logstash output到kafka记录与总结( No entry found for connection 2)
简述
本文记录logstash的output配置为kafka的过程。这里是简单的例子,输入为stdin,本文主要目的是为了记录在这次配置过程中遇到的问题和解决的过程及总结。
关于kafka集群的搭建可以参考:https://www.cnblogs.com/ldsggv/p/11010497.html
一、logstash的conf文件配置
- input{
- stdin {}
- }
- output{
- stdout { codec => rubydebug }
- kafka {
- bootstrap_servers => "192.168.183.195:9092,192.168.183.194:9092,192.168.183.196:9092" #生产者
- codec => json
- topic_id => "kafkalogstash" #设置写入kafka的topic
- }
- }
这里配置完成之后,如果kafka集群没有问题,那么启动logstash,就可以测试发送消息了;
启动:
- bin/logstash -f logstash-kafka.conf
然后等待启动,
当提示:
- [INFO ] -- ::51.163 [[main]-pipeline-manager] AppInfoParser - Kafka version : 2.1.
- [INFO ] -- ::51.164 [[main]-pipeline-manager] AppInfoParser - Kafka commitId : eec43959745f444f
- [INFO ] -- ::51.342 [Converge PipelineAction::Create<main>] pipeline - Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0xa43495c sleep>"}
- The stdin plugin is now waiting for input:
- [INFO ] -- ::51.444 [Ruby--Thread-: /usr/share/logstash/lib/bootstrap/environment.rb:] agent - Pipelines running {:count=>, :running_pipelines=>[:main], :non_running_pipelines=>[]}
- [INFO ] -- ::51.708 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>}
此时启动成功
然后输入消息,正常的输出为下图,在kafka集群也能看到对应的topic信息,也能通过kafka-console-consumer.sh消费消息
- {
- "@timestamp" => --11T10::.615Z,
- "host" => "emr-worker-4.cluster-96380",
- "@version" => "",
- "message" => ""
- }
- [INFO ] -- ::10.642 [kafka-producer-network-thread | producer-] Metadata - Cluster ID: S8sBZgHPRJOv-nULn_bVGw
- {
- "@timestamp" => --11T11::.234Z,
- "host" => "emr-worker-4.cluster-96380",
- "@version" => "",
- "message" => ""
- }
上面是正确的输出结果,但是我从一开始是没有成功的,输出为:
- [INFO ] -- ::33.558 [kafka-producer-network-thread | producer-] Metadata - Cluster ID: S8sBZgHPRJOv-nULn_bVGw
- [ERROR] -- ::33.581 [kafka-producer-network-thread | producer-] Sender - [Producer clientId=producer-] Uncaught error in kafka producer I/O thread:
- java.lang.IllegalStateException: No entry found for connection
- at org.apache.kafka.clients.ClusterConnectionStates.nodeState(ClusterConnectionStates.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.ClusterConnectionStates.disconnected(ClusterConnectionStates.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.NetworkClient.initiateConnect(NetworkClient.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.NetworkClient.ready(NetworkClient.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.producer.internals.Sender.sendProducerData(Sender.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:) [kafka-clients-2.1..jar:?]
- at java.lang.Thread.run(Thread.java:) [?:1.8.0_201]
- [ERROR] -- ::33.586 [kafka-producer-network-thread | producer-] Sender - [Producer clientId=producer-] Uncaught error in kafka producer I/O thread:
- java.lang.IllegalStateException: No entry found for connection
- at org.apache.kafka.clients.ClusterConnectionStates.nodeState(ClusterConnectionStates.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.ClusterConnectionStates.disconnected(ClusterConnectionStates.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.NetworkClient.initiateConnect(NetworkClient.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.NetworkClient.ready(NetworkClient.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.producer.internals.Sender.sendProducerData(Sender.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:) [kafka-clients-2.1..jar:?]
- at java.lang.Thread.run(Thread.java:) [?:1.8.0_201]
- [ERROR] -- ::33.586 [kafka-producer-network-thread | producer-] Sender - [Producer clientId=producer-] Uncaught error in kafka producer I/O thread:
- java.lang.IllegalStateException: No entry found for connection
- at org.apache.kafka.clients.ClusterConnectionStates.nodeState(ClusterConnectionStates.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.ClusterConnectionStates.disconnected(ClusterConnectionStates.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.NetworkClient.initiateConnect(NetworkClient.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.NetworkClient.ready(NetworkClient.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.producer.internals.Sender.sendProducerData(Sender.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:) ~[kafka-clients-2.1..jar:?]
- at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:) [kafka-clients-2.1..jar:?]
- at java.lang.Thread.run(Thread.java:) [?:1.8.0_201]
问题分析:
根据提示可以看出是连接的问题,通过ping 和telnet都可以确定网络可以连通,那么问题出在哪里了啊?
解决:
首先上面的问题是出现在线上搭建的时候,之后我再本地实验没有任何问题,之后再线上的kafka集群内下载了logstahs,相同的配置也OK,
此时可以确认是我线上的logstash配置有问题,但是确认不到问题的位置
之后下载了kafka-client-2.1.0,在本地查看出现问题的代码位置,才确认问题;
根据上面的提示跟踪代码
代码是在 initiateConnect(NetworkClient.java:921) ~[kafka-clients-2.1.0.jar:?] 这里抛出了异常:
- private void initiateConnect(Node node, long now) {
- String nodeConnectionId = node.idString();
- try {
- this.connectionStates.connecting(nodeConnectionId, now, node.host(), clientDnsLookup);
- InetAddress address = this.connectionStates.currentAddress(nodeConnectionId);
- log.debug("Initiating connection to node {} using address {}", node, address);
- selector.connect(nodeConnectionId,
- new InetSocketAddress(address, node.port()),
- this.socketSendBuffer,
- this.socketReceiveBuffer);
- } catch (IOException e) {
- /* attempt failed, we'll try again after the backoff */
- connectionStates.disconnected(nodeConnectionId, now);
- /* maybe the problem is our metadata, update it */
- metadataUpdater.requestUpdate();
- log.warn("Error connecting to node {}", node, e);
- }
- }
进入selector.connect()方法中可以看到,根据注释很快就确定了原因:
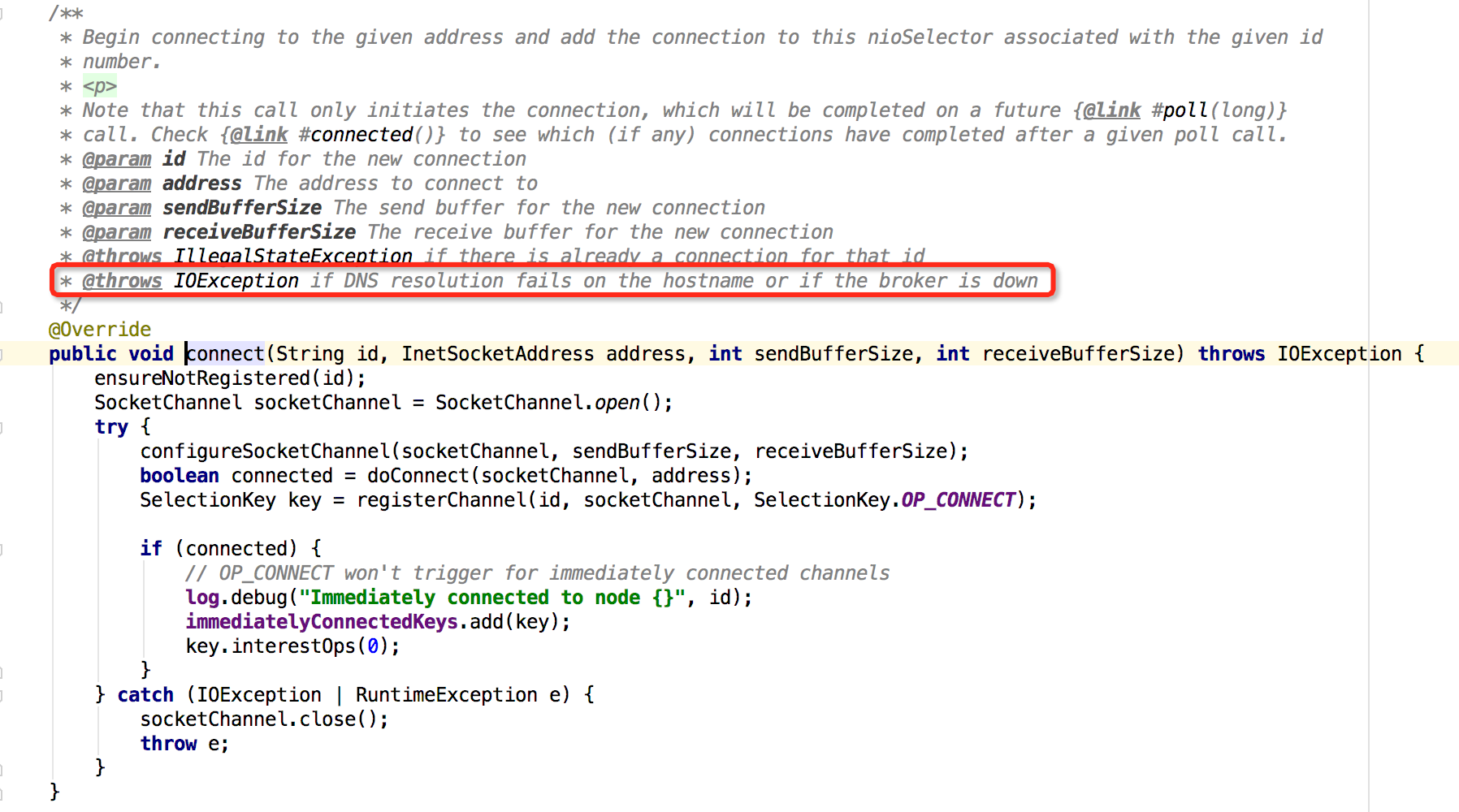
从图中的位置可以看到如果DNS在hostname解析失败,或者broker down掉,那么就会抛出这个异常,但是我的集群肯定没问题,那么就是DNS的问题,此时联想我本地的集群和线上的kafka集群都是由于都是集群都配置各自的/etc/hosts,但是线上logstash的机器在其他区域下,因此如果kafka的Producer通过dns解析本地路由然后和kafka集群通信的时候,如果本地解析不到就会报错,
Producer通过一个线程在一直跑,因为上面的错误日志是永远打印不完的,
因此解决的方法就是:
配置/etc/hosts;里面的内容是kafka集群的各个hostname和ip的对应关系,配置完成,重新启动logstash,运行正常。
总结:
在此疑惑的一点是,我明明配置了 bootstrap_servers => "192.168.183.195:9092,192.168.183.194:9092,192.168.183.196:9092" 那为什么还是dns解析不到地址,还是说producer在发型消息的时候没有使用我的配置?
为了进一步确认问题,我自己在本地跟踪和代码:
首先在Producer通过new KafkaProducer<>(props)方式创建的时候,会创建一个KafkaProducer实例,同时会newSender,Sender implements Runnable,之后会启动一个线程会在后台运行,将消息发送给kafka集群
因此主要看Sender的run方法就行,跟踪run方法有一个方法是sendProducerData(now);这个是发送数据,还有一个是client.poll(pollTimeout, now) 主要看这俩个方法就OK,
- private long sendProducerData(long now) {
- Cluster cluster = metadata.fetch();
- // get the list of partitions with data ready to send
- RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
- // if there are any partitions whose leaders are not known yet, force metadata update
- if (!result.unknownLeaderTopics.isEmpty()) {
- // The set of topics with unknown leader contains topics with leader election pending as well as
- // topics which may have expired. Add the topic again to metadata to ensure it is included
- // and request metadata update, since there are messages to send to the topic.
- for (String topic : result.unknownLeaderTopics)
- this.metadata.add(topic);
- log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}",
- result.unknownLeaderTopics);
- this.metadata.requestUpdate();
- }
- // remove any nodes we aren't ready to send to
- Iterator<Node> iter = result.readyNodes.iterator();
- long notReadyTimeout = Long.MAX_VALUE;
- while (iter.hasNext()) {
- Node node = iter.next();
- if (!this.client.ready(node, now)) {
- iter.remove();
- notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
- }
- }
- // create produce requests
- Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
- addToInflightBatches(batches);
- if (guaranteeMessageOrder) {
- // Mute all the partitions drained
- for (List<ProducerBatch> batchList : batches.values()) {
- for (ProducerBatch batch : batchList)
- this.accumulator.mutePartition(batch.topicPartition);
- }
- }
- accumulator.resetNextBatchExpiryTime();
- List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);
- List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);
- expiredBatches.addAll(expiredInflightBatches);
- // Reset the producer id if an expired batch has previously been sent to the broker. Also update the metrics
- // for expired batches. see the documentation of @TransactionState.resetProducerId to understand why
- // we need to reset the producer id here.
- if (!expiredBatches.isEmpty())
- log.trace("Expired {} batches in accumulator", expiredBatches.size());
- for (ProducerBatch expiredBatch : expiredBatches) {
- String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " + expiredBatch.topicPartition
- + ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";
- failBatch(expiredBatch, -, NO_TIMESTAMP, new TimeoutException(errorMessage), false);
- if (transactionManager != null && expiredBatch.inRetry()) {
- // This ensures that no new batches are drained until the current in flight batches are fully resolved.
- transactionManager.markSequenceUnresolved(expiredBatch.topicPartition);
- }
- }
- sensors.updateProduceRequestMetrics(batches);
- // If we have any nodes that are ready to send + have sendable data, poll with 0 timeout so this can immediately
- // loop and try sending more data. Otherwise, the timeout will be the smaller value between next batch expiry
- // time, and the delay time for checking data availability. Note that the nodes may have data that isn't yet
- // sendable due to lingering, backing off, etc. This specifically does not include nodes with sendable data
- // that aren't ready to send since they would cause busy looping.
- long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
- pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);
- pollTimeout = Math.max(pollTimeout, );
- if (!result.readyNodes.isEmpty()) {
- log.trace("Nodes with data ready to send: {}", result.readyNodes);
- // if some partitions are already ready to be sent, the select time would be 0;
- // otherwise if some partition already has some data accumulated but not ready yet,
- // the select time will be the time difference between now and its linger expiry time;
- // otherwise the select time will be the time difference between now and the metadata expiry time;
- pollTimeout = ;
- }
- sendProduceRequests(batches, now);
- return pollTimeout;
- }
- public List<ClientResponse> poll(long timeout, long now) {
- ensureActive();
- if (!abortedSends.isEmpty()) {
- // If there are aborted sends because of unsupported version exceptions or disconnects,
- // handle them immediately without waiting for Selector#poll.
- List<ClientResponse> responses = new ArrayList<>();
- handleAbortedSends(responses);
- completeResponses(responses);
- return responses;
- }
- long metadataTimeout = metadataUpdater.maybeUpdate(now);
- try {
- this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));
- } catch (IOException e) {
- log.error("Unexpected error during I/O", e);
- }
- // process completed actions
- long updatedNow = this.time.milliseconds();
- List<ClientResponse> responses = new ArrayList<>();
- handleCompletedSends(responses, updatedNow);
- handleCompletedReceives(responses, updatedNow);
- handleDisconnections(responses, updatedNow);
- handleConnections();
- handleInitiateApiVersionRequests(updatedNow);
- handleTimedOutRequests(responses, updatedNow);
- completeResponses(responses);
- return responses;
- }
从上面代码看poll方法里面会更新一次kafka的元数据,在更新完成之后,元数据里面的node信息,就不在是自己配置的bootstrap_servers ,而是集群node的信息,此时,再去运行sendProducerData的方法的时候在这个方法的24行,进入ready方法,之后执行initiateConnect方法,也就是最开始出现问题的方法,在这里的node信息是集群里面的leader信息,sender发送信息也只会和leader进行交流,此时会根据配置的hostname解析ip,如果运行producer的机器没有配置,那就会出现上面的问题
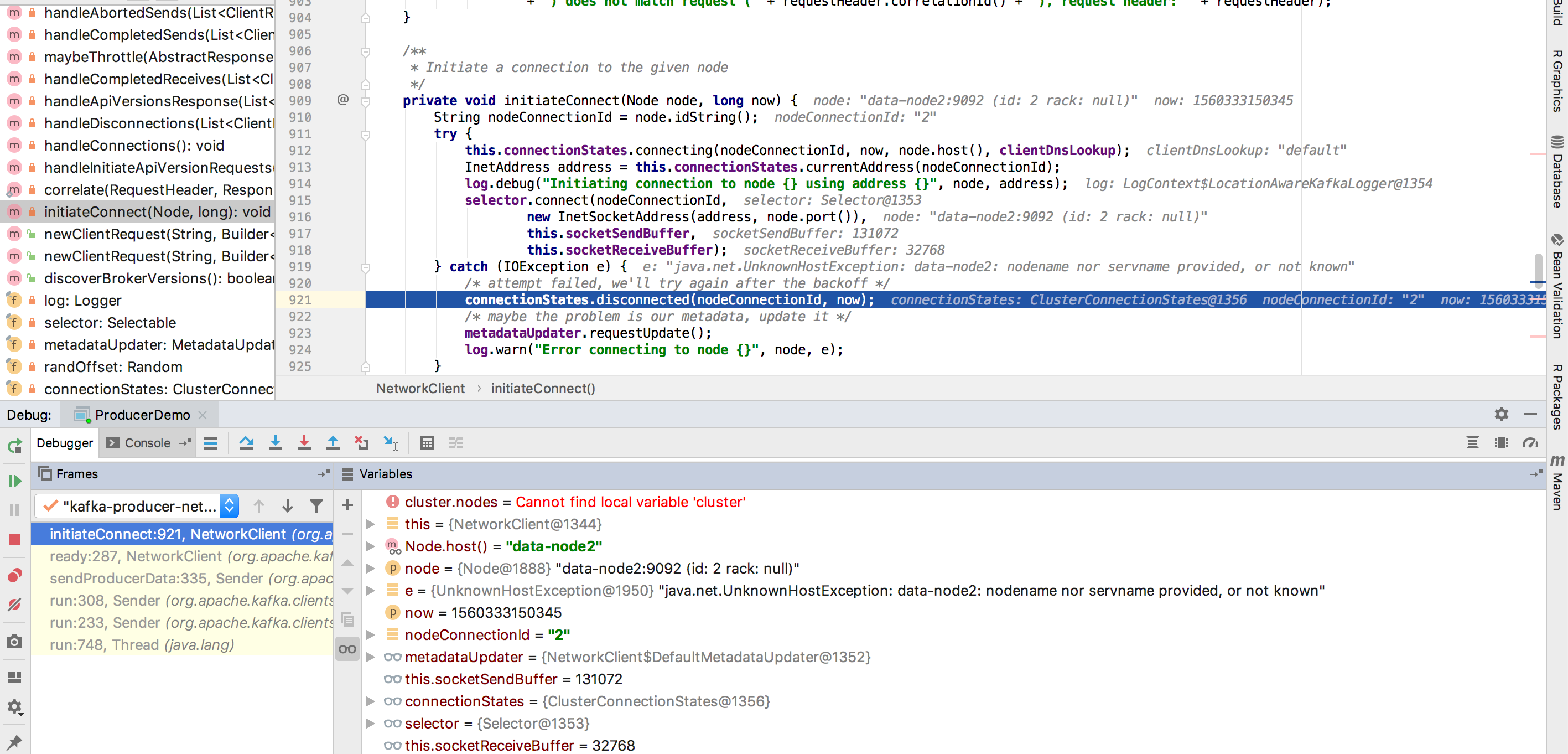
从上面的debug截图可以看出来,node确实从kafka集群同步的node信息,由于kafka集群对外的都是leader,所以producer不会使用配置的bootstrap_servers,而是通过它发现集群的信息,然后根据集群的信息,来确定和哪个node通信。其实producer和sender的创建很复杂,这里之后捡了和这个问题相关的说了,有兴趣的同学可以跟一根源码,会很有收获哟
问题到这里就解决了,究其原因还是因为配置的问题导致的,但是经过这个问题,查看kafka client的代码,对kafka的理解更深了一步。算是因祸得福吧《^_^》
logstash output到kafka记录与总结( No entry found for connection 2)的更多相关文章
- Filebeat之input和output(包含Elasticsearch Output 、Logstash Output、 Redis Output、 File Output和 Console Output)
前提博客 https://i.cnblogs.com/posts?categoryid=972313 Filebeat啊,根据input来监控数据,根据output来使用数据!!! Filebeat的 ...
- logstash output kafka ip 设置的坑
原设置 output { kafka { acks => " enable_metric => false codec => "json" topic_ ...
- logstash处理文件进度记录机制
假如使用如下配置处理日志 input { file { path => "/home/vagrant/logstash/logstash-2.2.2/dbpool-logs/dev/c ...
- logstash日志写入kafka
安装kafka curl -L -O https://mirrors.cnnic.cn/apache/kafka/0.10.2.1/kafka_2.10-0.10.2.1.tgz tar xf kaf ...
- (五)ELK Logstash output
# 输出插件将数据发送到一个特定的目的地, 除了elasticsearch还有好多可输出的地方, 例如file, csv, mongodb, redis, syslog等 output { if [t ...
- Kafka记录-Kafka简介与单机部署测试
1.Kafka简介 kafka-分布式发布-订阅消息系统,开发语言-Scala,协议-仿AMQP,不支持事务,支持集群,支持负载均衡,支持zk动态扩容 2.Kafka的架构组件 1.话题(Topic) ...
- Kafka记录Nginx的POST请求
最近因为工作原因,需要将Nignx的POST请求数据实时采集到Kafka中.最容易的想到的方案就是通过"tail -f" Nginx的log日志到Kafka的Broker集群中,但 ...
- logstash output时区差8个小时
logstash版本6.3.2,解决方式如下,不需要修改源码: input { redis { host => "127.0.0.1" port => " p ...
- spark streaming 对接kafka记录
spark streaming 对接kafka 有两种方式: 参考: http://group.jobbole.com/15559/ http://blog.csdn.net/kwu_ganymede ...
随机推荐
- linux - mysql:安装mysql
安装环境 系统是 centos6.5 1.下载 下载地址:http://dev.mysql.com/downloads/mysql/5.6.html#downloads 下载版本:我这里选择的5.6. ...
- Hive学习笔记二
目录 Hive常见属性配置 将本地库文件导入Hive案例 Hive常用交互命令 Hive其他命令操作 参数配置方式 Hive常见属性配置 1.Hive数据仓库位置配置 1)Default数据仓库的最原 ...
- AntDesign(React)学习-2 第一个页面
1.前面创建了第一个项目jgdemo,结构如下,使用TypeScript. 2.yarn start启动项目 3.点击GettingStarted是umi的官方网站 https://umijs.org ...
- openstack入门及应用
一.OpenStack云计算的介绍 (一)云计算的服务类型 IAAS:基础设施即服务,如:云主机 PAAS:平台即服务,如:docker SAAS:软件即服务,如:购买企业邮箱,CDN 传统IT IA ...
- Python模块/包/库安装几种方法(转载)
一.方法1: 单文件模块直接把文件拷贝到 $python_dir/Lib 二.方法2: 多文件模块,带setup.py 下载模块包(压缩文件zip或tar.gz),进行解压,CMD->cd进入模 ...
- MySQL | 查看log日志
1. 进入mysql mysql -u用户名 -p密码 2. 开启日志 et global general_log=on: 3. 查看mysql日志文件的路径 show variables like ...
- python 自动化实现定时发送html报告到邮箱
# coding =utf-8 import os import unittest import time import datetime import smtplib from email.mime ...
- 集成Log4Net到自己的Unity工程
需要使用的插件库说明: Loxodon Framework Log4NetVersion: 1.0.0© 2016, Clark Yang=============================== ...
- Python爬取ithome的一所有新闻标题评论数及其他一些信息并存入Excel中。
# coding=utf-8 import numpy as np import pandas as pd import sys from selenium import webdriver impo ...
- JS高级---bind方法的使用
bind方法的使用 //通过对象,调用方法,产生随机数 function ShowRandom() { //1-10的随机数 this.number = parseInt(Math.random() ...