论文阅读笔记(六)【TCSVT2018】:Semi-Supervised Cross-View Projection-Based Dictionary Learning for Video-Based Person Re-Identification
Introduction
(1)Motivation:
① 现实场景中,给所有视频进行标记是一项繁琐和高成本的工作,而且随着监控相机的记录,视频信息会快速增多,因此需要采用半监督学习的方式,只对一部分的视频进行标记.
② 不同的相机有着不同的拍摄条件(如设备质量、图片尺寸等等),不同设备间的差异影响匹配的性能.
(2)Contribution:
① 提出一个半监督视频行人重识别方法(semi-supervised video-based person re-id approach).
② 设计了一个半监督字典学习模型(semi-supervised cross-view projection-based dictionary learning, SCPDL),学习特征投影矩阵(降低视频内部的变化)和字典矩阵(降低视频之间的变化).
③ 采用iLIS-VID和PRID2011数据集验证方法.
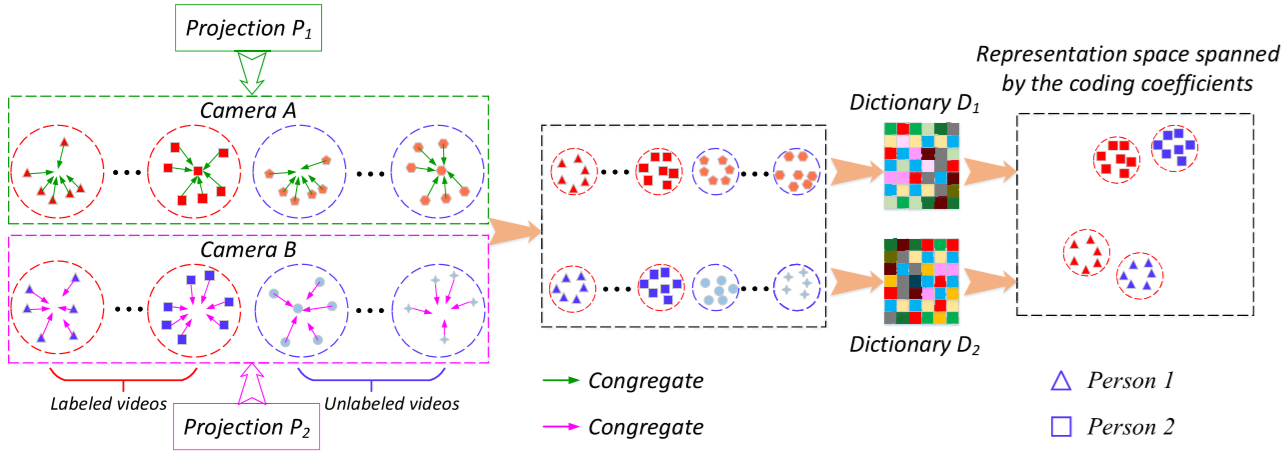
The proposed approach
(1)问题定义:
X = [XL, XU]:相机1中的视频,
Y = [YL, YU]:相机2中的视频,
其中 XL(p*n1)、YL(p*n3) 为标记的训练视频,XU(p*n2)、YU(p*n4) 为未标记的训练视频,n1、n2、n3、n4 为视频中包含的样本数,p 为样本的维数.
P1(p*q)、P2(p*q):相机1和相机2的特征投影矩阵,
其中 q 为投影特征的维数.
D1(q*m)、D2(q*m):相机1和相机2的字典矩阵,
其中 m 为字典的原子数量.
AL、AU、BL、BU:XL、XU、YL、YU 经过字典 D1、D2 后的编码(每个视频的特征向量转为了一个编码矩阵,如 ALi).
问题定义如下:
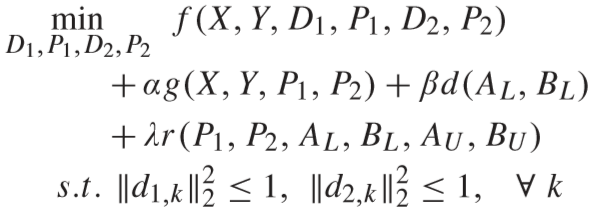
其中 α、β、λ 为平衡因子,d1,k (d2,k) 定义为 D1(D2) 的第 k 个原子.
具体如下:
f(X, Y, D1, P1, D2, P2) 为学习矩阵的保真度项(fidelity term):
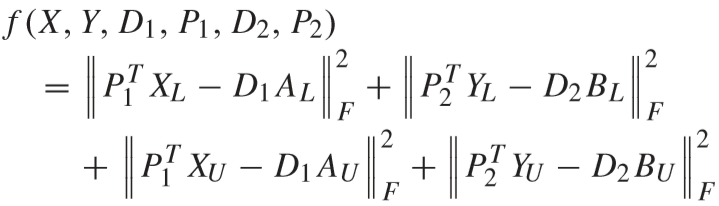
g(X, Y, P1, P2) 为视频聚合项(video congregating term):
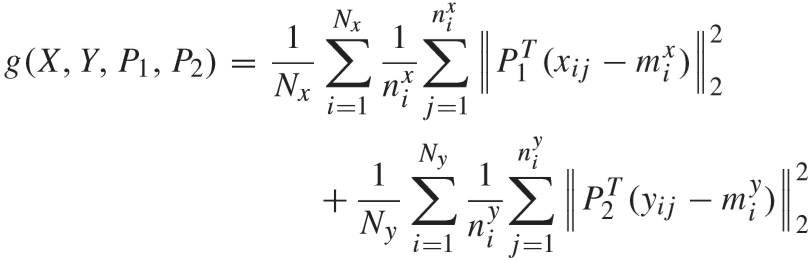
其中 Nx 和 Ny 分别为 X 和 Y 中行人视频的数量,nxi 和 nyi 分别为 X 和 Y 中第 i 个视频的样本数量,mxi 和 nyi 为 X 和 Y 中第 i 个视频所有样本的中心:
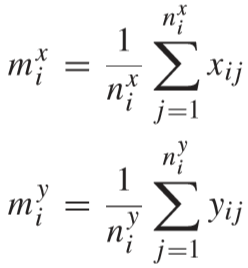
d(AL, BL) 为视频区分度项(video discriminant term),希望的结果是匹配项距离更小,不匹配项距离更大:
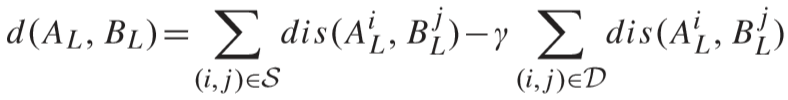
其中 γ 为平衡因子,S 是匹配成功的视频对,D 是不匹配的视频对,距离计算公式:
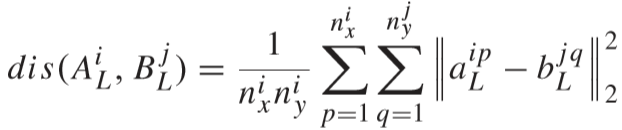
r(P1, P2, AL, BL, AU, BU) 为正则化项(regularization term):
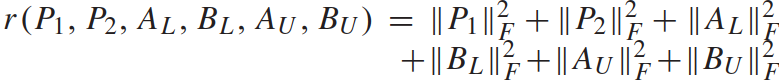
(2)方法概要:
(3)优化算法:
① 初始化:
通过优化下面的两个公式,对投影矩阵 P1 和 P2 进行初始化,并通过特征分解的方式得到解(特征分解推导参考:【传送门】):
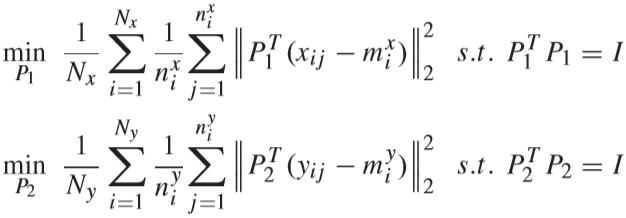
字典矩阵 D1 和 D2 采用随机生成的方法.
通过优化下面的四个公式,对 AL、AU、BL、BU 进行初始化,通过岭回归的方法进行求解(岭回归参考:【传送门】):
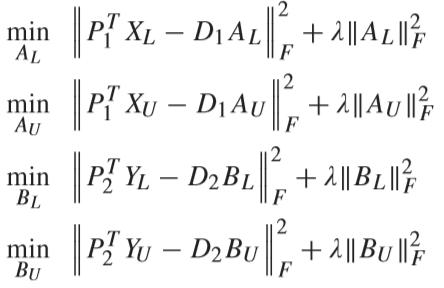
求解结果:
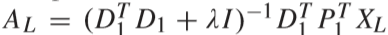
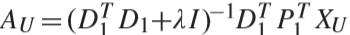

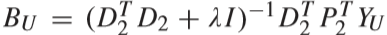
② 固定D1、D2、P1、P2,更新字典编码 AL、BL、AU、BU:

求解过程为对每一个视频 ALi 依次求解,先对 AL 进行求解(BL 类似),对下式进行求导得到解:
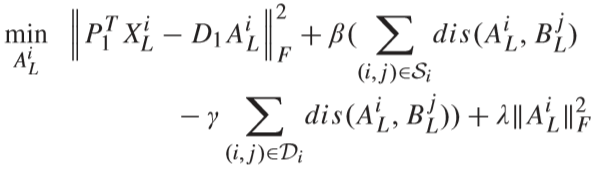
同理,对 AU、BU 进行更新.
③ 固定 AL、BL、AU、BU、D1、D2,更新 P1、P2:

通过求导得出解:
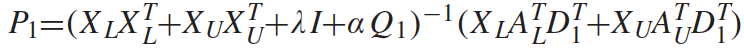
其中: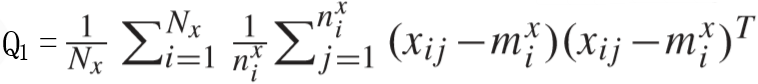

其中: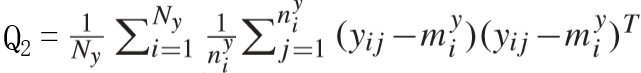
④ 固定 AL、BL、AU、BU、P1、P2,更新 D1、D2:
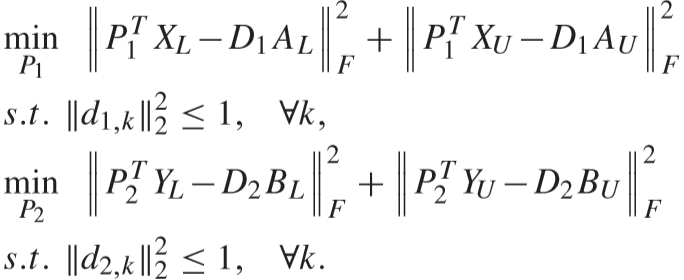
使用ADMM算法进行求解:
引入变量 S:
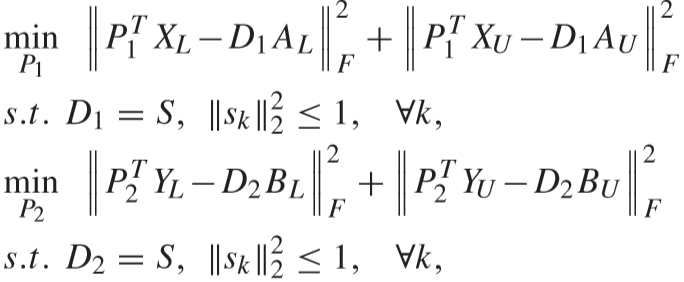
先对 D1 进行求解(D2 同理可得):

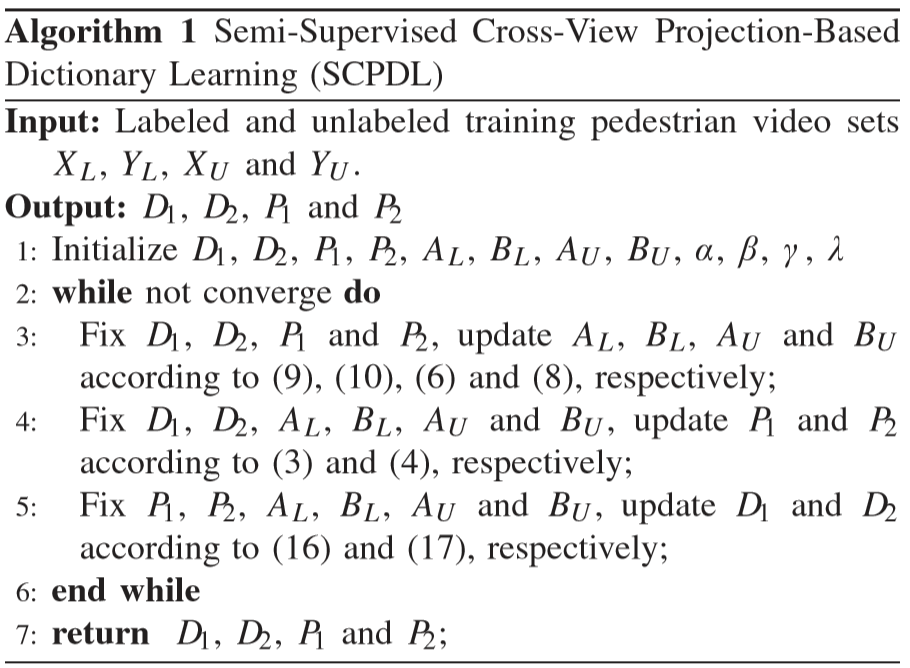
⑤ 算法总结:
(4)识别过程:
通过上述内容,已经学习到了投影矩阵(P1, P2)、字典矩阵(D1, D2).
从相机1中得到待测视频的特征为 Xi,从相机2中得到视频特征库 Z = {Z1, ..., Zj, ..., Zn}.
识别过程:
① 计算待测视频的字典编码 Ai:
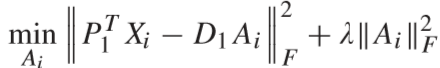
② 计算视频库所有视频的字典编码 Bj (j = 1, ...,n):
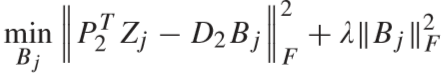
③ 计算 Ai 和 Bj (j = 1, ..., n) 的距离,并挑选出距离最近的匹配视频.
Experimental Results
(1)实验设置:
① 数据集:iLIDS-VID、PRID2011
参数(α、β等)训练阶段:将标记后的数据集划分,采用3折交叉验证法(分成3份,前2份作为训练集,第3份作为测试集,循环3次取平均测试结果)
评估训练阶段:总体数据集划分为一半标记的数据集,一半未标记的数据集.
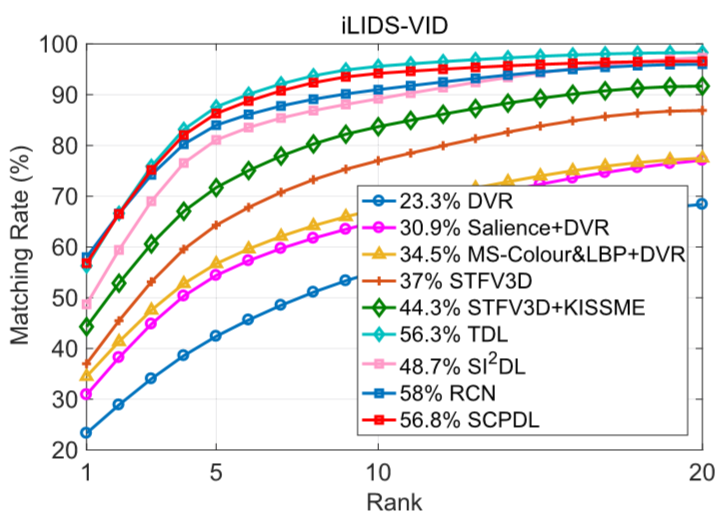
② 对比方法:DVR、Salience+DVR、MS-Colour&LBP+DVR、STFV3D、STFV3D+KISSME、TDL、SI2DL、RCN.
③ 参数设置:对于参数 α、β、γ、λ、q、m,采用学习曲线选取最佳的参数.
最终的设置为:对于iLIDS-VID, α = 6、β = 3、γ = 0.05、λ = 0.03、q = 300、m = 220;对于PRID2011,α = 5、β = 4、γ = 0.06、λ = 0.05、q = 260、m = 240.
(2)实验结果:
① 在iLIDS-VID上的结果:
② 在PRID2011上的结果:
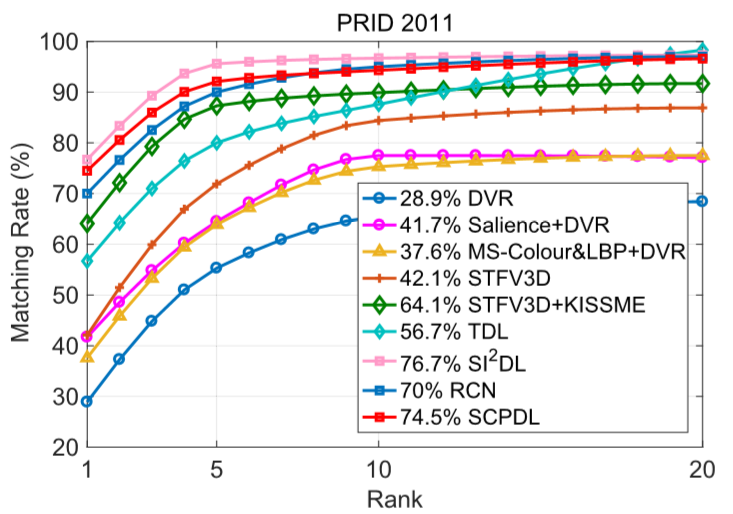
在rank-1阶段SCPDL方法比SI2DL差的可能原因: SCPDL是半监督学习的方法,只能使用一半的带标签数据进行训练,当相同数量的带标签数据时,性能将会更好.
论文阅读笔记(六)【TCSVT2018】:Semi-Supervised Cross-View Projection-Based Dictionary Learning for Video-Based Person Re-Identification的更多相关文章
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- 论文阅读笔记六十六:Wide Activation for Efficient and Accurate Image Super-Resolution(CVPR2018)
论文原址:https://arxiv.org/abs/1808.08718 代码:https://github.com/JiahuiYu/wdsr_ntire2018 摘要 本文证明在SISR中在Re ...
- 论文阅读笔记六十五:Enhanced Deep Residual Networks for Single Image Super-Resolution(CVPR2017)
论文原址:https://arxiv.org/abs/1707.02921 代码: https://github.com/LimBee/NTIRE2017 摘要 以DNN进行超分辨的研究比较流行,其中 ...
- 论文阅读笔记六十三:DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling(CVPR2017)
论文原址:https://arxiv.org/abs/1703.10295 github:https://github.com/lachlants/denet 摘要 本文重新定义了目标检测,将其定义为 ...
- 论文阅读笔记六十二:RePr: Improved Training of Convolutional Filters(CVPR2019)
论文原址:https://arxiv.org/abs/1811.07275 摘要 一个训练好的网络模型由于其模型捕捉的特征中存在大量的重叠,可以在不过多的降低其性能的条件下进行压缩剪枝.一些skip/ ...
- 论文阅读笔记六十一:Selective Kernel Networks(SKNet CVPR2019)
论文原址:https://arxiv.org/pdf/1903.06586.pdf github: https://github.com/implus/SKNet 摘要 在标准的卷积网络中,每层网络中 ...
- 论文阅读笔记六十:Squeeze-and-Excitation Networks(SENet CVPR2017)
论文原址:https://arxiv.org/abs/1709.01507 github:https://github.com/hujie-frank/SENet 摘要 卷积网络的关键构件是卷积操作, ...
- 论文阅读笔记(五)【CVPR2012】:Large Scale Metric Learning from Equivalence Constraints
由于在读文献期间多次遇见KISSME,都引自这篇CVPR,所以详细学习一下. Introduction 度量学习在机器学习领域有很大作用,其中一类是马氏度量学习(Mahalanobis metric ...
- [论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion
[论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 (1 ...
随机推荐
- Java开发最佳实践(一) ——《Java开发手册》之"编程规约"
Java开发手册版本更新说明 专有名词解释 一. 编程规约 (一) 命名风格 (二) 常量定义 (三) 代码格式 (四) OOP 规约 (五) 集合处理 (六) 并发处理 (七) 控制语句 (八) 注 ...
- IO流(字节流,字符流)
一,概述 IO流(input output):用来处理设备之间的数据. Java对数据的操作是通过流的对象. Java用于操作流的对象都在IO包中. 流是一组有顺序的,有起点和终点的字节集合,是对数据 ...
- 15.Android-实现TCP客户端,支持读写
在上章14.Android-使用sendMessage线程之间通信我们学习了如何在线程之间发送数据. 接下来我们便来学习如何通过socket读写TCP. 需要注意的是socket必须写在子线程中,不能 ...
- AndroidStudio报错:GradleSyncIssues-Could not install Gradle distribution from...
场景 在使用Android Studio 新建 App项目后,编译时提示: GradleSyncIssues-Could not install Gradle distribution from... ...
- Linux学习Day5:Vim编辑器、配置网卡、配置Yum软件仓库
今天首先学习Vim编辑器的使用,通过它可以对Linux系统的文件进行编写和修改.在Linux系统中一切都是文件,所以熟练掌握Vim编辑器的使用十分重要.最后通过配置主机网卡的实验,来加深Vim编辑器中 ...
- Linux学习Day2:安装RedHat Linux和新手必须掌握的命令
今天是Linux线上培训的第二天,主要是Linux环境的安装和几个常见命令的学习,具体如下: 一.RHEL7系统的安装 首先是VMware WorkStation 12.0软件的安装,然后是RHEL7 ...
- 插入数据失败提示: Setting autocommit to false on JDBC Connection 自动提交失败
来源:https://blog.csdn.net/qq_42799475/article/details/102742109 今天在执行mybstis的测试时,明明已经写好了插入语句但是数据库没有插入 ...
- 苹果Mac电脑永久路由的添加 & Mac 校园网连接教程
学校校园网面向全校师生开放,无奈Windows用户基数大,学校只为Windows平台制作了内网连接工具,Mac平台资源较少,本人查阅相关资料后,总结整理出以下步骤,方便本校学生连接校园网.有永久路由添 ...
- 简单的试了试async和await处理异步的方式
今天无意中就来试了试,感觉这个新的方法还是非常行的通的,接下来我们上代码 这段代码想都不用想输出顺序肯定是//null null 233,当然出现这个问题还是因为它是同步,接下来我们就进行异步方式来处 ...
- php操作mysql(数据库常规操作)
php操作数据库八步走 <?php .建立连接 $connection '); .判断连接是否成功 if (mysqli_connect_error() != null) { die(mysql ...