Kafka分布式集群部署
这个是kafka的官网地址:http://kafka.apache.org/
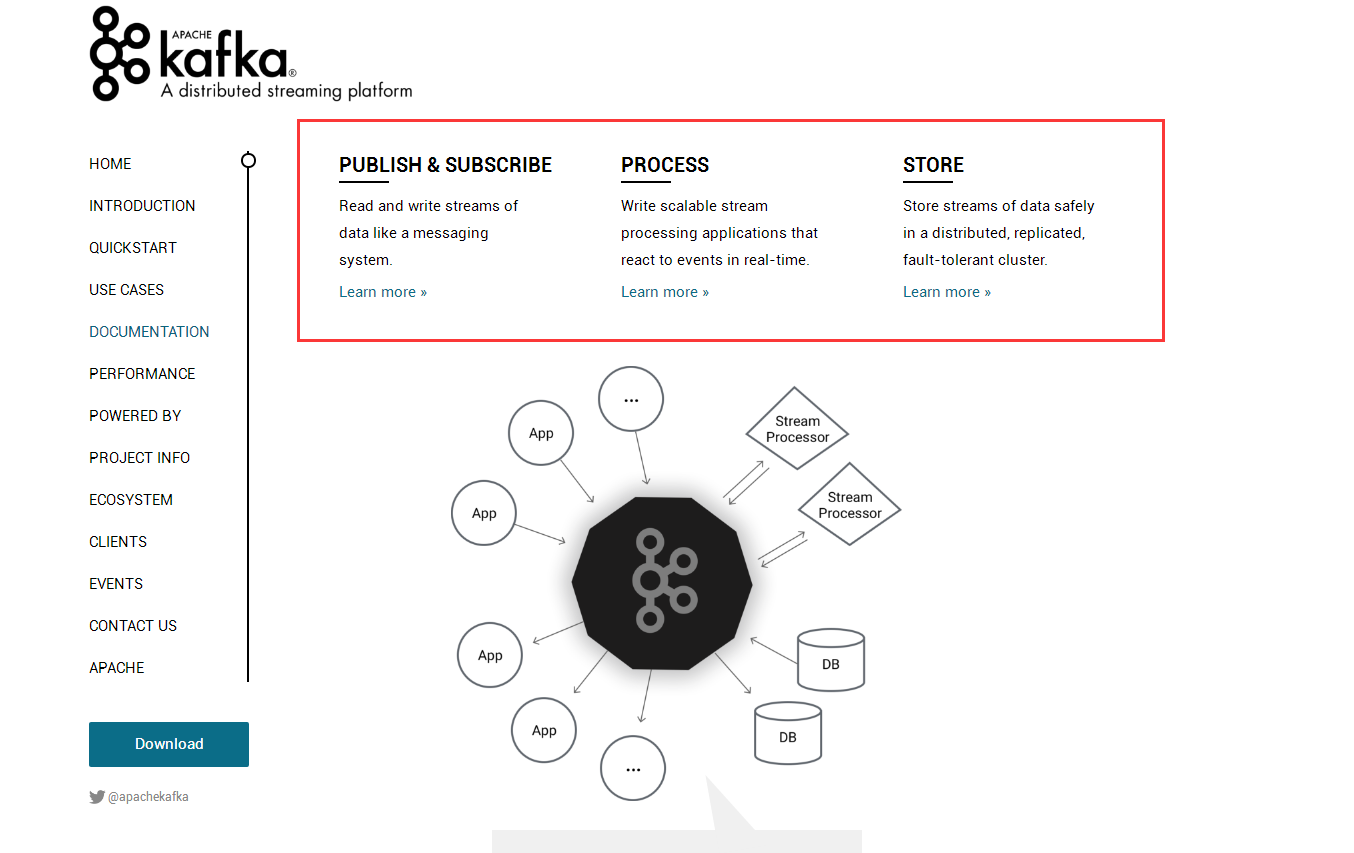
1、kafka是一个消息系统。
2、kafka对流数据可以高效的实时处理。
3、分布式集群的环境下能够保证数据的安全。

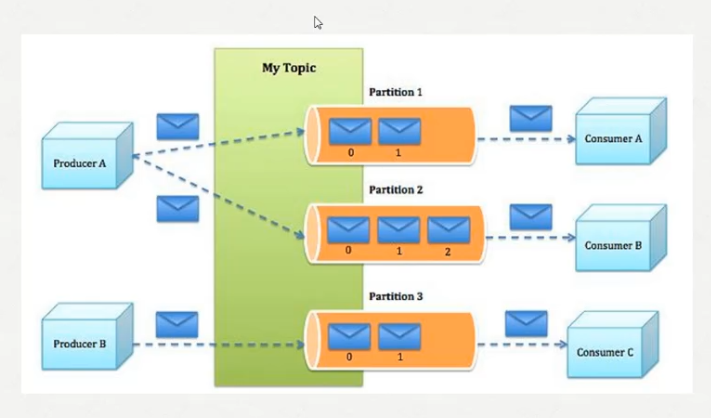
kafka的下载地址:http://kafka.apache.org/downloads
把安装包上传


把权限修改一下
解压

配置kafka


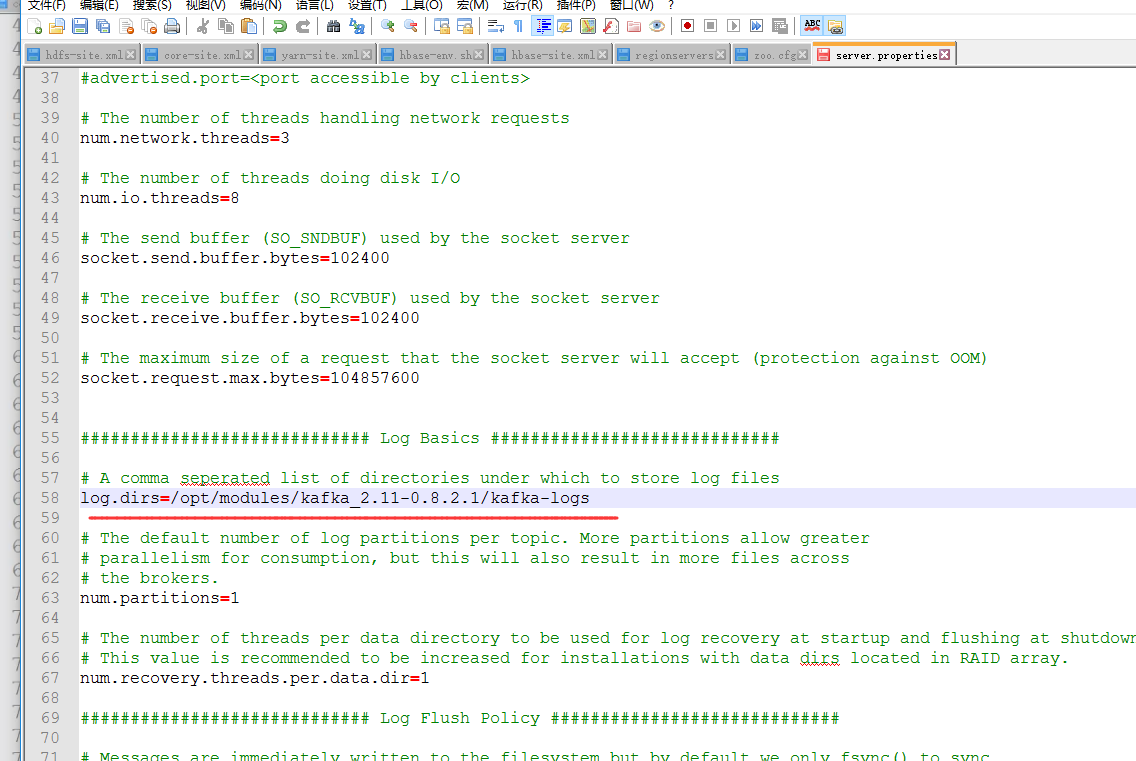
这个路径来自这里
配置zookeeper
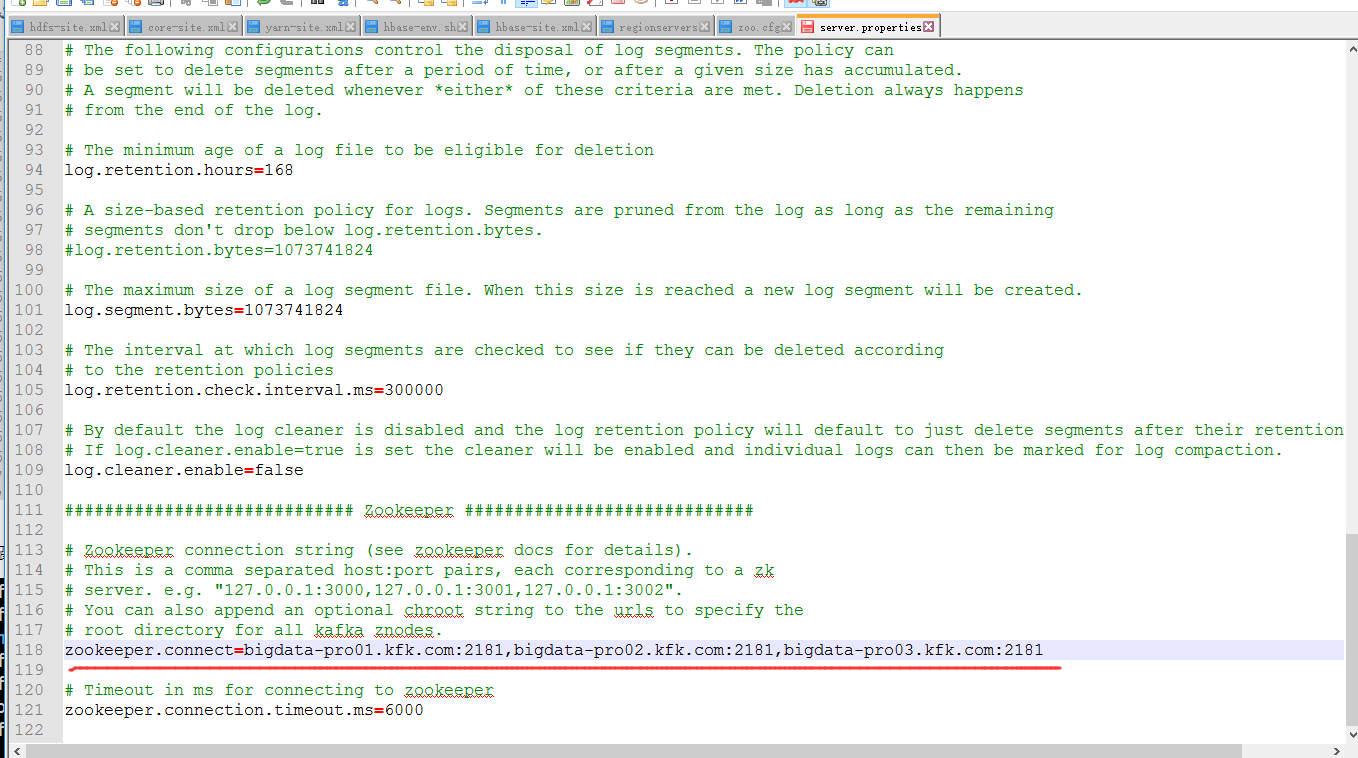
把这里改成kafka所在节点的主机名
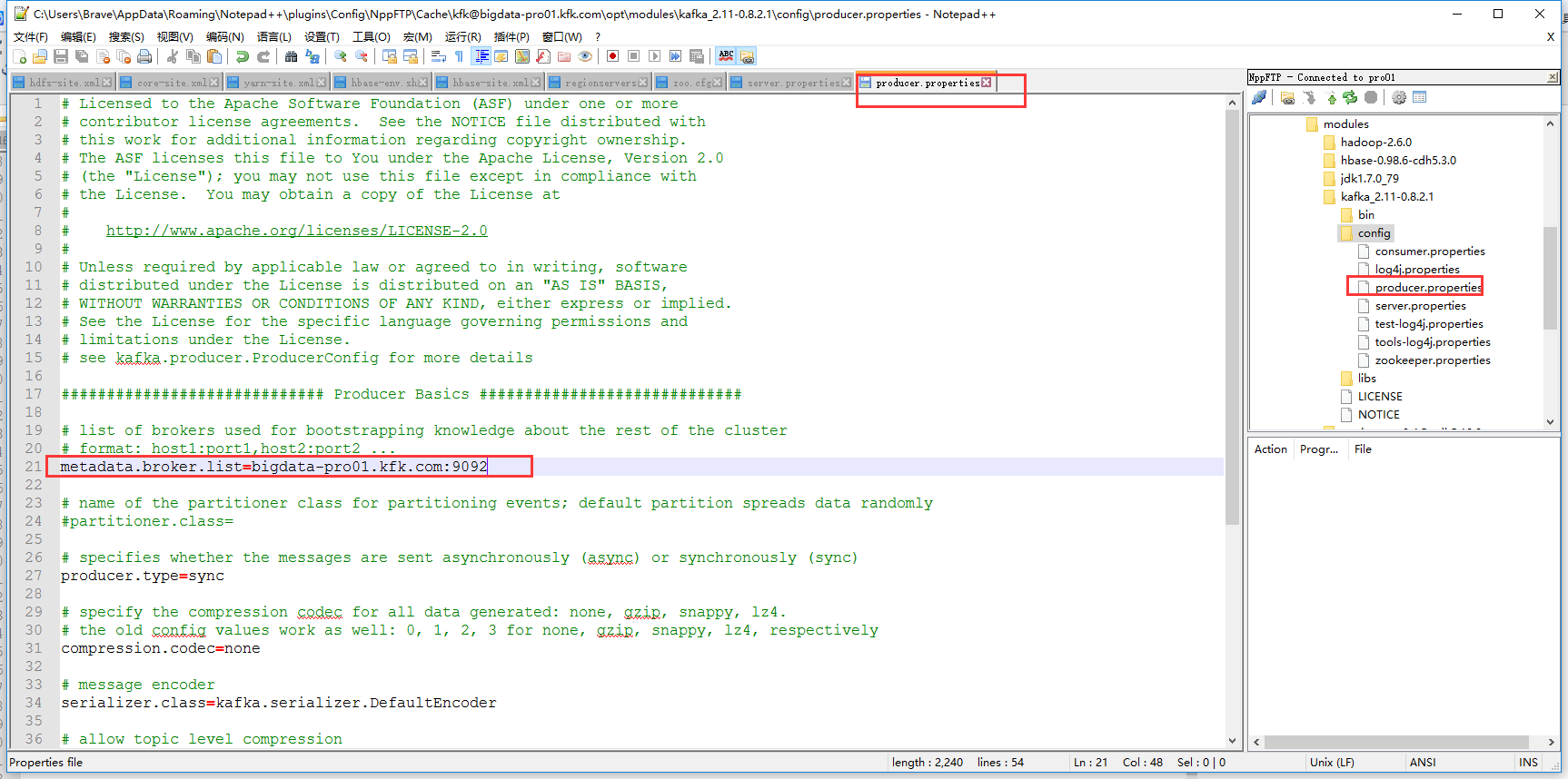
kafka的配置文件现在配置完了,把kafka分发到其他两台机器上


分发过去之后,把配置文件修改一下


第三台机器也是一样


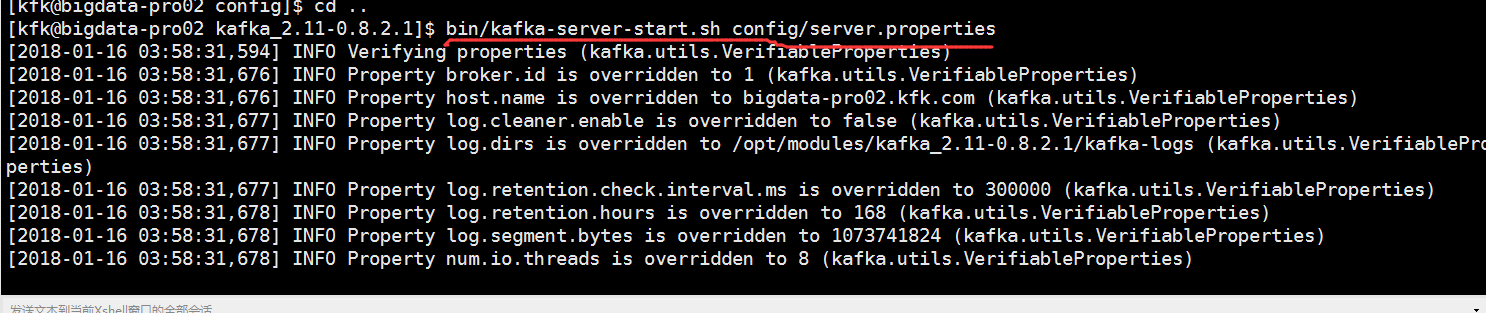
启动kafka
先把三个节点的zookeeper服务启动,这里就不多说怎么启动zookeeper了,然后启动我们的kafka

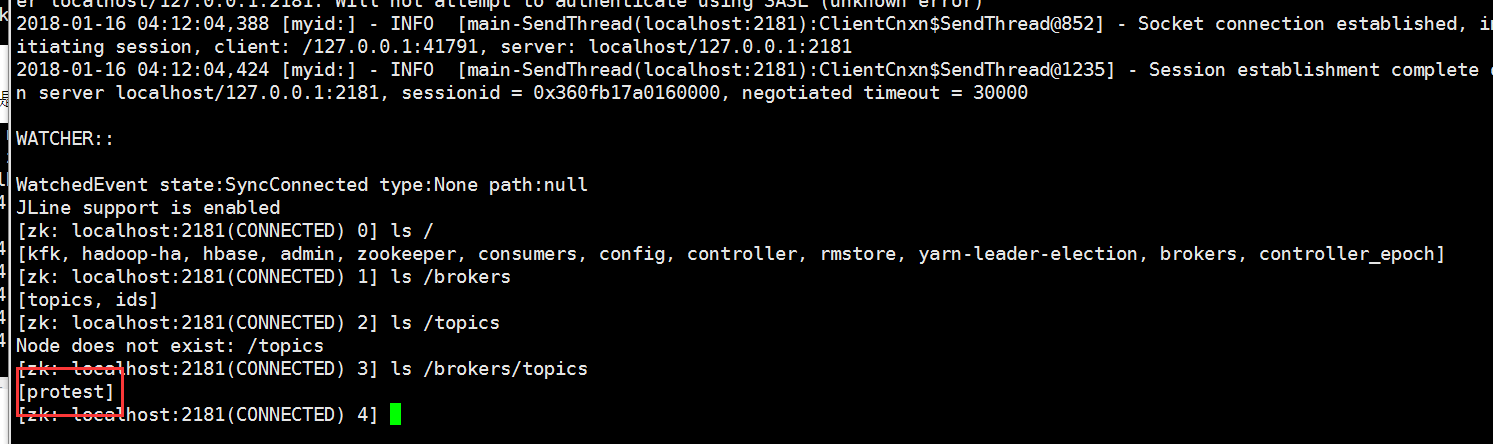
创建topic

通过zookeeper查看topic是否创建成功

创建生产者

创建一个消费者

在生产者这边输入

消费者这边都拿到了

后面两台机器的kafka启动也是一样的

Kafka分布式集群部署的更多相关文章
- 新闻实时分析系统-Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势)
基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势) 前言 前几天对Apollo配置中心的demo进行一个部署试用,现公司已决定使用,这两天进行分布式部署的时候 ...
- 超详细从零记录Hadoop2.7.3完全分布式集群部署过程
超详细从零记录Ubuntu16.04.1 3台服务器上Hadoop2.7.3完全分布式集群部署过程.包含,Ubuntu服务器创建.远程工具连接配置.Ubuntu服务器配置.Hadoop文件配置.Had ...
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署 系统系统环境: OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar. ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- solr 集群(SolrCloud 分布式集群部署步骤)
SolrCloud 分布式集群部署步骤 安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux ...
- SolrCloud 分布式集群部署步骤
https://segmentfault.com/a/1190000000595712 SolrCloud 分布式集群部署步骤 solr solrcloud zookeeper apache-tomc ...
随机推荐
- 使用apache cxf实现webservice服务
1.在idea中使用maven新建web工程并引入spring mvc,具体可以参考https://www.cnblogs.com/laoxia/p/9311442.html; 2.在工程POM文件中 ...
- oracle 之 CLUSTER_INTERCONNECTS is not set to the recommended value
问题:Database parameter CLUSTER_INTERCONNECTS is not set to the recommended value 在Oracle实际应用程序集群环境中可以 ...
- webpack 中,loader、plugin 的区别
loader 和 plugin 的主要区别: loader 用于加载某些资源文件. 因为 webpack 只能理解 JavaScript 和 JSON 文件,对于其他资源例如 css,图片,或者其他的 ...
- 手动制作openstack windows镜像
https://docs.openstack.org/image-guide/windows-image.html 这里以 windows 2008为例: 准备工作: 1准备好windows 2008 ...
- jmeter ---处理Cookie与Session
有些网站保存信息是使用Cookie,有些则是使用Session.对于这两种方式,JMeter都给予一定的支持. 1.Cookie 添加方式:线程组-配置元件-HTTP Cookie 管理器,如下图: ...
- 大数据时代——为什么用HADOOP?
转载自:http://www.daniubiji.cn/archives/538 什么叫大数据 “大”,说的并不仅是数据的“多”!不能用数据到了多少TB ,多少PB 来说. 对于大数据,可以用四个词来 ...
- Windows系统下MySQL数据库出现Access denied for user 'root'@'localhost' (using password:YES) 错误
Windows系统下MySQL数据库出现Access denied for user 'root'@'localhost' (using password:YES) 错误,(root密码错误) 处理方 ...
- tgz的解压
解压文件tgz 例如文件名为: yyyy.tgz 先使用GZIP解压为TAR文件 gzip -dv yyyy.tgz 同时解压后生成yyyy.tar文件 再使用tar解压yyyy.tar文件 tar ...
- HDMI初识
HDMI初识 1.阅读文档xapp1287 (1) KC705 HDMI Reference Design Block Diagram (2) KC705 HDMI Reference Design ...
- linux在线中文手册
linux在线中文手册 http://linux.51yip.com/ 百度中的百度应用也不错 http://www.baidu.com/s?word=linux%E5%91%BD%E4%BB%A4& ...