Spring与RestHighLevelClient
- Elasticsearch连接方式有两种;分别为TCP协议与HTTP协议
最近使用es比较多,之前使用一直是使用spring封装的spring-data-elasticsearch;关于spring-data-elasticsearch有以下几点比较难受:
基于TCP协议的使用(不确定是否支持http, 公司XX云大佬推荐使用HTTP协议,好像是官方推荐?)
版本对应比较恶心人
不好用
基于以上几点,索性抛弃spring-data-elasticsearch,自己造轮子;
根据 官方文档 描述,我们选择使用RestHighLevelClient来实现es基础查询;
官方描述:
The Java REST Client comes in 2 flavors:
Java Low Level REST Client: the official low-level client for Elasticsearch. It allows to communicate with an Elasticsearch cluster through http. Leaves requests marshalling and responses un-marshalling to users. It is compatible with all Elasticsearch versions.
Java High Level REST Client: the official high-level client for Elasticsearch. Based on the low-level client, it exposes API specific methods and takes care of requests marshalling and responses un-marshalling.
提供Java Low Level REST Client 版本和 Java High Level REST Client 版本:
- Java Low Level REST Client 与所有Elasticsearch版本兼容(版本问题舒服)
- 通过HTTP协议与Elasticsearch集群进行通信(大佬推荐)
- Java High Level REST Client 是基于Java Low Level REST Client 版本实现更多高级API
很显然我们选择RestHighLevelClient
Spring整合RestHighLevelClient
构建ElasticsearchClient
- 查看RestHighLevelClient构造器可以发现可以使用RestClientBuilder来构建,简单demo如下
/**
* 连接超时时间
*/
private final static int CONNECT_TIMEOUT = 5000;
/**
* 连接超时时间
*/
private final static int SOCKET_TIMEOUT = 40000;
/**
* 获取连接的超时时间
*/
private final static int CONNECTION_REQUEST_TIMEOUT = 1000;
/**
* 最大连接数
*/
private final static int MAX_CONNECT_NUM = 100;
/**
* 最大路由连接数
*/
private final static int MAX_CONNECT_ROUTE = 100;
@Bean(name = "elasticsearchClient", destroyMethod = "close")
public RestHighLevelClient client() {
RestClientBuilder builder = RestClient.builder(new HttpHost("host", "port", "http"));
// 配置一些请求配置的参数
builder.setRequestConfigCallback(requestConfigBuilder -> {
requestConfigBuilder.setConnectTimeout(CONNECT_TIMEOUT);
requestConfigBuilder.setSocketTimeout(SOCKET_TIMEOUT);
requestConfigBuilder.setConnectionRequestTimeout(CONNECTION_REQUEST_TIMEOUT);
return requestConfigBuilder;
});
// 配置一些httpClient的参数
builder.setHttpClientConfigCallback(httpClientBuilder -> {
httpClientBuilder.setMaxConnTotal(MAX_CONNECT_NUM);
httpClientBuilder.setMaxConnPerRoute(MAX_CONNECT_ROUTE);
return httpClientBuilder;
});
builder.setFailureListener(new RestClient.FailureListener(){
@Override
public void onFailure(HttpHost host) {
// TODO do something when failed
super.onFailure(host);
}
});
return new RestHighLevelClient(builder);
}
- 支持一些回调与参数的配置,具体的API可自行查看RestClientBuilder的源码
- 配置完client后我们可以使用client造一些简单的轮子, 如es默认查询只可以查询1000条数据,我们可以封装查询所有数据
public List<SearchHit> searchAll(SearchRequest searchRequest) {
try {
List<SearchHit> hits = new ArrayList<>(16);
int maxNum = searchRequest.source().size();
searchRequest.scroll(TimeValue.timeValueMinutes(10));
SearchResponse search = client.search(searchRequest);
hits.addAll(Arrays.asList(search.getHits().getHits()));
while (search.getHits().getHits().length == maxNum) {
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(search.getScrollId());
searchScrollRequest.scroll(TimeValue.timeValueMinutes(10));
search = client.searchScroll(searchScrollRequest);
hits.addAll(Arrays.asList(search.getHits().getHits()));
}
return hits;
} catch (IOException e) {
log.error("Get message error.", e);
return null;
}
}
- 有了以上接口,我们可以查询一些常用数据,如以下为查询数据的简单使用:
BoolQueryBuilder boolBuilder = QueryBuilders.boolQuery();
boolBuilder.filter(QueryBuilders.termQuery("type", 0));
boolBuilder.filter(QueryBuilders.termsQuery("id.keyword", id));
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("createTime");
rangeQueryBuilder.gte(startTime);
rangeQueryBuilder.lte(endTime);
boolBuilder.filter(rangeQueryBuilder);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(9999);
sourceBuilder.fetchSource(new String[]{"field1", "field2", "field3"}, new String[]{});
sourceBuilder.query(boolBuilder);
SearchRequest searchRequest = new SearchRequest("index");
searchRequest.source(sourceBuilder);
List<SearchHit> searchHits = repository.searchAll(searchRequest);
- 具体API使用可查看官方文档
更新于2019-10-28
IndexRequest indexRequest = new IndexRequest(index, type, id);
indexRequest.source(entityMapper.mapToString(map), Requests.INDEX_CONTENT_TYPE);
return client.index(indexRequest);
官方API中IndexRequest提供以下几种source方法:
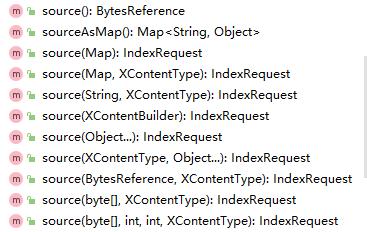
- 值得注意的是source(Map source) 与 source(Map source, XContentType contentType) 方法,对于Map的传参,会进行类型校验;
- 源码如下:
public IndexRequest source(Map source, XContentType contentType) throws ElasticsearchGenerationException {
try {
XContentBuilder builder = XContentFactory.contentBuilder(contentType);
builder.map(source);
return source(builder);
} catch (IOException e) {
throw new ElasticsearchGenerationException("Failed to generate [" + source + "]", e);
}
}
其中builder.map中的unknownValue方法会遍历参数进行逐一校验:
源码如下:
private XContentBuilder map(Map<String, ?> values, boolean ensureNoSelfReferences) throws IOException {
if (values == null) {
return this.nullValue();
} else {
if (ensureNoSelfReferences) {
ensureNoSelfReferences(values);
}
this.startObject();
Iterator var3 = values.entrySet().iterator();
while(var3.hasNext()) {
Entry<String, ?> value = (Entry)var3.next();
this.field((String)value.getKey());
this.unknownValue(value.getValue(), false);
}
this.endObject();
return this;
}
}
- 检验方法源码
private void unknownValue(Object value, boolean ensureNoSelfReferences) throws IOException {
if (value == null) {
this.nullValue();
} else {
XContentBuilder.Writer writer = (XContentBuilder.Writer)WRITERS.get(value.getClass());
if (writer != null) {
writer.write(this, value);
} else if (value instanceof Path) {
this.value((Path)value);
} else if (value instanceof Map) {
Map<String, ?> valueMap = (Map)value;
this.map(valueMap, ensureNoSelfReferences);
} else if (value instanceof Iterable) {
this.value((Iterable)value, ensureNoSelfReferences);
} else if (value instanceof Object[]) {
this.values((Object[])value, ensureNoSelfReferences);
} else if (value instanceof ToXContent) {
this.value((ToXContent)value);
} else {
if (!(value instanceof Enum)) {
throw new IllegalArgumentException("cannot write xcontent for unknown value of type " + value.getClass());
}
this.value(Objects.toString(value));
}
}
}
- 为了避免这个坑,可以使用jsonString来规避,具体使用如下:
IndexRequest indexRequest = new IndexRequest(index, type, id);
indexRequest.source(JSON.toJSONString(map), Requests.INDEX_CONTENT_TYPE);
client.index(indexRequest);
Spring与RestHighLevelClient的更多相关文章
- springboot使用RestHighLevelClient批量插入
1.引入maven(注意版本要一致) <dependency> <groupId>org.springframework.boot</groupId> <ar ...
- elasticsearch系列七:ES Java客户端-Elasticsearch Java client(ES Client 简介、Java REST Client、Java Client、Spring Data Elasticsearch)
一.ES Client 简介 1. ES是一个服务,采用C/S结构 2. 回顾 ES的架构 3. ES支持的客户端连接方式 3.1 REST API ,端口 9200 这种连接方式对应于架构图中的RE ...
- Elasticsearch Java client(ES Client 简介、Java REST Client、Java Client、Spring Data Elasticsearch)
elasticsearch系列七:ES Java客户端-Elasticsearch Java client(ES Client 简介.Java REST Client.Java Client.Spri ...
- elasticsearch RestHighLevelClient 使用方法及封装工具
目录 EsClientRHL 更新日志 开发原因: 使用前你应该具有哪些技能 工具功能范围介绍 工具源码结构介绍 开始使用 未来规划 git地址:https://gitee.com/zxporz/ES ...
- ElasticSearch使用RestHighLevelClient进行搜索查询
Elasticsearch Java API有四类client连接方式:TransportClient. RestClient .Jest. Spring_Data_Elasticsearch.其中 ...
- ElasticSearch RestHighLevelClient 通用操作
项目中使用到ElasticSearch作为搜索引擎.而ES的环境搭建自然是十分简单,且本身就适应于分布式环境,因此这块就不多赘述.而其本身特性和查询语句这篇博文不会介绍,如果有机会会深入介绍. 所 ...
- 20191127 Spring Boot官方文档学习(4.11)
4.11.使用NoSQL技术 Spring Data提供了其他项目来帮助您访问各种NoSQL技术,包括: Redis MongoDB Neo4J Solr Elasticsearch Cassandr ...
- 3.3_springBoot2.1.x检索之RestHighLevelClient方式
1.版本依赖 注意对 transport client不了解先阅读官方文档: transport client(传送门) 这里需要版本匹配,如失败查看官网或百度. pom.xml <?xml v ...
- Spring Boot 教程 - Elasticsearch
1. Elasticsearch简介 Elasticsearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearc ...
随机推荐
- Django单元测试中Fixtures用法
在使用单元测试时,有时候需要测试数据库中有数据,这时我们可以使用Django的Fixtures来生成测试数据. 基础配置 在settings.py 中配置如下内容: FIXTURE_DIRS = (' ...
- Python之write与writelines区别
一.传入的参数类型要求不同: 1. file.write(str)需要传入一个字符串做为参数,否则会报错. write( "字符串") with open('20200222.tx ...
- Go Web爬虫并发实现
题目:Exercise: Web Crawler 直接参考了 https://github.com/golang/tour/blob/master/solutions/webcrawler.go 的实 ...
- 二维数组的生成-new的使用
相关的思路来自于下面这个博客:https://blog.csdn.net/samuelcoulee/article/details/8674388 我们对于其中的一个方案进行了实现与测试——借助new ...
- python命令行工具的使用——argparse
argparse是一个常用的库函数,使用它的时候我们在命令行中不仅仅可以运行python文件,更可以零时调整参数,十分方便. 首先,如果你只是希望传一丢丢数据进去,那么只看下面两行就行了 import ...
- selenium获取缓存数据
爬虫呢有时候数据方便有时候登入获得cookies,以及获取他存缓存中的数据 一.获取缓存中的数据其实很简单js注入就好了 localStorage_1 = driver.execute_script( ...
- AE神奇插件TypeMonkey—抖音点赞100W+的文字视频特效是如何做出来的?
现在最火的东西,短视频必须要拥有姓名啦,抖音这些短视频平台风头正盛,我们也常常在上面看到一些文字动画Vlog,看着并不复杂,但是有些却有上百万的点击量,今天介绍的一款神奇插件——TypeMonkey, ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hive安装
实验目的 了解hive的原理和安装方式 学习使用MySQL数据库 使用hive进行基本操作 实验原理 1.Hive Hive是一个数据仓库技术,包括解释器.编译器.优化器,一次将一个sql语句装化为m ...
- Projected coordinate systems 和 wkid
Projected coordinate systems Well-known ID Name Well-known text 2000 Anguilla_1957_British_West_Indi ...
- 本地连接mysql的url写法
一.jdbc:mysql:///中三条斜杠(///) 第三个/代表什么? jdbc:mysql:///testdatabase等同于 jdbc:mysql://localhost:3306/testd ...