Spark常用函数讲解之Action操作
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD有两种操作算子:
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作:
1.RDD基本转换
2.键-值RDD转换
3.Action操作篇
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("reduce")
val sc = new SparkContext(conf)
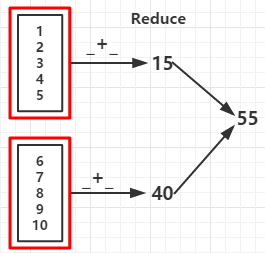
val rdd = sc.parallelize(1 to 10,2)
val reduceRDD = rdd.reduce(_ + _)
val reduceRDD1 = rdd.reduce(_ - _) //如果分区数据为1结果为 -53
val countRDD = rdd.count()
val firstRDD = rdd.first()
val takeRDD = rdd.take(5) //输出前个元素
val topRDD = rdd.top(3) //从高到底输出前三个元素
val takeOrderedRDD = rdd.takeOrdered(3) //按自然顺序从底到高输出前三个元素
println("func +: "+reduceRDD)
println("func -: "+reduceRDD1)
println("count: "+countRDD)
println("first: "+firstRDD)
println("take:")
takeRDD.foreach(x => print(x +" "))
println("\ntop:")
topRDD.foreach(x => print(x +" "))
println("\ntakeOrdered:")
takeOrderedRDD.foreach(x => print(x +" "))
sc.stop
}
func +:
func -: //如果分区数据为1结果为 -53
count:
first:
take: top: takeOrdered:

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("KVFunc")
val sc = new SparkContext(conf)
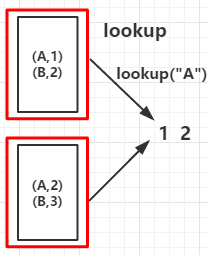
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val rdd = sc.parallelize(arr,2)
val countByKeyRDD = rdd.countByKey()
val collectAsMapRDD = rdd.collectAsMap()
println("countByKey:")
countByKeyRDD.foreach(print)
println("\ncollectAsMap:")
collectAsMapRDD.foreach(print)
sc.stop
}
countByKey:
(B,)(A,)
collectAsMap:
(A,)(B,)

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("Fold")
val sc = new SparkContext(conf)
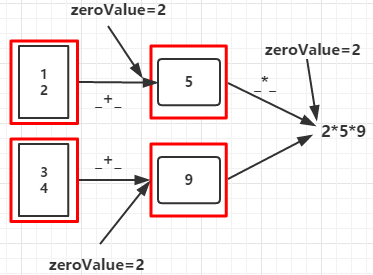
val rdd = sc.parallelize(List(1,2,3,4),2)
val aggregateRDD = rdd.aggregate(2)(_+_,_ * _)
println(aggregateRDD)
sc.stop
}

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("Fold")
val sc = new SparkContext(conf)
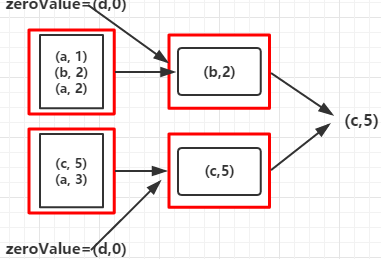
val rdd = sc.parallelize(Array(("a", 1), ("b", 2), ("a", 2), ("c", 5), ("a", 3)), 2)
val foldRDD = rdd.fold(("d", 0))((val1, val2) => { if (val1._2 >= val2._2) val1 else val2
})
println(foldRDD)
}
c,5

Spark常用函数讲解之Action操作的更多相关文章
- Spark常用函数讲解之键值RDD转换
摘要: RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集RDD有两种操作算子: Trans ...
- spark 常用函数介绍(python)
以下是个人理解,一切以官网文档为准. http://spark.apache.org/docs/latest/api/python/pyspark.html 在开始之前,我先介绍一下,RDD是什么? ...
- Spark RDD概念学习系列之action操作
不多说,直接上干货! action操作
- Spark常用函数(源码阅读六)
源码层面整理下我们常用的操作RDD数据处理与分析的函数,从而能更好的应用于工作中. 连接Hbase,读取hbase的过程,首先代码如下: def tableInitByTime(sc : SparkC ...
- CI框架常用函数(AR数据库操作的常用函数)
用户手册地址:http://codeigniter.org.cn/user_guide/index.html 1.查询表记录$this->db->select(); //选择查询的字段$t ...
- 四、spark常用函数说明学习
1.parallelize 并行集合,切片数.默认为这个程序所分配到的资源的cpu核的个数. 查看大小:rdd.partitions.size sc.paraliel ...
- Opencv常用函数讲解
1.approxPolyDP(Mat(ps), poly, 5, true);//根据点集,拟合出多边形 2.fillConvexPoly(mask, Mat(ps), Scalar(255));根据 ...
- Spark RDD、DataFrame原理及操作详解
RDD是什么? RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用. RDD内部可以 ...
- Spark Streaming中的操作函数讲解
Spark Streaming中的操作函数讲解 根据根据Spark官方文档中的描述,在Spark Streaming应用中,一个DStream对象可以调用多种操作,主要分为以下几类 Transform ...
随机推荐
- class 类(3) 继承
继承(Inheritance)是面向对象软 件技术当中的一个概念.如果一个类别A“继承自”另一个类别B,就把这个A称为“B的子类别”,而把B称为“A的父类别”,也可以称“B是A的超类”. 继承可以使得 ...
- ORACLE SEQUENCE 介绍
在oracle中sequence就是所谓的序列号,每次取的时候它会自己主动添加,一般用在须要按序列号排序的地方. 1.Create Sequence 你首先要有CREATE SEQUENCE或者C ...
- 曾经的足迹——对Linux CAN驱动的理解(1)
在Ti的AM335X系列Cortext-A8芯片中,CAN模块采用D_CAN结构,实质即两路CAN接口. 在此分享一下对基于AM335X的Linux CAN驱动源码的理解.下面来分析它的驱动源码及其工 ...
- Samba通过ad域进行认证并限制空间大小《转载》
本文实现了samba服务被访问的时候通过windows域服务器进行用户名和密码验证;认证通过的用户可以自动分配500M的共享空间;在用户通过windows域登陆系统的时候可以自动把这块空间映射成一块硬 ...
- 慕课linux学习笔记(一)centOS的安装
在VMware8上安装centos6.3 准备的文件 新建虚拟机 选择新建一个空的虚拟机 选择linux和centos 分配20G的硬盘空间 ' 修改配置 调整内存空间 桥接:虚拟机和真实机通讯使用的 ...
- WebApi2官网学习记录---Content Negotiation
Content Negotiation的意思是:当有多种Content-Type可供选择时,选择最合适的一种进行序列化并返回给client. 主要依据请求中的Accept.Accept-Charset ...
- Asp.net mvc4 + HighCharts + 柱状图
前端代码: @{ Layout = null;} <!DOCTYPE html> <html><head> <meta name="viewport ...
- 技巧集:nginx作代理时,查看请求被转发到哪台服务器
使用Nginx代理多台服务器实行负载的时候,如何查看某一个请求被转发到哪台服务器上呢? upstream demo { server 127.0.0.1:8781; server 127.0.0.1: ...
- java基础知识3
58.线程的基本概念.线程的基本状态以及状态之间的关系线程指在程序执行过程中,能够执行程序代码的一个执行单位,每个程序至少都有一个线程,也就是程序本身.Java中的线程有四种状态分别是:运行.就绪.挂 ...
- php 和 apache的关系
例如在客户端游览器输入他也回把这个地址传送到192.168.1.100里的apache里的,apache一看你传过来的是Php文件,如果在服务器没装php的情况下,他也会把这个文件打开,把里面的代码全 ...