消息队列(六)--- RocketMQ-消息消费
文章部分图片来自参考资料,侵删
概述
我们从前面的发送流程知道某个主题的消息到了broker 的 messageque 里,假如让我们来设计一个消息队列的消费者过程,那么多个消费者应该如何消费数量较少的 messagequeue 呢?消费者有两种消费模式 : 广播模式和集群模式 ,广播模式很好理解就是消费所有的消息;集群模式相当于多个消费者逻辑上认为是一个整体,最通俗的理解就是一个消息在集群里面只有一个消费者消费就算消费完成。
那么集群模式的消费方式应该按照何种策略呢?再一个既然集群模式只允许一个消费者消费,那么如何阻止其他消费者消费呢?
获取消费的方式也有两种,是broker 自己推过来呢还是消费者自己去拉呢?
根据这几个问题我们将带着疑问去看看 rocketmq 如何设计。
消息队列负载均衡
消费队列的负载均衡解决的就是消费者该去哪里消费的问题,从而达到消费均衡。
集群模式
group组里只要有一个人消费就算消费成功了,分多种策略
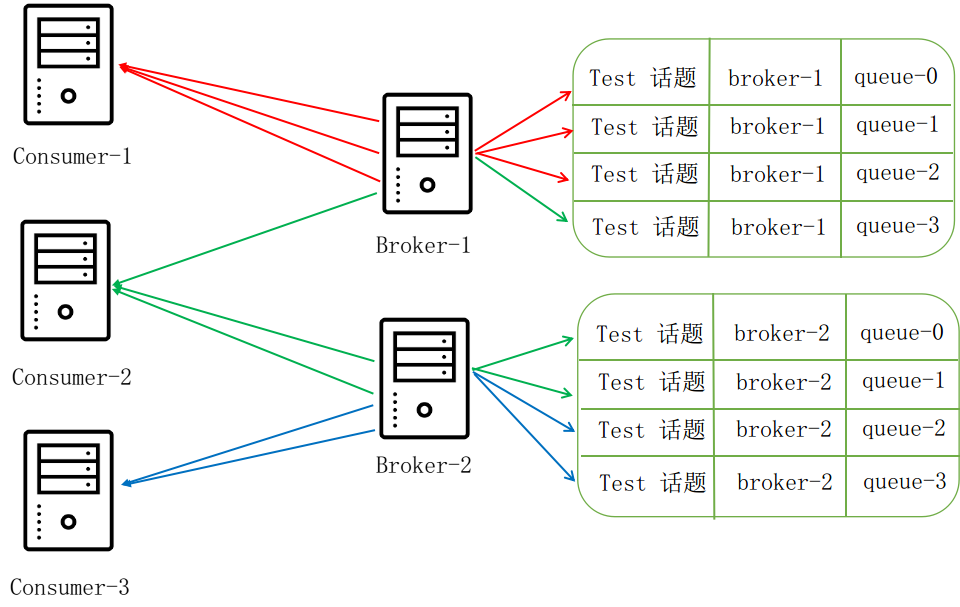
平均分配策略
在group里平均分配消息,例如3个节点9条消息,使用除法,每人3条消息。图片来自参考资料,侵删。
一致性哈希策略
(分布式哈希一致性)[https://www.cnblogs.com/Benjious/p/11899188.html]通过这篇文章可以了解一致性哈希
- 平均分配轮询策略
同样是上面的例子,轮询分配,同样是策略,rocketmq同样会利用虚拟节点防止hash环上节点不均衡的情况,而落在环上的keys这是broker上的队列。
广播模式.
全量消费,很好理解
消费模式在代码中实现
消息队列的负载均衡是由一个不停运行的均衡服务来定时执行的,执行的逻辑RebalanceImpl 来实现,
public void doRebalance(final boolean isOrder) {
Map<String, SubscriptionData> subTable = this.getSubscriptionInner();
if (subTable != null) {
for (final Map.Entry<String, SubscriptionData> entry : subTable.entrySet()) {
final String topic = entry.getKey();
try {
this.rebalanceByTopic(topic, isOrder);
} catch (Throwable e) {
if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
log.warn("rebalanceByTopic Exception", e);
}
}
}
}
this.truncateMessageQueueNotMyTopic();
}
public ConcurrentMap<String, SubscriptionData> getSubscriptionInner() {
return subscriptionInner;
}
private void rebalanceByTopic(final String topic, final boolean isOrder) {
switch (messageModel) {
//广播是存储在本地的,集群是存储在broker
case BROADCASTING: {
//广播,那么必定是去本地查找
...
}
case CLUSTERING: {
//集群模式消费进度存储在远程broker 端
...
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List<MessageQueue> allocateResult = null;
try {
//调用分配策略
allocateResult = strategy.allocate(
this.consumerGroup,
this.mQClientFactory.getClientId(),
mqAll,
cidAll);
} catch (Throwable e) {
log.error("AllocateMessageQueueStrategy.allocate Exception. allocateMessageQueueStrategyName={}", strategy.getName(),
e);
return;
}
Set<MessageQueue> allocateResultSet = new HashSet<MessageQueue>();
if (allocateResult != null) {
allocateResultSet.addAll(allocateResult);
}
}
}
}
默认是使用 AllocateMessageQueueAveragely 分配策略,这里我们思考一个问题,我们知道对于某条消息集群模式下只有一个消费者可以消费,消息是被放进 messagequeue 里的,当 消费者的数量大于
messagequeue 的数量的时候,那么该如何分配呢?一个messagequeue 可以分配多个消费者吗?下面我写了个测试,分配的逻辑和 AllocateMessageQueueAveragely 一样。
public static void main(String[] args) {
Main m = new Main();
m.test();
}
public List<MessageQueue> op( String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
List<MessageQueue> result = new ArrayList<>();
int index = cidAll.indexOf(currentCID);
int mod = mqAll.size() % cidAll.size();
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
+ 1 : mqAll.size() / cidAll.size());
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}
public void test(){
List<String> cidAll = new ArrayList<>();
for (int i=0; i<8; i++) {
String cid = "192.168.10.86@" + i;
cidAll.add(cid);
}
List<MessageQueue> mqAll = new ArrayList<>();
for (int i=0; i<3; i++) {
MessageQueue mq = new MessageQueue(i);
mqAll.add(mq);
}
for (String cid :
cidAll) {
List<MessageQueue> op = op(cid, mqAll, cidAll);
System.out.println("当前 cid : "+ cid + " ");
for (MessageQueue mq : op) {
System.out.println("去 "+ mq.no +" 号拿消息进行消息");
}
}
}
当前 cid : 192.168.10.86@0
去 0 号拿消息进行消息
当前 cid : 192.168.10.86@1
去 1 号拿消息进行消息
当前 cid : 192.168.10.86@2
去 2 号拿消息进行消息
当前 cid : 192.168.10.86@3
当前 cid : 192.168.10.86@4
当前 cid : 192.168.10.86@5
当前 cid : 192.168.10.86@6
当前 cid : 192.168.10.86@7
(忽略我不规范的命名,哈哈)可以看到在集群模式下要是有多余的消费者那么他们肯定是饿着,分配不到messagequeue 。
消费进度
某个消费者消费了某个消息,那么如何在标识该消费“已被我消费了呢”,也就是保存进度的问题
,对于广播模式,保存进度是在broker 端中保存的,而集群模式这保存是在客户端本地。存储进度主要是 offsetStore接口,它的子类实现 LocalFileOffsetStore 和 RemoteBrokerOffsetStore 分别对应这本地储存和远程储存
集群模式下
以下内容来自参考资料,作者写的非常
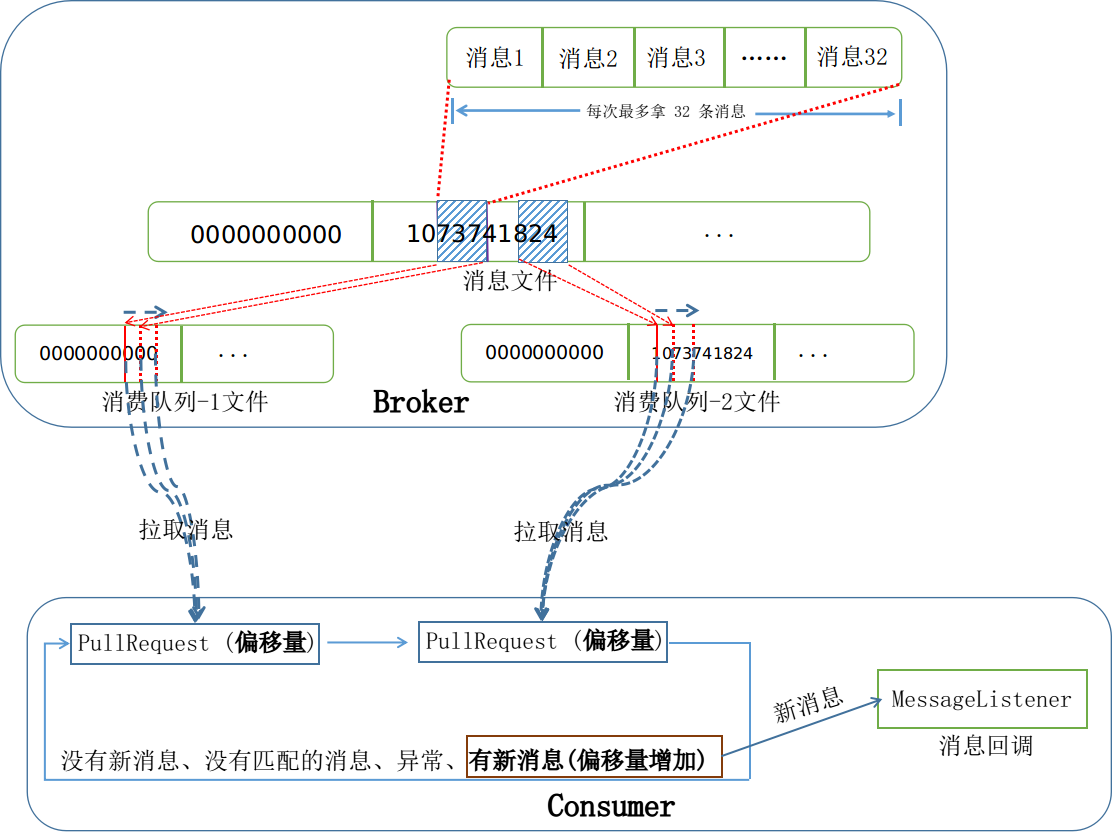
在消费者客户端,RebalanceService 服务会定时地 (默认 20 秒) 从 Broker 服务器获取当前客户端所需要消费的消息队列,并与当前消费者客户端的消费队列进行对比,看是否有变化。对于每个消费队列,会从 Broker 服务器查询这个队列当前的消费偏移量。然后根据这几个消费队列,创建对应的拉取请求 PullRequest 准备从 Broker 服务器拉取消息,如下图所示:

当从 Broker 服务器拉取下来消息以后,只有当用户成功消费的时候,才会更新本地的偏移量表。本地的偏移量表再通过定时服务每隔 5 秒同步到 Broker 服务器端:
public class MQClientInstance {
private void startScheduledTask() {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
MQClientInstance.this.persistAllConsumerOffset();
}
}, 1000 * 10, this.clientConfig.getPersistConsumerOffsetInterval(), TimeUnit.MILLISECONDS);
}
}
而维护在 Broker 服务器端的偏移量表也会每隔 5 秒钟序列化到磁盘中:
public class BrokerController {
public boolean initialize() throws CloneNotSupportedException {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
BrokerController.this.consumerOffsetManager.persist();
}
}, 1000 * 10, this.brokerConfig.getFlushConsumerOffsetInterval(), TimeUnit.MILLISECONDS);
}
}
拉取消费
rocketmq 的 push 实际都是利用不断地去 pull 来达到 push 的效果。 push 实际是用 pull 实现的,开始的时候内存为空,生成 pullRequest 然后去 broker 请求数据,请求回来后再次生成 pullRequest再次去请求,去broker拉取消费进行的消费的服务 : PullMessageService ,它接受 PullRequest
public class PullRequest {
private MessageQueue messageQueue;
private ProcessQueue processQueue;
}
public class ProcessQueue {
private final TreeMap<Long, MessageExt> msgTreeMap = new TreeMap<Long, MessageExt>();
}
PullRequest 关联MessageQueue 和 ProcessQueue ,ProcessQueue 是指某个MessageQueue的消费进度抽象
/**
* Queue consumption snapshot
*
*/
public class ProcessQueue {
...
private final Logger log = ClientLogger.getLog();
//读写锁
private final ReadWriteLock lockTreeMap = new ReentrantReadWriteLock();
// TreeMap 是可以排序的 map(红黑树实现)
private final TreeMap<Long, MessageExt> msgTreeMap = new TreeMap<Long, MessageExt>();
private final AtomicLong msgCount = new AtomicLong();
private final AtomicLong msgSize = new AtomicLong();
private final Lock lockConsume = new ReentrantLock();
/**
* A subset of msgTreeMap, will only be used when orderly consume
*/
private final TreeMap<Long, MessageExt> consumingMsgOrderlyTreeMap = new TreeMap<Long, MessageExt>();
private final AtomicLong tryUnlockTimes = new AtomicLong(0); }
可以看到ProcessQueue维护两个消息树为了就是记录消费的进度,这在后面会介,我们也可以大概地猜测到 PullRequest 实际应该的含义是某个指定的 MessageQueue 进度发生了变化,就会生成一个 PullRequest 去远程拉取消费进行消费。
服务器在收到客户端的请求之后,会根据话题和队列 ID 定位到对应的消费队列。然后根据这条请求传入的 offset 消费队列偏移量,定位到对应的消费队列文件。偏移量指定的是消费队列文件的消费下限。
public class DefaultMessageStore implements MessageStore {
public GetMessageResult getMessage(final String group, final String topic, final int queueId, final long offset,
final int maxMsgNums,
final MessageFilter messageFilter) {
// ...
ConsumeQueue consumeQueue = findConsumeQueue(topic, queueId);
if (consumeQueue != null) {
// 首先根据消费队列的偏移量定位消费队列
SelectMappedBufferResult bufferConsumeQueue = consumeQueue.getIndexBuffer(offset);
if (bufferConsumeQueue != null) {
try {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
// 最大消息长度
final int maxFilterMessageCount = Math.max(16000, maxMsgNums * ConsumeQueue.CQ_STORE_UNIT_SIZE);
// 取消息
for (; i < bufferConsumeQueue.getSize() && i < maxFilterMessageCount; i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {
long offsetPy = bufferConsumeQueue.getByteBuffer().getLong();
int sizePy = bufferConsumeQueue.getByteBuffer().getInt();
// 根据消息的偏移量和消息的大小从 CommitLog 文件中取出一条消息
SelectMappedBufferResult selectResult = this.commitLog.getMessage(offsetPy, sizePy);
getResult.addMessage(selectResult);
status = GetMessageStatus.FOUND;
}
// 增加下次开始的偏移量
nextBeginOffset = offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);
} finally {
bufferConsumeQueue.release();
}
}
}
// ...
}
}
客户端和 Broker 服务器端完整拉取消息的流程图如下所示:
消费消费
顺序消费和并发消费,顺序消费指的是消费同一个 messagequeue 里的消息,从而达到顺序消费的目的。
broker 中记录的信息
consumerFilter.json
消费者过滤相关
consumerOffset.json
消费者消费broker各个队列到了哪个位置
{
"offsetTable":{
"%RETRY%generalCallbackGroup@generalCallbackGroup":{0:0
},
"Jodie_topic_1023@CID_JODIE_1":{0:10,1:11,2:10,3:9
},
"PayTransactionTopic@mq_test_callback":{0:0,1:0,2:1,3:1
},
}
}
可以看到是有json表示的是“topic + group ”中的四个队列的消费情况
delayOffset.json 、
延时相关
subscriptionGroup.json
订阅相关,group相关的配置, 消费者订阅了哪些topic
{
"dataVersion":{
"counter":1,
"timestamp":1572054949837
},
"subscriptionGroupTable":{
"CID_ONSAPI_OWNER":{
"brokerId":0,
"consumeBroadcastEnable":true,
"consumeEnable":true,
"consumeFromMinEnable":true,
"groupName":"CID_ONSAPI_OWNER",
"notifyConsumerIdsChangedEnable":true,
"retryMaxTimes":16,
"retryQueueNums":1,
"whichBrokerWhenConsumeSlowly":1
},
"CID_ONSAPI_PERMISSION":{
"brokerId":0,
"consumeBroadcastEnable":true,
"consumeEnable":true,
"consumeFromMinEnable":true,
"groupName":"CID_ONSAPI_PERMISSION",
"notifyConsumerIdsChangedEnable":true,
"retryMaxTimes":16,
"retryQueueNums":1,
"whichBrokerWhenConsumeSlowly":1
},
...
}
}
topics.json
topic相关配置,broker 中拥有那些topic
{
"dataVersion":{
"counter":5,
"timestamp":1573745719274
},
"topicConfigTable":{
"TopicTest":{
"order":false,
"perm":6,
"readQueueNums":4,
"topicFilterType":"SINGLE_TAG",
"topicName":"TopicTest",
"topicSysFlag":0,
"writeQueueNums":4
},
"%RETRY%please_rename_unique_group_name_4":{
"order":false,
"perm":6,
"readQueueNums":1,
"topicFilterType":"SINGLE_TAG",
"topicName":"%RETRY%please_rename_unique_group_name_4",
"topicSysFlag":0,
"writeQueueNums":1
}
...
}
}
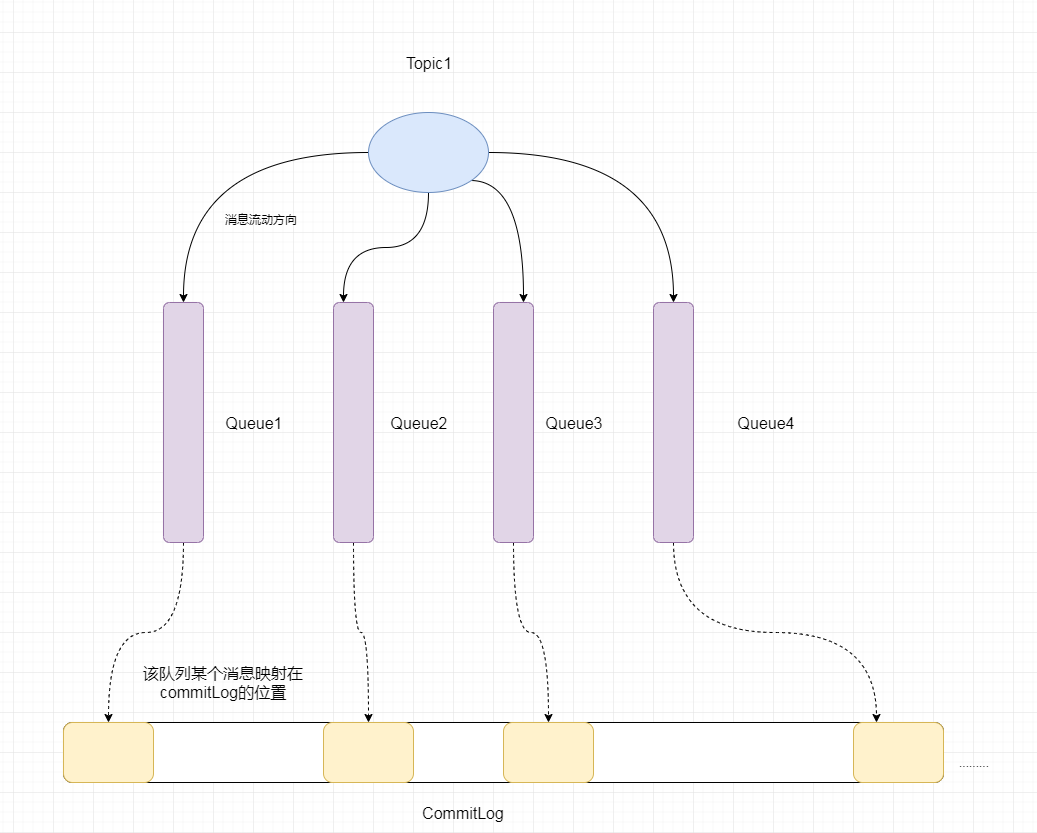
consumerQueue 图例
消费消息
消费消息有并发消费和顺序消费两种,主要的核心实现就是 ConsumeMessageConcurrentlyService 和 ConsumeMessageOrderlyService ,又它们继承的接口看的出来他们都是持有了一个线程池,并在线程池内进行消费。
public class DefaultMQPushConsumerImpl implements MQConsumerInner {
public void pullMessage(final PullRequest pullRequest) {
PullCallback pullCallback = new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
if (pullResult != null) {
switch (pullResult.getPullStatus()) {
case FOUND:
// 消息放入处理队列的消息树中
boolean dispathToConsume = processQueue
.putMessage(pullResult.getMsgFoundList());
// 提交一个消息消费请求
DefaultMQPushConsumerImpl.this
.consumeMessageService
.submitConsumeRequest(
pullResult.getMsgFoundList(),
processQueue,
pullRequest.getMessageQueue(),
dispathToConsume);
break;
}
}
}
};
}
}
下面的代码可以看到任务来自自己投到线程池执行。
public class ConsumeMessageConcurrentlyService implements ConsumeMessageService {
class ConsumeRequest implements Runnable {
@Override
public void run() {
// ...
status = listener.consumeMessage(Collections.unmodifiableList(msgs), context);
// ...
}
}
}
消费完后
public class ConsumeMessageConcurrentlyService implements ConsumeMessageService {
public void processConsumeResult(final ConsumeConcurrentlyStatus status, /** 其它参数 **/) {
// 从消息树中删除消息
long offset = consumeRequest.getProcessQueue().removeMessage(consumeRequest.getMsgs());
//假如某个队列在这个时候刚好给移除了,不提交进度,这可能会存在重复消费的情况,所有客户端还是要自己做幂等处理
if (offset >= 0 && !consumeRequest.getProcessQueue().isDropped()) {
this.defaultMQPushConsumerImpl.getOffsetStore()
.updateOffset(consumeRequest.getMessageQueue(), offset, true);
}
}
}
而有序消费就有趣多了,我们先思考一下,顺序消费是在线程池执行了,那么如何保证有序呢,加锁。假如在执行的时候刚好进行rebalance,移除了该队列的消费,那么有序消费就不能进行了,什么意思呢?假设 Consumer-1 消费者客户端一开始需要消费 3 个消费队列,这个时候又加入了 Consumer-2 消费者客户端,并且分配到了 MessageQueue-2 消费队列。当 Consumer-1 内部的均衡服务检测到当前消费队列需要移除 MessageQueue-2 队列,
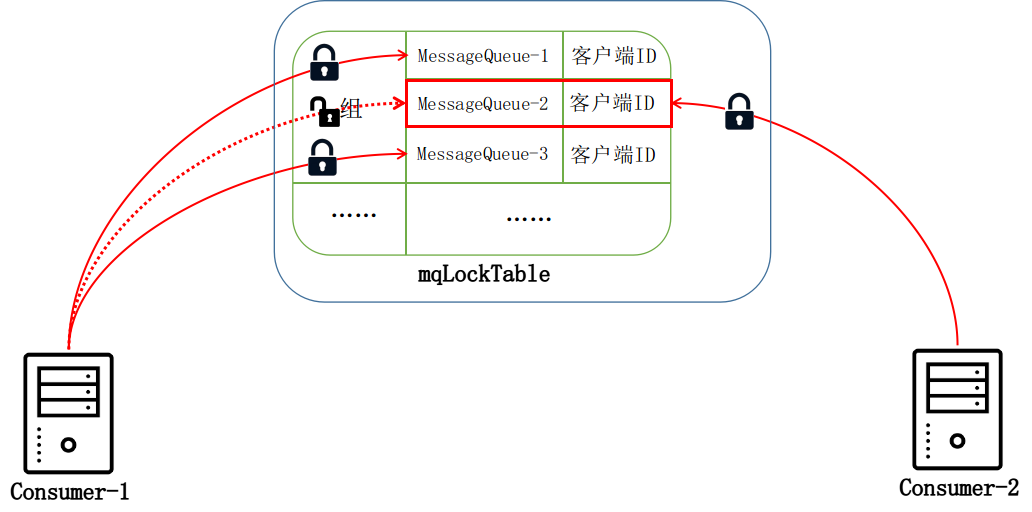
可以看到要是2号messagequeue 此时正在执行有序消费,然后却被另一个消费者进行消费,那么就不能保证有序消费了,于是在 broker 端应该也要有把锁,保证messagequeue在被有序消费时只有一个消费者持有,而上面的场景也一样,当消费者不再从messagequeue 消费的时候,也会向broker申请释放锁。
public abstract class RebalanceImpl {
private boolean updateProcessQueueTableInRebalance(final String topic,
final Set<MessageQueue> mqSet,
final boolean isOrder) {
while (it.hasNext()) {
// ...
if (mq.getTopic().equals(topic)) {
// 当前客户端不需要处理这个消息队列了
if (!mqSet.contains(mq)) {
pq.setDropped(true);
// 解锁
if (this.removeUnnecessaryMessageQueue(mq, pq)) {
// ...
}
}
// ...
}
}
}
}
class ConsumeRequest implements Runnable {
private final ProcessQueue processQueue;
private final MessageQueue messageQueue;
public ConsumeRequest(ProcessQueue processQueue, MessageQueue messageQueue) {
this.processQueue = processQueue;
this.messageQueue = messageQueue;
}
public ProcessQueue getProcessQueue() {
return processQueue;
}
public MessageQueue getMessageQueue() {
return messageQueue;
}
@Override
public void run() {
if (this.processQueue.isDropped()) {
log.warn("run, the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
return;
}
final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);
//获取锁,保证线程池内只有一个线程可以对该messageQueue 进行消费
synchronized (objLock) {
//广播消费 ,或是processQueue.isLocked()已经锁住了,或是锁没过期
//那么 processQueue.isLocked() 什么时候返回true 呢?ConsumeMessageOrderlyService内有个定时任务,周期去broker 中锁住这个 messagequeue
//上文已经讲了 processQueue 和 messagequeue 是一一对应的。
if (MessageModel.BROADCASTING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())
|| (this.processQueue.isLocked() && !this.processQueue.isLockExpired())) {
...
try {
//再次获取锁,这里的锁有什么用呢?我们通过查找processQueue上锁的地方,发现就是在 Rebalance重新分配消费队列的时候会上锁
//为了保证此刻不被其他消费者占用于是上锁
this.processQueue.getLockConsume().lock();
if (this.processQueue.isDropped()) {
log.warn("consumeMessage, the message queue not be able to consume, because it's dropped. {}",
this.messageQueue);
break;
}
//业务逻辑回调
status = messageListener.consumeMessage(Collections.unmodifiableList(msgs), context);
} catch (Throwable e) {
log.warn("consumeMessage exception: {} Group: {} Msgs: {} MQ: {}",
RemotingHelper.exceptionSimpleDesc(e),
ConsumeMessageOrderlyService.this.consumerGroup,
msgs,
messageQueue);
hasException = true;
} finally {
this.processQueue.getLockConsume().unlock();
}
.....
}
}
}
}
补充
service构建源码分析
Rocketmq 中创建一个service部分都继承了 ServiceThread,让我们开看一下源码
public abstract class ServiceThread implements Runnable {
private static final Logger log = LoggerFactory.getLogger(LoggerName.COMMON_LOGGER_NAME);
private static final long JOIN_TIME = 90 * 1000;
//保存了一个线程
protected final Thread thread;
/**
* 主要的阻塞方法是 await 方法,然后通过 countdown 来唤醒正在 await 的线程,每次多个线程调用进行 waitForRunning 的时候
* waitPoint 的 栅栏数量都会重置(阻塞,stop后被唤醒,又再次阻塞的情况)。
*/
protected final CountDownLatch2 waitPoint = new CountDownLatch2(1);
protected volatile AtomicBoolean hasNotified = new AtomicBoolean(false);
protected volatile boolean stopped = false;
//初始化的时候就创建一个线程
public ServiceThread() {
this.thread = new Thread(this, this.getServiceName());
}
public abstract String getServiceName();
public void start() {
this.thread.start();
}
public void shutdown() {
this.shutdown(false);
}
public void shutdown(final boolean interrupt) {
this.stopped = true;
log.info("shutdown thread " + this.getServiceName() + " interrupt " + interrupt);
if (hasNotified.compareAndSet(false, true)) {
waitPoint.countDown(); // notify
}
try {
if (interrupt) {
this.thread.interrupt();
}
long beginTime = System.currentTimeMillis();
if (!this.thread.isDaemon()) {
this.thread.join(this.getJointime());
}
long eclipseTime = System.currentTimeMillis() - beginTime;
log.info("join thread " + this.getServiceName() + " eclipse time(ms) " + eclipseTime + " "
+ this.getJointime());
} catch (InterruptedException e) {
log.error("Interrupted", e);
}
}
public long getJointime() {
return JOIN_TIME;
}
public void stop() {
this.stop(false);
}
public void stop(final boolean interrupt) {
this.stopped = true;
log.info("stop thread " + this.getServiceName() + " interrupt " + interrupt);
if (hasNotified.compareAndSet(false, true)) {
waitPoint.countDown(); // notify
}
if (interrupt) {
this.thread.interrupt();
}
}
public void makeStop() {
this.stopped = true;
log.info("makestop thread " + this.getServiceName());
}
public void wakeup() {
if (hasNotified.compareAndSet(false, true)) {
waitPoint.countDown(); // notify
}
}
/**
* 当只有一个线程的时候直接案通过CAS 成功后执行,多个线程则需要等待一段时间间隔后执行
*
* @param interval 等待的时间
*/
protected void waitForRunning(long interval) {
if (hasNotified.compareAndSet(true, false)) {
this.onWaitEnd();
return;
}
//entry to wait
waitPoint.reset();
try {
waitPoint.await(interval, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
log.error("Interrupted", e);
} finally {
hasNotified.set(false);
this.onWaitEnd();
}
}
protected void onWaitEnd() {
}
public boolean isStopped() {
return stopped;
}
}
可以知道他的构造创建了一个线程用于执行子类实现的run 方法,而自身的countDownLatch 和 Atomic原子类主要是用来应对多个线程同时操作的情况。
参考资料
- http://silence.work/2019/03/03/RocketMQ%20%E6%B6%88%E8%B4%B9%E6%B6%88%E6%81%AF%E8%BF%87%E7%A8%8B%E5%88%86%E6%9E%90/
- https://www.kunzhao.org/blog/2018/04/08/rocketmq-message-index-flow/
- https://cloud.tencent.com/developer/article/1554950
消息队列(六)--- RocketMQ-消息消费的更多相关文章
- 消息队列之事务消息,RocketMQ 和 Kafka 是如何做的?
每个时代,都不会亏待会学习的人. 大家好,我是 yes. 今天我们来谈一谈消息队列的事务消息,一说起事务相信大家都不陌生,脑海里蹦出来的就是 ACID. 通常我们理解的事务就是为了一些更新操作要么都成 ...
- 消费端如何保证消息队列MQ的有序消费
消息无序产生的原因 消息队列,既然是队列就能保证消息在进入队列,以及出队列的时候保证消息的有序性,显然这是在消息的生产端(Producer),但是往往在生产环境中有多个消息的消费端(Consumer) ...
- 消息队列之-RocketMQ入门
简介 RocketMQ是阿里开源的消息中间件,目前已经捐献个Apache基金会,它是由Java语言开发的,具备高吞吐量.高可用性.适合大规模分布式系统应用等特点,经历过双11的洗礼,实力不容小觑. 官 ...
- 分布式消息队列RocketMQ--事务消息--解决分布式事务
说到分布式事务,就会谈到那个经典的”账号转账”问题:2个账号,分布处于2个不同的DB,或者说2个不同的子系统里面,A要扣钱,B要加钱,如何保证原子性? 一般的思路都是通过消息中间件来实现“最终一致性” ...
- 几种MQ消息队列对比与消息队列之间的通信问题
消息队列 开发语言 协议支持 设计模式 持久化支持 事务支持 负载均衡支持 功能特点 缺点 RabbitMQ Erlang AMQP,XMPP,SMTP,STOMP 代理(Broker)模式(消息在发 ...
- 阿里消息队列中间件 RocketMQ 源码分析 —— Message 拉取与消费(上)
- [分布式学习]消息队列之rocketmq笔记
文档地址 RocketMQ架构 哔哩哔哩上的视频 mq有很多,近期买了<分布式消息中间件实践>这本书,学习关于mq的相关知识.mq大致有有4个功能: 异步处理.比如业务端需要给用户发送邮件 ...
- 消息队列之--RocketMQ
序言 资料 https://github.com/alibaba/RocketMQ http://rocketmq.apache.org/
- 消息队列中间件 RocketMQ 源码分析 —— Message 存储
- 阿里消息队列中间件 RocketMQ源码解析:Message发送&接收
随机推荐
- AVR单片机丢固件原因分析和解决方案
一.硬件方面 除了下面列举的方面,还需要评估下其他措施. 1.电源因素,禁干扰. 只要用廉价劣质的开关电源,不管哪个单片机,都存在EEPROM丢数据和单片机程序丢失的情况. 1.转接板走线,直接接到了 ...
- MariaDB 安装配置记录
1.集群搭建记录 iptables --append INPUT --protocol tcp \ --source 192.168.126.129 --jump ACCEPT iptables -- ...
- Learn from Niu
创新的源头来自于思考,尤其是深度思考: 1. 读博过程必然会经历痛苦,思考,深度思考这么一个过程,其中思考是最重要的,尤其是深度思考. 思考之后才是创新. 2. 借用其他的知识弥补这个领域的知识,不简 ...
- SSM项目使用junit单元测试时Mybaties通配符加载Mapper不能正常加载
个人博客 地址:http://www.wenhaofan.com/article/20181108104133 问题描述 项目使用maven build 以及tomcat run能够正常运行,但是使用 ...
- spring项目中 通过自定义applicationContext工具类获取到applicationContext上下文对象
spring项目在服务器启动的时候 spring容器中就已经被创建好了各种对象,在我们需要使用的时候可以进行调用. 工具类代码如下 import org.springframework.beans.B ...
- python之路之反射
这个是上两个的加强版
- java的jdk和jre区别
本文是本人随便总结的== 首先大概清楚个关系:jdk 包含 jre 包含 jvm 然后来看下,当我们配置完java运行环境的时候,是不是在java默认安装文件下发现jdk和jre两个包,然后jdk包里 ...
- spring(五):AOP
AOP(Aspect Oriented Programming) 面向切面编程,是一种编程范式,提供从另一个角度来考虑程序结构从而完善面向对象编程(OOP). 在进行OOP开发时,都是基于对组件(比如 ...
- PHP 源码 — intval 函数源码分析
PHP 源码 - intval 函数源码分析 文章来源: https://github.com/suhanyujie/learn-computer/ 作者:suhanyujie 基于PHP 7.3.3 ...
- [前端] html限制input输入数字和小数
限制input只能输入数字和小数 html代码 <input type="text" style="width:50px" name="widt ...