zookeeper的安装与配置(单机和集群)
单机模式:
1、首先去官网下载zookeeper的包 zookeeper-3.4.10.tar.gz
2、用FTP上传到服务器或者Linux虚拟机的/usr/local目录下
3、解压文件tar -zxvf zookeeper-3.4.10.tar.gz
4、在conf文件夹下新建zoo.cfg文件,或者使用里面自带的zoo_sample.cfg,重新cp zoo_sample.cfg zoo.cfg
zoo.cfg文件内容:
tickTime=2000
dataDir=/Users/zookeeper/data
dataLogDir=/Users/zookeeper/logs
clientPort=4180
至此, zookeeper的单机模式已经配置好了. 启动server只需运行脚本:
5、运行server脚本
./zkServer.sh start
6、Server启动之后, 就可以启动client连接server了, 执行脚本:
./zkCli.sh -server localhost:4180
(本次操作还是在本server上操作,你看localhost了嘛)
伪集群模式:
所谓伪集群, 是指在单台机器中启动多个zookeeper进程, 并组成一个集群. 以启动3个zookeeper进程为例.
1、首先去官网下载zookeeper的包 zookeeper-3.4.10.tar.gz
2、用FTP文上传到/usr/local下
3、解压文件tar -zxvf zookeeper-3.4.10.tar.gz
4、复制3分zookeeper文件
cp -r zookeeper-3.4.10.tar.gz zookeeper0
cp -r zookeeper-3.4.10.tar.gz zookeeper1
cp -r zookeeper-3.4.10.tar.gz zookeeper2
5、在每个zookeeper/conf/新建zoo.cfg文件
① zookeeper0下的zoo.cfg文件
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/Users/zookeeper0/data
dataLogDir=/Users/zookeeper0/logs
clientPort=4180
server.0=127.0.0.1:8880:7770
server.1=127.0.0.1:8881:7771
server.2=127.0.0.1:8882:7772
② zookeeper1下的zoo.cfg文件
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/Users/zookeeper1/data
dataLogDir=/Users/zookeeper1/logs
clientPort=4181
server.0=127.0.0.1:8880:7770
server.1=127.0.0.1:8881:7771
server.2=127.0.0.1:8882:7772
③ zookeeper2下的zoo.cfg文件
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/Users/zookeeper2/data
dataLogDir=/Users/zookeeper2/logs
clientPort=4182
server.0=127.0.0.1:8880:7770
server.1=127.0.0.1:8881:7771
server.2=127.0.0.1:8882:7772
发现只有dataDir和dataLogDir还有clientPort这三个参数不一致,其他参数完全一致。
6、在这三个datadir配置的路径下/Users/zookeeper0、1、2上增加myid文件,里面依次填上0、1、2。
数字0、1、2和每个conf/zoo.cfg中的server.0、server.1、server.2的数字一一对应,让zookeeper知道你是哪个server
7、分别给这3个zookeeper节点开启服务
./zkServer.sh start
开启后,最好每个zookeeper都查看状态看一下服务是否启动:(因为start的启动的信息不准确)
./zkServer.sh status
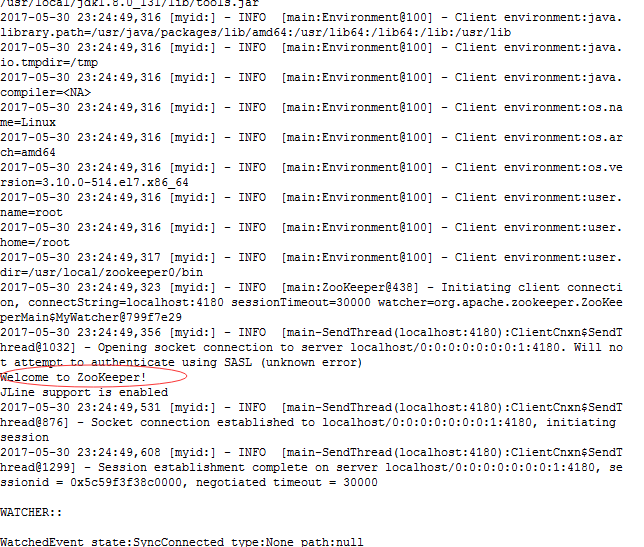
8、用客户端连接:
在任意一台server端,执行:
./zkCli.sh -server localhost:
看到以下信息,就恭喜你成功了。
集群模式:
集群模式, 各server部署在不同的机器上, 因此各server的conf/zoo.cfg文件可以完全一样(是所有都一样)
他们的zookeeper的conf下的zoo.cfg文件为:
tickTime=
initLimit=
syncLimit=
dataDir=/home/zookeeper/data
dataLogDir=/home/zookeeper/logs
clientPort=
server.=10.1.39.43::
server.=10.1.39.44::
server.=10.1.39.45::
部署了3台zookeeper server, 分别部署在10.1.39.43, 10.1.39.44, 10.1.39.45上。
各server的dataDir目录下的myid文件中的数字必须不同。
10.1.39.43 server的myid为1
10.1.39.44 server的myid为2
10.1.39.45 server的myid为3
至此,所有的安装与部署就都搞定了。
------------------------------------------------------------------------------
下面还有一些知识点:
ZooKeeper服务命令:
在准备好相应的配置之后,可以直接通过zkServer.sh 这个脚本进行服务的相关操作
- 1. 启动ZK服务: sh bin/zkServer.sh start
- 2. 查看ZK服务状态: sh bin/zkServer.sh status
- 3. 停止ZK服务: sh bin/zkServer.sh stop
- 4. 重启ZK服务: sh bin/zkServer.sh restart
zoo.cfg配置详解:
tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,每个tickTime 时间就会发送一个心跳。
dataDir:Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
clientPort:客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
initLimit:Leader和Follower初始化连接时最长能忍受多少个心跳时间间隔数。总的时间长度就是 5*2000=10 秒。
syncLimit:Leader 与 Follower之间发送消息,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒。
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
myid文件:
除了修改 zoo.cfg 配置文件,集群模式下还要配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面就有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个server。
server.1=10.1.39.43:2888:3888,很多人不理解为啥后面有两个端口?解释一下:
2888:标识这个服务器与集群中的leader服务器交换信息的端口
3888:leader挂掉时专门用来进行选举leader所用的端口
zookeeper的安装与配置(单机和集群)的更多相关文章
- ZooKeeper 的安装和配置---单机和集群
如题本文介绍的是ZooKeeper 的安装和配置过程,此过程非常简单,关键是如何应用(将放在下节及相关节中介绍). 单机安装.配置: 安装非常简单,只要获取到 Zookeeper 的压缩包并解压到某个 ...
- zookeeper安装和配置(单机+伪集群+集群)
#单机模式 解压到合适目录. 进入zookeeper目录下的conf子目录, 复制zoo_sample.cfg-->zoo.cfg(如果没有data和logs就新建):tickTime=2000 ...
- zookeeper之一 安装和配置(单机+集群)
这里我以zookeeper3.4.10.tar.gz来演示安装,安装到/usr/local/soft目录下. 一.单机版配置 1.安装和配置 #.下载 wget http://apache.fayea ...
- centos7环境下zookeeper的搭建步骤之单机伪集群
首先说明:这里是单机版的伪集群搭建 第一步:下载zookeeper:zookeeper的下载地址: http://mirror.bit.edu.cn/apache/zookeeper/ 第二步:安装: ...
- Zookeeper集群搭建(多节点,单机伪集群,Docker集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- ZooKeeper的安装、配置、启动和使用(一)——单机模式
ZooKeeper的安装.配置.启动和使用(一)——单机模式 ZooKeeper的安装非常简单,它的工作模式分为单机模式.集群模式和伪集群模式,本博客旨在总结ZooKeeper单机模式下如何安装.配置 ...
- hbase单机及集群安装配置,整合到hadoop
问题导读:1.配置的是谁的目录conf/hbase-site.xml,如何配置hbase.rootdir2.如何启动hbase?3.如何进入hbase shell?4.ssh如何达到互通?5.不安装N ...
- 浅谈 zookeeper 原理,安装和配置
当前云计算流行, 单一机器额的处理能力已经不能满足我们的需求,不得不采用大量的服务集群.服务集群对外提供服务的过程中,有很多的配置需要随时更新,服务间需要协调工作,那么这些信息如何推送到各个节点?并且 ...
- Zookeeper的安装的配置
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt192 安装和配置详解 本文介绍的 Zookeeper 是以 3.2.2 这个 ...
- 【运维技术】Zookeeper单机以及集群搭建教程
Zookeeper单机以及集群搭建教程 单机搭建 单机安装以及启动 安装zookeeper的前提是必须有java环境 # 选择目录进行下载安装 cd /app # 下载zk,可以去官方网站下载,自己上 ...
随机推荐
- 字符串方法 charAt()/charCodeAt()/indexOf()/lastIndexOf()
charAt()与charCodeAt() 语法:stringObject.charAt(index) 功能:返回stringObject中index位置的字符 语法:stringObject.cha ...
- java web 大总结
C/s架构: socket.serversocket.awt/swing做一个客户端软件 建好socket连接后,通过IO流交换数据.数据格式由各个开发者自己确定,B/C架 ...
- stacking过程
图解stacking原理: 上半部分是用一个基础模型进行5折交叉验证,如:用XGBoost作为基础模型Model1,5折交叉验证就是先拿出四折作为training data,另外一折作为testing ...
- tp5中代替tp3.2中的一些方法
U方法 U方法是TP中的生成路由的内置方法,现在这个方法可以完全使用url方法替换 I方法 之前的TP有个I方法用来接收请求参数,目前可以使用input方法替代 C方法 c方法被config方法代替
- Router components
Input Unit The Input unit contains virtual channel buffers and an input VC arbiter. Route Info: use ...
- 535 5.7.8 Error: authentication failed: generic failure安装EMOS时SMTP测试报错
按照官方手册安装EMOS时候,进行到SMTP认证测试的时候报如下错: 535 5.7.8 Error: authentication failed: generic failure 原来是因为之前关闭 ...
- s5-15 开放的最短路径优先_OSPF
L-S路由协议的实例—OSPF 开放的路径优先(Open Shortest Path First) 使用图(graph)来表述真实的网络 - 每个路由器/Lan都是一个节点 - 测量代价/量度(met ...
- SHELL脚本之awk妙用
对于一个sougou文本文件,解压后大概4G,要求在其基础上切出第一列时间年月日时分秒增加在列中,作为hive的一个索引.先将文件head一下展示格式: [root@Master date]# hea ...
- 学以致用二---配置Centos7.2 基本环境
Centos 7 虚拟机安装好后,接下来该配置环境了. 一.查看系统版本 cat /etc/redhat-release 二.修改主机名 /etc/hostname 注意,hostname里的内容为l ...
- estimator = KerasClassifier
如何在scikit-learn模型中使用Keras 通过用 KerasClassifier 或 KerasRegressor 类包装Keras模型,可将其用于scikit-learn. 要使用这些包装 ...