KMP算法的一次理解
1. 引言
在一个大的字符串中对一个小的子串进行定位称为字符串的模式匹配,这应该算是字符串中最重要的一个操作之一了。KMP本身不复杂,但网上绝大部分的文章把它讲混乱了。下面,咱们从暴力匹配算法讲起,随后阐述KMP的流程步骤、next 数组的简单求解、递推原理、代码求解,接着基于next 数组匹配,谈到有限状态自动机,next 数组的优化,KMP的时间复杂度分析,最后简要介绍两个KMP的扩展算法。
2. 暴力匹配算法
2.1 问题描述:
有一个文本串s和一个模式串p,现在要查找p在s中的位置,怎么查找?
如果用暴力匹配的思路,并假设文本串匹配到i位置,模式串匹配到j位置。
2.2 算法描述:
有关字符串的模式匹配,首先来看最简单的一个算法,那就是暴力法。具体的算法描述:
(1)初始化i指向主串的初始位置,这里假设是主串的0位置;j指向子串的0位置。
(2)若当前字符匹配成功,也就是s[i] == p[j],则i++,j++,继续匹配下一个字符串。
(3)如果匹配不成功,也就是s[i] != p[j],则i = i-j+1,j=0。相当于每次匹配失败时,i回溯,j重置为0。
提示:
在不成功匹配的时候,i是本次匹配后主串的指针,那么较匹配开始前的位置移动的量为j。所以i-j是本次匹配的起始位置。+1代表向后移动一个位置。
2.3 暴力算法实现:
//返回子串p在主串s中的位置,如果不存在就返回-1
int ViolentMatch(char *s, char *p)
{
int i = 0;
int j = 0;
int sLen = strlen(s);
int pLen = strlen(p); while(i < sLen && j < pLen)
{
if(s[i] == p[j])
{
++i;
++j;
}
else
{
i = i - j + 1;//j代表这一次移动的次数,i-j表示s串的本次的起始位置,+1表示前进一个位置
j = 0;
}
}//while if(j == pLen)
{
return i - pLen ;
}
else
{
return -1;
}
}
这种暴力的匹配算法的时间复杂度在最坏的情况下为O[(n-m+1)*m],其中n为主串的长度,m为模式串的长度。可以看出算法的时间复杂度很大,显然我们不需要这样的算法,因为它很烂。但是这是我们设计其它算法的基础。
3. KMP算法前分析
在开始KMP算法之前,先来回顾一下字符串模式匹配的暴力法,具体的过程如下图所示:

注:图中两个串的匹配都是从1开始的,代码中的匹配都是从0开始的。
可以看到匹配主串的i的值是不断的回溯的,然而KMP三位大师发现这种回溯其实是不需要的。这种算法就是本文的主旨KMP算法,它利用之前已经部分匹配这个有效信息,保持i 不回溯,通过修改j 的位置,让模式串尽量地移动到有效的位置。
既然i值不能回溯了,也就是不能变小了,那么要考虑变化的就是j值了。为了能说清楚KMP算法,先以暴力算法为基础分析两个例子。
3.1 例1:
主串s=“abcdefgab”模式串p=“abcdex”,也就是上面的图中所示的问题。对于这个例子不难发现,模式串的首字母“a”与后面的串“bcdex”中的任意一个字符都不相等,那么对于①中所示的那样,前五位字符分别与主串匹配成功。也就是说模式串的首字符“a”不可能与主串的第2位到第5位的字符相等。也就是说②③④⑤的判断是多于的。所以只需要保留①⑥就可以了。

注:图中两个串的匹配都是从1开始的,代码中的匹配都是从0开始的。
通过这个例子可以看出如果模式串中的首字符与后面的字符不相同,那么在不成功匹配的时候,i不用回溯。只需要保持i的值不变,然后把j匹配到起始的位置。所以原来暴力算法的代码只需要改动else的部分修改为:
while(i < sLen && j < pLen)
{
if(s[i] == p[j])
{
++i;
++j;
}
else
{
j = 0;
}
}//while
但是这样做是有一个前提的,那就是模式串的首字符与模式串的其它字符是不同的。但是如果不满足这个条件呢?也就是模式串的首字符不满足同其它的字符相异 。
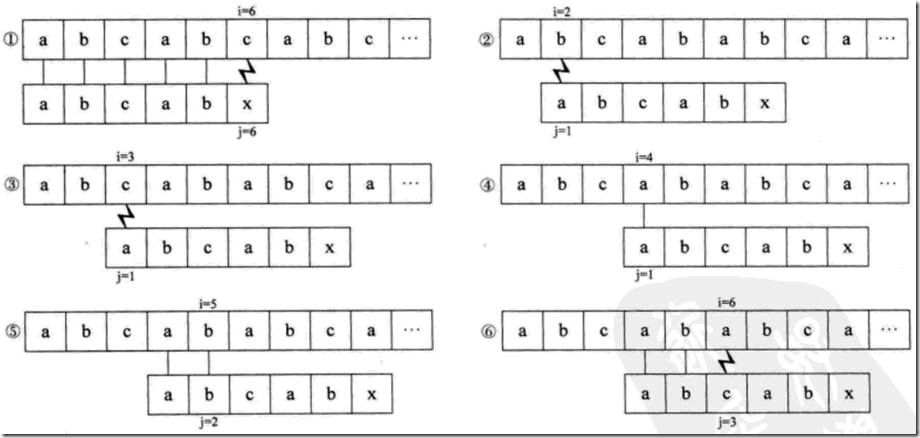
3.2 例2:
主串s=”abcabcabc”,模式串p=”abcabx”,对于开始的判断,前5个字符完全相等,第6个字符不等。但是这时的模式串并不满足例1中的条件,不能满足 首字符与模式串中的其它字符相异。
注:图中两个串的匹配都是从1开始的,代码中的匹配都是从0开始的。
但是还是可以借助例1中的经验的,那就是模式串的首字符与第2个字符、第3个字符不同,所以如图中所以②③的步骤是多余的。
有意思的来了,再来看:对于模式串来说,它的首字符和第4个字符都是“a”,第2个字符和第5个字符都是“b”,也就是说在模式串中有公共的子串“ab”,那么在①中已经看出来,模式串的第45位置和主串的第45位置也都是“ab”,所以④⑤的过程也是多余的。所以只需要保留①⑥就可以了。

注:图中两个串的匹配都是从1开始的,代码中的匹配都是从0开始的。
所以似乎源代码可以这样来修改:
while(i < sLen && j < pLen)
{
if(s[i] == p[j])
{
++i;
++j;
}
else
{
//如果当前字符匹配失败(即s[i] != p[j]),则令 i 不变,j = next[j]
//next[j]即为j所对应的next值
j = next[j];
}
}//while
所以这种算法实现了,i不回溯,j适当的回溯。具体这个next[j]是多少,往后看。
4. KMP算法
前面说到了字符串的模式匹配的暴力方法,同时在暴力方法的基础上做了一些改进:不让主串的匹配指针i回溯,通过发掘模式串的一些特性,不断的修改模式串的匹配指针。但是模式串的匹配指针怎么修改呢,那就得要结合其自身的一些特性,然后产生相应的修改值,记录在next[j]这个数组中。
4.1 寻找前缀后缀最长公共元素长度:
对于 ,寻找模式串P中长度最大且相等的前缀和后缀。如果存在
,寻找模式串P中长度最大且相等的前缀和后缀。如果存在 =
=  ,那么在包含pj的模式串中有最大长度为k+1的相同前缀后缀。举个例子,如果给定的模式串为“abab”,那么它的各个子串的前缀后缀的公共元素的最大长度如下表格所示:
,那么在包含pj的模式串中有最大长度为k+1的相同前缀后缀。举个例子,如果给定的模式串为“abab”,那么它的各个子串的前缀后缀的公共元素的最大长度如下表格所示:

比如对于字符串aba来说,它有长度为1的相同前缀后缀a;而对于字符串abab来说,它有长度为2的相同前缀后缀ab(相同前缀后缀的长度为k + 1,k + 1 = 2)。
4.2 求next数组:
next数组考虑的是除当前字符外的最长前缀后缀公共元素,为什么是除了当前字符呢?回顾前面的两个例子中的模式串“abcdex”和“abcabx”,发现当匹配指针到达某一个字符并且要用到next数组的时候,这个字符一定是匹配失败的字符,在源代码中也可看到这一点,所以这个字符无论如何都要再比较的,不能从算法上逃过去。所以看的是匹配失败的那个字符之前读入的字符,利用这些已经部分匹配这个有效信息,保持i 不回溯,通过修改j 的位置,让模式串尽量地移动到有效的位置。
通过第1步骤求得各个前缀后缀的公共元素的最大长度后,只要稍作变形即可:将第1步骤中求得的值整体向右移动一位,然后初值赋为-1(这里的-1不代表最长相同前缀后缀的长度,仅仅代表这个字符是模式串的首字符,后面就能知道为什么让初始值为-1了),如下表格所示:

比如对于aba来说,第3个字符a之前的字符串ab中有长度为0的相同前缀后缀,所以第3个字符a对应的next值为0;而对于abab来说,第4个字符b之前的字符串aba中有长度为1的相同前缀后缀a,所以第4个字符b对应的next值为1(相同前缀后缀的长度为k,k = 1)。
4.3 根据next数组进行匹配:
说了上面的两个步骤,下面进入正题,怎么根据next数组的值,在保证i值不回溯的情况下,调整j的值进行匹配。
匹配失配,j = next [j],模式串相对于主串向右移动的位数为:j - next[j]。换言之,当模式串的后缀 跟文本串
跟文本串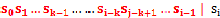 匹配成功,但Pj 跟si匹配失败时,因为next[j] = k,相当于在不包含pj的模式串中有最大长度为k 的相同前缀后缀,即
匹配成功,但Pj 跟si匹配失败时,因为next[j] = k,相当于在不包含pj的模式串中有最大长度为k 的相同前缀后缀,即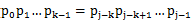 ,故令j = next[j],从而让模式串右移j - next[j] 位,使得模式串的前缀
,故令j = next[j],从而让模式串右移j - next[j] 位,使得模式串的前缀
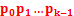 对应着文本串
对应着文本串 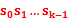 ,而后让Pk 跟si 继续匹配。如下图所示:
,而后让Pk 跟si 继续匹配。如下图所示:
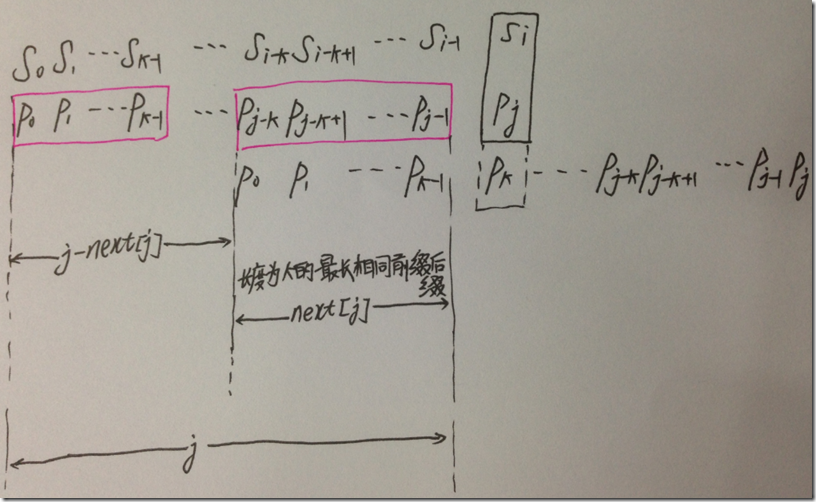
综上,KMP的next 数组相当于告诉我们:当模式串中的某个字符跟文本串中的某个字符匹配失配时,模式串下一步应该跳到哪个位置。如模式串中在j 处的字符跟文本串在i 处的字符匹配失配时,下一步用next [j] 处的字符继续跟文本串i 处的字符匹配,相当于模式串向右移动 j - next[j] 位。
接下来看一个例子,具体的解释上面的东西:
4.4 寻找最长前缀后缀的例子:
如果给定的模式串是:“ABCDABD”,从左至右遍历整个模式串,其各个子串的前缀后缀分别如下表格所示:

也就是说,原模式串子串对应的各个前缀后缀的公共元素的最大长度表为(下简称《最大长度表》):

4.5 基于《最大长度表匹配》的例子:
因为模式串中首尾可能会有重复的字符,故可得出下述结论:
失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值
下面,结合之前的《最大长度表》和上述结论,进行字符串的匹配。如果给定文本串“BBC ABCDAB ABCDABCDABDE”,和模式串“ABCDABD”,现在要拿模式串去跟文本串匹配,这里先直接用最大前缀后缀公共元素长度表,先不用next数据。还有一点就是失配字符的前一个字符对应的最大长度值其实就是下一次匹配时模式串的匹配指针的值,例子中用的是相对于主串的右偏移量,当然两种理解方式都是可以的。如下图所示:

1. 因为模式串中的字符A跟文本串中的字符B、B、C、空格一开始就不匹配,所以不必考虑结论,直接将模式串不断的右移一位即可,直到模式串中的字符A跟文本串的第5个字符A匹配成功:

2. 继续往后匹配,当模式串最后一个字符D跟文本串匹配时失配,显而易见,模式串需要向右移动。但向右移动多少位呢?因为此时已经匹配的字符数为6个(ABCDAB),然后根据《最大长度表》可得失配字符D的上一位字符B对应的长度值为2,所以根据之前的结论,可知需要向右移动6 - 2 = 4 位。

3. 模式串向右移动4位后,发现C处再度失配,因为此时已经匹配了2个字符(AB),且上一位字符B对应的最大长度值为0,所以向右移动:2 - 0 =2 位。

4. A与空格失配,向右移动1 位。

5. 继续比较,发现D与C 失配,故向右移动的位数为:已匹配的字符数6减去上一位字符B对应的最大长度2,即向右移动6 - 2 = 4 位。

6. 经历第5步后,发现匹配成功,过程结束。

这样整个匹配过程就结束了,即使后面再有可以匹配成功的字符串,也不会匹配了。当然如果再次调用匹配函数也是可以的。
通过上述匹配过程可以看出,问题的关键就是寻找模式串中最大长度的相同前缀和后缀,找到了模式串中每个字符之前的前缀和后缀公共部分的最大长度后,便可基于此匹配。而这个最大长度便正是next 数组要表达的含义。
提示:
找已经匹配过的字符的前缀后缀的最长公共序列的原因是:
()能利用匹配子串的不同,防止i的回溯
()能利用匹配子串的相同,找到模式串的合理的有效位置
5. 求next数组
前面已经基本介绍完了KMP算法的基本思想,但是还有一些问题没有解决,其中很重要的一个就是怎么根据《最大长度表》求解next数组,还有就是怎么使用程序迭代出next数组的值。
5.1 根据《最大长度表》求next数组:
由前面讲到的,我们已经知道,字符串“ABCDABD”各个前缀后缀的最大公共元素长度分别为:

而且,根据这个表可以得出下述结论:
失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值
上文利用这个表和结论进行匹配时,我们发现,当匹配到一个字符失配时,其实没必要考虑当前失配的字符,更何况我们每次失配时,都是看的失配字符的上一位字符对应的最大长度值。如此,便引出了next 数组。
给定字符串“ABCDABD”,可求得它的next 数组如下:

把next 数组跟之前求得的最大长度表对比后,不难发现,next 数组相当于“最大长度值” 整体向右移动一位,然后初始值赋为-1。意识到了这一点,你会惊呼原来next 数组的求解竟然如此简单:就是找最大对称长度的前缀后缀,然后整体右移一位,初值赋为-1(当然,你也可以直接计算某个字符对应的next值,就是看这个字符之前的字符串中有多大长度的相同前缀后缀,也就是前面说的不包含Pj)。
换言之,对于给定的模式串:ABCDABD,它的最大长度表及next 数组分别如下:

根据最大长度表求出了next 数组后,从而有
失配时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值
而后,你会发现,无论是基于《最大长度表》的匹配,还是基于next 数组的匹配,两者得出来的向右移动的位数是一样的。为什么呢?因为:
- 根据《最大长度表》,失配时,模式串向右移动的位数 = 已经匹配的字符数 - 失配字符的上一位字符的最大长度值
- 而根据《next 数组》,失配时,模式串向右移动的位数 = 失配字符的位置 - 失配字符对应的next 值
- 其中,从0开始计数时,失配字符的位置 = 已经匹配的字符数(失配字符不计数),而失配字符对应的next 值 = 失配字符的上一位字符的最大长度值,两相比较,结果必然完全一致。
所以,你可以把《最大长度表》看做是next 数组的雏形,甚至就把它当做next 数组也是可以的,区别不过是怎么用的问题。
5.2 通过代码递推计算next数组(这是KMP算法的核心):
5.2.1 next数组引言
next数组又称为前缀数组,它描述的是子串的对称程度,程度越高,值越大。这里说的对称不是中心对称,而是中心字符块的对称。比如说不是abccba而是abcabc这样的对称。
看下面的一个例子:

注:这里的next数组包含当前字符在内的最长公共前缀后缀
(1)逐个查找模式串
a. 当前面字符的前一个字符的对称程度为0的时候,只要将当前字符与子串第一个字符进行比较。这个很好理解啊,前面都是0,说明都不对称了,如果多加了一个字符,要对称的话最多是当前的和第一个对称。比如agcta这个里面t的是0,那么后面的a的对称程度只需要看它是不是等于第一个字符a了。
b. 按照这个推理,我们就可以总结一个规律,不仅前面是0呀,如果前面一个字符的next值是1,那么我们就把当前字符与子串第二个字符进行比较,因为前面的是1,说明前面的字符已经和第一个相等了,如果这个又与第二个相等了,说明对称程度就是2了。有两个字符对称了。比如上面agctag,倒数第二个a的next是1,说明它和第一个a对称了,接着我们就把最后一个g与第二个g比较,又相等,自然对称成都就累加了,就是2了。
c. 按照上面的推理,如果一直相等,就一直累加,可以一直推啊,推到这里应该一点难度都没有吧,如果你觉得有难度说明我写的太失败了。
当然不可能会那么顺利让我们一直对称下去,如果遇到下一个不相等了,那么说明不能继承前面的对称性了,这种情况只能说明没有那么多对称了,但是不能说明一点对称性都没有,所以遇到这种情况就要重新来考虑,这个也是难点所在。
(2)回头来找对称性
在这里依然用上面表中一段来举个例子:
位置i=0到14如下,我加的括号只是用来说明问题:
(a g c t a g c )( a g c t a g c) t
我们可以看到这段,最后这个t之前的对称程度分别是:1,2,3,4,5,6,7,倒数第二个c往前看有7个字符对称,所以对称为7。但是到最后这个t就没有继承前面的对称程度next值,所以这个t的对称性就要重新来求。
这里首要要申明几个事实
1、t 如果要存在对称性,那么对称程度肯定比前面这个c 的对称程度小,所以要找个更小的对称,这个不用解释了吧,如果大那么t就继承前面的对称性了。
2、要找更小的对称,必然在对称内部还存在子对称,而且这个t必须紧接着在子对称之后。
如下图说明。

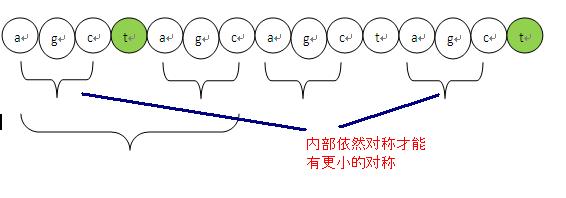
说明:既然不能继承前面的对称性了,那么就要在原来的前后缀内部找更小的对称,这个小对称的后缀一定在后面的那个大括号中产生(前缀在前面的小括号中产生),问题就变成了在后面的大括号中寻找一个最大长度的后缀,又因为后面的大括号和前面的大括号相等,所以问题进一步的转化为在前面的大括号中寻找最长的后缀。再看,这个前面的大括号中的最长后缀一定对应一个最长的前缀。只要找到了这个最长的前缀,并且它的后面也是字符t,那么久匹配成功了。所以问题一步步的转换,变成了当对称性继承失配后,去检查能否继承k(图中红色a的下标)之前的最长前缀的对称性。k之前的最长前缀是谁呢?
很容易的得到,k之前最长前缀后缀的字符数为l = next[k],那么前缀的下标为[0,1…l-1],那么只需要比较pl和pj看看是否相等,如果相等就继承对称性,next[j]=next[l]+1。如果不能继承对称性,就按上面的方法递归。
在来换个角度分析一下:现在如果相求next[14]。那么就得在p13之前(不包括P13)的字符串中找到一个最大的前后缀,如果找到的前缀的后面的那个字符和p13相等,那么就继承了前面字符串的对称性。p13之前的最长前缀是多少呢?答案就是下标[0,1,…,next[13]-1]。所以比较P[next[13]]和pj看看能否继承对称性。
如果不能继承对称性,那么就寻找更小的最长前缀。就回到上面的说明中了。
5.2.2 next数组实现
(1)如果对于值k,已有,相当于next[j] = k。
此意味着什么呢?究其本质,next[j] = k 代表p[j] 之前的模式串子串中,有长度为k 的相同前缀和后缀。有了这个next 数组,在KMP匹配中,当模式串中j 处的字符失配时,下一步用next[j]处的字符继续跟文本串匹配,相当于模式串向右移动j - next[j] 位。
(2)下面的问题是:已知next [0, ..., j],如何求出next [j + 1]呢?
对于P的前j+1个序列字符: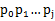 ,对于这个模式串已经知道:。
,对于这个模式串已经知道:。
- 若p[k] == p[j],则next[j + 1 ] = next [j] + 1 = k + 1;
- 若p[k ] ≠ p[j],如果此时p[ next[k] ] == p[j ],则next[ j + 1 ] = next[k] + 1,否则继续递归前缀索引k = next[k],而后重复此过程。 相当于在字符p[j+1]之前不存在长度为k+1的前缀"p0 p1, …, pk-1 pk"跟后缀“pj-k pj-k+1, …, pj-1 pj"相等,那么是否可能存在另一个值t+1 < k+1,使得长度更小的前缀 “p0 p1, …, pt-1 pt” 等于长度更小的后缀 “pj-t pj-t+1, …, pj-1 pj” 呢?如果存在,那么这个t+1 便是next[ j+1]的值,此相当于利用已经求得的next 数组(next [0, ..., k, ..., j])进行P串前缀跟P串后缀的匹配。
那么对于这种利用已经求得的next数组求解的理论依据是什么呢?
看一个模式串p =“ababaaaba”,根据算法一个匹配前缀和后缀,直到前缀是“abab”后缀是“abaa”的时候,也就是k=3,j=5的时候,匹配失败。这时的暴力解法是遍历第4个字符b之前的所有字符,找到一个“a”,然后在看看这个前缀是否能有与之对应的后缀。
换个角度想,如果想找到包含第5个字符“a”的后缀对应的前缀,那么这个后缀的除了“a”之外的字符在前面肯定有过前缀匹配,只要在前缀的最后来一个“a”就可以了。很巧的是,之前字符串的匹配记录都存放在next数组中。这也就是用到next数组进行前后缀匹配的原因,它缩小了匹配前后缀的来源范围,同时又不会漏掉哪一个字符串。反过来讲,如果“a”前面的字符都没有成功匹配过,试问加上一个“a”又怎么能成功匹配!
这种方法也是对next数组的下标进行回溯,这一点是KMP算法的核心。
所以代码为:
//k=-1是第一个的入口
//是回溯到最后仍未能找到合适匹配的入口
//这里说的回溯到最后指的是:k=0时p[k=0]仍不等于p[j]
//这时要继续向后回溯,k=next[k]到了k=-1这个入口点
void GetNext(char *p, int *next)
{
int pLen = strlen(p);
int j = 0;
int k = -1;
next[0] = -1; while(j < pLen - 1)
{
//首字符入口,回溯到最后不能匹配的入口
if(k == -1)
{
++k;
++j;
next[j] = k;//表示在j这个字符之前,能够构成公共前后缀的最大字符数
}//if
else
{
//p[k]表示前缀,p[j]表示后缀
if(p[j] == p[k])
{
++k;
++j;
next[j] = k;//表示在j这个字符之前,能够构成公共前后缀的最大字符数
}
else
{
k = next[k];//回溯之前已经有过匹配的前缀
}
}//else }//while
}
改写:
void GetNext(char *p, int *next)
{
int pLen = strlen(p);
int j = 0;
int k = -1;
next[0] = -1; while(j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if(k == -1 || p[j] == p[k])
{
++k;
++j;
next[j] = k;//表示在j这个字符之前,能够构成公共前后缀的最大字符数
}
else
{
k = next[k];//回溯之前已经有过匹配的前缀
}
}
}
行文至此,咱们全面了解了暴力匹配的思路、KMP算法的原理、流程、流程之间的内在逻辑联系,以及next 数组的简单求解(《最大长度表》整体右移一位,然后初值赋为-1)和代码求解,最后基于《next 数组》的匹配,看似洋洋洒洒,清晰透彻,但以上忽略了一个小问题。就是到这里的KMP算法仍然不是完美的,它还存在问题。
6. KMP模式匹配算法改进
如果用之前的next 数组方法求模式串“abab”的next 数组,可得其next 数组为-1 0 0 1(0 0 1 2整体右移一位,初值赋为-1),当它跟下图中的文本串去匹配的时候,发现b跟c失配,于是模式串右移j - next[j] = 3 - 1 =2位。

右移2位后,b又跟c失配。事实上,因为在上一步的匹配中,已经得知p[3] = b,与s[3] = c失配,而右移两位之后,让p[ next[3] ] = p[1] = b 再跟s[3]匹配时,必然失配。问题出在哪呢?

问题出在不该出现p[j] = p[ next[j] ]。为什么呢?理由是:当p[j] != s[i] 时,下次匹配必然是p[ next [j]] 跟s[i]匹配,如果p[j] = p[ next[j] ],必然导致后一步匹配失败(因为p[j]已经跟s[i]失配,然后你还用跟p[j]等同的值p[next[j]]去跟s[i]匹配,很显然,必然失配),所以不能允许p[j] = p[ next[j ]]。如果出现了p[j] = p[ next[j] ]咋办呢?如果出现了,则需要再次递归,即令next[j] = next[ next[j] ]。
void GetNextVal(char *p, int *next)
{
int pLen = strlen(p);
int j = 0;
int k = -1;
next[0] = -1; while(j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if(k == -1 || p[j] == p[k])
{
++k;
++j;
if(p[j] != p[k])
{
next[j] = k;//表示在j这个字符之前,能够构成公共前后缀的最大字符数
}
else
{
next[j] = next[k];//因为不能出现p[j] = p[next[j]],所以当出现时需要继续递归,k = next[k] = next[next[k]]
} }
else
{
k = next[k];//回溯之前已经有过匹配的前缀
}
}
}
看一个例子:
主串s=”aaaabcde”模式串p=”aaaaax”。如果用前面的next数组的方法,过程如下图所示:
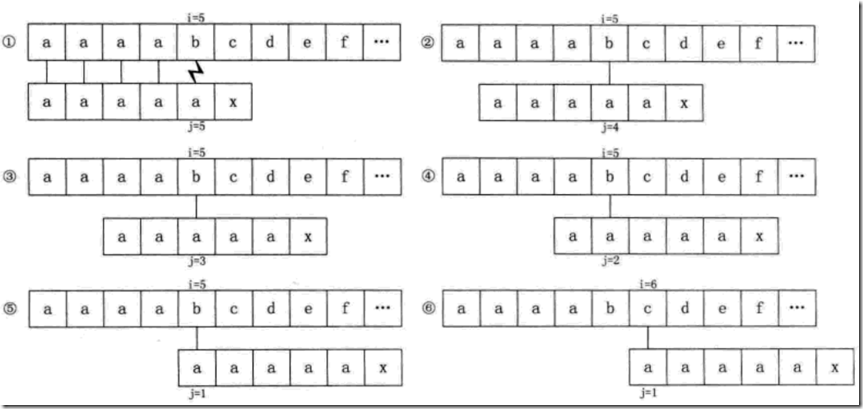
其中的2345都是多余的判断,产生这个的原因就是p[j] = p[ next[j ]]。这样的话就导致了,在匹配的时候多次的去查找next数组。
总而言之,它是在计算next数组的同时,如果a位字符与它的next值指向的b位字符相等,这该a位的nextval就指向b位的nextval值。
7. KMP算法实现和时间复杂度分析:
在前面对KMP算法做了各种的讲解之后,现在要对这个算法做一个代码的实现了:
int KmpSearch(char *s, char *p)
{
int i = 0;
int j = 0;
int sLen = strlen(s);
int pLen = strlen(p); while(i < sLen && j < pLen)
{
//如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
if(j == -1 || s[i] == p[j])
{
i++;
j++;
}
else
{
//如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]
//next[j]即为j所对应的next值
j = next[j];
}
}//while if(j == pLen)
{
return i - j;
}
else
{
return -1;
}
}
KMP算法时间复杂度分析:
如果文本串的长度为n,模式串的长度为m,那么匹配过程的时间复杂度为O(n),算上计算next的O(m)时间,KMP的整体时间复杂度为O(m + n)。
8. 参考文献
July老师的博客,从到到尾彻底理解KMP算法:http://blog.csdn.net/v_july_v/article/details/7041827
数据结构书籍:大话数据结构。
KMP算法的一次理解的更多相关文章
- KMP算法详解 --- 彻头彻尾理解KMP算法
前言 之前对kmp算法虽然了解它的原理,即求出P0···Pi的最大相同前后缀长度k. 但是问题在于如何求出这个最大前后缀长度呢? 我觉得网上很多帖子都说的不是很清楚,总感觉没有把那层纸戳破, 后来翻看 ...
- poj 2406:Power Strings(KMP算法,next[]数组的理解)
Power Strings Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 30069 Accepted: 12553 D ...
- 字符串匹配与KMP算法实现
>>字符串匹配问题 字符串匹配问题即在匹配串中寻找模式串是否出现, 首先想到的是使用暴力破解,也就是Brute Force(BF或蛮力搜索) 算法,将匹配串和模式串左对齐,然后从左向右一个 ...
- 浅谈KMP算法及其next[]数组
KMP算法是众多优秀的模式串匹配算法中较早诞生的一个,也是相对最为人所知的一个. 算法实现简单,运行效率高,时间复杂度为O(n+m)(n和m分别为目标串和模式串的长度) 当字符串长度和字符集大小的比值 ...
- [模板]KMP算法
昨天晚上一直在调KMP(模板传送门),因为先学了hash[关于hash的内容会在随后进行更(gu)新(gu)]于是想从1开始读...结果写出来之后一直死循环,最后我还是改回从0读入字符串了. [预先定 ...
- KMP算法字符串查找子串
题目: 经典的KMP算法 分析: 和KMP算法对应的是BF算法,其中BF算法时间复杂度,最坏情况下可以达到O(n*m),而KMP算法的时间复杂度是O(n + m),所以,KMP算法效率高很多. 但是K ...
- KMP 算法中的 next 数组
KMP 算法中对 next 数组的理解 next 数组的意义 此处 next[j] = k:则有 k 前面的浅蓝色区域和 j 前面的浅蓝色区域相同: next[j] 表示当位置 j 的字符串与主串不匹 ...
- 深入理解KMP算法
前言:本人最近在看<大话数据结构>字符串模式匹配算法的内容,但是看得很迷糊,这本书中这块的内容感觉基本是严蔚敏<数据结构>的一个翻版,此书中给出的代码实现确实非常精炼,但是个人 ...
- KMP算法简明扼要的理解
KMP算法也算是相当经典,但是对于初学者来说确实有点绕,大学时候弄明白过后来几年不看又忘记了,然后再弄明白过了两年又忘记了,好在之前理解到了关键点,看了一遍马上又能理解上来.关于这个算法的详解网上文章 ...
随机推荐
- 米兰站热卖:奢侈品电商困局已破?-搜狐IT
米兰站热卖:奢侈品电商困局已破?-搜狐IT 米兰站热卖:奢侈品电商困局已破?
- VC6.0调试大全
VC调试方法大全 一.调试基础 调试快捷键 F5: 开始调试 Shift+F5: 停止调试 F10: 调试到下一句,这里是单步跟踪 F11: 调试到下一句,跟进函数内部 Shift+F11: ...
- Ueditor和CKeditor 两款编辑器的使用与配置
一丶ueditor 百度编辑器 1.官方文档,演示,下载地址:http://ueditor.baidu.com/website/index.html 2.百度编辑器的好:Editor是由百度web前端 ...
- mysql在查询结果中增加排序字段
ELECT userId , () AS runRank , mostFast1 FROM user_info, ()) b WHERE mostFast1 IS NOT NULL ORDER BY ...
- nodejs事件机制
var EventEmitter = function() { this.evts = {}; }; EventEmitter.prototype = { constructor: EventEmit ...
- Angular form
参考 http://blog.xebia.com/2013/10/15/angularjs-validating-radio-buttons/ http://stackoverflow.com/que ...
- Linux系统管理员:不要害怕升级内核
Linux系统管理员平时很重要的一项工作就是负责系统内核升级.做好系统内核的升级工作,对于Linux系 统的稳定性具有至关重要的作用.但是很少有人敢贸然的对Linux系统的内核进行升级,担心会影响现有 ...
- 闪存主控IC的作用
闪存主要是由闪存芯片.主控芯片.晶振.PCB板等部件组成的.其中主控芯片相当于闪存的“灵魂”,它控制着闪存的工作.主控芯片也是处理单元,在里面写入的程序对整个电路做控制.主控IC是把flash跟hos ...
- cssline-height行高 全解
1. 基线.底线.顶线 2. 行距.行高 3. 内容区 4. 行内框 5. 行框 元素对行高的影响 扩展阅读 1. 基线.底线.顶线 行高指的是文本行的基线间的距离. 基线并不是汉字的下端 ...
- 10个必备的移动UI设计资源站
http://www.uisdc.com/10-necessary-mobile-ui-design-resources# 交互设计中如何增加趣味性.提升愉悦http://www.uisdc.com/ ...