阻塞队列BlockingQueue之LinkedBlokingQueue
1、简介
LinkedBlokingQueue 是链表实现的有界阻塞队列,此队列的默认和最大长度为 Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。ArrayList和ArrayBlockingQueue一样,内部基于数组来存放元素,而LinkedBlockingQueue则和LinkedList一样,内部基于链表来存放元素。
2、源码分析
2.1、属性
/**
* 节点类,用于存储数据
*/
static class Node<E> {
E item;
Node<E> next; Node(E x) { item = x; }
} /** 阻塞队列的大小,默认为Integer.MAX_VALUE */
private final int capacity; /** 当前阻塞队列中的元素个数 */
private final AtomicInteger count = new AtomicInteger(); /**
* 阻塞队列的头结点
*/
transient Node<E> head; /**
* 阻塞队列的尾节点
*/
private transient Node<E> last; /** 获取并移除元素时使用的锁,如take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock(); /** notEmpty条件对象,当队列没有数据时用于挂起执行删除的线程 */
private final Condition notEmpty = takeLock.newCondition(); /** 添加元素时使用的锁如 put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock(); /** notFull条件对象,当队列数据已满时用于挂起执行添加的线程 */
private final Condition notFull = putLock.newCondition();
从上面的属性我们知道,每个添加到LinkedBlockingQueue队列中的数据都将被封装成Node节点,添加的链表队列中,其中head和last分别指向队列的头结点和尾结点。与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制,也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。
这里如果不指定队列的容量大小,也就是使用默认的Integer.MAX_VALUE,如果存在添加速度大于删除速度时候,有可能会内存溢出,这点在使用前希望慎重考虑。
另外,LinkedBlockingQueue对每一个lock锁都提供了一个Condition用来挂起和唤醒其他线程。
2.2、构造函数
public LinkedBlockingQueue() {
// 默认大小为Integer.MAX_VALUE
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
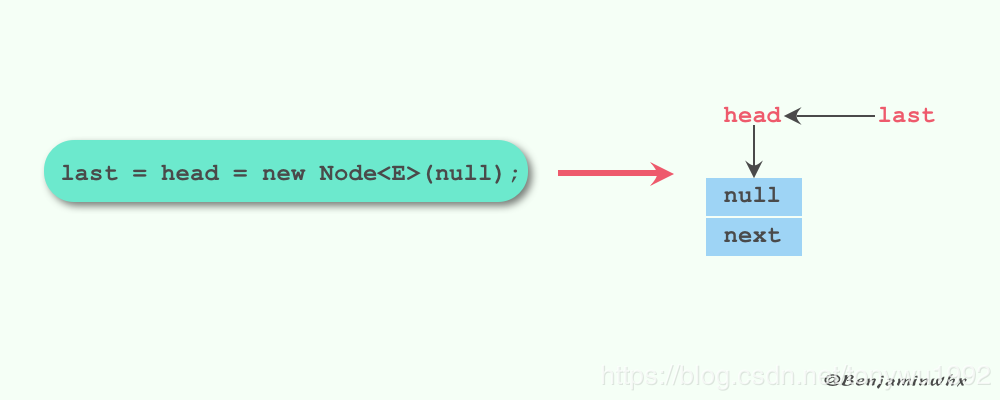
last = head = new Node<E>(null);
}
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
count.set(n);
} finally {
putLock.unlock();
}
}
默认的构造函数和最后一个构造函数创建的队列大小都为Integer.MAX_VALUE,只有第二个构造函数用户可以指定队列的大小。第二个构造函数最后初始化了last和head节点,让它们都指向了一个元素为null的节点。
最后一个构造函数使用了putLock来进行加锁,但是这里并不是为了多线程的竞争而加锁,只是为了放入的元素能立即对其他线程可见。
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
putLock.lock(); // Never contended, but necessary for visibility
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
count.set(n);
} finally {
putLock.unlock();
}
}
2.3、方法
同样,LinkedBlockingQueue也有着和ArrayBlockingQueue一样的方法,我们先来看看入队列的方法。
2.3.1、入队方法
LinkedBlockingQueue提供了多种入队操作的实现来满足不同情况下的需求,入队操作有如下几种:
- void put(E e);
- boolean offer(E e);
- boolean offer(E e, long timeout, TimeUnit unit)。
put(E e)
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
// 获取锁中断
putLock.lockInterruptibly();
try {
//判断队列是否已满,如果已满阻塞等待
while (count.get() == capacity) {
notFull.await();
}
// 把node放入队列中
enqueue(node);
c = count.getAndIncrement();
// 再次判断队列是否有可用空间,如果有唤醒下一个线程进行添加操作
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// 如果队列中有一条数据,唤醒消费线程进行消费
if (c == 0)
signalNotEmpty();
}
小结put方法来看,它总共做了以下情况的考虑:
- 队列已满,阻塞等待。
- 队列未满,创建一个node节点放入队列中,如果放完以后队列还有剩余空间,继续唤醒下一个添加线程进行添加。如果放之前队列中没有元素,放完以后要唤醒消费线程进行消费。
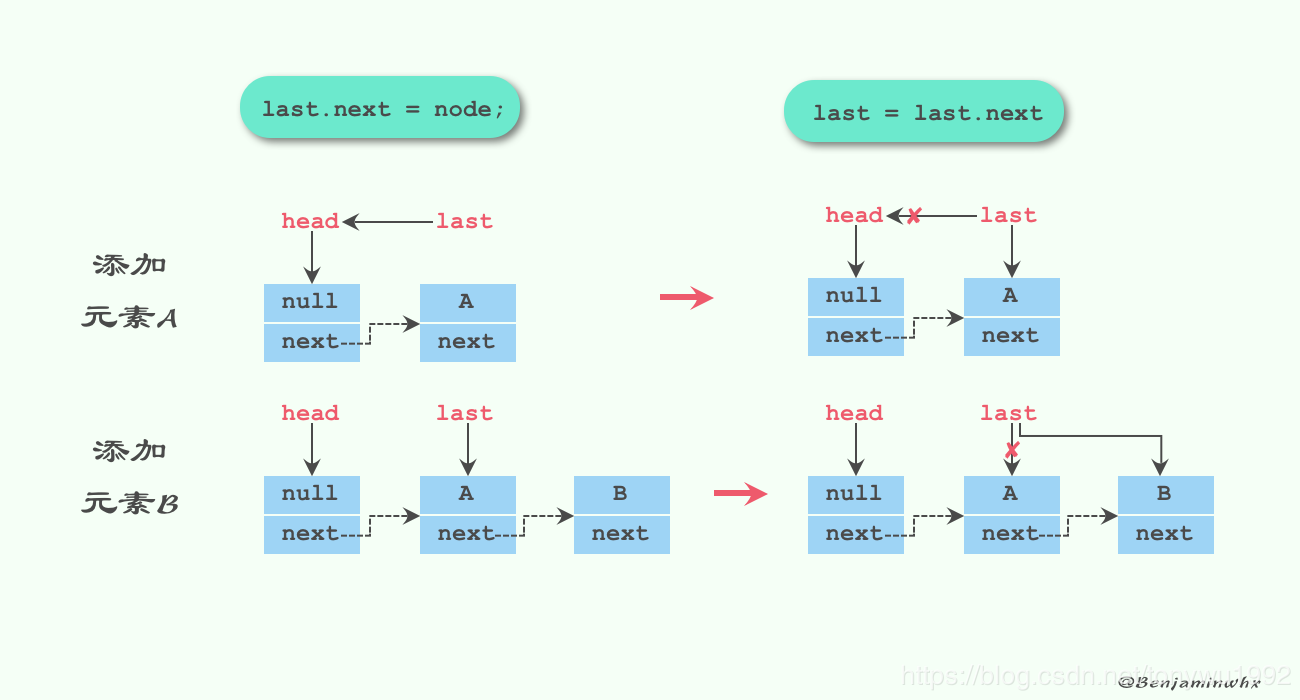
enqueue(Node node)方法:
private void enqueue(Node<E> node) {
last = last.next = node;
}
接下来我们看看signalNotEmpty,顺带着看signalNotFull方法。
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
private void signalNotFull() {
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
notFull.signal();
} finally {
putLock.unlock();
}
}
为什么要这么写?因为signal的时候要获取到该signal对应的Condition对象的锁才行。
offer(E e)
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final AtomicInteger count = this.count;
if (count.get() == capacity)
return false;
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
// 队列有可用空间,放入node节点,判断放入元素后是否还有可用空间,
// 如果有,唤醒下一个添加线程进行添加操作。
if (count.get() < capacity) {
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
}
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return c >= 0;
}
可以看到offer仅仅对put方法改动了一点点,当队列没有可用元素的时候,不同于put方法的阻塞等待,offer方法直接方法false。
offer(E e, long timeout, TimeUnit unit)
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException { if (e == null) throw new NullPointerException();
long nanos = unit.toNanos(timeout);
int c = -1;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
// 等待超时时间nanos,超时时间到了返回false
while (count.get() == capacity) {
if (nanos <= 0)
return false;
nanos = notFull.awaitNanos(nanos);
}
enqueue(new Node<E>(e));
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return true;
}
该方法只是对offer方法进行了阻塞超时处理,使用了Condition的awaitNanos来进行超时等待,这里为什么要用while循环?因为awaitNanos方法是可中断的,为了防止在等待过程中线程被中断,这里使用while循环进行等待过程中中断的处理,继续等待剩下需等待的时间。
2.3.2、出队方法
入队列的方法说完后,我们来说说出队列的方法。LinkedBlockingQueue提供了多种出队操作的实现来满足不同情况下的需求,如下:
- E take();
- E poll();
- E poll(long timeout, TimeUnit unit);
take()
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
// 队列为空,阻塞等待
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
// 队列中还有元素,唤醒下一个消费线程进行消费
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
// 移除元素之前队列是满的,唤醒生产线程进行添加元素
if (c == capacity)
signalNotFull();
return x;
}
take方法看起来就是put方法的逆向操作,它总共做了以下情况的考虑:
- 队列为空,阻塞等待。
- 队列不为空,从队首获取并移除一个元素,如果消费后还有元素在队列中,继续唤醒下一个消费线程进行元素移除。如果放之前队列是满元素的情况,移除完后要唤醒生产线程进行添加元素。
我们来看看dequeue方法
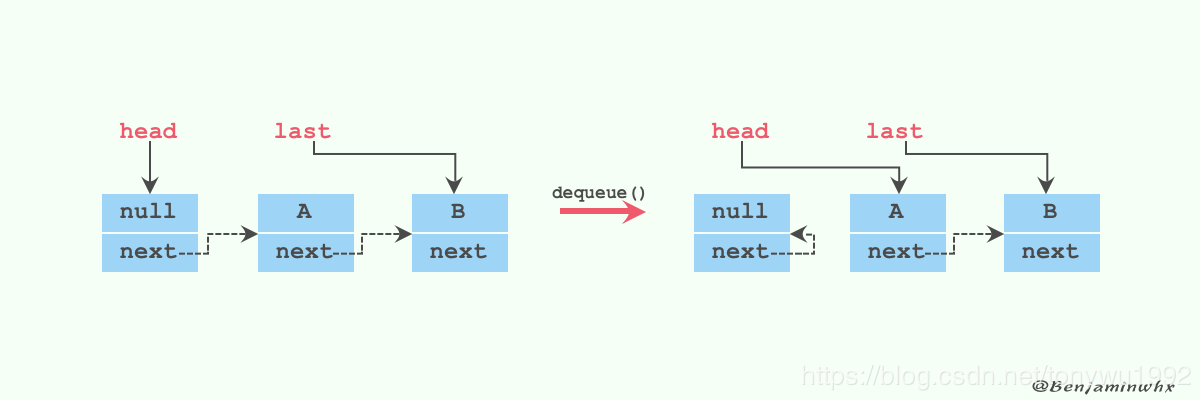
private E dequeue() {
// 获取到head节点
Node<E> h = head;
// 获取到head节点指向的下一个节点
Node<E> first = h.next;
// head节点原来指向的节点的next指向自己,等待下次gc回收
h.next = h; // help GC 问题1
// head节点指向新的节点
head = first;
// 获取到新的head节点的item值
E x = first.item;
// 新head节点的item值设置为null
first.item = null;
return x;
}
其实这个写法看起来很绕,我们其实也可以这么写:
private E dequeue() {
// 获取到head节点
Node<E> h = head;
// 获取到head节点指向的下一个节点,也就是节点A
Node<E> first = h.next;
// 获取到下下个节点,也就是节点B
Node<E> next = first.next;
// head的next指向下下个节点,也就是图中的B节点
h.next = next;
// 得到节点A的值
E x = first.item;
first.item = null; // help GC
first.next = first; // help GC
return x;
}
poll()
public E poll() {
final AtomicInteger count = this.count;
if (count.get() == 0)
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
if (count.get() > 0) {
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
}
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
poll方法去除了take方法中元素为空后阻塞等待这一步骤,这里也就不详细说了。同理,poll(long timeout, TimeUnit unit)也和offer(E e, long timeout, TimeUnit unit)一样,利用了Condition的awaitNanos方法来进行阻塞等待直至超时。这里就不列出来说了。
2.3.3、获取元素方法
public E peek() {
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
Node<E> first = head.next;
if (first == null)
return null;
else
return first.item;
} finally {
takeLock.unlock();
}
}
2.3.4、删除元素方法
public boolean remove(Object o) {
if (o == null) return false;
// 两个lock全部上锁
fullyLock();
try {
// 从head开始遍历元素,直到最后一个元素
for (Node<E> trail = head, p = trail.next;
p != null;
trail = p, p = p.next) {
// 如果找到相等的元素,调用unlink方法删除元素
if (o.equals(p.item)) {
unlink(p, trail);
return true;
}
}
return false;
} finally {
// 两个lock全部解锁
fullyUnlock();
}
}
void fullyLock() {
putLock.lock();
takeLock.lock();
}
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}
因为remove方法使用两个锁全部上锁,所以其他操作都需要等待它完成,而该方法需要从head节点遍历到尾节点,所以时间复杂度为O(n)。我们来看看unlink方法。
void unlink(Node<E> p, Node<E> trail) {
// p的元素置为null
p.item = null;
// p的前一个节点的next指向p的next,也就是把p从链表中去除了
trail.next = p.next;
// 如果last指向p,删除p后让last指向trail
if (last == p)
last = trail;
// 如果删除之前元素是满的,删除之后就有空间了,唤醒生产线程放入元素
if (count.getAndDecrement() == capacity)
notFull.signal();
}
3、问题
看源码的时候,我给自己抛出了一个问题。
- 为什么dequeue里的h.next不指向null,而指向h?
- 为什么unlink里没有p.next = null或者p.next = p这样的操作?
这个疑问一直困扰着我,直到我看了迭代器的部分源码后才豁然开朗,下面放出部分迭代器的源码:
private Node<E> current;
private Node<E> lastRet;
private E currentElement; Itr() {
fullyLock();
try {
current = head.next;
if (current != null)
currentElement = current.item;
} finally {
fullyUnlock();
}
} private Node<E> nextNode(Node<E> p) {
for (;;) {
// 解决了问题1
Node<E> s = p.next;
if (s == p)
return head.next;
if (s == null || s.item != null)
return s;
p = s;
}
}
迭代器的遍历分为两步,第一步加双锁把元素放入临时变量中,第二部遍历临时变量的元素。也就是说remove可能和迭代元素同时进行,很有可能remove的时候,有线程在进行迭代操作,而如果unlink中改变了p的next,很有可能在迭代的时候会造成错误,造成不一致问题。这个解决了问题2。
而问题1其实在nextNode方法中也能找到,为了正确遍历,nextNode使用了 s == p的判断,当下一个元素是自己本身时,返回head的下一个节点。
4、总结
LinkedBlockingQueue是一个阻塞队列,内部由两个ReentrantLock来实现出入队列的线程安全,由各自的Condition对象的await和signal来实现等待和唤醒功能。它和ArrayBlockingQueue的不同点在于:
- 队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE),对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
- 数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
- 由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
- 两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
原文链接: https://blog.csdn.net/tonywu1992/article/details/83419448
阻塞队列BlockingQueue之LinkedBlokingQueue的更多相关文章
- Java并发编程-阻塞队列(BlockingQueue)的实现原理
背景:总结JUC下面的阻塞队列的实现,很方便写生产者消费者模式. 常用操作方法 常用的实现类 ArrayBlockingQueue DelayQueue LinkedBlockingQueue Pri ...
- Java并发(十八):阻塞队列BlockingQueue
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列. 这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空.当队列满时,存储元素的线程会等待队列可用. 阻塞队列常用于生产 ...
- spring线程池ThreadPoolTaskExecutor与阻塞队列BlockingQueue
一: ThreadPoolTaskExecutor是一个spring的线程池技术,查看代码可以看到这样一个字段: private ThreadPoolExecutor threadPoolExecut ...
- Java阻塞队列(BlockingQueue)实现 生产者/消费者 示例
Java阻塞队列(BlockingQueue)实现 生产者/消费者 示例 本文由 TonySpark 翻译自 Javarevisited.转载请参见文章末尾的要求. Java.util.concurr ...
- 并发编程-concurrent指南-阻塞队列BlockingQueue
阻塞队列BlockingQueue,java.util.concurrent下的BlockingQueue接口表示一个线程放入和提取实例的队列. 适用场景: BlockingQueue通常用于一个线程 ...
- Java并发指南11:解读 Java 阻塞队列 BlockingQueue
解读 Java 并发队列 BlockingQueue 转自:https://javadoop.com/post/java-concurrent-queue 最近得空,想写篇文章好好说说 java 线程 ...
- 阻塞队列BlockingQueue用法
多线程环境中,通过队列可以很容易实现数据共享,比如经典的“生产者”和“消费者”模型中,通过队列可以很便利地实现两者之间的数据共享. 假设我们有若干生产者线程,另外又有若干个消费者线程.如果生产者线程需 ...
- 阻塞队列BlockingQueue用法(转)
多线程环境中,通过队列可以很容易实现数据共享,比如经典的“生产者”和“消费者”模型中,通过队列可以很便利地实现两者之间的数据共享. 假设我们有若干生产者线程,另外又有若干个消费者线程.如果生产者线程需 ...
- 阻塞队列BlockingQueue
BlockingQueue最终会有四种状况,抛出异常.返回特殊值.阻塞.超时,下表总结了这些方法: 抛出异常 特殊值 阻塞 超时 插入 add(e) offer(e) put(e) offer(e, ...
随机推荐
- Docker+Nginx+Tomcat实现负载均衡
环境检测: 1.Docker没有安装的小伙伴请查看https://www.cnblogs.com/niuniu0108/p/12372531.html 2.没有创建Nginx容器的小伙伴请查看http ...
- 中间件c10k问题
中间件c10k问题 没有使用iocp/epoll/kqueue通讯的中间件,中间件就算部署在拥有多核CPU的强大服务器上,最头痛的问题是C10K问题. 中间件没有办法通过优化程序,提升CPU利用率来处 ...
- 订阅消息---由于微信小程序取消模板消息,限只能开发订阅消息
订阅消息开发步骤: 1.小程序管理后台添加订阅消息的模板 2.小程序前端编写调用(拉起)订阅授权 wx.requestSubscribeMessage({ tmplIds: ['34fwe1211xx ...
- 大json直接序列化成dataset
rtnDs= JsonConvert.DeserializeObject<DataSet>(strBuff);
- 0219 springmvc-拦截器和响应增强
拦截器 拦截器分同步拦截器和异步拦截器: HandlerInterceptor 方法和执行时机 可以看DispathcerServlet的原来确定它的三个方法的执行时机: AsynHandlerInt ...
- eclipse调字体大小
首先调java字体: Window -> Preferences -> General -> Appearance -> Colors and Fonts -> Java ...
- LED Keychain-A Tool To Drive Specific Market Segments
LED keychain are an excellent tool to drive specific market segments. They can focus on a small grou ...
- PP: Multilevel wavelet decomposition network for interpretable time series analysis
Problem: the important frequency information is lack of effective modelling. ?? what is frequency in ...
- SpringBoot学习- 10、设计用户角色权限表
SpringBoot学习足迹 前几节已经基本了解了SpringBoot框架常用的技术,其他的消息队列,定时器等技术暂时用不到,真正项目中如果基于微信系,阿里系开发的话,还要了解平台专用的技术知识,学习 ...
- Django学习笔记3
From the last two parts, we know, by using the HttpResponse we can return text to the web page, and ...