Python爬虫学习教程:天猫商品数据爬虫
天猫商品数据爬虫使用教程
- 下载chrome浏览器
- 查看chrome浏览器的版本号,下载对应版本号的chromedriver驱动
- pip安装下列包
- pip install selenium
- pip install pyquery
- 登录微博,并通过微博绑定淘宝账号密码
- 在main中填写chromedriver的绝对路径
- 在main中填写微博账号密码
#改成你的chromedriver的完整路径地址
chromedriver_path = "/Users/bird/Desktop/chromedriver.exe"
#改成你的微博账号
weibo_username = "改成你的微博账号"
#改成你的微博密码
weibo_password = "改成你的微博密码"
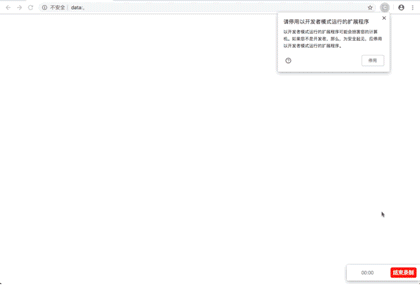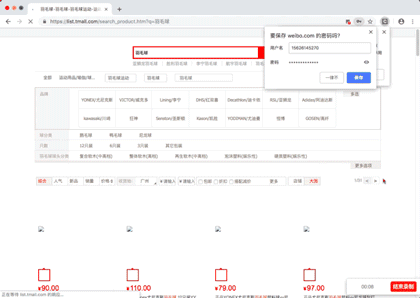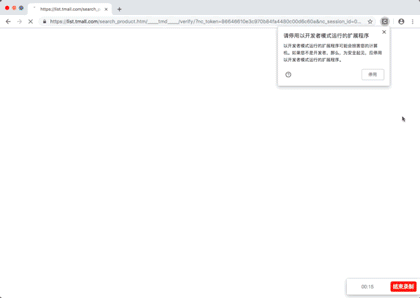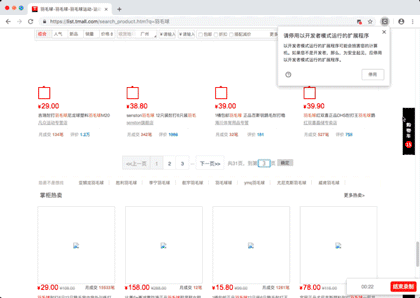
效果演示图片

项目源码
# -*- coding: utf-8 -*- from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver import ActionChains
from pyquery import PyQuery as pq
from time import sleep #定义一个taobao类
class taobao_infos: #对象初始化
def __init__(self):
url = 'https://login.taobao.com/member/login.jhtml'
self.url = url options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加载图片,加快访问速度
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium self.browser = webdriver.Chrome(executable_path=chromedriver_path, options=options)
self.wait = WebDriverWait(self.browser, 10) #超时时长为10s #延时操作,并可选择是否弹出窗口提示
def sleep_and_alert(self,sec,message,is_alert): for second in range(sec):
if(is_alert):
alert = "alert(\"" + message + ":" + str(sec - second) + "秒\")"
self.browser.execute_script(alert)
al = self.browser.switch_to.alert
sleep(1)
al.accept()
else:
sleep(1) #登录淘宝
def login(self): # 打开网页
self.browser.get(self.url) # 自适应等待,点击密码登录选项
self.browser.implicitly_wait(30) #智能等待,直到网页加载完毕,最长等待时间为30s
self.browser.find_element_by_xpath('//*[@class="forget-pwd J_Quick2Static"]').click() # 自适应等待,点击微博登录宣传
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="weibo-login"]').click() # 自适应等待,输入微博账号
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('username').send_keys(weibo_username) # 自适应等待,输入微博密码
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('password').send_keys(weibo_password) # 自适应等待,点击确认登录按钮
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="btn_tip"]/a/span').click() # 直到获取到淘宝会员昵称才能确定是登录成功
taobao_name = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.site-nav-bd > ul.site-nav-bd-l > li#J_SiteNavLogin > div.site-nav-menu-hd > div.site-nav-user > a.site-nav-login-info-nick ')))
# 输出淘宝昵称
print(taobao_name.text) # 获取天猫商品总共的页数
def search_toal_page(self): # 等待本页面全部天猫商品数据加载完毕
good_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#J_ItemList > div.product > div.product-iWrap'))) #获取天猫商品总共页数
number_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.ui-page > div.ui-page-wrap > b.ui-page-skip > form')))
page_total = number_total.text.replace("共","").replace("页,到第页 确定","").replace(",","") return page_total # 翻页操作
def next_page(self, page_number):
# 等待该页面input输入框加载完毕
input = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.ui-page > div.ui-page-wrap > b.ui-page-skip > form > input.ui-page-skipTo'))) # 等待该页面的确定按钮加载完毕
submit = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.ui-page > div.ui-page-wrap > b.ui-page-skip > form > button.ui-btn-s'))) # 清除里面的数字
input.clear() # 重新输入数字
input.send_keys(page_number) # 强制延迟1秒,防止被识别成机器人
sleep(1) # 点击确定按钮
submit.click() # 模拟向下滑动浏览
def swipe_down(self,second):
for i in range(int(second/0.1)):
js = "var q=document.documentElement.scrollTop=" + str(300+200*i)
self.browser.execute_script(js)
sleep(0.1)
js = "var q=document.documentElement.scrollTop=100000"
self.browser.execute_script(js)
sleep(0.2) # 爬取天猫商品数据
def crawl_good_data(self): # 对天猫商品数据进行爬虫
self.browser.get("https://list.tmall.com/search_product.htm?q=羽毛球")
err1 = self.browser.find_element_by_xpath("//*[@id='content']/div/div[2]").text
err1 = err1[:5]
if(err1 == "喵~没找到"):
print("找不到您要的")
return
try:
self.browser.find_element_by_xpath("//*[@id='J_ComboRec']/div[1]")
err2 = self.browser.find_element_by_xpath("//*[@id='J_ComboRec']/div[1]").text
#print(err2) err2 = err2[:5] if(err2 == "我们还为您"):
print("您要查询的商品书目太少了")
return
except:
print("可以爬取这些信息")
# 获取天猫商品总共的页数
page_total = self.search_toal_page()
print("总共页数" + page_total) # 遍历所有页数
for page in range(2,int(page_total)): # 等待该页面全部商品数据加载完毕
good_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#J_ItemList > div.product > div.product-iWrap'))) # 等待该页面input输入框加载完毕
input = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.ui-page > div.ui-page-wrap > b.ui-page-skip > form > input.ui-page-skipTo'))) # 获取当前页
now_page = input.get_attribute('value')
print("当前页数" + now_page + ",总共页数" + page_total) # 获取本页面源代码
html = self.browser.page_source # pq模块解析网页源代码
doc = pq(html) # 存储天猫商品数据
good_items = doc('#J_ItemList .product').items() # 遍历该页的所有商品
for item in good_items:
good_title = item.find('.productTitle').text().replace('\n',"").replace('\r',"")
good_status = item.find('.productStatus').text().replace(" ","").replace("笔","").replace('\n',"").replace('\r',"")
good_price = item.find('.productPrice').text().replace("¥", "").replace(" ", "").replace('\n', "").replace('\r', "")
good_url = item.find('.productImg').attr('href')
print(good_title + " " + good_status + " " + good_price + " " + good_url + '\n') # 精髓之处,大部分人被检测为机器人就是因为进一步模拟人工操作
# 模拟人工向下浏览商品,即进行模拟下滑操作,防止被识别出是机器人
self.swipe_down(2) # 翻页,下一页
self.next_page(page) # 等待滑动验证码出现,超时时间为5秒,每0.5秒检查一次
# 大部分情况不会出现滑动验证码,所以如果有需要可以注释掉下面的代码
# sleep(5)
WebDriverWait(self.browser, 5, 0.5).until(EC.presence_of_element_located((By.ID, "nc_1_n1z"))) #等待滑动拖动控件出现
try:
swipe_button = self.browser.find_element_by_id('nc_1_n1z') #获取滑动拖动控件 #模拟拽托
action = ActionChains(self.browser) # 实例化一个action对象
action.click_and_hold(swipe_button).perform() # perform()用来执行ActionChains中存储的行为
action.reset_actions()
action.move_by_offset(580, 0).perform() # 移动滑块 except Exception as e:
print ('get button failed: ', e) if __name__ == "__main__": # 使用之前请先查看当前目录下的使用说明文件README.MD
# 使用之前请先查看当前目录下的使用说明文件README.MD
# 使用之前请先查看当前目录下的使用说明文件README.MD chromedriver_path = "/Users/bird/Desktop/chromedriver.exe" #改成你的chromedriver的完整路径地址
weibo_username = "改成你的微博账号" #改成你的微博账号
weibo_password = "改成你的微博密码" #改成你的微博密码 a = taobao_infos()
a.login() #登录
a.crawl_good_data() #爬取天猫商品数据
平台网站经常变动,可以做参考
很多初学者,对Python的概念都是模糊不清的,Python能做什么,学的时候,该按照什么线路去学习,学完往哪方面发展,想深入了解,详情可以点击有道云笔记链接了解:http://note.youdao.com/noteshare?id=7df52a4961924a8d98d3bc774cbfe54d
Python爬虫学习教程:天猫商品数据爬虫的更多相关文章
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- selenium跳过webdriver检测并爬取天猫商品数据
目录 简介 编写思路 使用教程 演示图片 源代码 @(文章目录) 简介 现在爬取淘宝,天猫商品数据都是需要首先进行登录的.上一节我们已经完成了模拟登录淘宝的步骤,所以在此不详细讲如何模拟登录淘宝.把关 ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- scrapy爬虫学习系列一:scrapy爬虫环境的准备
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Python实战:Python爬虫学习教程,获取电影排行榜
Python应用现在如火如荼,应用范围很广.因其效率高开发迅速的优势,快速进入编程语言排行榜前几名.本系列文章致力于可以全面系统的介绍Python语言开发知识和相关知识总结.希望大家能够快速入门并学习 ...
- Python网络爬虫学习手记(1)——爬虫基础
1.爬虫基本概念 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.--------百度百科 简单的说,爬 ...
- 【原创】Python 二手车之家车辆档案数据爬虫
本文仅供学习交流使用,如侵立删! 二手车之家车辆档案数据爬虫 先上效果图 环境 win10 python3.9 lxml.retrying.requests 需求分析 需求: 主要是需要车辆详情页中车 ...
- 使用火蜘蛛采集器Firespider采集天猫商品数据并上传到微店
有很多朋友都需要把天猫的商品迁移到微店上去.可在天猫上的商品数据非常复杂,淘宝开放接口禁止向外提供数据,一般的采集器对ajax数据采集的支持又不太好. 还有现在有了火蜘蛛采集器,经过一定的配置,终于把 ...
- Python爬虫学习==>第六章:爬虫的基本原理
学习目的: 掌握爬虫相关的基本概念 正式步骤 Step1:什么是爬虫 请求网站并提取数据的自动化程序 Step2:爬虫的基本流程 Step3:Request和Response 1.request 2. ...
随机推荐
- Python之路【第三十二篇】:django 分页器
Django的分页器paginator 文件为pageDemo models.py from django.db import models # Create your models here. cl ...
- 大数据-Storm
Storm 流式处理框架 Storm是实时的,分布式,高容错的计算系统.java+cljoure Storm常驻内存,数据在内存中处理不经过磁盘,数据通过网络传输. 底层java+cljoure构成, ...
- C++-POJ2352-Stars[数据结构][树状数组]
/* 虽然题目没说,但是读入有以下特点 由于,输入是按照按照y递增,如果y相同则x递增的顺序给出的 所以,可以利用入读的时间进行降为处理 */ 于是我们就得到了一个一维的树状数组解法啦 值得一提:坐标 ...
- 怎么把项目发布到github上
方法一:在github上新建一个项目,然后在本地任意个文件夹(最好新建)右键 git bash here ,再之后 git clone https://github.com/CKTim/BlueT ...
- 常见的sql语句练习
一. 1.新建表 test id varchar2(20)name varchar2(20)addr varchar2(50)score number create table test(id var ...
- 《你一生的故事》--------------science fiction-------------《巴比伦塔》
而塔就不一样了,不等你靠近去触摸它,就已经感到一种纯粹的坚固与力量.所有的传说都认为,建造这座塔的目的,是为了获得一种力量,这种力量是任何一座巴比伦庙塔都未曾拥有的.普通的巴比伦塔只是用太阳晒干的泥砖 ...
- python 让异常名称显示出来
一 try: pass except Exception as e: print(e) 二 import sys try: pass except: print(sys.exc_info()) 下面有 ...
- Linux服务器上实现数据库和图片文件的定时备份
一. 1.首先创建一个目录,用于存放备份的数据 2.在该目录下创建两个子目录一个用于存放数据库的信息,一个用于存放图片资源 3.#数据库的备份 执行下面的命令 mysqldump ...
- js判断非127开头的IP地址
js验证回送地址,IP地址不能以127开头 回送地址(127.x.x.x)是本机回送地址(Loopback Address) var ipNotStartWith127 = function(ip) ...
- 在远程连接mysql数据库出现问题怎么办
远程连接mysql数据库报“Communications link failure...”错误 今天在用myEclipse连接时提示:Communications link failure,Last ...