大型分布式C++框架《三:序列化与反序列化》
一、前言
个人感觉序列化简单来说就是按一定规则组包。反序列化就是按组包时的规则来接包。正常来说。序列化不会很难。不会很复杂。因为过于复杂的序列化协议会导致较长的解析时间,这可能会使得序列化和反序列化阶段成为整个系统的瓶颈。就像压缩文件、解压文件,会占用大量cpu时间。
二、分配序列化空间的大小
说序列化之前先说下平台给序列化分配的buf的空间大小
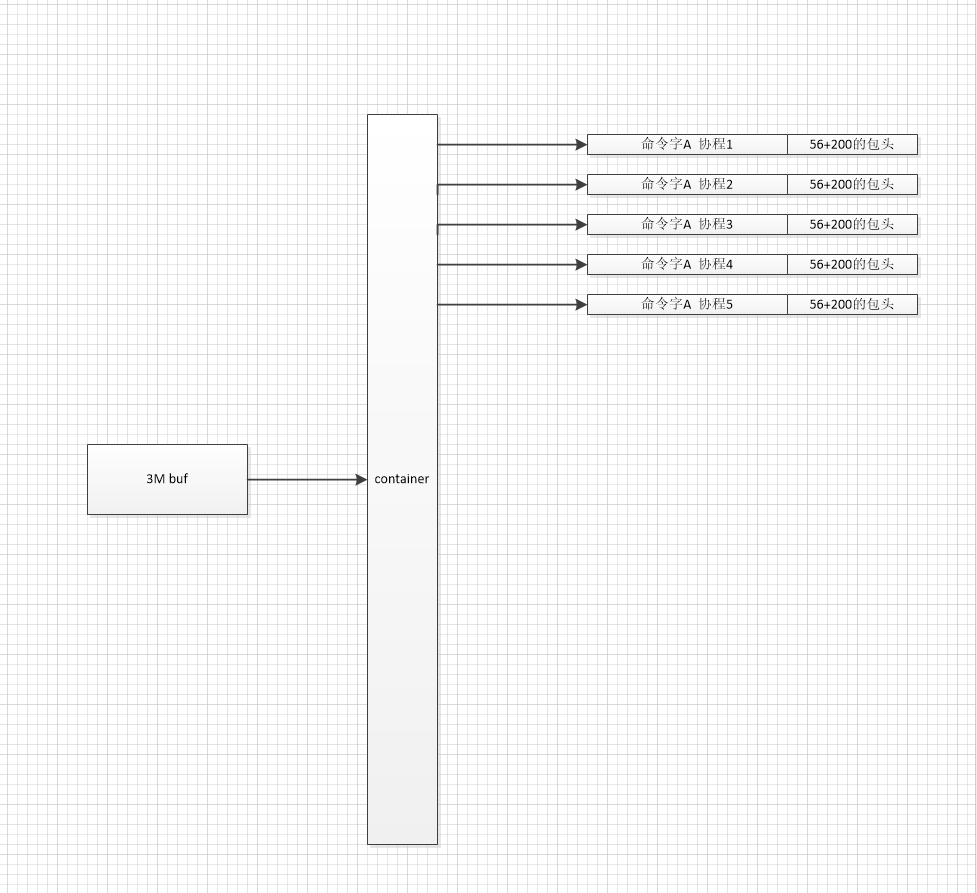
三、序列化步骤
1、我们先看下请求。
- oCntlInfo.setOperatorUin();
- oCntlInfo.setOperatorKey("abcde");
- oCntlInfo.setRouteKey();
- std::string source = "aaaaa";
- std::string inReserve;
- std::string errmsg;
- std::string outStr;
- std::string machineKey;
- for(int i =;i<*;i++)
- {
- machineKey.append("a");
- }
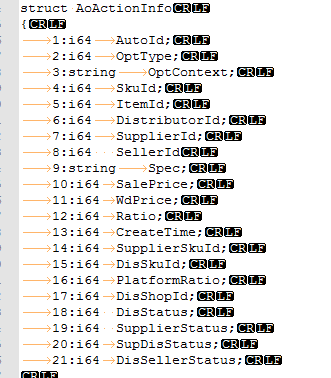
- AoActionInfo oActionInfo;
- oActionInfo.SetDisShopId();
- oActionInfo.SetDistributorId();
- uint32_t dwResult = Stub4App.AddActionSupplier(
- oCntlInfo,
- machineKey,
- source,
- ,
- ,
- oActionInfo,
- inReserve,
- errmsg,
- outStr);
- if(dwResult == )
- {
- std::cout << "Invoke OK!" << std::endl;
- std::cout << "Invoke OK!" << std::endl;
- }
客户端直接调用函数接口。到服务端请求结果
函数的入参都是我们需要序列化的内容。注意这里是rpc调用的一个关键点。
2、序列化开始
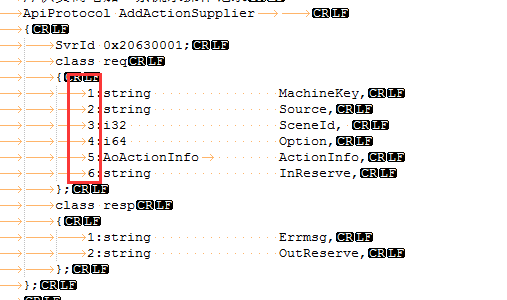
a) 先看下我们的thritf
如果下图。发现我们的函数入参也是打上了tag标志的。作用跟我们在结构体中打tag标志是一样的。为了标识一个字段的含义。
序列化的时候把这些tag序列化进去。 然后反序列化的时候靠这些tag来解析
b ) 先把图贴出来。按着图来讲更清晰些

CByteStream(char* pStreamBuf = NULL, uint32_t nBufLen = 0,bool bStore=true, bool bRealWrite = true);
- )int32_t* pLen = (int32_t*)bs.getRawBufCur();
- )bs << ;
- )int32_t iLen=bs.getWrittenLength();
- )Serialize_w(bs);
- )*pLen = bs.getWrittenLength() - iLen;
f)最后对整个_Cao_action_AddActionSupplier_Req写了两个字节的包尾
其实我们可以看到我们的这种序列化,很整齐。很规则。比较紧凑。但是并不节省空间。这个里面有很多数据可以压缩的。但是压缩带来一个问题就是解压的时候很消耗cpu的。跟我的业务场景不服和。也没必要。
四、序列化解析
其实知道了数据是怎么写入的 解析起来就很容易了。其实这种序列化就是两边约定规则。知道规则以后就可以解析了
解析的具体步骤就不详细说了。这里说下解析的时候几个特殊的地方
五、话外
我们的这一套就是远程调用rpc服务。通过我们的序列化。
其实就能了解所谓的RPC服务是什么样的。
说白了,远程调用就是将对象名、函数名、参数等传递给远程服务器,服务器将处理结果返回给客户端。
为了能解析出这些信息。在入参的时候做上标识(这里是打tag).
谷歌的protobuf也用过。跟thrift其实差不多但是序列化和反序列的话的具体实现是有些不同的。
谷歌的protobuf更节省空间
以前具体看过序列化的源码。觉得序列化反序列化以及rpc很神秘。现在看了源码才发现确实写的确实好,
但是没那么神秘里。其实就是按一定规则组包。所以还是要多看源码啊。
我们用的thrift就是 facebook的thrift。但是改了些东西。大体是一样的。
大型分布式C++框架《三:序列化与反序列化》的更多相关文章
- Storm分布式实时流计算框架相关技术总结
Storm分布式实时流计算框架相关技术总结 Storm作为一个开源的分布式实时流计算框架,其内部实现使用了一些常用的技术,这里是对这些技术及其在Storm中作用的概括介绍.以此为基础,后续再深入了解S ...
- 开源分享 Unity3d客户端与C#分布式服务端游戏框架
很久之前,在博客园写了一篇文章,<分布式网游server的一些想法语言和平台的选择>,当时就有了用C#做网游服务端的想法.写了个Unity3d客户端分布式服务端框架,最近发布了1.0版本, ...
- Django准备知识-web应用、http协议、web框架、Django简介
一.web应用 Web应用程序是一种可以通过web访问的应用程序(web应用本质是基于socket实现的应用程序),程序的最大好处是用户很容易访问应用程序,用户只需要有浏览器即可,不需要再安装其他软件 ...
- Unity 游戏框架搭建 2018 (一) 架构、框架与 QFramework 简介
约定 还记得上版本的第二十四篇的约定嘛?现在出来履行啦~ 为什么要重制? 之前写的专栏都是按照心情写的,在最初的时候笔者什么都不懂,而且文章的发布是按照很随性的一个顺序.结果就是说,大家都看完了,都还 ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎
Python分布式爬虫必学框架Scrapy打造搜索引擎 部分课程截图: 点击链接或搜索QQ号直接加群获取其它资料: 链接:https://pan.baidu.com/s/1-wHr4dTAxfd51M ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌
Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌ (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 第1章 课程介绍 介绍课程目标.通过课程能学习到 ...
- Django框架-目录文件简介
Rhel6.5 Django1.10 Python3.5 Django框架-目录文件简介 1.介绍Django Django:一个可以使Web开发工作愉快并且高效的Web开发框架. 使用Django, ...
- Net框架下-ORM框架LLBLGen的简介
>对于应用程序行业领域来说,涉及到Net框架的,在众多支持大型项目的商用ORM框架中,使用最多的目前了解的主要有三款: 1.NHibernate(从Java版移植来的Net版). 2.微软的EF ...
- Unity3d&C#分布式游戏服务器ET框架介绍-组件式设计
前几天写了<开源分享 Unity3d客户端与C#分布式服务端游戏框架>,受到很多人关注,QQ群几天就加了80多个人.开源这个框架的主要目的也是分享自己设计ET的一些想法,所以我准备写一系列 ...
- asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程
最近在学习张善友老师的NanoFabric 框架的时了解到Exceptionless : https://exceptionless.com/ !因此学习了一下这个开源框架!下面对Exceptionl ...
随机推荐
- Thinkpad Edge E440 Ubuntu14.04 无线网卡驱动 解决
http://ubuntuforums.org/showthread.php?t=2190347 正文: Thinkpad Edge E440 安装 Ubuntu12.04 后 无法使用无线网卡, 须 ...
- 配置VSFTP服务器
一.Linux FTP服务器分类: <1>wu-ftp <2>proftp=profession ftp <3>vsftp=very security ftp ...
- 国内使用google地图的初级使用
<!DOCTYPE html><html><head><title>Simple Map</title><meta name=&quo ...
- SharePoint中获取当前登录的用户名几种方式
第一种方法: System.Web.HttpContext.Current.User.Identity.Name.ToString();或者: SPContext.Current.Site.OpenW ...
- (转)asp.net 使用cookie完成记住密码自动登录
代码如下 复制代码 string username = this.txtUserName.Text;//用户名 string password = this.txtPassword.T ...
- linux下查看已经安装的jdk 并卸载jdk
一.查看Jdk的安装路径: whereis javawhich java (java执行路径)echo $JAVA_HOME echo $PATH 备注:如果是windows中,可以使用: set j ...
- mssql定时执行作业。
---2000 企业管理器 --管理 --SQL Server代理 --右键作业 --新建作业 --"常规"项中输入作业名称 --"步骤"项 --新建 --&q ...
- Oracle 错误码
Oracle作为一款比较优秀同时也比较难以掌握的大型数据库,在我们学习使用的过程中,不可避免的会遇到一些错误,为此 Oracle 给出了一套完备的错误消息提示机制 我们可以根据Oracle给出的消息提 ...
- uva 10154 贪心+dp
题目链接:https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem ...
- CRT内存调试标记
static unsigned char _bNoMansLandFill = 0xFD; /* fill no-man's land with this */ static unsigned cha ...