // tumbling event-time windows
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>) // tumbling processing-time windows
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>) // 这种方式可以指定窗口的对齐方式,
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
如上段代码中最后一个例子展示的那样,tumbling window assigners包含一个可选的offset参数,我们可以用它来改变窗口的对齐方式。
如果我们指定了一个15分钟的窗口,那么每个小时内,每个窗口的开始时间和结束时间为:
[00:00,00:15)
[00:15,00:30)
[00:30,00:45)
[00:45,01:00)
如果我们指定了一个5分钟的offset,那么每个窗口的开始时间和结束时间为:
[00:05,00:20)
[00:20,00:35)
[00:35,00:50)
[00:50,01:05)
一个实际的应用场景是,我们可以使用 offset 使我们的时区以0时区为准。比如我们生活在中国,时区是 UTC+08:00,可以指定一个 Time.hour(-8),使时间以0时区为准。
滚动窗口适用场景:
适用场景:适合做每个时间段的聚合计算,BI分析。例如统计某页面每分钟点击的pv。
场景1:我们需要统计每一分钟中用户购买的商品的总数,需要将用户的行为事件按每一分钟进行切分,这种切分被成为翻滚时间窗口(Tumbling Time Window)。
应用案例:
编写代码模拟:
下面代码仅仅是模拟,每5秒划分一个窗口,打印输出信息。跟上面购买商品的场景无关。
package com.lagou.window; import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector; import java.text.SimpleDateFormat;
import java.util.Iterator;
import java.util.Random; /**
* @author doublexi
* @date 2021/10/30 11:37
* @description 基于时间的滚动时间窗口
* 1、获取流数据源
* 2、获取窗口
* 3、操作窗口数据
* 4、输出窗口数据
*/
public class WindowDemo {
public static void main(String[] args) throws Exception {
// 获取数据源
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 使用匿名内部类的方式添加自定义数据源
DataStreamSource<String> data = env.addSource(new SourceFunction<String>() {
int count = 0; // 每1秒产生一个数字,拼接字符串作为数据源事件发送出去。
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (true) {
ctx.collect(count + "号数据源");
count++;
Thread.sleep(1000);
}
} @Override
public void cancel() { }
}); // 对输入的流的数据进行转换封装
SingleOutputStreamOperator<Tuple3<String, String, String>> maped = data.map(new MapFunction<String, Tuple3<String, String, String>>() {
@Override
public Tuple3<String, String, String> map(String value) throws Exception {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
long l = System.currentTimeMillis();
String dataTime = sdf.format(l);
Random random = new Random();
int randomNum = random.nextInt(5);
return new Tuple3<>(value, dataTime, String.valueOf(randomNum));
}
});
// 为了增加并行度,进行keyBy聚合操作,相同key数据会进入同一个分区,给同一个subtask任务
KeyedStream<Tuple3<String, String, String>, String> keyByed = maped.keyBy(value -> value.f0); // 2、获取窗口
// 基于时间驱动, 每5s割出一个窗口
WindowedStream<Tuple3<String, String, String>, String, TimeWindow> timeWindow = keyByed.timeWindow(Time.seconds(5));
// 基于事件驱动, 每相隔3个事件(即三个相同key的数据), 划分一个窗口进行计算
// WindowedStream<Tuple2<String, Integer>, Tuple, GlobalWindow> countWindow = keyedStream.countWindow(3); // 3、操作窗口数据
// apply是窗口的应用函数,即apply里的函数将应用在此窗口的数据上。
// 第一个参数Tuple3是窗口输入进来的数据类型,第二个参数Object是输出的数据类型,第三个参数String是数据源中key的数据类型,第四个参数指明当前处理的窗口是什么类型的窗口
SingleOutputStreamOperator<String> applyed = timeWindow.apply(new WindowFunction<Tuple3<String, String, String>, String, String, TimeWindow>() {
// s就是上面一行一行的数据源,window代表当前窗口,
// 一个窗口中数据源可能是相同的,根据keyBy分组的,如果有两个数据源相同,就会放入这个input迭代器里,
// out将处理结果往外发送
@Override
public void apply(String s, TimeWindow window, Iterable<Tuple3<String, String, String>> input, Collector<String> out) throws Exception {
Iterator<Tuple3<String, String, String>> iterator = input.iterator();
// new 一个StringBuilder去做字符串拼接
StringBuilder sb = new StringBuilder();
while (iterator.hasNext()) {
// 这个next就是一个一个Tuple3数据
Tuple3<String, String, String> next = iterator.next();
sb.append(next.f0 + "..." + next.f1 + "..." + next.f2);
}
// 拼接输出的信息,
String s1 = s + "..." + window.getStart() + "..." + sb;
out.collect(s1);
}
}); applyed.print(); // 转换算子都是lazy init的, 最后要显式调用 执行程序
env.execute(); }
}
上面timeWindow.apply()方法里面是使用匿名内部类的方式,实现WindowFunction接口。
我们也可以通过自定义类实现WindowFunction方式都可以。
运行结果:
因为我们将时间窗口设置为5s,所以它是隔一段时间输出一次。
输出内容中:
这里第一个就是s数据源本身,
第二个就是window.getStart(),窗口的开始时间,
第三个字段数据就是input里的Tuple3里的第一个参数value,数据源本身,
第四个字段数据就是处理时间,当时用的system.currentTimemills,
第五个字段数据就是一个5以内的随机数
window.getStart()时间相同,表示它是同一个窗口里的数据。
2021-10-30 12:29:15.295数据处理时间不一样,因为它是属于不同的任务槽,它是并发执行的,哪个任务槽先处理完就先输出哪个。
5> 0号数据源...1635568150000...0号数据源...2021-10-30 12:29:14.395...1 6> 1号数据源...1635568155000...1号数据源...2021-10-30 12:29:15.295...0
8> 3号数据源...1635568155000...3号数据源...2021-10-30 12:29:17.308...2
4> 2号数据源...1635568155000...2号数据源...2021-10-30 12:29:16.302...0
1> 4号数据源...1635568155000...4号数据源...2021-10-30 12:29:18.315...0
1> 5号数据源...1635568155000...5号数据源...2021-10-30 12:29:19.322...1 8> 8号数据源...1635568160000...8号数据源...2021-10-30 12:29:22.342...1
2> 6号数据源...1635568160000...6号数据源...2021-10-30 12:29:20.329...4
2> 10号数据源...1635568160000...10号数据源...2021-10-30 12:29:24.355...0
5> 9号数据源...1635568160000...9号数据源...2021-10-30 12:29:23.349...2
4> 7号数据源...1635568160000...7号数据源...2021-10-30 12:29:21.334...0 8> 13号数据源...1635568165000...13号数据源...2021-10-30 12:29:27.377...4
5> 12号数据源...1635568165000...12号数据源...2021-10-30 12:29:26.369...1
6> 14号数据源...1635568165000...14号数据源...2021-10-30 12:29:28.384...4
4> 11号数据源...1635568165000...11号数据源...2021-10-30 12:29:25.361...0
4> 15号数据源...1635568165000...15号数据源...2021-10-30 12:29:29.388...1 4> 18号数据源...1635568170000...18号数据源...2021-10-30 12:29:32.306...1
3> 16号数据源...1635568170000...16号数据源...2021-10-30 12:29:30.395...3
6> 17号数据源...1635568170000...17号数据源...2021-10-30 12:29:31.301...0
3> 20号数据源...1635568170000...20号数据源...2021-10-30 12:29:34.320...3
3> 19号数据源...1635568170000...19号数据源...2021-10-30 12:29:33.313...0 Process finished with exit code -1
1.2、Sliding Window(滑动窗口)
滑动窗口的概念:
滑动窗口的划分同滚动一样,可以基于时间戳来进行划分窗口,也可以基于到来的事件元素数量来划分窗口。因为我们这里考虑的是TimeWindow,所以这里考虑基于时间戳来进行滑动窗口划分。
概念:
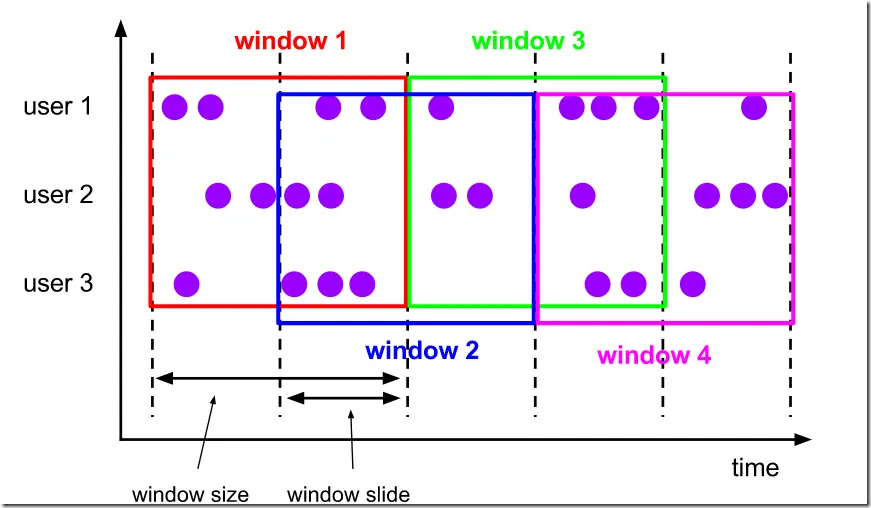
滑动窗口也是一种比较常见的窗口类型,其特点是在滚动窗口基础之上增加了窗口滑动时间(Slide Time),且允许窗口数据发生重叠。
当 Windows size 固定之后,窗口并不像滚动窗口按照 Windows Size 向前移动,而是根据设定的 Slide Time 向前滑动。
窗口之间的数据重叠大小根据 Windows size 和 Slide time 决定,
- 当 Slide time 小于 Windows size便会发生窗口重叠,
- Slide size 大于 Windows size 就会出现窗口不连续,数据可能不能在任何一个窗口内计算,
- Slide size 和 Windows size 相等时,Sliding Windows 其实就是Tumbling Windows。
滑动窗口是滚动窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成
特点:
- 窗口长度固定,可以有重叠,可以有空隙。
- 一个元素可以对应多个窗口,也可以不属于任意一个窗口,看slide size而定。
比如下图这样,设置了一个10分钟大小的滑动窗口,它的滑动参数(slide)为5分钟。这样的话,每5分钟将会创建一个新的窗口,并且这个窗口中包含了一部分来自上一个窗口的元素。
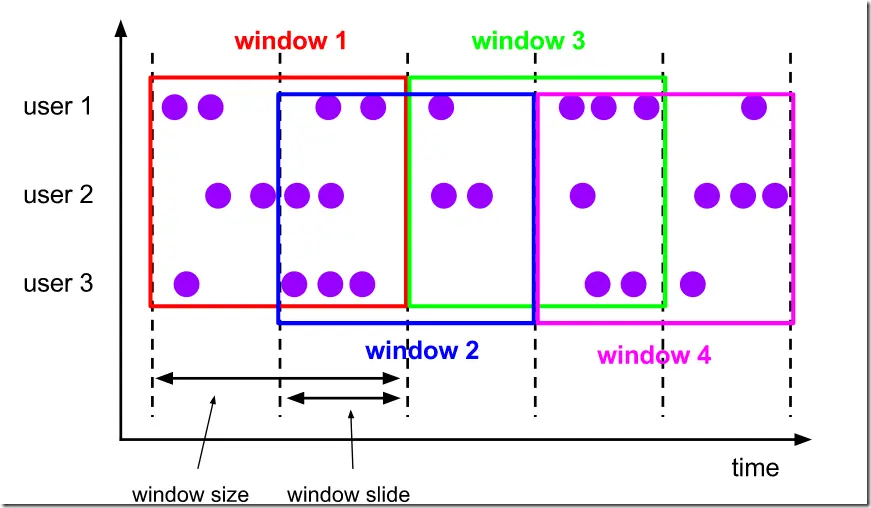
基于时间的滑动窗口
场景: 我们可以每30秒计算一次最近一分钟用户购买的商品总数。
基于事件的滑动窗口
场景: 每10个 “相同”元素计算一次最近100个元素的总和.
滑动窗口适用场景:
适用场景:对最近一段时间段内进行统计(如某接口近几分钟的失败调用率)
比如:每隔3秒计算最近5秒内,每个基站的日志数量
每30秒计算一次最近一分钟用户购买的商品总数。
滑动时间窗口调用api:
也分为timeWindow()和window()两种调用方式。
方式一:直接使用.timeWindow()
// inputStream进行keyby后,调用.timeWindow方法,
// 滑动timeWindow里面比滚动多一个参数,窗口滑动间隔slide time
// 增加了一个Time.seconds(2),表示一个步长,向右滑动2秒后,生成一个新的窗口。
keyedStream.timeWindow(Time.seconds(5), Time.seconds(2));
注意:这种方式,如果需要按照处理时间划分窗口,也需要在env指明TimeCharacteristic时间类型。
例如:
// 默认就是EventTime,ProcessingTime需要显式指定
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
方式二:使用window()
使用window()的方式,就不需要在env里单独指定TimeCharacteristic时间类型,因为在window()的参数里需要传入指定的参数。
DataStream<T> input = ...; // sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>); // sliding processing-time windows
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>); // sliding processing-time windows offset by -8 hours
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>);
同样,我们可以通过offset参数来为窗口设置偏移量。
应用案例:
这里根据1.1的滚动时间窗口案例改编,数据源、计算逻辑都不变,只是单纯的增加了一个滑动时间间隔,就变成了滑动时间窗口了。
下面是每5秒划分一个窗口间隔,滑动间隔为2秒。
keyByed.timeWindow(Time.seconds(5), Time.seconds(2));
意思就是每2秒统计一下最近5秒内的数据情况,我们这里直接打印输出了。
完整代码如下:
package com.lagou.window; import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector; import java.text.SimpleDateFormat;
import java.util.Iterator;
import java.util.Random; /**
* @author doublexi
* @date 2021/10/30 11:37
* @description 基于时间的滑动时间窗口
* 1、获取流数据源
* 2、获取窗口
* 3、操作窗口数据
* 4、输出窗口数据
*/
public class WindowDemoSlide {
public static void main(String[] args) throws Exception {
// 获取数据源
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> data = env.addSource(new SourceFunction<String>() {
int count = 0; @Override
public void run(SourceContext<String> ctx) throws Exception {
while (true) {
ctx.collect(count + "号数据源");
count++;
Thread.sleep(1000);
}
} @Override
public void cancel() { }
});
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); // 2、获取窗口
SingleOutputStreamOperator<Tuple3<String, String, String>> maped = data.map(new MapFunction<String, Tuple3<String, String, String>>() {
@Override
public Tuple3<String, String, String> map(String value) throws Exception {
long l = System.currentTimeMillis();
String dataTime = sdf.format(l);
Random random = new Random();
int randomNum = random.nextInt(5);
return new Tuple3<>(value, dataTime, String.valueOf(randomNum));
}
});
// 为了增加并行度,进行keyBy聚合操作,相同key数据会进入同一个分区,给同一个subtask任务
KeyedStream<Tuple3<String, String, String>, String> keyByed = maped.keyBy(value -> value.f0);
// 每5s割出一个窗口,并且每2秒向前移动,滑动间隔为2s。
WindowedStream<Tuple3<String, String, String>, String, TimeWindow> timeWindow = keyByed.timeWindow(Time.seconds(5), Time.seconds(2)); // 3、操作窗口数据
// 第一个参数Tuple3是窗口输入进来的数据类型,第二个参数Object是输出的数据类型,第三个参数String是数据源中key的数据类型,第四个参数指明当前处理的窗口是什么类型的窗口
SingleOutputStreamOperator<String> applyed = timeWindow.apply(new WindowFunction<Tuple3<String, String, String>, String, String, TimeWindow>() {
// s就是上面一行一行的数据源,window代表当前窗口,
// 一个窗口中数据源可能是相同的,根据keyBy分组的,如果有两个数据源相同,就会放入这个input迭代器里,
// out将处理结果往外发送
@Override
public void apply(String s, TimeWindow window, Iterable<Tuple3<String, String, String>> input, Collector<String> out) throws Exception {
Iterator<Tuple3<String, String, String>> iterator = input.iterator();
// new 一个StringBuilder去做字符串拼接
StringBuilder sb = new StringBuilder();
while (iterator.hasNext()) {
// 这个next就是一个一个Tuple3数据
Tuple3<String, String, String> next = iterator.next();
sb.append(next.f0 + "..." + next.f1 + "..." + next.f2);
}
// 拼接输出的信息,
String s1 = s + "..." + sdf.format(window.getStart()) + "..." + sdf.format(window.getEnd()) + "..." + sb;
out.collect(s1);
}
}); applyed.print();
env.execute(); }
}
运行结果如下:
6> 1号数据源...2021-10-30 14:07:54.000...2021-10-30 14:07:59.000...1号数据源...2021-10-30 14:07:58.695...3
5> 0号数据源...2021-10-30 14:07:54.000...2021-10-30 14:07:59.000...0号数据源...2021-10-30 14:07:57.694...4 6> 1号数据源...2021-10-30 14:07:56.000...2021-10-30 14:08:01.000...1号数据源...2021-10-30 14:07:58.695...3
4> 2号数据源...2021-10-30 14:07:56.000...2021-10-30 14:08:01.000...2号数据源...2021-10-30 14:07:59.700...4
5> 0号数据源...2021-10-30 14:07:56.000...2021-10-30 14:08:01.000...0号数据源...2021-10-30 14:07:57.694...4
8> 3号数据源...2021-10-30 14:07:56.000...2021-10-30 14:08:01.000...3号数据源...2021-10-30 14:08:00.706...2 4> 2号数据源...2021-10-30 14:07:58.000...2021-10-30 14:08:03.000...2号数据源...2021-10-30 14:07:59.700...4
1> 4号数据源...2021-10-30 14:07:58.000...2021-10-30 14:08:03.000...4号数据源...2021-10-30 14:08:01.711...3
8> 3号数据源...2021-10-30 14:07:58.000...2021-10-30 14:08:03.000...3号数据源...2021-10-30 14:08:00.706...2
6> 1号数据源...2021-10-30 14:07:58.000...2021-10-30 14:08:03.000...1号数据源...2021-10-30 14:07:58.695...3
1> 5号数据源...2021-10-30 14:07:58.000...2021-10-30 14:08:03.000...5号数据源...2021-10-30 14:08:02.715...4 4> 7号数据源...2021-10-30 14:08:00.000...2021-10-30 14:08:05.000...7号数据源...2021-10-30 14:08:04.726...2
1> 5号数据源...2021-10-30 14:08:00.000...2021-10-30 14:08:05.000...5号数据源...2021-10-30 14:08:02.715...4
2> 6号数据源...2021-10-30 14:08:00.000...2021-10-30 14:08:05.000...6号数据源...2021-10-30 14:08:03.721...0
8> 3号数据源...2021-10-30 14:08:00.000...2021-10-30 14:08:05.000...3号数据源...2021-10-30 14:08:00.706...2
1> 4号数据源...2021-10-30 14:08:00.000...2021-10-30 14:08:05.000...4号数据源...2021-10-30 14:08:01.711...3 5> 9号数据源...2021-10-30 14:08:02.000...2021-10-30 14:08:07.000...9号数据源...2021-10-30 14:08:06.738...4
2> 6号数据源...2021-10-30 14:08:02.000...2021-10-30 14:08:07.000...6号数据源...2021-10-30 14:08:03.721...0
4> 7号数据源...2021-10-30 14:08:02.000...2021-10-30 14:08:07.000...7号数据源...2021-10-30 14:08:04.726...2
8> 8号数据源...2021-10-30 14:08:02.000...2021-10-30 14:08:07.000...8号数据源...2021-10-30 14:08:05.732...1
1> 5号数据源...2021-10-30 14:08:02.000...2021-10-30 14:08:07.000...5号数据源...2021-10-30 14:08:02.715...4
观察结果会发现:
我们这里相比滚动时间窗口,便于观察,我们增加了窗口的结束时间的打印。
并且窗口的开始时间与结束时间都不再使用时间戳,使用sdf格式化,转成了年月日时分秒的格式。
同一个窗口的开始时间都是一样的,不同窗口之间的滑动间隔,步长为2秒,并且同一个窗口内的时间仍然是5秒。
因为滑动间隔小于窗口大小,我们会发现有些数据会出现在多个窗口上。
1.3、Session Window (会话窗口)
会话窗口的概念:
会话窗口(Session Windows)主要是将某段时间内活跃度较高的数据聚合成一个窗口进行计算,窗口的触发的条件是 Session Gap,是指在规定的时间内如果没有数据活跃接入,则认为窗口结束,然后触发窗口计算结果。
需要注意的是如果数据一直不间断地进入窗口,也会导致窗口始终不触发的情况。
与滑动窗口、滚动窗口不同的是,Session Windows 不需要有固定 windows size 和 slide time,只需要定义 session gap,来规定不活跃数据的时间上限即可。
特点:
- 会话窗口根据会话的间隔来把数据分配到不同的窗口。
- 会话窗口不重叠,没有固定的开始时间和结束时间。
- 与翻滚窗口和滑动窗口相反, 当会话窗口在一段时间内(session gap)没有接收到元素时会关闭会话窗口。后续的元素将会被分配给新的会话窗口
如下图所示:
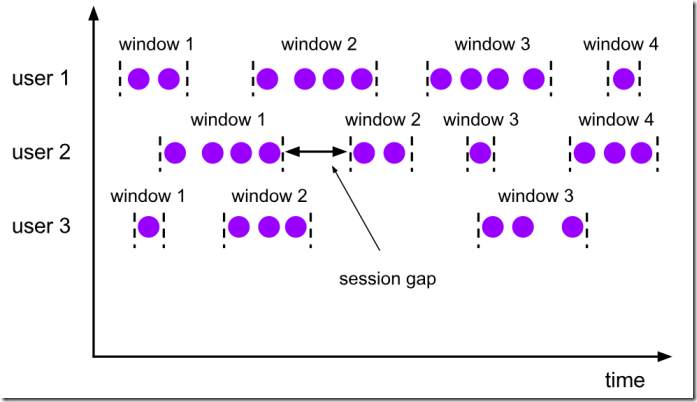
会话窗口就是根据上图中的session gap来切分不同的窗口,当一个窗口在大于session gap时间内没有接收到数据,窗口就会关闭,所以在这种模式下,窗口的长度是可变的,开始和结束时间也是不确定的,唯独可以设置定长的session gap.
该类窗口的特点:
- 时间无对齐
- 当前系统时间-分组内最后一次的时间如果超时,则进行触发计算
会话窗口分配器可以直接配置一个静态常量会话间隔,也可以通过函数来动态指定会话间隔时间。
我们可以设置定长的Session gap,也可以使用SessionWindowTimeGapExtractor动态地确定Session gap的长度。
适用场景:
在这种用户交互事件流中,我们首先想到的是将事件聚合到会话窗口中(一段用户持续活跃的周期),由非活跃的间隙分隔开。
场景一:如上图所示,就是需要计算每个用户在活跃期间总共购买的商品数量,如果用户30秒没有活动则视为会话断开(假设raw data stream是单个用户的购买行为流)。
场景二:3秒内如果没有数据进入,则计算每个基站的日志数量
场景三:比如音乐 app 听歌的场景,我们想统计一个用户在一个独立的 session 中听了多久的歌曲(如果超过15分钟没听歌,那么就是一个新的 session 了)
我们可以用 spark Streaming ,每一个小时进行一次批处理,计算用户session的数据分布,但是 spark Streaming 没有内置对 session 的支持,我们只能手工写代码来维护每个 user 的 session 状态,里面仍然会有诸多的问题。
我们使用 flink 来解决这个问题
(1)读取 kafka 中的数据
(2)基于用户的 userId,设置 一个 session window 的 gap,在同一个session window 中的数据表示用户活跃的区间
(3)最后使用一个自定义的 window Function
参考:https://cloud.tencent.com/developer/article/1539537
会话窗口api调用:
这里没有像timeWindow()类似的直接的api,要通过window方法指定窗口指派器的方式生成sessionWindow。
方式如下:
// 获取Session窗口
// 这里没有像TimeWindow类似的直接的api,要通过window方法指定窗口指派器的方式生成sessionWindow
// 这里会话窗口间隔为10s
WindowedStream<String, String, TimeWindow> sessionWindow = keyByed.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)));
我们仔细研究TimeWindow的源码,会发现,其实TimeWindow的本质也是通过这种方式去生成一个TimeWindow窗口的。
注意:这里的时间也分为处理时间(ProcessingTime)和事件时间(EventTime)。
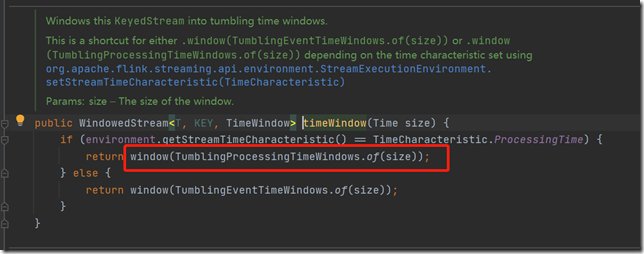
window方法,也就是将数据流放到WindowedStream里,里面包含的都是一些根据key进行分组的数据,
元素是根据windowAssigner来往里面放的。
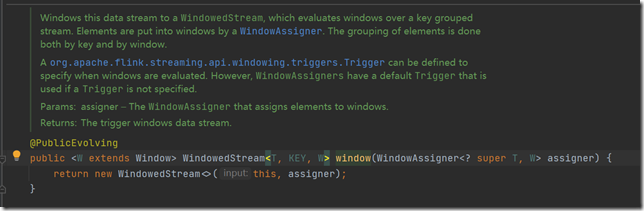
WindowAssigner就是指派0个或多个window给到元素。我们将哪些元素放到哪个window当中。
窗口指派器是指以怎样的规则将元素发给哪个window,哪些规则也就是窗口要包含哪些元素。
并且这些元素还都是根据key分组好的元素。
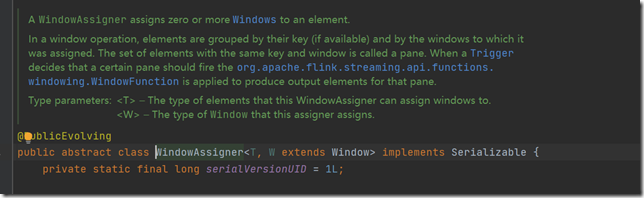
我们会发现withGap就是创建了一个新的SessionWindows的WindowAssigner。
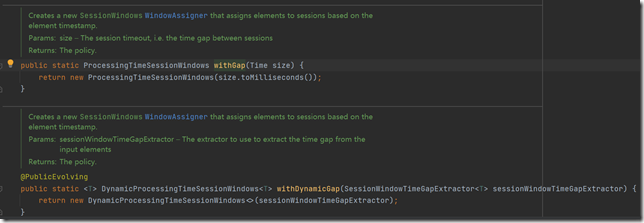
参照官网,api调用方式总结如下:
主要分EventTime与ProcessingTime,定长gap与不定长gap。
DataStream<T> input = ...; // event-time session windows with static gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>); // event-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap((element) -> {
// determine and return session gap
}))
.<windowed transformation>(<window function>);
// 或者这种方式也行:
// event-time session windows with dynamic gap
input
.keyBy(...)
.window(DynamicEventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[T] {
override def extract(element: T): Long = {
// determine and return session gap
}
}))
.<window function>(...) // processing-time session windows with static gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>); // processing-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// determine and return session gap
}))
.<windowed transformation>(<window function>);
// 动态的这种类也行
// processing-time session windows with dynamic gap
input
.keyBy(...)
.window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[T] {
override def extract(element: T): Long = {
// determine and return session gap
}
}))
.<window function>(...)
如上,固定大小的会话间隔可以通过Time.milliseconds(x),Time.seconds(x),Time.minutes(x)来指定,动态会话间隔通过实现SessionWindowTimeGapExtractor接口来指定。
注意:由于会话窗口没有固定的开始结束时间,它的计算方法与滚动窗口、滑动窗口有所不同。在一个会话窗口算子内部会为每一个接收到的元素创建一个新的窗口,如果这些元素之间的时间间隔小于定义的会话窗口间隔,则将阿门合并到一个窗口。为了能够进行窗口合并,我们需要为会话窗口定义一个Tigger函数和Window Function函数(例如ReduceFunction, AggregateFunction, or ProcessWindowFunction. FoldFunction不能用于合并)。
应用案例:
模拟案例:
这里数据源为:通过nc每秒发送一个数字1,如果10秒内没有收到数字,则视为会话断开,统计上个窗口里的所有数字1,拼接为一个字符串。
案例代码如下:
package com.lagou.window; import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector; /**
* @author doublexi
* @date 2021/10/30 14:19
* @description 基于会话的窗口
*/
public class WindowDemoSession {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> data = env.socketTextStream("linux121", 7777);
SingleOutputStreamOperator<String> maped = data.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
// 这里对数据基本没处理,原模原样传出
return value;
}
}); // 这里指定根据value自身来进行聚合
KeyedStream<String, String> keyByed = maped.keyBy(value -> value);
// 获取Session窗口
// 这里没有像TimeWindow类似的直接的api,要通过window方法指定窗口指派器的方式生成sessionWindow
// 这里是以当前事件处理时间为会话窗口开始时间,间隔为10s,形成一个Session窗口
WindowedStream<String, String, TimeWindow> sessionWindow = keyByed.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)));
// 第一个参数为输入数据的类型,第二个参数为输出数据的类型,第三个参数为key的数据类型,第四个参数为窗口类型,发现这里也是时间窗口
SingleOutputStreamOperator<String> applyed = sessionWindow.apply(new WindowFunction<String, String, String, TimeWindow>() {
@Override
public void apply(String s, TimeWindow window, Iterable<String> input, Collector<String> out) throws Exception {
StringBuilder sb = new StringBuilder();
for (String str : input) {
sb.append(str);
}
out.collect(sb.toString());
}
}); applyed.print();
env.execute();
}
}
启动nc:输入数据源
[root@linux121 ~]# nc -lp 7777
1
1
1
运行flink程序:
数据源输入完毕后,等待10s,也就是等待结束这次会话,然后就会看到SessionWindow触发执行了,打印结果,输出结果如下:
4> 111
如果在这个session gap内,也就是连续10秒,都没有接收到新元素,则会关闭上一个窗口,触发窗口计算。
2、CountWindow (计数窗口)
CountWindow是根据到来的元素的个数来生成窗口的。与时间无关。
CountWindow也分滚动窗口(Tumbling Window)和滑动窗口(Sliding Window)
这里是根据事件数量来划分的,所以也可以称为滚动计数窗口,和滑动计数窗口。
CountWindow没有像时间窗口那样丰富的api调用。
这里主要就是使用.countWindow()这一个api,根据参数的不同来设定不同的指派器。
2.1、Tumbling Window(滚动计数窗口)
滚动窗口的概念:
- 滚动窗口能将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口
- 滚动窗具有固定的尺寸,不重叠。
我们这里是基于元素数量来划分的。
滚动计数窗口的api:
// Stream of (userId, buyCnts)
val buyCnts: DataStream[(Int, Int)] = ... val tumblingCnts: DataStream[(Int, Int)] = buyCnts
// key stream by sensorId
.keyBy(0)
// tumbling count window of 100 elements size
.countWindow(100)
// compute the buyCnt sum
.sum(1)
适用场景:
当我们想要每100个用户购买行为事件统计购买总数,那么每当窗口中填满100个元素了,就会对窗口进行计算,这种窗口我们称之为翻滚计数窗口(Tumbling Count Window)
单词每出现三次统计一次,统计最近三次的数据?
应用案例:
这是一个模拟的案例。
输入数据源是通过nc进行输入数据的,通过socketTextStream监听nc的数据源。
nc上会输入一些数字,当接收到3个相同的数字之后,就会触发window关闭,开始window的计算。
这里的窗口函数主要是将窗口中的数据源进行拼接打印输出。
代码如下:
基于事件(数据源数量)的滚动计数窗口:
package com.lagou.window; import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.util.Collector; import java.text.SimpleDateFormat;
import java.util.Iterator;
import java.util.Random; /**
* @author doublexi
* @date 2021/10/30 13:36
* @description 基于事件(数据源数量)的滚动窗口
*/
public class WindowDemoCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> data = env.socketTextStream("linux121", 7777);
// 2、获取窗口
SingleOutputStreamOperator<Tuple3<String, String, String>> maped = data.map(new MapFunction<String, Tuple3<String, String, String>>() {
@Override
public Tuple3<String, String, String> map(String value) throws Exception {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
long l = System.currentTimeMillis();
String dataTime = sdf.format(l);
Random random = new Random();
int randomNum = random.nextInt(5);
return new Tuple3<>(value, dataTime, String.valueOf(randomNum));
}
});
// 为了增加并行度,进行keyBy聚合操作,相同key数据会进入同一个分区,给同一个subtask任务
KeyedStream<Tuple3<String, String, String>, String> keyByed = maped.keyBy(value -> value.f0);
// 根据事件数量去划分窗口,每3个数据源划分为一个窗口
WindowedStream<Tuple3<String, String, String>, String, GlobalWindow> countWindow = keyByed.countWindow(3); // 3、操作窗口数据
// 第一个参数Tuple3是窗口输入进来的数据类型,第二个参数Object是输出的数据类型,第三个参数String是数据源中key的数据类型,第四个参数指明当前处理的窗口是什么类型的窗口,这里是GlobalWindow
// 这里的GlobalWindow没有太多的操作接口,无法获取window相关信息,所以我们就不拿了
SingleOutputStreamOperator<String> applyed = countWindow.apply(new WindowFunction<Tuple3<String, String, String>, String, String, GlobalWindow>() {
@Override
public void apply(String s, GlobalWindow window, Iterable<Tuple3<String, String, String>> input, Collector<String> out) throws Exception {
Iterator<Tuple3<String, String, String>> iterator = input.iterator();
StringBuilder sb = new StringBuilder();
while (iterator.hasNext()) {
Tuple3<String, String, String> next = iterator.next();
sb.append(next.f0 + ".." + next.f1 + ".." + next.f2);
}
out.collect(sb.toString());
}
}); applyed.print();
env.execute();
}
}
启动nc:
[root@linux121 ~]# nc -lp 7777
运行程序,观察输出:
在nc上输入数据
[root@linux121 ~]# nc -lp 7777
1
2
3
4
5
6
1
1
程序输出结果:
4> 1..2021-10-30 13:50:19.178..11..2021-10-30 13:50:28.126..31..2021-10-30 13:50:28.729..2
我们发现输入123456后,都没有输出,直到遇上了第三个1,才有一个输出结果。那是因为这是根据事件的滚动窗口,我们上面设置了3个数据源才会划分一个窗口。
上面的keyBy是将相同的key的数据源交给同一个任务槽去执行。
窗口机制里调用了这个keyBy,相同的key就会调用到相同的槽,同一个槽里又进行了countWindow操作,就是在这一个槽里开启了窗口。
因为进行了keyBy分组,就会把123456分发到不同的任务槽里,每一个数字都处于单独的任务槽。
1任务槽里感知到了有3个数据源后,3个1,就会去触发执行window里的操作,就会打印。
2.2、Sliding Window(滑动计数窗口)
滑动窗口的概念:
因为我们这里考虑的是基于元素的数量来进行滑动窗口划分。
概念:
滑动窗口也是一种比较常见的窗口类型,其特点是在滚动窗口基础之上增加了窗口滑动间隔(Slide size),且允许窗口数据发生重叠。
当 Windows size 固定之后,窗口并不像滚动窗口按照 Windows Size 向前移动,而是根据设定的 Slide size 向前滑动。
窗口之间的数据重叠大小根据 Windows size 和 Slide size 决定,
- 当 Slide size 小于 Windows size便会发生窗口重叠,
- Slide size 大于 Windows size 就会出现窗口不连续,数据可能不能在任何一个窗口内计算,
- Slide size 和 Windows size 相等时,Sliding Windows 其实就是Tumbling Windows。
如下图:
滑动计数窗口的适用场景:(关键词:最近)
例如计算每10个元素计算一次最近100个元素的总和,
每隔5s计算一下最近10s的数据
滑动计数窗口的api:
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// sliding count window of 100 elements size and 10 elements trigger interval
.countWindow(100, 10)
.sum(1)
应用案例:
基于事件的滑动计数窗口:
也很简单,在之前滚动计数窗口代码的基础上稍加改动即可。
# 根据事件源数量来设置窗口,这里设置步长为1
keyByed.countWindow(3, 1);
开启一个nc:
[root@linux121 ~]# nc -lp 7777
1
1
1
1
启动程序,查看运行结果:
4> 1..2021-10-30 14:14:25.243..2
4> 1..2021-10-30 14:14:25.243..21..2021-10-30 14:14:26.547..3
4> 1..2021-10-30 14:14:25.243..21..2021-10-30 14:14:26.547..31..2021-10-30 14:14:27.956..1
4> 1..2021-10-30 14:14:26.547..31..2021-10-30 14:14:27.956..11..2021-10-30 14:14:29.364..4
这里我们发现,每输入一个1就会输出一条数据,
因为它的步长为1,来一个元素后就会向右滑动,形成一个新的窗口。
3、GlobalWindows (全局窗口)
概念介绍:
全局窗口分配器会将具有相同key值的所有元素分配在同一个窗口。这种窗口模式下需要我们设置一个自定义的Trigger,否则将不会执行任何计算,这是因为全局窗口中没有一个可以处理聚合元素的自然末端。所有相同keyed的元素分配到一个窗口里,这种窗口很少使用。

适用场景:
全局窗口的应用场景几乎是没有的。
全局窗口的api调用:
val input: DataStream[T] = ... input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>)
应用案例:
引用自:https://blog.csdn.net/weixin_45764675/article/details/104818931
package com.baizhi.jsy.windowProcessTime
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.assigners.{GlobalWindows, ProcessingTimeSessionWindows, SlidingProcessingTimeWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger
import org.apache.flink.streaming.api.windowing.windows.{GlobalWindow, TimeWindow}
import org.apache.flink.util.Collector
object FlinkWindowProcessGlobal {
def main(args: Array[String]): Unit = {
//1.创建流计算执⾏行行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream - 细化
val text = env.socketTextStream("Centos",9999)
//3.执⾏行行DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(word=>(word._1))
.window(GlobalWindows.create())
.trigger(CountTrigger.of(4))
.apply(new UserDefineGlobalWindowFunction)
.print()
//5.执⾏行行流计算任务
env.execute("Tumbling Window Stream WordCount")
}
}
class UserDefineGlobalWindowFunction extends WindowFunction[(String,Int),(String,Int),String,GlobalWindow]{
override def apply(key: String,
window: GlobalWindow,
input: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val sum = input.map(_._2).sum
out.collect((s"${key}",sum))
}
}
输出结果:
GlobalWindow与GlobalWindows的区别:
注意:直接使用GlobalWindows指派器的场景很少,几乎没有。但是我们却经常在窗口实现函数里看到GlobalWindow。经常容易看混淆。注意,它们是不一样的。
GlobalWindow是一种窗口类型,GlobalWindows是一种窗口指派器。
GlobalWindow:
首先,GlobalWindow继承自Window,它是一种窗口类型。
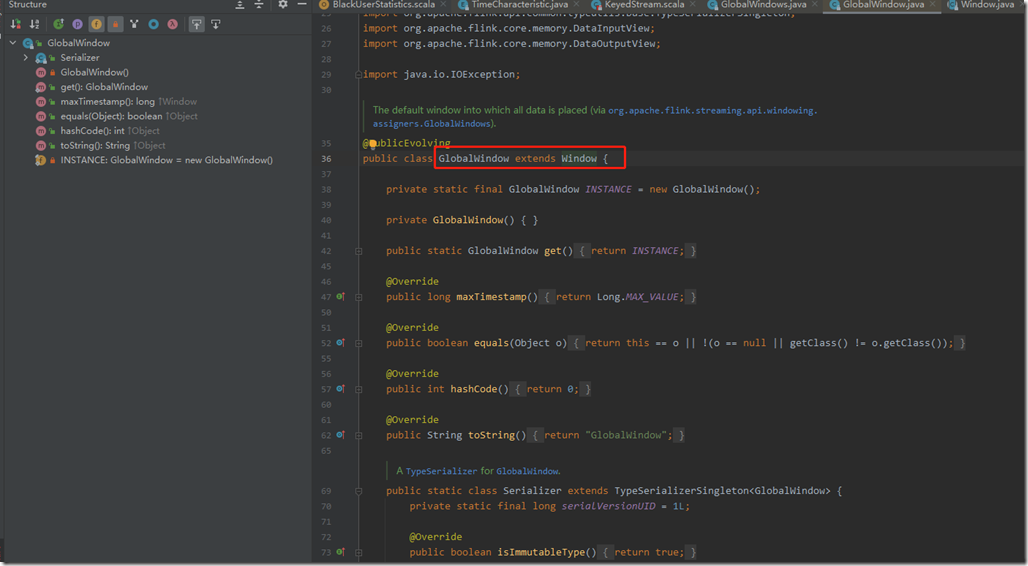
同样继承自Window的有GlobalWindow和TimeWindow

GlobalWindow与TimeWindow它们都继承了父类的maxTimeStamp()方法。
它的maxTimestamp方法与TimeWindow不同,TimeWindow有start和end属性,其maxTimestamp方法返回的是end-1;而GlobalWindow的maxTimestamp方法返回的是Long.MAX_VALUE;GlobalWindow定义了自己的Serializer
GlobalWindows
GlobalWindows是一种窗口指派器。
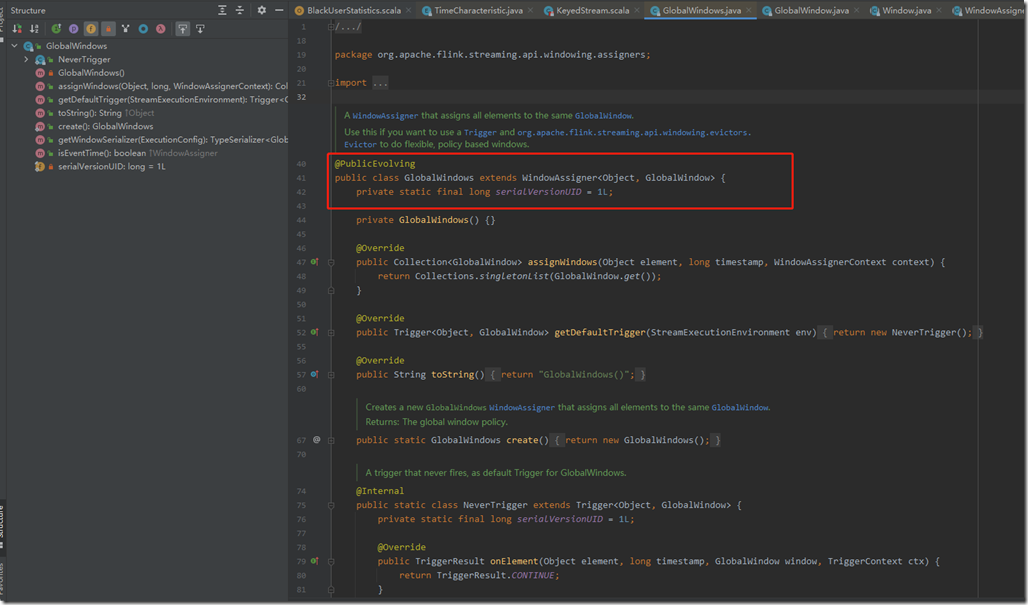
- GlobalWindows继承了WindowAssigner,key类型为Object,窗口类型为GlobalWindow
- GlobalWindows的assignWindows方法返回的是GlobalWindow;getDefaultTrigger方法返回的是NeverTrigger;getWindowSerializer返回的是GlobalWindow.Serializer();isEventTime返回的为false
- NeverTrigger继承了Trigger,其onElement、onProcessingTime、onProcessingTime返回的TriggerResult均为TriggerResult.CONTINUE;该行为就是不做任何触发操作;如果需要触发操作,则需要在定义window操作时设置自定义的trigger,覆盖GlobalWindows默认的NeverTrigger
4、Non-keyed Window
当你的stream过来之后,第一件事需要明确的是你的stream需要keyed或者不需要。这个必须要窗口定义前确定。使用keyBy(...)将会把你的无尽的stream切割成逻辑的keyed stream。比如 keyBy(...)没有被调用,你的stream将不会keyed。
在已经keyed stream中,你写进来的事件任意属性attribute可以使用key。由于使用了keyed stream可以允许你的windowd 计算在并行的多任务的模式下运行,每一个逻辑的keyed stream可以相互独立的运行而相互没有影响。所有具有相同key的元素会被发射到相同的并行任务上执行。
如果在non-keyed streams中,你原有的stream不会分割成不同的逻辑stream并且所有的window逻辑只会执行在一个单独的任务上使用并发度为1。(也就说所有的数据会汇总到一个task上执行)
对于KeyedStream,我们直接按照上面1、2、3的方式去调用api就可以了。
注意:
1、Non-keyed Stream都有windowAll()窗口函数
当一个dataStream经过keyBy()之后,就会形成一个KeyedStream,keyedStream后面可以接着调用窗口等函数。api类似如下:
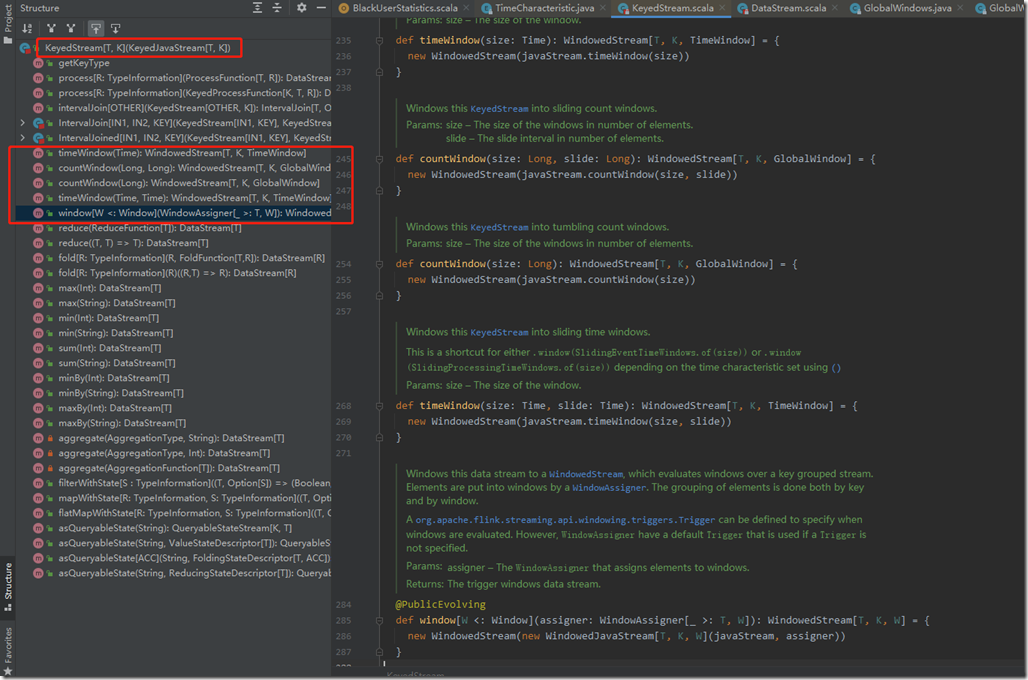
里面就是我们上面1、2、3的方式去使用窗口指派器。
如果dataStream没有经过keyBy(),就是Non-keyed Stream,就是原生的dataStream的话,其实它也可以调用窗口函数。api如下:
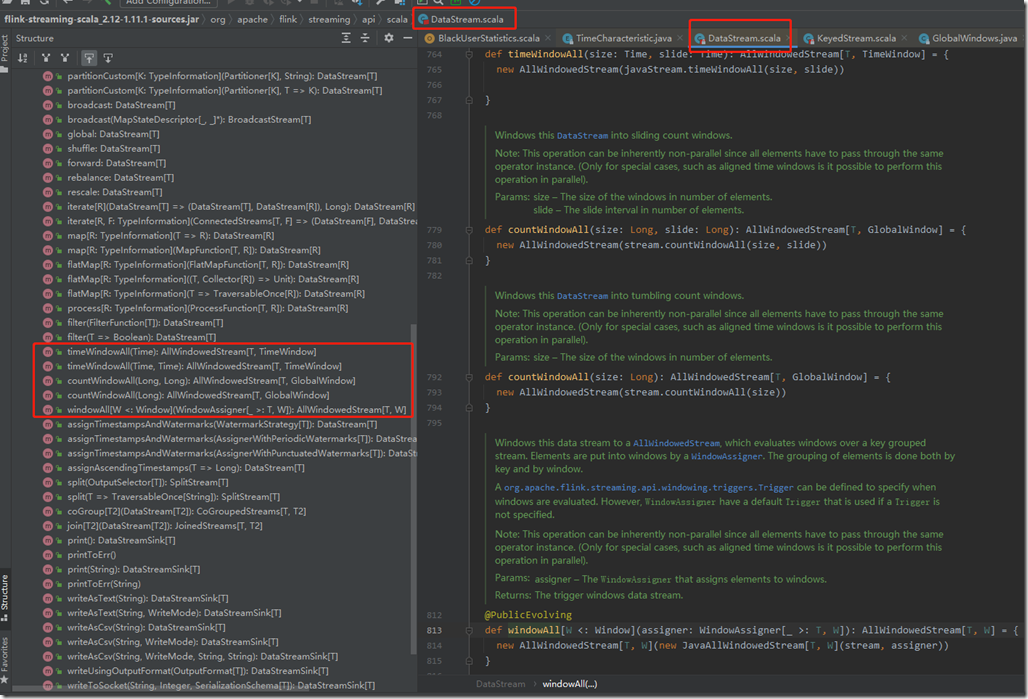
我们发现Non-keyed Stream相比keyed Stream,Window Assigner的调用方式上,只是多了个All。
因为KeyedStream是并行任务,根据key的不同,会有不同的task在并行执行。
相同的key的元素会划分到同一个task上执行。
而Non-keyed Stream不会划分,只有一个单独的任务,并行度为1,所有的数据会汇总到一个task上执行,所以Non-keyed Stream的窗口api都是带All的,因为它们要处理所有的数据元素。
注意:这里和KeyedStream后的GlobalWindow是不一样的,前者是对分完区后,同一个task上的数据的global。而后者Non-keyed Stream是不分区的,针对所有的元素。
2、Non-keyed Stream也可以划分为滚动窗口、滑动窗口。
Non-keyed Stream上也有timeWindowAll、countWindowAll、windowAll的方法调用。
它们也可以实现滚动时间窗口、滑动时间窗口、滚动计数窗口、滑动计数窗口,以及自己指定窗口指派器。不同的是,它是非并行的,所有的元素都会经过同一个算子。
源码如下:
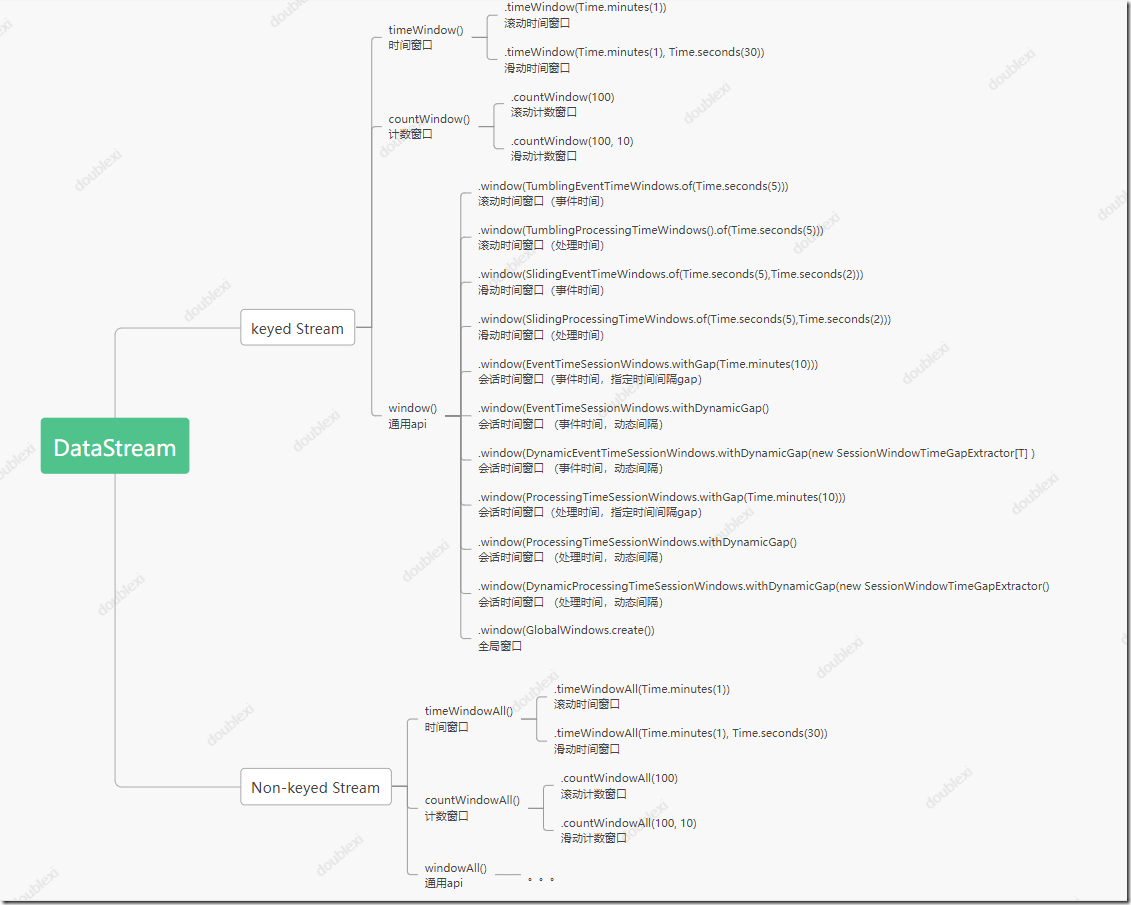
窗口指派器总结如下图:
参考引用:
官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/operators/windows/
https://segmentfault.com/a/1190000022106275
https://blog.csdn.net/qq_28680977/article/details/113531672
Flink的窗口处理机制(一)的更多相关文章
- Flink(八)【Flink的窗口机制】
目录 Flink的窗口机制 1.窗口概述 2.窗口分类 基于时间的窗口 滚动窗口(Tumbling Windows) 滑动窗口(Sliding Windows) 会话窗口(Session Window ...
- 第六篇 ANDROID窗口系统机制之显示机制
第六篇 ANDROID窗口系统机制之显示机制 ANDROID的显示系统是整个框架中最复杂的系统之一,涉及包括窗口管理服务.VIEW视图系统.SurfaceFlinger本地服务.硬件加速等.窗口管理服 ...
- uCGUI 按键窗口切换机制(更新篇)
在之前文章中,讲述了一个低内存使用量的的窗口切换机制.有人会问,低内存使用量是多低呢,我这里举个例子.我有一个项目中使用到本切换机制,128*64的单色屏,初步计算有105个窗口(后面还会增加),总内 ...
- sentinel 滑动窗口统计机制
sentinel的滑动窗口统计机制就是根据当前时间,获取对应的时间窗口,并更新该时间窗口中的各项统计指标(pass/block/rt等),这些指标被用来进行后续判断,比如限流.降级等:随着时间的推移, ...
- Flink会话窗口测试
Flink会话窗口测试 一.测试结论: 1.会话窗口的间隔时间和水位线作用一样,表示输出现在时间 - 间隔时间之前所有未结算时间的数据,作用类似于水位线,但是和水位线开闭不一样. 2.会话窗口显示的数 ...
- Win32窗口消息机制 x Android消息机制 x 异步执行
如果你开发过Win32窗口程序,那么当你看到android代码到处都有的mHandler.sendEmptyMessage和 private final Handler mHandler = new ...
- 【源码解析】Flink 滑动窗口数据分配到多个窗口
之前一直用翻滚窗口,每条数据都只属于一个窗口,所有不需要考虑数据需要在多个窗口存的事情. 刚好有个需求,要用到滑动窗口,来翻翻 flink 在滑动窗口中,数据是怎么分配到多个窗口的 一段简单的测试代码 ...
- Flink Window窗口机制
总览 Window 是flink处理无限流的核心,Windows将流拆分为有限大小的"桶",我们可以在其上应用计算. Flink 认为 Batch 是 Streaming 的一个特 ...
- 关于 Flink 状态与容错机制
Flink 作为新一代基于事件流的.真正意义上的流批一体的大数据处理引擎,正在逐渐得到广大开发者们的青睐.就从我自身的视角看,最近也是在数据团队把一些原本由 Flume.SparkStreaming. ...
随机推荐
- Go IF 条件语句
条件语句需要开发者通过指定一个或多个条件,并通过测试条件是否为 true 来决定是否执行指定语句,并在条件为 false 的情况在执行另外的语句. 以下是在大多数编程语言中发现的典型条件语句的一般形式 ...
- 洛谷 P6783 - [Ynoi2008] rrusq(KDT+势能均摊+根号平衡)
洛谷题面传送门 首先显然原问题严格强于区间数颜色,因此考虑将询问离线下来然后用某些根号级别复杂度的数据结构.按照数颜色题目的套路,我们肯定要对于每种颜色维护一个前驱 \(pre\),那么答案可写作 \ ...
- 洛谷 P5470 - [NOI2019] 序列(反悔贪心)
洛谷题面传送门 好几天没写题解了,写篇题解意思一下(大雾 考虑反悔贪心,首先我们考虑取出 \(a,b\) 序列中最大的 \(k\) 个数,但这样并不一定满足交集 \(\ge L\) 的限制,因此我们需 ...
- 流量限制器(Flux Limiter)
内容翻译自Wikipedia Flux limiter 流量限制器(Flux limiters)应用在高精度格式中-这种数值方法用来求解科学与工程问题,特别是由偏微分方程(PDE's)描述的流体动力学 ...
- 【R绘图】R 基础(base )低级函数legend绘图?
ggplot虽然好用,但base才是真正的瑞士军刀,什么都能用,各种自定义图形自由组合,出版级图片用base才是王道.但要达到随心所欲,需要熟练掌握. legend是比较重要的低级函数,有很多细节处理 ...
- “equals”有值 与 “==”存在 “equals”只是比较值是否相同,值传递,==地址传递,null==a,避免引发空指针异常,STRING是一个对象==null,对象不存在,str.equals("")对象存在但是包含字符‘''
原文链接:http://www.cnblogs.com/lezhou2014/p/3955536.html "equals" 与 "==" "equa ...
- C#数字验证
using System; using System.Collections; using System.Configuration; using System.Data; using System. ...
- 巩固javaweb的第二十五天
常用的验证 1. 非空验证 // 验证是否是空 function isNull(str) { if(str.length==0) return true; else return false; } 2 ...
- Java交换数组元素
Java 交换数组元素 代码示例 import java.util.Arrays; import java.util.Collections; import java.util.List; impor ...
- 一起手写吧!call、apply、bind!
apply,call,bind都是js给函数内置的一些api,调用他们可以为函数指定this的执行,同时也可以传参. call call 接收多个参数,第一个为函数上下文也就是this,后边参数为函数 ...