Normalized Cuts and Image Segmentation
Shi J. and Malik J. Normalized cuts and image segmentation. In IEEE Transactions on Pattern Analysis and Machine Intelligence.
概
在Digital Image Preprocessing的书上看到了这个算法, 对于其公式结果的推出不是很理解, 于是下载下来看了看. 本文主要讲的是一种利用图结构进行图像分割的算法.
主要内容
假设\(f(x, y), x=1,2,\cdots M, y=1,2,\cdots N\)为一张图片, 我们想要对其进行分割. 给定某一个距离函数, 可以用于衡量任意两点\(i, j\)的相似度:
\]
把图片的每一个pixel看成一个节点, pixel和pixel之间的边为一条无向边, 则整体构成了一个无向的图 \(G = (V, E)\), 每条边的权重如上所述是\(w_{ij}\), 故易知\(w_{ij} = w_{ji}\). 我们的目标是将图分成相斥的两块\(A, B\), 即满足:
\]
以往的做法是, 找到一个分割, 使得下列指标最小:
\]
但是这种策略往往会导致不均匀的分割, 即最角落里的元素被单独分割出来:
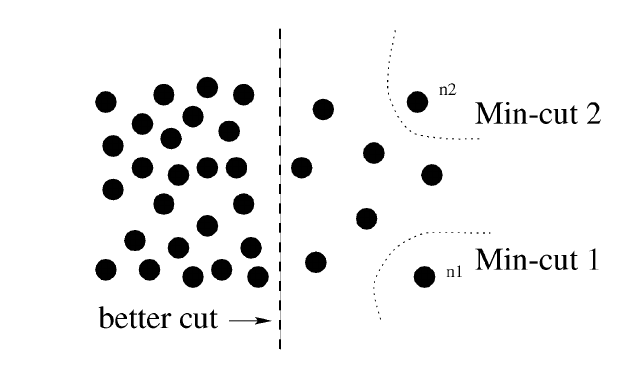
于是作者提出了一种新的指标:
\]
其中\(assoc(A, V) = \sum_{i \in A, j \in V} w_{ij}\).
注意到:
\]
所以只有到\(assoc(A, A), assoc(B, B)\)都足够大的时候Ncut才会足够小, 这说明该指标更关注了内部的一种紧密性.
求解
令
d_i = \sum_{j}w_{ij}.
\]
则
+\frac{\sum_{x_i < 0, x_i > 0} -w_{ij}x_i x_j}{\sum_{x_i < 0}d_i}.
\]
容易证明(但是不容易想到):
[\frac{1+x}{2}]_i = 0, \: \text{if } i \in B.
\]
[\frac{1-x}{2}]_i = 0, \: \text{if } i \in A.
\]
令
D_{ii} = d_i,
\]
且\(D_{ii}\)为对角矩阵.
所以我们能够证明以下事实:
4 \cdot assoc(A, V) = 2\cdot (1 + x)^T D 1 = (1 + x)^T D (1 + x) \\
4 \cdot assoc(B, V) = 2\cdot (1 - x)^T D 1 = (1 - x)^T D (1 - x) \\
assoc(V, V) = \sum_i d_i = 1^T D 1 \\
(1 + x)^T D (1 - x) = 0.
\]
又注意到:
\]
于是同理可证:
\]
令
\]
则
\]
综上可得:
\]
又
&[(1 + x) - b(1-x)]^T (D-W)[(1+x) - b(1-x)] \\
=& (1+x)^T(D-W)(1+x) + b^2 (1-x)^T(D-W) \\
&- 2b (1+x)^T(D-W)(1-x) \\
=&4(1+b^2)cut(A, B) - 2b (1 + x)^TD(1-x) + 2b(1 + x)^T W(1-x) \\
=&4(1+b^2)cut(A, B) - 0 + 8b cut(A, B) \\
=&4(1 + b)^2 cut(A, B).
\end{array}
\]
又
\]
故
b = \frac{k}{1-k}.
\]
令\(y = (1 + x) - b(1 - x)\), 且
\]
\]
故
\mathrm{s.t.} \quad y_i \in \{1, 1 - b\}.
\]
倘若我们能放松条件至实数域中, 此时只需要通过求解下列系统:
\]
需要注意的是:
\]
此时\(z_0 = D^{\frac{1}{2}}1\),
故\(1\)实际上上述系统的一个解, 且对应最小的特征值, 但其不是我们所要的解. 因为\(y\)必须要还满足:
\]
这意味着, 我们要的恰恰是
\]
的倒数第二小的特征值对应的特征向量\(z_1\), 于是\(y_1 = D^{-\frac{1}{2}}z_1\).
相似度
文中采用如下的计算方式:
\left \{
\begin{array}{ll}
e^{-\|F_i - F_j\|^2 / \sigma^2_I} \cdot e^{-\|X_i - X_j\|^2 / \sigma^2_X} & \text{if } \|X_i - X_j\| < r \\
0 & \text{else}.
\end{array}
\right.
\]
其中\(F\)对应颜色之类的距离, 如直接取密度值, 而\(X\)对应空间距离, \(r\)限定了搜索范围, 同样会导致\(W\)变成系数矩阵, 对应特征求解加速有帮助.
总的算法流程
- 计算权重矩阵\(W\)以及\(D\);
- 通过
\[D^{-\frac{1}{2}}(D-W)D^{-\frac{1}{2}} z = \lambda z
\]计算得到倒数第二小的特征值所对应的特征向量\(z_1\)并令\(y_1=z_1\);
- 通过某种方法(如网格搜索)找到一个阈值\(t\):
\[x_i = 1, \: \text{if }y_i > t, \: \text{else } -1.
\]且\(x\)的划分下
\[Ncut(A, B)
\]较小.
- 对于\(A, B\)可以重复上述分割过程, 直到满足区域数目或者其它某种条件(比如文中说的特征向量的分布过于均匀时停止).
skimage.future.graph.cut
Normalized Cuts and Image Segmentation的更多相关文章
- {Reship}{Code}{CV}
UIUC的Jia-Bin Huang同学收集了很多计算机视觉方面的代码,链接如下: https://netfiles.uiuc.edu/jbhuang1/www/resources/vision/in ...
- UIUC同学Jia-Bin Huang收集的计算机视觉代码合集
转自:http://blog.sina.com.cn/s/blog_631a4cc40100wrvz.html UIUC的Jia-Bin Huang同学收集了很多计算机视觉方面的代码,链接如下: ...
- 计算机视觉与模式识别代码合集第二版two
Topic Name Reference code Image Segmentation Segmentation by Minimum Code Length AY Yang, J. Wright, ...
- 谱聚类 Spectral Clustering
转自:http://www.cnblogs.com/wentingtu/archive/2011/12/22/2297426.html 如果说 K-means 和 GMM 这些聚类的方法是古代流行的算 ...
- CV code references
转:http://www.sigvc.org/bbs/thread-72-1-1.html 一.特征提取Feature Extraction: SIFT [1] [Demo program][SI ...
- [ZZ] UIUC同学Jia-Bin Huang收集的计算机视觉代码合集
UIUC同学Jia-Bin Huang收集的计算机视觉代码合集 http://blog.sina.com.cn/s/blog_4a1853330100zwgm.htmlv UIUC的Jia-Bin H ...
- Computer Vision Resources
Computer Vision Resources Softwares Topic Resources References Feature Extraction SIFT [1] [Demo pro ...
- 漫谈 Clustering (4): Spectral Clustering
转:http://blog.pluskid.org/?p=287 如果说 K-means 和 GMM 这些聚类的方法是古代流行的算法的话,那么这次要讲的 Spectral Clustering 就可以 ...
- CV codes代码分类整理合集 《转》
from:http://www.sigvc.org/bbs/thread-72-1-1.html 一.特征提取Feature Extraction: SIFT [1] [Demo program] ...
随机推荐
- nodeJs-querystring 模块
JavaScript 标准参考教程(alpha) 草稿二:Node.js querystring 模块 GitHub TOP querystring 模块 来自<JavaScript 标准参考教 ...
- RocketMQ集群搭建方式
各角色介绍 Producer:消息的发送者:举例:发信者 Consumer:消息接收者:举例:收信者 Broker:暂存和传输消息:举例:邮局 NameServer:管理Broker:举例:各个邮局的 ...
- Linux学习 - 文本编辑器Vim
一.Vim工作模式 二.命令 插入 a 光标后插入 A 光标所在行尾插入 i 光标前插入 I 光标所在行首插入 o 光标下插入新行 O 光标上插入新行 删除 x 删除光标处字符 nx 删除光标处后 ...
- tomcat 之 session 集群
官网地址 https://tomcat.apache.org/tomcat-8.5-doc/cluster-howto.html #:配置各tomcat节点 [root@node1 ~]# vim / ...
- When do we use Initializer List in C++?
Initializer List is used to initialize data members of a class. The list of members to be initialize ...
- Mybatis-Plus默认主键策略导致自动生成19位长度主键id的坑
原创/朱季谦 某天检查一位离职同事写的代码,发现其对应表虽然设置了AUTO_INCREMENT自增,但页面新增功能生成的数据主键id很诡异,长度达到了19位,且不是从1开始递增的-- 我检查了一下,发 ...
- ABP VNext框架基础知识介绍(2)--微服务的网关
ABP VNext框架如果不考虑在微服务上的应用,也就是开发单体应用解决方案,虽然也是模块化开发,但其集成使用的难度会降低一个层级,不过ABP VNext和ABP框架一样,基础内容都会设计很多内容,如 ...
- LET函数(Excel函数集团)
LET函数,是个Office365新增函数,所以,还在用上古版本的童鞋请无视此篇哈~ 话说Excel中,有个自定义名称的功能,如下图,左右两个表分别自定义了"data1"和&quo ...
- Java中List排序的3种方法
在某些特殊的场景下,我们需要在 Java 程序中对 List 集合进行排序操作.比如从第三方接口中获取所有用户的列表,但列表默认是以用户编号从小到大进行排序的,而我们的系统需要按照用户的年龄从大到小进 ...
- java 输入输出IO流 RandomAccessFile文件的任意文件指针位置地方来读写数据
RandomAccessFile的介绍: RandomAccessFile是Java输入输出流体系中功能最丰富的文件内容访问类,它提供了众多的方法来访问文件内容,它既可以读取文件内容,也可以向文件输出 ...