Python+Requests+Re(正则)爬取某糗事百科图片(数据分析一)
1、博客目前在学习爬虫课程,使用正则表达式来爬取网页的图片信息
2、下面我们一起来回归下Python中的正则使用方式/方法
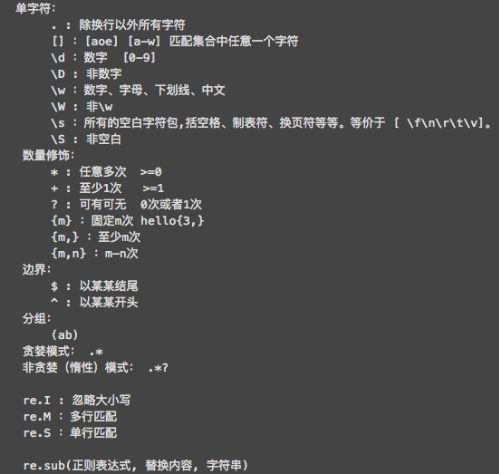
3、糗事百科图片爬取源码如下:
import requests
import re
import os
if __name__ == '__main__':
# headers请求头信息
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
# 新建文件夹用来存储糗事图片
if not os.path.exists('./qiushiLibs'):
os.makedirs('./qiushiLibs')
# Url进行封装循环分页爬取
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
for page in range(1,2):
new_url = format(url%page)
# 调用get请求获取text字符串
page_source = requests.get(url=new_url,headers=headers).text
# 正则表达式:使用到非贪婪模式
ER = r'<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
# 返回list数组
img_src_list = re.findall(ER,page_source,re.S)
for src in img_src_list:
# 遍历拼接图片URL
src = 'https:'+src
# 下载图片新建请求
# 以二进制流的方式存储
img_content = requests.get(url=src,headers=headers).content
# print(img_content)
# 生成图片的名称
imgName = src.split('/')[-1]
# 图片路径
imgPath = './qiushiLibs/'+imgName
# 持久化存储
with open(imgPath,'wb') as fp:
fp.write(img_content)
print(imgName,'下载成功!!!')
Python+Requests+Re(正则)爬取某糗事百科图片(数据分析一)的更多相关文章
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
- [Python]网络爬虫(八):糗事百科的网络爬虫(v0.2)源码及解析
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8932310 项目内容: 用Python写的糗事百科的网络爬虫. 使用方法: 新建一个 ...
- python+正则+多进程爬取糗事百科图片
话不多说,直接上代码: # 需要的库 import requests import re import os from multiprocessing import Pool # 请求头 header ...
- python requests库网页爬取小实例:百度/360搜索关键词提交
百度/360搜索关键词提交全代码: #百度/360搜索关键词提交import requestskeyword='Python'try: #百度关键字 # kv={'wd':keyword} #360关 ...
- Python Requests库网络爬取全代码
#爬取京东商品全代码 import requestsurl = "http://item.jd.com/2967929.html"try: r = requests.get(url ...
- python requests库网页爬取小实例:亚马逊商品页面的爬取
由于直接通过requests.get()方法去爬取网页,它的头部信息的user-agent显示的是python-requests/2.21.0,所以亚马逊网站可能会拒绝访问.所以我们要更改访问的头部信 ...
- python Requests库网络爬取IP地址归属地的自动查询
#IP地址查询全代码import requestsurl = "http://m.ip138.com/ip.asp?ip="try: r = requests.get(url + ...
- python+BeautifulSoup+多进程爬取糗事百科图片
用到的库: import requests import os from bs4 import BeautifulSoup import time from multiprocessing impor ...
- 【Python】python3 正则爬取网页输出中文乱码解决
爬取网页时候print输出的时候有中文输出乱码 例如: \\xe4\\xb8\\xad\\xe5\\x8d\\x8e\\xe4\\xb9\\xa6\\xe5\\xb1\\x80 #爬取https:// ...
随机推荐
- 3D目标检测(CVPR2020:Lidar)
3D目标检测(CVPR2020:Lidar) LiDAR-Based Online 3D Video Object Detection With Graph-Based Message Passing ...
- Linux 2 的 Windows 子系统上发布 CUDA
Linux 2 的 Windows 子系统上发布 CUDA 为响应大众需求,微软 宣布 在 2020 年 5 月的 建造 大会上推出了 建造 ( WSL 2 ) – GPU 加速功能.这一特性为许多计 ...
- HashMap底层实现原理及面试常见问题
HashMap底层源码分析 1.HashMap底层采用的存储结构 1.在JDK1.7及之前采用的存储结构是数组+链表 2.到了JDK1.8之后采用的是数组+链表+红黑树 2.HashMap实现的原理 ...
- 1738. 找出第 K 大的异或坐标值
2021-05-19 LeetCode每日一题 链接:https://leetcode-cn.com/problems/find-kth-largest-xor-coordinate-value/ 标 ...
- 重新整理 .net core 实践篇—————中间件[十九]
前言 简单介绍一下.net core的中间件. 正文 官方文档已经给出了中间件的概念图: 和其密切相关的是下面这两个东西: IApplicationBuilder 和 RequestDelegate( ...
- C# Net Core 使用 itextsharp.lgplv2.core 把Html转PDF
C# Net Core 使用 itextsharp.lgplv2.core 把Html转PDF 只支持英文(中文我不知道怎么弄,懂的朋友帮我看一下)!!!!![补充:评论区的小伙伴已解决] 引入包it ...
- CyclicBarrier 原理(秒懂)
疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 面试必备 + 面试必备 [博客园总入口 ] 疯狂创客圈 经典图书 : <Sprin ...
- 『无为则无心』Python基础 — 4、Python代码常用调试工具
目录 1.Python的交互模式 2.IDLE工具使用说明 3.Sublime3工具的安装与配置 (1)Sublime3的安装 (2)Sublime3的配置 4.使用Sublime编写并调试Pytho ...
- Kubernetes的资源管理
本节讲解为一个pod配置资源的预期使用量和最大使用量.通过设置这两组参数,可以确保pod公平地使用Kubernetes集群资源,同时也影响着整个集群pod的调度方式. 1.为pod中的容器申请资源 创 ...
- Redisson 分布式锁实现之源码篇 → 为什么推荐用 Redisson 客户端
开心一刻 一男人站在楼顶准备跳楼,楼下有个劝解员拿个喇叭准备劝解 劝解员:兄弟,别跳 跳楼人:我不想活了 劝解员:你想想你媳妇 跳楼人:媳妇跟人跑了 劝解员:你还有兄弟 跳楼人:就是跟我兄弟跑的 劝解 ...