spark之RDD练习
一、基础练习
练习一:翻倍列表中的数值并排序列表,并选出其中大于等于10的元素。
//通过并行化生成rdd
val rdd1 = sc.parallelize(List(5, 6, 14, 7, 3, 8, 2, 9, 1, 10))
//对rdd1里的每一个元素乘2然后排序
val rdd2 = rdd1.map(_ * 2).sortBy(x => x, true)
rdd1.collect
res0: Array[Int] = Array(2, 4, 6, 10, 12, 14, 16, 18, 20, 28)
//过滤出大于等于十的元素
val rdd3 = rdd2.filter(_ >= 10)
//将元素以数组的方式在客户端显示
rdd2.collect
res1: Array[Int] = Array(10, 12, 14, 16, 18, 20, 28)
练习二:将字符数组里面的每一个元素先切分在压平。
val rdd1 = sc.parallelize(Array("a b c", "d e f", "h i j"))
//将rdd1里面的每一个元素先切分在压平
val rdd2 = rdd1.flatMap(_.split(' '))
rdd1.collect
res2: Array[String] = Array(a, b, c, d, e, f, h, i, j)
练习三:求两个列表中的交集、并集、及去重后的结果
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
//求并集
val rdd3 = rdd1.union(rdd2)
rdd3.collect
res3: Array[Int] = Array(5, 6, 4, 3, 1, 2, 3, 4)
//去重
rdd3.distinct.collect
res5: Array[Int] = Array(4, 6, 2, 1, 3, 5)
//求交集
val rdd4 = rdd1.intersection(rdd2)
rdd4.collect
res4: Array[Int] = Array(4, 3)
练习四:对List列表中的kv对进行join与union操作
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
//求jion
val rdd3 = rdd1.join(rdd2)
rdd3.collect
res0: Array[(String, (Int, Int))] = Array((tom,(1,1)), (jerry,(3,2)))
//求并集
val rdd4 = rdd1 union rdd2
rdd4.collect
res1: Array[(String, Int)] = Array((tom,1), (jerry,3), (kitty,2), (jerry,2), (tom,1), (shuke,2))
//按key进行分组
val rdd5 = rdd4.groupByKey
rdd5.collect
res5: Array[(String, Iterable[Int])] =
Array((tom,CompactBuffer(1, 1)),
(jerry,CompactBuffer(3, 2)),
(shuke,CompactBuffer(2)),
(kitty,CompactBuffer(2)))
练习五:cogroup与groupByKey的区别
val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
//cogroup
val rdd3 = rdd1.cogroup(rdd2)
//注意cogroup与groupByKey的区别
rdd3.collect
res0: Array[(String, (Iterable[Int], Iterable[Int]))] =
Array((tom,(CompactBuffer(1, 2),CompactBuffer(1))),
(jerry,(CompactBuffer(3),CompactBuffer(2))),
(shuke,(CompactBuffer(),CompactBuffer(2))),
(kitty,(CompactBuffer(2),CompactBuffer())))
//可看出groupByKey中对于每个key只有一个CompactBuffer(2),且CompactBuffer括号内的数值进行了合并成了列表
//而对于cogroup有多少个key就有几个CompactBuffer,且CompactBuffer括号内的数值就是原来的value
练习六:reduce聚合操作
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5))
//reduce聚合
val rdd2 = rdd1.reduce(_ + _)
rdd2: Int = 15
练习七:对List的kv对进行合并后聚合及排序
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)
rdd3.collect
res5: Array[(String, Int)] = Array((tom,1), (jerry,3), (kitty,2), (shuke,1), (jerry,2), (tom,3), (shuke,2), (kitty,5))
//按key进行聚合
val rdd4 = rdd3.reduceByKey(_ + _)
rdd4.collect
res6: Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))
//按value的降序排序
val rdd5 = rdd4.map(t => (t._2, t._1)).sortByKey(false).map(t => (t._2, t._1))
rdd5.collect
res9: Array[(String, Int)] = Array((kitty,7), (jerry,5), (tom,4), (shuke,3))
//第一个map进行kv调换,然后sortByKey(false)降序排序,之后再一次map对kv调换回来
二、Spark RDD的高级算子
1、mapPartitionsWithIndex

接收一个函数参数:
- 第一个参数:分区号
- 第二个参数:分区中的元素
//创建一个函数返回RDD中的每个分区号和元素:
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
def func1(index:Int, iter:Iterator[Int]):Iterator[String] ={
iter.toList.map( x => "[PartID:" + index + ", value=" + x + "]" ).iterator
}
//调用:
rdd1.mapPartitionsWithIndex(func1).collect
res2: Array[String] =
Array([PartID:0, value=1], [PartID:0, value=2], [PartID:0, value=3],
[PartID:0, value=4], [PartID:1, value=5], [PartID:1, value=6],
[PartID:1, value=7], [PartID:1, value=8], [PartID:1, value=9])
2、aggregate
先对局部聚合,再对全局聚合
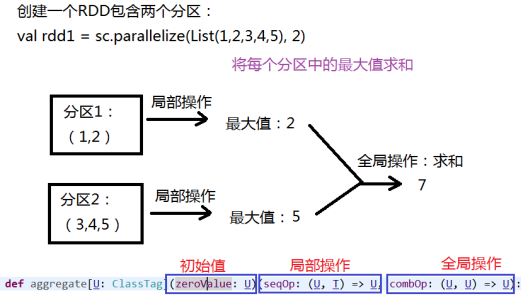
- 查看每个分区中的元素:
//创建一个函数返回RDD中的每个分区号和元素:
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
def func1(index:Int, iter:Iterator[Int]):Iterator[String] ={
iter.toList.map( x => "[PartID:" + index + ", value=" + x + "]" ).iterator
}
//调用:
rdd1.mapPartitionsWithIndex(func1).collect
res2: Array[String] =
Array([PartID:0, value=1], [PartID:0, value=2], [PartID:0, value=3],
[PartID:0, value=4], [PartID:1, value=5], [PartID:1, value=6],
[PartID:1, value=7], [PartID:1, value=8], [PartID:1, value=9])
//将每个分区中的最大值求和(注意:初始值是0):
rdd1.aggregate(0)(math.max(_,_),_+_)
res3: Int = 7
//如果初始值时候10,则结果为:30。
rdd1.aggregate(10)(math.max(_,_),_+_)
res4: Int = 30
//如果是求和,注意:初始值是0:
scala> rdd1.aggregate(0)(_+_,_+_)
res5: Int = 15
//如果初始值是10,则结果是:45
scala> rdd1.aggregate(10)(_+_,_+_)
res6: Int = 45
- 一个字符串的例子:
val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2)
//修改一下刚才的查看分区元素的函数
scala> def func2(index:Int, iter:Iterator[(String)]):Iterator[String]=
{iter.toList.map(x=>"partID:" + index + ",val:" + x + "]").iterator}
//两个分区中的元素:
scala> rdd2.mapPartitionsWithIndex(func2).collect
res7: Array[String] = Array(partID:0,val:a], partID:0,val:b], partID:0,val:c], partID:1,val:d], partID:1,val:e], partID:1,val:f])
//运行结果:
scala> rdd2.aggregate("")(_+_,_+_)
res1: String = abcdef
scala> rdd2.aggregate("|")(_+_,_+_)
res2: String = ||abc|def
- 更复杂一点的例子
scala> val rdd3 = sc.parallelize(List("12","23","345","4567"),2)
//最后是x+y
scala> rdd3.aggregate("")((x,y)=>math.max(x.length,y.length).toString,(x,y)=>x+y)
res5: String = 24
//最后是y+x
scala> rdd3.aggregate("")((x,y)=>math.max(x.length,y.length).toString,(x,y)=>y+x)
res13: String = 42
val rdd4 = sc.parallelize(List("12","23","345",""),2)
//最后是x+y
scala> rdd4.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y)=>x+y)
res17: String = 10
//最后是y+x
scala> rdd4.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y)=>y+x)
res18: String = 01
spark之RDD练习的更多相关文章
- [Spark] Spark的RDD编程
本篇博客中的操作都在 ./bin/pyspark 中执行. RDD,即弹性分布式数据集(Resilient Distributed Dataset),是Spark对数据的核心抽象.RDD是分布式元素的 ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- [Spark][Python][RDD][DataFrame]从 RDD 构造 DataFrame 例子
[Spark][Python][RDD][DataFrame]从 RDD 构造 DataFrame 例子 from pyspark.sql.types import * schema = Struct ...
- spark中RDD的转化操作和行动操作
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark之 RDD
简介 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合. Resilien ...
- 解读Spark Streaming RDD的全生命周期
本节主要内容: 一.DStream与RDD关系的彻底的研究 二.StreamingRDD的生成彻底研究 Spark Streaming RDD思考三个关键的问题: RDD本身是基本对象,根据一定时间定 ...
随机推荐
- 【转载】signal(SIGCHLD, SIG_IGN)和signal(SIGPIPE, SIG_IGN)
来源:https://blog.csdn.net/guotao1983/article/details/82118218 signal(SIGCHLD, SIG_IGN) 因为并发服务器常常fork很 ...
- Android之ScrollView嵌套ListView冲突 (listView只显示一行)
在ScrollView中嵌套使用ListView,ListView只会显示一行多一点.两者进行嵌套,即会发生冲突.由于ListView本身都继承于ScrollView,一旦在ScrollView中嵌套 ...
- js文本复制插件&vue
/* HTML: * <a href="javascript:;" class="copy" data-clipboard-text="copy ...
- Cesium案例解析(五)——3DTilesPhotogrammetry摄影测量3DTiles数据
目录 1. 概述 2. 案例 3. 结果 1. 概述 3D Tiles是用于传输和渲染大规模3D地理空间数据的格式,例如摄影测量,3D建筑,BIM / CAD,实例化特征和点云等.与常规的模型文件格式 ...
- Android Studio 学习笔记(四):Adapter和RecyclerView说明
在现版本中,滚动控件有多种,而相比于ListView,GridView,RecyclerView的用途更广,因此将前两者作为Adapter适配器的引入,再对RecyclerView进行简单讲解. MV ...
- SSM项目下Druid连接池的配置及数据源监控的使用
一,连接池的配置 在pom.xml中添加,druid的maven信息 <dependency> <groupId>com.alibaba</groupId> < ...
- 【57】目标检测之Anchor Boxes
Anchor Boxes 到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,你可以这么做,就是使用anchor box这个概念. 我们还是先吃一颗栗子 ...
- DAG求最短路--TSP变形--状压dp
DAG状压dp的一种 题目: $m$个城市,$n$张车票,第i张车票上的时间是$t_i$, 求从$a$到$b$的最短时间,如果无法到达则输出“impossible” 解法: 考虑状态:“现在在城市$v ...
- spark 报错 InvalidClassException: no valid constructor
2019-03-19 02:50:24 WARN TaskSetManager:66 - Lost task 1.0 in stage 0.0 (TID 1, 1.2.3.4, executor 1) ...
- #《Essential C++》读书笔记# 第一章 C++ 编程基础
前言 Stanley B.Lippman 先生所著的<C++ Primer>是学习C++的一本非常优秀的教科书,但<C++ Primer>作为一本大部头书,显然不适合所有的初学 ...