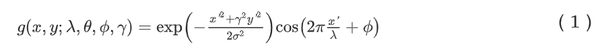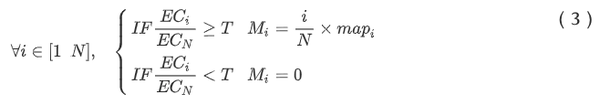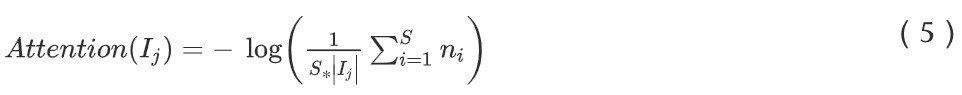Riche, N., Mancas, M., Duvinage, M., Mibulumukini, M., Gosselin, B., & Dutoit, T. (2013). RARE2012: A multi-scale rarity-based saliency detection with its comparative statistical analysis. Signal Processing: Image Communication, 28(6), 642–658.
https://doi.org/10.1016/j.image.2013.03.009
一篇老早老早以前的文章啦,今天看到有文章使用它的方法,特地拜读下。
视觉注意力机制这东西我们感兴趣,那就是因为它有用呀。比如帮助人机交互界面优化,让用户使用交互按钮更加舒服;广告设计的评估;视频图像数据压缩,着重保留更感兴趣的图像信息。机器人的视觉感知等等吧。
关于人类的视觉注意力的通用定义,不知道现在生物学上有没有研究明白这是怎么回事,反正在这篇文章发表的时候是没有滴。但是一般意义上讲,人类的注意力可以定义为对传入刺激进行优先排序并有选择地关注其中一部分的自然能力。行,有个初步的定义也好呀。那视觉上的注意力咋搞呢,大脑接收到的图像信号并不只是一个待排序的信号序列呀。
在计算机视觉中,对注意力机制的探索大部分依赖于“saliency maps”这一概念,字面意思就是“显著性图”。简单来讲,“saliency maps”就是对某一个模型的输入信号做了一个映射,映射的结果就是,对模型比较重要的信号会得到一个较强的相应。
那么对于视觉注意力机制来讲,输入就是图像;人眼容易被吸引的地方就是比较重要的信号。所以,解释视觉注意力机制,就是想找到一个更好的“saliency maps”。它应该迅速的根据输入图像告诉我们,那些地方对我们的视觉感知系统非常有吸引力。
按照这样的思路,“saliency maps”中就包含了两种机制。一种是自下而上的注意力,也称为刺激驱动的或外在的注意力。另一种是自上而下的,也称为任务驱动的或内生的注意力,它集成了观察者在特定情况下可能具有的特定知识(任务,场景类型的模型,可识别的对象等)。而RARE2012纯粹是自下而上的,因为自下而上的方法性能更好。就是完全依靠输入图像信息,不需要考虑其他决策机制,当然性能更好辣。
文章对比了当年流行的好几种 方法,结论就是他们的方法挺好。哈哈哈
-------------------------------------------------------------------------------------------
第一步:首先用主成分分析PCA的方法,把rgb三通道的图像映射到三个线性不相关空间。就是拆分成了三个通道,这三个通道中,channal1主要包含亮度信息,而channal2和channal3则包含色度的信息。但是三个通道的信息都是独立的。看起来它的三个通道有点像hsv嘛,hsv就是明度、色调和饱和度。不过具体怎样分解的我不知道哦,还要看源码,文章中没说。
第二步:对三个通道的图像直接用PCA计算rarity。哎,这里还是得看源码,对图像进行主成分分析得到降维我可以理解,那上边用PCA方法拆分通道是咋回事呢?不管如何,这样做得到了三张rarity分布图。这样做就是在提取图像中的低级颜色特征,当然也包括亮度分布特征。
第三步:然后再对上述三个通道图像利用Gabor滤波器提取方向特征图。选择Gabor滤波器是因为Gabor类似于大脑中视觉皮层(V1)的简单神经处理过程。
Gabor与人类视觉系统中简单细胞的视觉刺激响应非常相似。它在提取目标的局部空间和频率域信息方面具有良好的特性。Gabor小波对于图像的边缘敏感,能够提供良好的方向选择和尺度选择特性,而且对于光照变化不敏感,能够提供对光照变化良好的适应性。
用Gabor 函数形成的二维Gabor 滤波器具有在空间域和频率域同时取得最优局部化的特性,因此能够很好地描述对应于空间频率(尺度)、空间位置及方向选择性的局部结构信息。Gabor就是用来提取图像中的空间方向和纹理特征。
文章中对Gabor分别输入8个方向,这样对于一幅输入图像来讲,一共会有8个结果。这8幅输出要融合到1张输出图像中。
根据EC大小对8张方向图排序。每张方向图都乘以权重:i/N 。N=8,i就是这张方向图的EC排第几位。文中设了一个阈值,筛选掉EC太小的方向图:
这样PCA方法得到的三张图像channal1、channal2和channal3经过Gabor提取到了3幅纹理方向的rarity图。
-------------------------------------------------------------------------------------------
这一阶段的稀有度机制才是rare2012的关键,毕竟名字就是这个嘛。
方法就是:统计在设定的尺度范围内,该像素出现的频率。

n_i 是当前像素j的灰度值为i的概率(比例),
n_i 就是根据rarity图的直方图得到的。这个公式说的有点不明不白的,S是啥?看起来是没有归一化的rarity图中的灰度最大值。不管怎样,它的思想就是统计图像中某一灰度出现的频率,认为是某一个灰度在局部区域出现的概率。这就是该像素的注意力得分,就是Attention()。
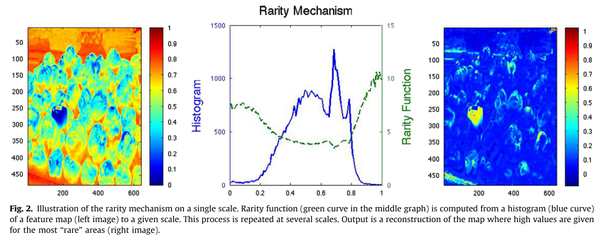
Fig. 2中给出了一个例子,输入左图,蓝色的区域在整幅图像中出现的概率较低,那么它在稀有度图中的值就偏高。
第二阶段中,对第一阶段得到的6张map计算attention。
-------------------------------------------------------------------------------------------
对第二阶段得到的6张attention map进行融合操作。
首先是通道内融合,由channal1得到的颜色特征图和纹理方向图计算attention后,进行融合。融合方法为:
就是EC和map点乘。这里出现了S哦,不过它是不是公式5中的S呢,这个要看下源码,论文中没说。N=2,为啥是2,哪里来的两张图,也不明白。
先不管这些地方,看最后,rare2012是如何得到最终的输出的:
根据第三阶段的融合操作,三个通道的图像最后输出了三个结果。
这三个结果再融合起来,就是最后的输出了。融合的方法就是第一阶段的第三步,融合gabor后的8张图像的方法。首先计算效率系数,然后排序,然后乘权重,阈值筛选。
rare2012是由rare2007和rare2011发展而来,每一次改进都带来的一些创新。性能更好,考虑的特征更全面。俺么rare2012结果如何?
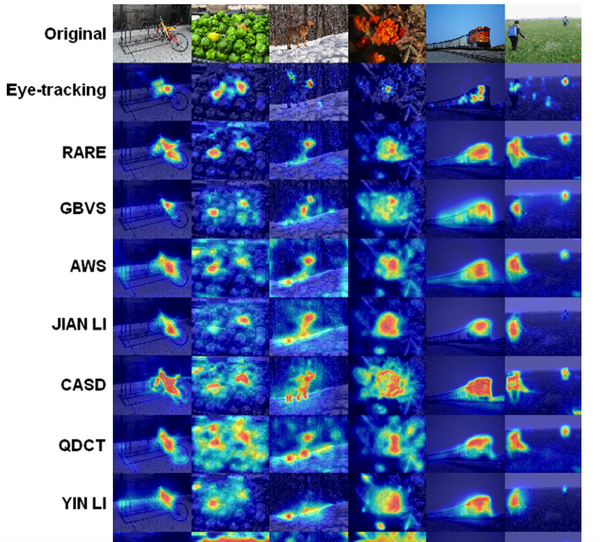
对比结果中,上面是眼动监测的结果,也就是人眼实际的聚焦情况。下面是rare2012的结果。看起来挺好的嘛。
但是rare2012有时也有完全出错的时候。fig7中后面三个数据的结果,rare2012都错了。看来注意力机制还是要引入充分合理的自上而下的逻辑判断。
不过rare2012在当年对比同类模型,还是相当有优势的。当然论文中有定量的性能和准确率分析。
- (读论文)推荐系统之ctr预估-NFM模型解析
本系列的第六篇,一起读论文~ 本人才疏学浅,不足之处欢迎大家指出和交流. 今天要分享的是另一个Deep模型NFM(串行结构).NFM也是用FM+DNN来对问题建模的,相比于之前提到的Wide& ...
- 读论文系列:Deep transfer learning person re-identification
读论文系列:Deep transfer learning person re-identification arxiv 2016 by Mengyue Geng, Yaowei Wang, Tao X ...
- (读论文)推荐系统之ctr预估-DeepFM模型解析
今天第二篇(最近更新的都是Deep模型,传统的线性模型会后面找个时间更新的哈).本篇介绍华为的DeepFM模型 (2017年),此模型在 Wide&Deep 的基础上进行改进,成功解决了一些问 ...
- 读论文系列:Object Detection SPP-net
本文为您解读SPP-net: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Motivat ...
- Deep Learning 33:读论文“Densely Connected Convolutional Networks”-------DenseNet 简单理解
一.读前说明 1.论文"Densely Connected Convolutional Networks"是现在为止效果最好的CNN架构,比Resnet还好,有必要学习一下它为什么 ...
- Deep Learning 24:读论文“Batch-normalized Maxout Network in Network”——mnist错误率为0.24%
读本篇论文“Batch-normalized Maxout Network in Network”的原因在它的mnist错误率为0.24%,世界排名第4.并且代码是用matlab写的,本人还没装caf ...
- Deep Learning 23:dropout理解_之读论文“Improving neural networks by preventing co-adaptation of feature detectors”
理论知识:Deep learning:四十一(Dropout简单理解).深度学习(二十二)Dropout浅层理解与实现.“Improving neural networks by preventing ...
- Deep Learning 18:DBM的学习及练习_读论文“Deep Boltzmann Machines”的笔记
前言 论文“Deep Boltzmann Machines”是Geoffrey Hinton和他的大牛学生Ruslan Salakhutdinov在论文“Reducing the Dimensiona ...
- Deep Learning 16:用自编码器对数据进行降维_读论文“Reducing the Dimensionality of Data with Neural Networks”的笔记
前言 论文“Reducing the Dimensionality of Data with Neural Networks”是深度学习鼻祖hinton于2006年发表于<SCIENCE > ...
随机推荐
- @bzoj - 4709@ 柠檬
目录 @desription@ @solution@ @accepted code@ @details@ @desription@ 一共有 N 只贝壳,编号为 1...N,贝壳 i 的大小为 si. ...
- mysql 优化 1
一. 数据库索引 规则8:业务需要的相关索引是根据实际的设计所构造sql语句的where条件确定的,业务不需要的不要建索引,不允许在联合索引(或主键)中存在多余的字段,特别是该字段根本不会在条件语句中 ...
- H3C 常用信息查看命令
- H3C 命令级别
- rowStyle设置Bootstrap Table行样式
日常开发中我们通常会用到隔行变色来美化表格,也会根据每行的数据显示特定的背景颜色,如果库存低于100的行显示红色背景 CSS样式 <style> .bg-blue { background ...
- JPA+Postgresql+Spring Data Page分页失败
按照示例进行如下代码编写 Repository Page<DeviceEntity> findByTenantId(int tenantId, Pageable pageable); se ...
- Ralasafe配置手册
Ralasafe访问控制(权限管理)中间件的配置工作非常少.因为项目发起人非常讨厌配置.因此,"己所不欲,勿施于人",Ralasafe的配置也非常少. Ralasafe配置工作只有 ...
- 使用vuex来管理数据
最近一直工作比较忙,博客已经鸽了好久了,趁着今天是周末,写点东西吧 使用vuex来管理数据 最近一直在用vue做项目,但是却从来没真正去用过vuex,因为一直感觉很复杂,其实真正去研究一下啊,就会发现 ...
- 2018.11.9浪在ACM集训队第四次测试赛
2018.11.9浪在ACM集训队第四次测试赛 整理人:朱远迪 A 生活大爆炸版 石头剪刀布 参考博客:[1] 刘凯 B 联合权值 参考博客: [1]田玉康 ...
- dotnet 使用 MessagePack 序列化对象
和很多序列化库一样,可以通过 MessagePack 序列化和反序列化,和 json 相比这个库提供了二进制的序列化,序列化之后的内容长度比 json 小很多 这个库能序列的内容不多,大多数时候建议使 ...