(三) DRF 序列化
一、单表的GET和POST:
使用serializers序列化,针对每一个表,需要单独写函数。一般会写在views.py里面,但是这样做,会导致整个文件代码过长。需要分离出来!
在app01(应用名)目录下,创建文件app01_serializers.py,表示自定义序列化
from app01 import models
from rest_framework import serializers # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
depth = # 深度为2
views.py中
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化 class Comment(APIView):
def get(self, request):
res = {"code":} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return JsonResponse(res)
二、Response
Rest framework 引入了Response对象,它是一个TemplateResponse类型,并根据客户端需求正确返回需要的类型。
使用前,需要导入模块Response
from rest_framework.response import Response
举例:
修改视图Comment中的get方法,将JsonResponse改成Response
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化
from rest_framework.response import Response
# Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return Response(res)
三、serializers校验
举例:判断空数据
修改views.py,添加post逻辑代码。注意:使用is_valid校验
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化
from rest_framework.response import Response # Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return Response(res) def post(self, request):
res = {"code": }
# 去提交的数据
comment_data = self.request.data
# 对用户提交的数据做校验
ser_obj = app01_serializers.CommentSerializer(data=comment_data)
if ser_obj.is_valid():
# 表示数据没问题,可以创建
pass
else:
# 表示数据有问题
res["code"] =
res["error"] = ser_obj.errors
return Response(res)
使用postman发送一个空数据的post请求
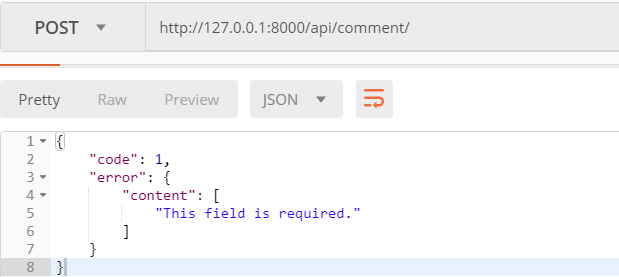
它返回This field is required,表示次字段不能为空!
错误信息中文显示
修改app01_serializers.py,使用extra_kwargs指定错误信息
from app01 import models
from rest_framework import serializers # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
depth = # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
}
重启django,重新发送空的post请求
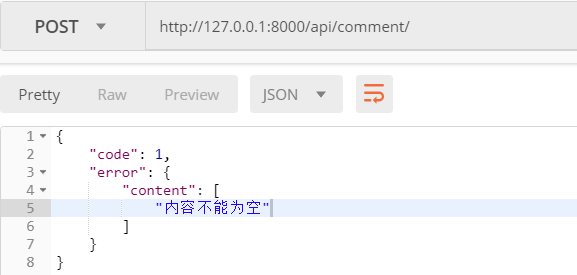
四、外键的GET和POST
序列化校验
上面虽然只发送了content参数,就让通过了,显然不合理!为什么呢?
因为app01_comment表有2个字段,content和article。这2个字段都应该校验才对!
因为serializers默认校验时,排除了外键字段。比如article
要对外键进行校验,必须在extra_kwargs中指定外键字段
修改app01_serializers.py,注意关闭depth参数
当序列化类MATE中定义了depth时,这个序列化类中引用字段(外键)则自动变为只读,所以进行更新或者创建操作的时候不能使用此序列化类
大概意思就是,使用了depth参数,会忽略外键字段
完整代码如下:
from app01 import models
from rest_framework import serializers # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
# depth = # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
"article": {
"error_messages": {
"required": '文章不能为空'
}
}
}
再次发送post请求,还是只有一个参数content
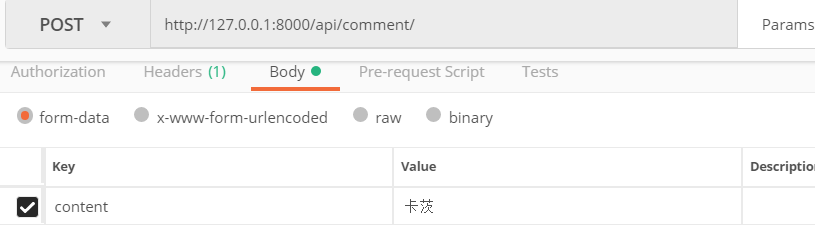
查看执行结果:
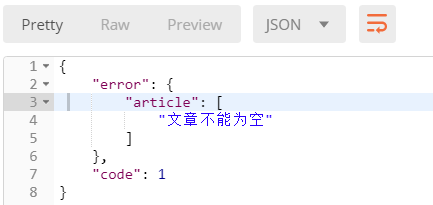
发送正确的2个参数
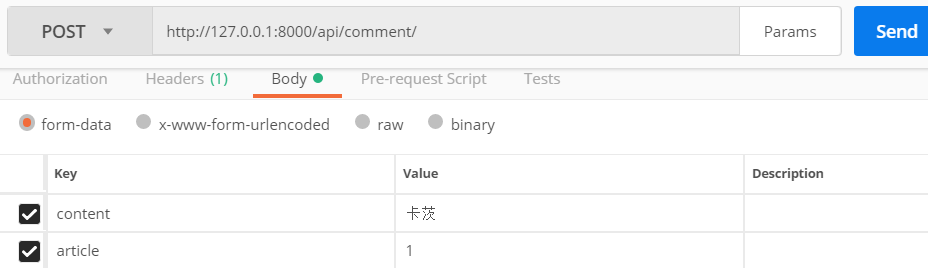
查看结果
read_only=True
read_only:True表示不允许用户自己上传,只能用于api的输出。如果某个字段设置了read_only=True,那么就不需要进行数据验证,只会在返回时,将这个字段序列化后返回
举例:允许article不校验
修改app01_serializers.py,加入一行代码
article = serializers.SerializerMethodField(read_only=True)
from app01 import models
from rest_framework import serializers # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
article = serializers.SerializerMethodField(read_only=True) class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
# depth = # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
"article": {
"error_messages": {
"required": '文章不能为空'
}
}
}
保存POST数据
修改views.py,在post方法中,将pass改成ser_obj.save(),完整代码如下:
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化
from rest_framework.response import Response # Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return Response(res) def post(self, request):
res = {"code": }
# 去提交的数据
comment_data = self.request.data
# 对用户提交的数据做校验
ser_obj = app01_serializers.CommentSerializer(data=comment_data)
if ser_obj.is_valid():
# 表示数据没问题,可以创建
ser_obj.save()
else:
# 表示数据有问题
res["code"] =
res["error"] = ser_obj.errors
return Response(res)
修改app01_serializers.py,注释掉read_only=True
发送2个正确的参数
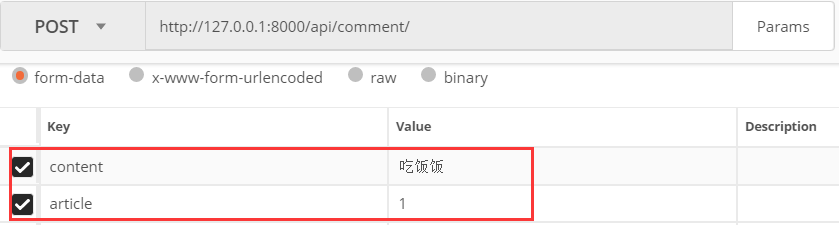
查看app01_comment表记录,发现多了一条记录

为什么直接save,就可以保存了呢?
因为它将校验过的数据传过去了,就好像form组件中的self.cleaned_data一样
本质上还是调用ORM的create()方法
五、非serializer 的验证条件
比如重置密码、修改密码都需要手机验证码。但是用户 model 里面并没有验证码这个选项
需要使用validate,用于做校验的钩子函数,类似于form组件的clean_字段名
使用时,需要导入模块,用来输出错误信息
from rest_framework.validators import ValidationError
局部钩子
validate_字段名,表示局部钩子。
举例:评论的内容中,不能包含 "草"
修改app01_serializers.py,校验评论内容
from app01 import models
from rest_framework import serializers
from rest_framework.validators import ValidationError # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
# article = serializers.SerializerMethodField(read_only=True) # 用于做校验的钩子函数,类似于form组件的clean_字段名
def validate_content(self, value):
if '草' in value:
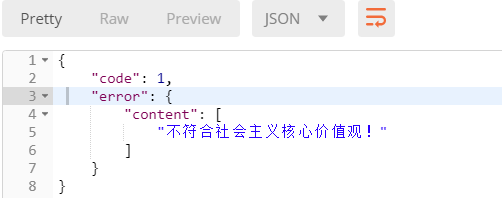
raise ValidationError('不符合社会主义核心价值观!')
else:
return value class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
# depth = # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
"article": {
"error_messages": {
"required": '文章不能为空'
}
}
}
使用postman发送包含关键字的评论
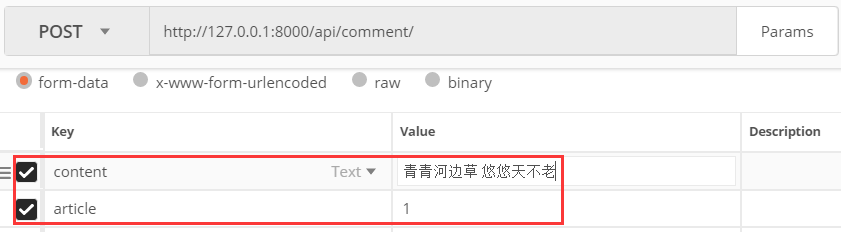
查看返回结果:
全局钩子
validate,表示全局钩子。
比如在用户注册时,我们需要填写验证码,这个验证码只需要验证,不需要保存到用户这个Model中:
def validate(self, attrs):
del attrs["code"]
return attrs
六、超链接的序列化
HyperlinkedModelSerializer类类似于ModelSerializer类,不同之处在于它使用超链接来表示关联关系而不是主键。
默认情况下序列化器将包含一个url字段而不是主键字段。
url字段将使用HyperlinkedIdentityField字段来表示,模型的任何关联都将使用HyperlinkedRelatedField字段来表示。
你可以通过将主键添加到fields选项中来显式的包含,例如:
class AccountSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Account
fields = ('url', 'id', 'account_name', 'users', 'created')
绝对和相对URL
当实例化一个HyperlinkedModelSerializer时,你必须在序列化器的上下文中包含当前的request值,例如:
serializer = AccountSerializer(queryset, context={'request': request})
这样做将确保超链接可以包含恰当的主机名,一边生成完全限定的URL,例如:
http://api.example.com/accounts/1/
而不是相对的URL,例如:
/accounts//
如果你真的要使用相对URL,你应该明确的在序列化器上下文中传递一个{'request': None}。
需求:要求api返回结果中,school展示的是超链接
修改app01_urls.py,增加路由
urlpatterns = [
# 文章
url(r'article/', views.Article.as_view()),
url(r'article/(?P<pk>\d+)', views.ArticleDetail.as_view(), name='article-detail'),
# 学校
url(r'school/(?P<id>\d+)', views.SchoolDetail.as_view(), name='school-detail'),
# 评论
url(r'comment/', views.Comment.as_view()),
]
指定name是为做反向链接,它能解析出绝对url
序列化
修改app01_serializers.py
from app01 import models
from rest_framework import serializers
from rest_framework.validators import ValidationError # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
# article = serializers.SerializerMethodField(read_only=True) # 用于做校验的钩子函数,类似于form组件的clean_字段名
def validate_content(self, value):
if '草' in value:
raise ValidationError('不符合社会主义核心价值观!')
else:
return value #全局的钩子
def validate(self, attrs):
# self.validated_data # 经过校验的数据 类似于form组件中的cleaned_data
# 全局钩子
pass class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
# depth = # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
"article": {
"error_messages": {
"required": '文章不能为空'
}
}
} # 文章的序列化类
class ArticleModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article # 绑定的ORM类是哪一个
fields = "__all__" # ["id", "title", "type"]
# depth = # 官方推荐不超过10层 # 文章超链接序列化
class ArticleHyperLinkedSerializer(serializers.HyperlinkedModelSerializer):
school = serializers.HyperlinkedIdentityField(view_name='school-detail', lookup_url_kwarg='id') class Meta:
model = models.Article # 绑定的ORM类是哪一个
fields = ["id", "title", "type", "school"] # 学校的序列化
class SchoolSerializer(serializers.ModelSerializer):
class Meta:
model = models.School
fields = "__all__"
参数解释:
source 表示来源
lookup_field 表示查找字段,默认使用的pk, 指的是反向生成URL的时候, 路由中分组命名匹配的value
lookup_url_kwarg 表示路由查找的参数,pk表示主键, 默认使用pk,指的是反向生成URL的时候 路由中的分组命名匹配的key
view_name 它是指urls定义的name值,一定要一一对应。 默认使用 表名-detail
修改views.py,增加视图函数
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化
from rest_framework.response import Response # Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return Response(res) def post(self, request):
res = {"code": }
# 去提交的数据
comment_data = self.request.data
# 对用户提交的数据做校验
ser_obj = app01_serializers.CommentSerializer(data=comment_data)
if ser_obj.is_valid():
# 表示数据没问题,可以创建
ser_obj.save()
else:
# 表示数据有问题
res["code"] =
res["error"] = ser_obj.errors
return Response(res) # return HttpResponse("创建新评论") def put(self, request):
return HttpResponse("修改评论") def delete(self, request):
return HttpResponse("删除评论") # 文章CBV
class Article(APIView):
def get(self, request):
res = {"code": }
all_article = models.Article.objects.all()
ser_obj = app01_serializers.ArticleHyperLinkedSerializer(all_article, many=True, context={'request': request})
res["data"] = ser_obj.data
return Response(res) def post(self, request):
res = {"code": }
ser_obj = app01_serializers.ArticleModelSerializer(data=self.request.data)
if ser_obj.is_valid():
ser_obj.save()
else:
res["code"] =
res["error"] = ser_obj.errors
return Response(res) # 文章详情CBV
class ArticleDetail(APIView):
def get(self, request, pk):
res = {"code": }
article_obj = models.Article.objects.filter(pk=pk).first()
# 序列化
ser_obj = app01_serializers.ArticleHyperLinkedSerializer(article_obj, context={'request': request})
res["data"] = ser_obj.data
return Response(res) # 学校详情CBV
class SchoolDetail(APIView):
def get(self, request, id):
res = {"code": }
school_obj = models.School.objects.filter(pk=id).first()
ser_obj = app01_serializers.SchoolSerializer(school_obj, context={'request': request})
res["data"] = ser_obj.data
return Response(res)
参数解释:
id 表示参数,它和url的参数,是一一对应的
content 表示上下文
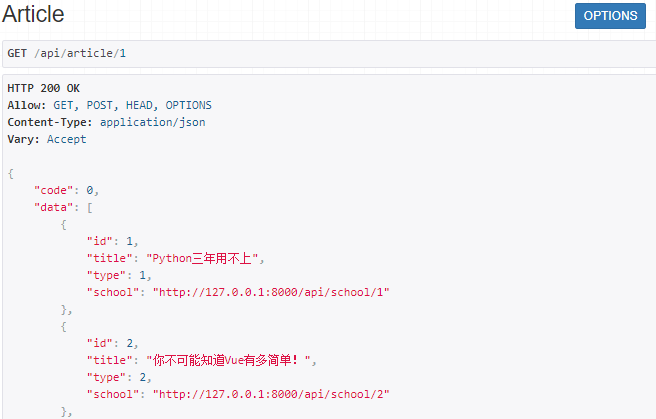
重启django项目,访问网页:
http://127.0.0.1:8000/api/article/1
效果如下:
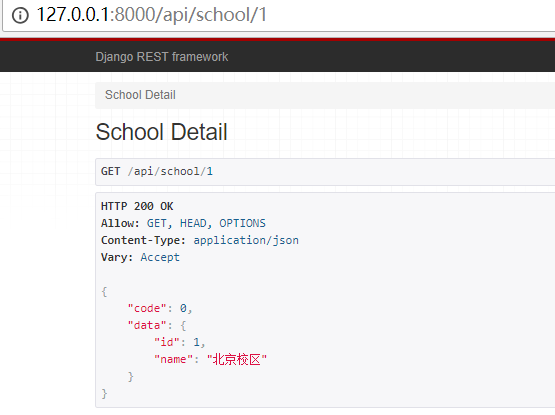
点击第一个链接,效果如下:
(三) DRF 序列化的更多相关文章
- python 全栈开发,Day99(作业讲解,DRF版本,DRF分页,DRF序列化进阶)
昨日内容回顾 1. 为什么要做前后端分离? - 前后端交给不同的人来编写,职责划分明确. - API (IOS,安卓,PC,微信小程序...) - vue.js等框架编写前端时,会比之前写jQuery ...
- python 全栈开发,Day95(RESTful API介绍,基于Django实现RESTful API,DRF 序列化)
昨日内容回顾 1. rest framework serializer(序列化)的简单使用 QuerySet([ obj, obj, obj]) --> JSON格式数据 0. 安装和导入: p ...
- Django的DRF序列化方法
安装rest_framework -- pip install djangorestframework -- 注册rest_framework序列化 -- Python--json -- 第一版 用v ...
- drf序列化和反序列化
目录 drf序列化和反序列化 一.自定义序列化 1.1 设置国际化 二.通过视图类的序列化和反序列化 三.ModelSerializer类实现序列化和反序列化 drf序列化和反序列化 一.自定义序列化 ...
- DRF 序列化组件 模型层中参数补充
一. DRF序列化 django自带有序列化组件,但是相比rest_framework的序列化较差,所以这就不提django自带的序列化组件了. 首先rest_framework的序列化组件使用同fr ...
- Django(44)drf序列化源码分析(1)
序列化与反序列化 一般后端数据返回给前端的数据格式都是json格式,简单易懂,但是我们使用的语言本身并不是json格式,像我们使用的Python如果直接返回给前端,前端用的javascript语言 ...
- 大型分布式C++框架《三:序列化与反序列化》
一.前言 个人感觉序列化简单来说就是按一定规则组包.反序列化就是按组包时的规则来接包.正常来说.序列化不会很难.不会很复杂.因为过于复杂的序列化协议会导致较长的解析时间,这可能会使得序列化和反序列化 ...
- DRF 序列化组件
Serializers 序列化组件 Django的序列化方法 class BooksView(View): def get(self, request): book_list = Book.objec ...
- C#对象的三种序列化
要让一个对象支持.Net序列化服务,用户必须为每一个关联的类加上[Serializable]特性.如果类中有些成员不适合参与序列化(比如:密码字段),可以在这些域前加上[NonSerialized]特 ...
随机推荐
- python序列函数
zip:序列并行处理 >>> name=['ghostwu','wukong','bajie'] >>> age=['] >>> sex=['ma ...
- linux上SVN服务器搭建后windows无法连接到服务器
忙了一天,linux搭建svn服务器,搭建好后windows一直无法连接,总觉得自己对: 原因: 1.以后禁止用sublime在本地编辑好后用XFTP上传到服务器(这样会导致文件权限问题,不能替换成功 ...
- Python数据模型
引言 像大多数人一样,我在对一直传统的面向过程语言C一知半解之后,走进了面向对象的世界,尽管对OOP一无所知,还好Python还保留有函数式编程,这使得我才不那么抵触,直到现在,习惯了面向对象之后,也 ...
- 编译64位cu文件的设置
作者:朱金灿 来源:http://blog.csdn.net/clever101 CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运 ...
- SQLServer 学习笔记之超详细基础SQL语句 Part 10
Sqlserver 学习笔记 by:授客 QQ:1033553122 -----------------------接Part 9------------------- 删除约束的语法 ALTER T ...
- CSS3 中的 box-sizing属性
语法: box-sizing: content-text | border-box | inherit; content-box(默认): 宽度和高度分别应用元素的内容框:在宽度和高度之外绘制元素的内 ...
- 数据分析——Matplotlib图形绘制
创建画布或子图 函数名称 函数作用 plt.figure 创建一个空白画布,可以指定画布大小,像素. figure.add_subplot 创建并选中子图,可以指定子图的行数,列数,与选中图片编号. ...
- deep learning自学知识积累笔记
推荐系统的演变过程 协同过滤(英雄所见略同)思想为类似喜好的人的选择必然也类似.比如小学男生普遍喜欢打手游,中年大叔普遍喜欢射雕英雄传 随后有了SVD奇异值分解,但是SVD要求不能太稀疏,因此有了隐语 ...
- 控制台输出 mybatis 中的sql语句
控制台输出 mybatis 中的sql语句 在 log4j.xml 文件中 增加如下配置 <!-- mybatis 输出的sql,DEBUG级别 --> <logger name=& ...
- ASP.NET动态引用样式表(css)和脚本(js)文件
// 引入js文件 HtmlGenericControl scriptControl = new HtmlGenericControl("script"); scriptContr ...