55.storm 之 hello word(本地模式)
strom hello word
概述
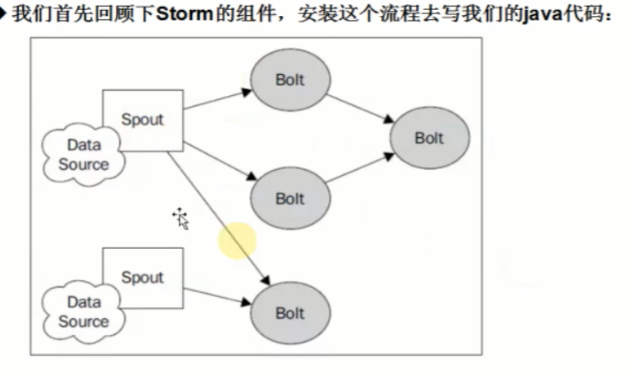
然后卡一下代码怎么实现的:
- 编写数据源类:Spout。可以使用两种方式:
继承BaseRichSpout类
实现IRichSpout接口
主要需要实现或重写几个方法:open、nextTuple、declareOutputFields
- 继续编写数据处理类:Bolt。可以使用两种方式:
继承BaseBasicBolt类
实现IRichBolt接口
终点实现或重写几个方法:execute、declareOutputFields
- 最后编写主函数(Topology)去进行提交一个任务
在使用Topology的时候,Storm框架为我们提供了两种模式:本地模式和集群模式
本地模式:(无需Storm集群,直接在java中即可运行,一般用于测试和开发阶段)执行main函数即可
集群模式:(需要Storm集群,把实现java程序打包,然后Topology进行提交)需要把应用打成jar,使用Storm命令吧Topology提交到集群中去。
实际操作
先来看一下代码结构:
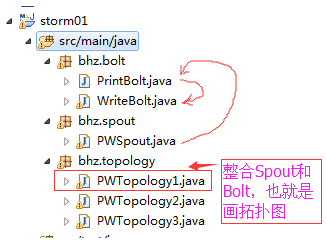
就如上图所说,数据从PWSpout流到PrintBolt,最后到WriteBolt写到文件。具体看一下这几个类的代码:
先看一本地模式的:
PWTopology1.java 拓扑结构构建
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import bhz.bolt.PrintBolt;
import bhz.bolt.WriteBolt;
import bhz.spout.PWSpout; public class PWTopology1 { public static void main(String[] args) throws Exception {
//
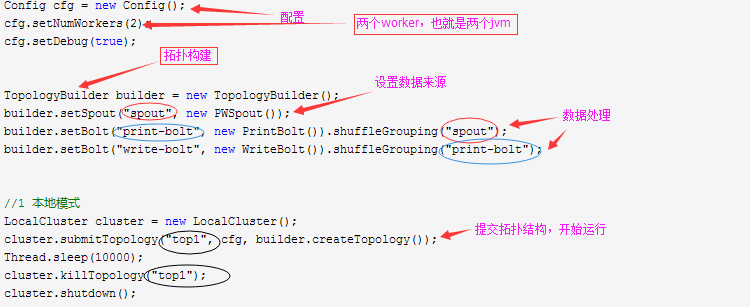
Config cfg = new Config();
cfg.setNumWorkers(2);
cfg.setDebug(true); TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new PWSpout());
builder.setBolt("print-bolt", new PrintBolt()).shuffleGrouping("spout");
builder.setBolt("write-bolt", new WriteBolt()).shuffleGrouping("print-bolt"); //1 本地模式
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("top1", cfg, builder.createTopology());
Thread.sleep(10000);
cluster.killTopology("top1");
cluster.shutdown(); //2 集群模式
// StormSubmitter.submitTopology("top1", cfg, builder.createTopology()); }
}
代码分析:
数据来源:
import java.util.HashMap;
import java.util.Map;
import java.util.Random; import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
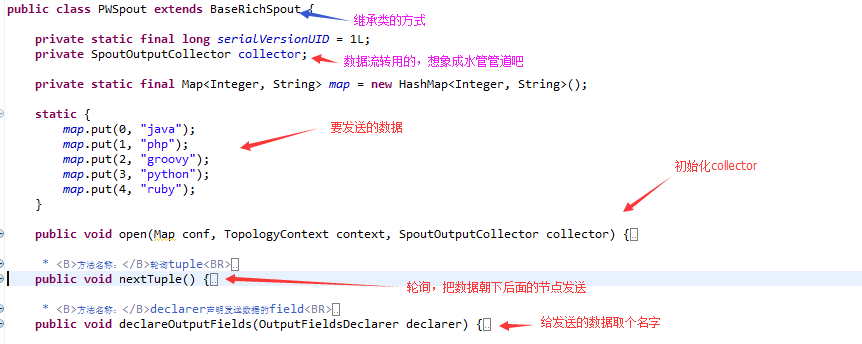
import backtype.storm.tuple.Values; public class PWSpout extends BaseRichSpout { private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector; private static final Map<Integer, String> map = new HashMap<Integer, String>(); static {
map.put(0, "java");
map.put(1, "php");
map.put(2, "groovy");
map.put(3, "python");
map.put(4, "ruby");
} @Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
//对spout进行初始化
this.collector = collector;
//System.out.println(this.collector);
} /**
* <B>方法名称:</B>轮询tuple<BR>
* <B>概要说明:</B><BR>
* @see backtype.storm.spout.ISpout#nextTuple()
*/
@Override
public void nextTuple() {
//随机发送一个单词
final Random r = new Random();
int num = r.nextInt(5);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
this.collector.emit(new Values(map.get(num)));
} /**
* <B>方法名称:</B>declarer声明发送数据的field<BR>
* <B>概要说明:</B><BR>
* @see backtype.storm.topology.IComponent#declareOutputFields(backtype.storm.topology.OutputFieldsDeclarer)
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//进行声明
declarer.declare(new Fields("print"));
} }
代码解析:
整体结构
细入分析
---------------------------- open 方法---------------------------------------------------------

--------------------------------- nextTuple方法 --------------------------------------------------------------

---------------------------- declareOutputFields方法 ----------------------------------------------------

数据处理
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory; import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; public class PrintBolt extends BaseBasicBolt { private static final Log log = LogFactory.getLog(PrintBolt.class); private static final long serialVersionUID = 1L; @Override
public void execute(Tuple input, BasicOutputCollector collector) {
//获取上一个组件所声明的Field
String print = input.getStringByField("print");
log.info("【print】: " + print);
//System.out.println("Name of input word is : " + word);
//进行传递给下一个bolt
collector.emit(new Values(print)); } @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("write"));
} }
代码分析
import java.io.FileWriter; import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory; import clojure.main;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple; public class WriteBolt extends BaseBasicBolt { private static final long serialVersionUID = 1L; private static final Log log = LogFactory.getLog(WriteBolt.class); private FileWriter writer ;
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
//获取上一个组件所声明的Field
String text = input.getStringByField("write");
try {
if(writer == null){
if(System.getProperty("os.name").equals("Windows 10")){
writer = new FileWriter("D:\\099_test\\" + this);
} else if(System.getProperty("os.name").equals("Windows 8.1")){
writer = new FileWriter("D:\\099_test\\" + this);
} else if(System.getProperty("os.name").equals("Windows 7")){
writer = new FileWriter("D:\\099_test\\" + this);
} else if(System.getProperty("os.name").equals("Linux")){
System.out.println("----:" + System.getProperty("os.name"));
writer = new FileWriter("/usr/local/temp/" + this);
}
}
log.info("【write】: 写入文件");
writer.write(text);
writer.write("\n");
writer.flush(); } catch (Exception e) {
e.printStackTrace();
}
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
和PrintBolt 这个类很相似,都是在处理数据。不作过多解释
55.storm 之 hello word(本地模式)的更多相关文章
- Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: Eclipse的下载 Eclipse的安装 Eclipse的使用 本地模式或集群模式 Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群 ...
- IntelliJ IDEA的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: IntelliJ IDEA的下载 IntelliJ IDEA的安装 IntelliJ IDEA中的scala插件安装 用SBT方式来创建工程 或 选择Scala方式来创建工程 本地模式或集群 ...
- Scala IDE for Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: Scala IDE for Eclipse的下载 Scala IDE for Eclipse的安装 本地模式或集群模式 我们知道,对于开发而言,IDE是有很多个选择的版本.如我们大部分人经常 ...
- Linux下的Hadoop安装(本地模式)
系统为CentOS 6.9,Hadoop版本2.8.3,虚拟机VMware Workstation 主要介绍Linux虚拟机安装.环境配置和Hadoop本地模式的安装.伪分布式和Windows下的安装 ...
- Scala进阶之路-Spark本地模式搭建
Scala进阶之路-Spark本地模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark简介 1>.Spark的产生背景 传统式的Hadoop缺点主要有以下两 ...
- IntelliJ IDEA(Community版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
不多说,直接上干货! 对于初学者来说,建议你先玩玩这个免费的社区版,但是,一段时间,还是去玩专业版吧,这个很简单哈,学聪明点,去搞到途径激活!可以看我的博客. 包括: IntelliJ IDEA(Co ...
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- 2.hadoop基本配置,本地模式,伪分布式搭建
2. Hadoop三种集群方式 1. 三种集群方式 本地模式 hdfs dfs -ls / 不需要启动任何进程 伪分布式 所有进程跑在一个机器上 完全分布式 每个机器运行不同的进程 2. 服务器基本配 ...
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
随机推荐
- springboot深入学习(三)-----docker
一.spring data思路 spring data使用统一的api来对各种数据库存储技术进行数据访问操作提供了支持,包括oracle.mysql.redis.mongoDB等等.主要是通过spri ...
- 关于preg_match() / preg_replace()函数的一点小说明
int preg_match ( string $pattern , string $subject [, array &$matches [, int $flags = 0 [, int $ ...
- C语言三种方法调用数组
#include <stdio.h> /********************************* * 方法1: 第一维的长度可以不指定 * * 但必须指定第二维的长度 * *** ...
- maven打包到私服,打的是war包,好郁闷
jenkins打完包上传到私服以后,发现只有war包,然而并木有别人想要的jar包,郁闷之极啊! 然后把公司的项目做了对比,发现这个正常的能上传jar包的项目的与我的另一个项目有点出入: 正常: 异 ...
- Linux中的sleep、usleep、nanosleep、poll和select
在进行Linux C/C++编程时,可调用的sleep函数有好多个,那么究竟应当调用哪一个了?下表列出了这几个函数间的异同点,可作为参考: 性质 精准度 线程安全 信号安全 sleep libc库函数 ...
- redis的repl-ping-slave-period和repl-ping-replica-period
网上很多Redis方面的文章,会涉及到repl-ping-slave-period和repl-ping-replica-period这两个重要参数,从一些中文解释来看,意思差不多,即:SLAVE周期性 ...
- CCommandLineInfo类
## CCommandLineInfo cmdInfo;//定义命令行 ParseCommandLine(cmdInfo);//解析命令行 // 调度在命令行中指定的命令.如果 // 用 /RegSe ...
- 线段树区间覆盖 蛤玮打扫教室(zzuli 1877)
http://acm.zzuli.edu.cn/zzuliacm/problem.php?id=1877 Description 现在知道一共有n个机房,算上蛤玮一共有m个队员,教练做了m个签,每 ...
- mysql同时使用order by和limit查询时的一个严重隐患 -- 丢失数据
转自: https://blog.csdn.net/tsxw24/article/details/44994835 我经常使用order by和limit来做数据分页显示并排序,一直也没发现过什么问题 ...
- pickle 继承
1.什么是方法,什么是函数 class Foo: def chi(self): print("我是吃") @staticmethod def static_method(): pa ...