Fluent_Python_Part2数据结构,03-dict-set,字典和集合
字典和集合
dict和set都基于hash table实现
1. 大纲:
- 常见的字典方法
- 如何处理查找不到的键
- 标准库中dict类型的变种
- set和fronzenset类型
- Hash table的工作原理
- Hash table带来的潜在影响
字典dict
2. 泛映射类型
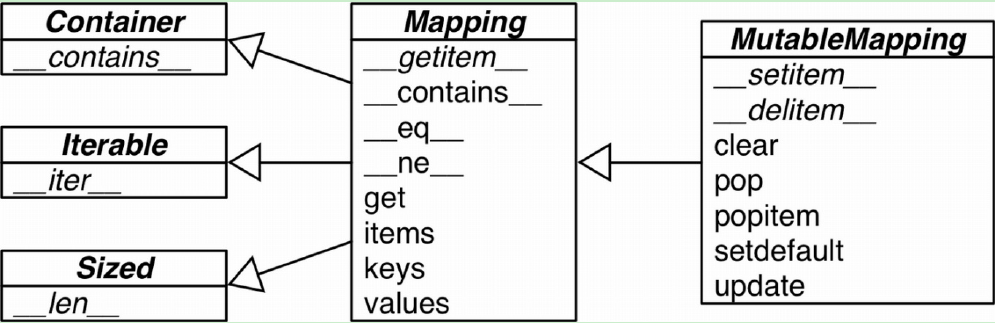
在collections.abc中,有Mapping和MutableMapping,两个抽象基类,主要作用是作为形式化文档,定义了映射类型的基本API。
my_dict = {}
#判定数据是不是广义上的映射类型
#不用type的原因是这个参数可能不是dict
isinstance(my_dict, abc.Mapping)
标准库里的映射类型都是基于dict扩展的,因此它们有个共同的限制,只有hashable的数据类型才能作为key(保持键唯一),值没有这个限制。
https://docs.python.org/3/glossary.html#term-hashable
Hashable对象要实现__hash__()和__eq__()方法
一般来说不可变类型都是可hashtable的,但是有特例,dict虽然是不可变类型,但它里面的元素可能是可变的类型。
tt = (1, 2, (30, 40))
hash(tt)
#Error, dict里面的list不是可散列的类型
t1 = (1, 2, [30, 40])
hash(t1)
tf = (1, 2, frozenset([30, 40]))
hash(tf)
创建字典的不同方式
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> a == b == c == d == e
True
3. 字典推导式(dict comprehension, dictcomp)
列表推导式用[],元组推导式用(),字典推导式用{}
dictcomp可以从任何以key-value作为元素的可迭代元素中构建出字典
DIAL_CODES = [
(86, 'China'),
(91, 'India'),
(1, 'United States'),
(62, 'Indonesia'),
(55, 'Brazil'),
(92, 'Pakistan'),
(880, 'Bangladesh'),
(234, 'Nigeria'),
(7, 'Russia'),
(81, 'Japan'),
]
#dictcomp, {}
country_code = {country : code for code, country in DIAL_CODES}
print(country_code)
#以大写打印code < 65的国家名
temp = {code : country.upper() for country, code in country_code.items()}
print(temp)
4. 常见的映射类型方法
中文电子书P137,dict、collections.defaultdict和collections.OrderedDict的常用方法
5. 用setdefault处理找不到的键(key)
d[key]找不到时会抛出KeyError异常,可以用d.get(key, default)来代替,给找不到的key一个默认的返回值。但是要更新某个key对应的value时,用__getitem__和get都是不自然,而且效率低。所以d.get并不是处理找不到的key的最好方法
中文电子书P139,用setdefault处理
dict1 = {'name':'Allen', 'age':18}
#setdefault方法如果有key-value就不动,没有就添加。这个方法有返回值
print(dict1)
dict1.setdefault('age', 30)
dict1.setdefault('xxx', 22)
print(dict1)
6. 用defaultdict处理找不到的键 未搞懂
7. 用__missing__处理找不到的键
不只字典,所有映射类型在处理找不到的键的时候,都会牵扯到__missing__方法。
That is, 如果一个类继承了dict,然后这个继承类提供了__missing__方法,那么在__getitem__碰到找不到的键的时候,Python就会自动调用它,而不是抛出KeyError异常。
Note:missing__方法只会被__getitem__调用,例如d[key]。另外对get或__contains(in运算符用到这个方法)没有影响。
像 k in my_dict.keys()在Python3中效率是很高的,因为dict.keys()返回的是dictionary-view-objects。而在Python2中,dict.keys()返回的是一个列表,k in my_list操作需要扫描整个列表。
8. 字典的变种
不同的映射类型:
- collections.OrderedDict: 在添加键的时候会保持顺序。
- collections.ChainMap:可以容纳数个不同的映射对象,在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找。这个特性在给有嵌套作用域的语言做解释器时非常有用,可以用一个映射对象来代表一个作用域的上下文。
- collections.Counter这个映射类型可以给hashable的对象计数,或者是当作多重集来用。Counter实现+和-运算符来合并记录,还有most_common([n])会按照次序返回映射里最常见的n个键和它们的计数。
from collections import Counter
str1 = 'aabbccdd'
counter_str = Counter(str1)
print(type(counter_str))
print(counter_str)
counter_str.update('aabbccdd')
print(counter_str)
print(counter_str.most_common(3))
4.collections.UserDict,这个类把标准dict用纯Python实现了一遍。让用户继承来写子类的。
9. 自定义映射类型
所有映射类型都是基于dict的。自定义映射类型,以UserDict为基类,比普通的dict为基类方便。
因为如果从dict继承,dict有时候在某些方法上走一些捷径,导致子类要重写这些方法,但UserDict不会有这些问题。具体看中文电子书12.1节。
Note:UserDict并不是dict的子类,是MutableMapping的子类,但是其中有一个叫data的属性是dict的实例,这个是UserDict存储数据的地方。好处是UserDict的子类实现__setitem__和__contains__时代码更简洁。
例子1. 添加、更新还是查询操作,StrKeyDict都会把非字符串的键转换为字符串
import collections
class StrKeyDict(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains(self, key):
return str(key) in self.data
def __setitem__(self, key, value):
self.data[str(key)] = value
StrKeyDict里剩下的映射类型的方法都是从UserDict、MutableMapping和Mapping这些超类继承而来。特别是Mapping这个ABC(抽象基类),以文档化的形式提供了实用的API。以后两个方法值得注意:
- MutableMapping.update。可以直接利用,可以用在__init__里。原理是self[key] = value来添加新值,所以它是使用__setitem__方法。
- Mapping.get。
10. 不可变映射类型
之前有不可变的序列类型,但是在标准库中没有不可变的字典类型,但是可以用替身来代替。
字典是可以动态修改的,但不希望用户修改,所以需要一个只读的映射视图。types.MappingProxyType返回一个只读的映射视图。
from types import MappingProxyType
d = {'1' : 'A'}
d_proxy = MappingProxyType(d)
print('d_proxy:', d_proxy)
#MappingProxyType只读,没有赋值操作
#d_proxy[2] = 'x'
d[2] = 'x'
#MappingProxyType是动态的,也就是对d所做的任何改动都会反馈到它上面。
print('d_proxy:', d_proxy)
集合set
11. 集合
set的本质是许多唯一对象的聚集。因此,集合可以去重
l1 = ['spam', 'spam', 'eggs', 'eggs']
s1 = set(l1)
print(s1)
print(list(s1))
set中的元素必须是hashable(保证唯一),但set本身是不可散列的,但是frozenset是hashable的。因此可以创建一个包含不同frozenset的set。set里面的元素是hashable的,所以搜索速度极快。
set还有很多基础的中缀运算符,a | b并集,a & b交集,a - b差集。可以省去不必要的循环和逻辑操作。
例子1. needles元素在haystack里出现的次数,两个变量都是set类型
found = len(needles & haystack)
例子2. needles和haystack是任何两个可迭代对象
found = 0
for n in needles:
if n in haystack:
found += 1
例子3. 转换为set再运算
found = len(set(needles) & set(haystack))
#另一种写法
found = len(set(needles).intersection(haystack))
12. 集合字面量
{1}, {1, 2}是集合的字面量,set()是空集, {}是空字典。
字面量{1,2,3}比构造方法(set([1,2,3]))更快。集合字面量,Python会利用BUILD_SET的字节码来创建集合。
from dis import dis
dis('{1}')
dis('set([1])')
创建frozenset只能用构造方法
frozenset(range(10))
13. 集合推导式(set comprehension, setcomps)
列表推导式用[], 元组推导式用(), 字典和集合推导式用{}
例子1. 用setcomps创建一个Latin-1字符集合
#获取字符的名字name
from unicodedata import name
#把编码32~255之间的字符的名字里有"SIGN"单词挑出来,放到一个集合里面
s1 = {chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i),'')}
print(s1)
print(name('+',''))
14. 集合的操作
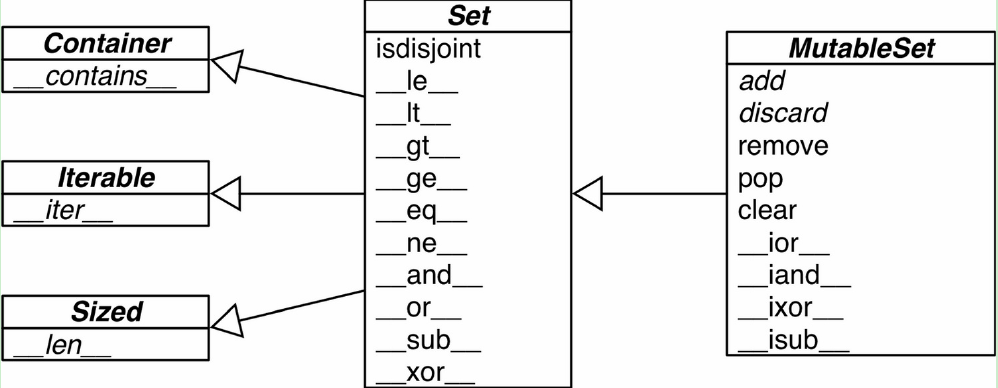
collections.abc(抽象基类),提供API信息。
集合的数学运算: 中文电子书P161
集合的比较运算: 中文电子书P162
集合的其他方法: 中文电子书P163
15. dict和set的原理
dict和set都是借助hash table来实现功能的。例如in运算,所以速度快。
Note:列表的背后没有用散列表来支持in运算符,每次搜索都是顺序遍历。
16. 字典中的散列表
如果对象A == 对象B,那么hash(A) == hash(B)。调用hash(),实际上运行的是__hash__。
dict取值原理采用散列表算法,中文电子书P169
17. 使用散列表实现dict带来的优势和限制
中文电子书P171
- key必须是hashable的
- 字典在内存上的开销巨大,因为hash table是稀疏数组
- key查询很快,因为hash table是classic的空间换时间
- key的顺序取决于添加顺序
- 往字典里添加新键可能会改变已有键的顺序,不要对字典同时进行迭代和修改。因为Python解释器可能做出为字典扩容的决定,把旧表复制到一个新的更大的散列表时,可能发生散列冲突。
6. .keys()、.items()、.values()返回的是字典的视图,动态反馈字典的变化。
18. 使用散列表实现set带来的优势和限制
set和frozenset的实现也依赖散列表,但在它们的hash table存放的只有元素的引用(就像在字典里只存key而没有相应的值)。
Note:在set加入Python前之前,我们都是把字典加上无意义的value当集合使用。
和散列表实现dict的优点和缺点类似:
- 集合里的元素必须是可散列的。
- 集合很消耗内存。
- 可以很高效地判断元素是否存在于某个集合中。
- 元素的次序取决于被添加到集合里的次序。
- 往集合里添加元素,可能会改变集合里已有元素的次序。
Fluent_Python_Part2数据结构,03-dict-set,字典和集合的更多相关文章
- Python数据结构之三——dict(字典)
Python版本:3.6.2 操作系统:Windows 作者:SmallWZQ 知识源于生活.Python也是如此. 提到字典,我首先想到的是数学大师--高斯. 为何想起他呢?这主要是因为高斯算法 ...
- Python中list(列表)、dict(字典)、tuple(元组)、set(集合)详细介绍
更新时间:2019.08.10 更新内容: "2.14加入sorted()函数" "2.3"加入一种删除元素的方法 "二.字典"新增1.5, ...
- 06-Python元组,列表,字典,集合数据结构
一.简介 数据结构是我们用来处理一些数据的结构,用来存储一系列的相关数据. 在python中,有列表,元组,字典和集合四种内建的数据结构. 二.列表 用于存储任意数目.任意类型的数据集合.列表是内置可 ...
- 《流畅的Python》第二部分 数据结构 【序列构成的数组】【字典和集合】【文本和字节序列】
第二部分 数据结构 第2章 序列构成的数组 内置序列类型 序列类型 序列 特点 容器序列 list.tuple.collections.deque - 能存放不同类型的数据:- 存放的是任意类型的对象 ...
- python数据结构-如何在列表、字典、集合中根据条件筛选数据
如何在列表.字典.集合中根据条件筛选数据 问题举例: 过滤列表[1, 2, 5, -1, 9, 10]中的负数 筛选字典{“zhangsan”:97, "lisi":80, &qu ...
- 『Python CoolBook』数据结构和算法_字典比较&字典和集合
一.字典元素排序 dict.keys(),dict.values(),dict.items() 结合max.min.sorted.zip进行排序是个很好的办法,另外注意不使用zip时,字典的lambd ...
- Python黑帽编程2.3 字符串、列表、元组、字典和集合
Python黑帽编程2.3 字符串.列表.元组.字典和集合 本节要介绍的是Python里面常用的几种数据结构.通常情况下,声明一个变量只保存一个值是远远不够的,我们需要将一组或多组数据进行存储.查询 ...
- 数据结构中的列表、元组、字典、集合 ,深浅copy
数据结构:数据结构是计算机存储数据和组织数据的方式.数据结构是指相互之间存在一种或多种特定关系的数据元素的集合.在python中主要的数据类型统称为容器. 而序列(如列表.元组).映射(如字典).集合 ...
- python大法好——字典、集合
字典 前面我们说过列表,它适合于将值组织到一个结构中并且通过编号对其进行引用.字典则是通过名字来引用值的数据结构,并且把这种数据结构称为映射,字典中的值没有特殊的顺序,都存储在一个特定的键(key)下 ...
随机推荐
- Docker+JMeter单机版+Nginx
基于JMeter5.1.1+Nginx1.12.2JMeter发起压测 Nginx作为文件服务器 一.目录结构: Dockerfile文件: FROM ubuntu:18.04# 基础镜像 MAIN ...
- Java-类的生命周期浅析
简述:Java虚拟机为Java程序提供运行时环境,其中一项重要的任务就是管理类和对象的生命周期.类的生命周期.类的生命周期从类被加载.连接和初始化开始,到类被卸载结束.当类处于生命周期中时,它的二级制 ...
- STM32F103之DMA学习记录
/================翻译STM32F103开发手册DMA章节===========================/ 13 DMA(Direct memory access) 13.1 ...
- 使用命令行生成动态库dll
1.安装开发工具,比如visual studio或者mingw等等.下面以visual studio编译器cl作为讲解. 2.导出dll中的函数基本使用两种方式,可以使用关键字__declspec(d ...
- C语言是菜鸟和大神的分水岭
作为一门古老的编程语言,C语言已经坚挺了好几十年了,初学者从C语言入门,大学将C语言视为基础课程.不管别人如何抨击,如何唱衰,C语言就是屹立不倒:Java.C#.Python.PHP.Perl 等都有 ...
- 【New】简•导航 正式上线
[New]简•导航 正式上线 一个简单的导航 链接:http://huangenet.gitee.io/simple/ 欢迎访问⊙ω⊙ 代码托管在码云,访问速度更快哦!
- C#堆和栈的入门理解
声明:以下内容从网络整理,非原创,适当待入个人理解. 解释1.栈是编译期间就分配好的内存空间,因此你的代码中必须就栈的大小有明确的定义:堆是程序运行期间动态分配的内存空间,你可以根据程序的运行情况确定 ...
- opencv:全局阈值
图像的二值化分割,最重要的就是计算阈值 阈值的计算方法很多,基本分为两类,全局阈值与自适应阈值 OTSU.Triangle #include <opencv2/opencv.hpp> #i ...
- Bugku-CTF加密篇之来自宇宙的信号(银河战队出击)
来自宇宙的信号 银河战队出击 flag格式 flag{字母小写}
- bugku 变量1
变量1 题目信息 flag In the variable ! <?php error_reporting(0); include "flag1.php"; highligh ...