小爬爬1:jupyter简单使用&&爬虫相关概念
1.jupyter的基本使用方式
两种模式:code和markdown
(1)code模式可以直接编写py代码
(2)markdown可以直接进行样式的指定
(3)双击可以重新进行编辑
(4)快捷键总结:
插入cell:a b
删除cell:x
切换cell的模式:m y
执行cell:shift+enter
tab:自动补全
shift+tab:打开帮助文档
(5)ipynb文件相当于是放在缓存中,没有先后顺序.缓存机制
2.第二种打开anaconda的方式:
(1)图1
(2)图2
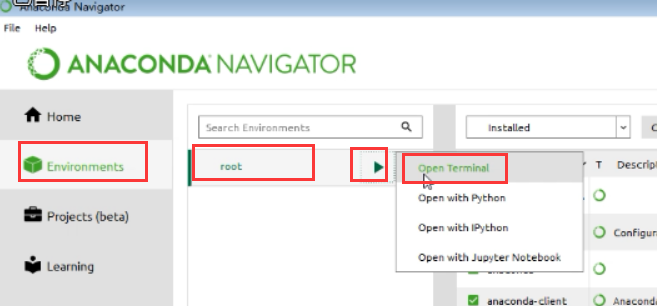
(3)图3,下图两个路径,也是也已打开浏览器的内容的

上边的方式打开,就不需要配置环境变量了.
2.基本概念:http回顾
1.什么是爬虫?
我们用过很多:就是浏览器本身就是
概念:通过编写程序,模拟浏览器上网,让其去互联网上获取数据的过程.
2.爬虫的分类
(1)通用爬虫:获取一整张页面数据, 比如百度,360,搜狗浏览器(背后有一套抓取系统)
(2)聚焦爬虫:根据指定的需求获取页面中指定的局部数据
(3)增量式爬虫:用来监测网站数据更新的情况,爬取网站最新更新出来的数据
(4)分布式爬虫:讲解完scrapy之后,再涉及到
3.反爬本质
反爬机制:网站可以采取相关的技术手段或者策略阻止爬虫程序进行网站数据的爬取
反反爬策略:让爬虫程序通过破解反爬机制获取数据
4.协议
(1)robots协议(可以不遵守):一种反爬协议,规定哪些数据可爬,哪些不可以爬,必须双方遵循才行.
防君子不防小人的协议
https://www.taobao.com/robots.txt
(2)http协议(超文本传输协议):client和server进行数据交互的形式(一定要善于总结)
https协议:安全的http
人与人之间其实就是在进行数据交互.
-使用到的头信息
请求头信息:
--User-Agent:请求载体的身份标识(浏览器或者爬虫程序都行,爬虫通过伪装的)
比如,我们安装的是谷歌浏览器,而我们访问的是百度,请求的载体是"谷歌浏览器"
--Connection:keep-alive或者close
close属性:当发送的请求成功之后,请求对应的链接会立马断开
keep-alive;当发送的请求成功之后,请求对应的链接会断开,但是不会马上断开
响应头信息:
--content-type:可以是json或者text或者js,作用:说明服务端响应回客户端的数据格式或者数据类型.
5.
https:安全的http协议
证书秘钥加密?
在理解上边的加密方式之前,我们先了解"对称秘钥加密","非对称秘钥加密"
初步了解即可
三种加密方式:证书秘钥加密,对称秘钥加密,非对称密钥加密
(1)SSL加密技术:
SSL采用的加密技术叫做"共享密钥加密",也叫作"对称秘钥加密".
缺点:一旦被三方拦截,就会被破解秘钥和公钥,密文就可能被破解

(2)非对称加密
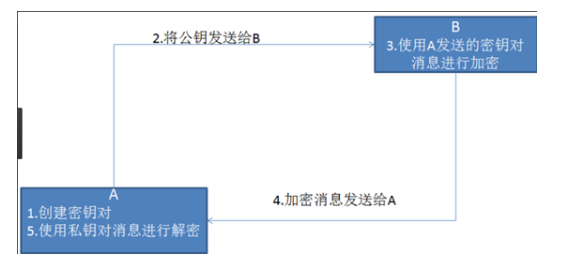
缺点:(1)效率比较低,(2)客户端不知道是不是服务端发送的公钥.
(3)证书秘钥加密:攻克了非对称秘钥加密的问题
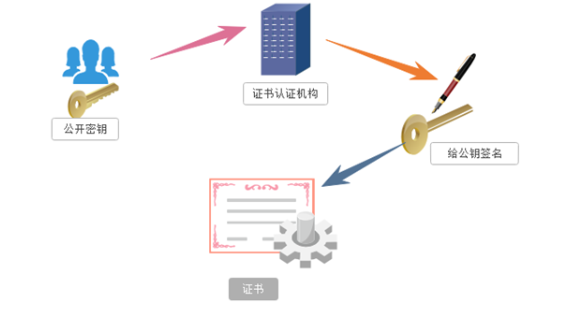
三方机构:证书认证机构
参考博客:https://www.cnblogs.com/bobo-zhang/p/9645715.html
小爬爬1:jupyter简单使用&&爬虫相关概念的更多相关文章
- 小爬爬1:开篇&&简单介绍启动
1.第一阶段的内容 2.学习的方法? 思考,总结,重复 3.长大了意味着什么?家庭的责任,真的很重 4.数据分析&&数据清洗 numpy&&pandas&&am ...
- 一个简单java爬虫爬取网页中邮箱并保存
此代码为一十分简单网络爬虫,仅供娱乐之用. java代码如下: package tool; import java.io.BufferedReader; import java.io.File; im ...
- 用python3.x与mysql数据库构建简单的爬虫系统(转)
这是在博客园的第一篇文章,由于本人还是一个编程菜鸟,也写不出那些高大上的牛逼文章,这篇文章就是对自己这段时间学习python的一个总结吧. 众所周知python是一门对初学编程的人相当友好的编程语言, ...
- 纯手工打造简单分布式爬虫(Python)
前言 这次分享的文章是我<Python爬虫开发与项目实战>基础篇 第七章的内容,关于如何手工打造简单分布式爬虫 (如果大家对这本书感兴趣的话,可以看一下 试读样章),下面是文章的具体内容. ...
- 每天几分钟跟小猫学前端之node系列:用node实现最简单的爬虫
先来段求分小视频: https://www.iesdouyin.com/share/video/6550631947750608142/?region=CN&mid=6550632036246 ...
- 【转】使用webmagic搭建一个简单的爬虫
[转]使用webmagic搭建一个简单的爬虫 刚刚接触爬虫,听说webmagic很不错,于是就了解了一下. webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代 ...
- Selenium + PhantomJS + python 简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDrive ...
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
- nodejs实现最简单的爬虫
本文将以抓取百度搜索结果中关键词的相关搜索为例子,教会大家以nodejs制作最简单的爬虫: 开始之前呢,先来个公众号求粉: 将使用的node模块及属性介绍: request: ...
随机推荐
- [code]自动白平衡white blance
//2013.10.24 //eageldiao //自动白平衡 CvScalar rgb; rgb=cvAvg(src); #ifdef COLOR_GW //灰度世界假设(R,= R*K/Ravg ...
- Linux 7.X 解锁用户账号
Linux 7.X 解锁用户账号 使用指令:sudo passwd -u tomcat ,解锁. 但是会有如下提示信息: 因为 55 失败登录而锁定账户 此时,需执行指令:pam_tally2 -u ...
- promise基础和进阶
本文不对Promise的做过深的解析,只对基础的使用方法,然后会记录一些promise的使用技巧,可以巧妙的解决异步的常见问题. 在过去一直理解的是解决了一直异步回调的坑,但是用了npm async之 ...
- char类型和int类型之间的转换
在视屏课程第二章里,我们已经学习了一些常用的数据类型转换.然而,有一些时候我们会经常会遇到将char类型转换成int类型,或者需要将int类型转换为char类型的情况. 这里,我们来探讨一下这种不常用 ...
- ngVerify - 更高效的 angular 表单验证
ngVerify v1.5.0 a easy Angular Form Validation plugin.简洁高效的__angular表单验证插件__ See how powerful it.看看它 ...
- springmvc框架使用拦截器实现301永久重定向,其实用过滤器应该是更好
做seo的朋友提出要求 所有不带www.的访问需要301到带www的域名,以集中权重 可以使用过滤器检查servername带不带www,也可以使用拦截器 不会配置过滤器,所以先用拦截器实现吧,不过我 ...
- IO流5 --- FileReader读入数据的基本操作 --- 技术搬运工(尚硅谷)
FileReader 字符输入流 @Test public void test1(){ File file = new File("hello.txt"); FileReader ...
- 学习JDK1.8集合源码之--LinkedHashMap
1. LinkedHashMap简介 LinkedHashMap继承自HashMap,实现了Map接口. LinkedHashMap是HashMap的一种有序实现(多态,HashMap的有序态),可以 ...
- Django--登录功能
登录功能: 1.路由访问如果不加斜杠,内部会重定向加斜杠的路由 所有的html文件都默认卸载templates文件夹下面 所有的(css,js,前端第三方的类库)默认都放在static文件夹下 htm ...
- day38 11-Spring的Bean的属性的注入:对象属性
package cn.itcast.spring3.demo5; public class Person { private String name;//人的名字 private Car2 car2; ...