Python使用Tabula提取PDF表格数据
今天遇到一个批量读取pdf文件中表格数据的需求,样式大体是以下这样:
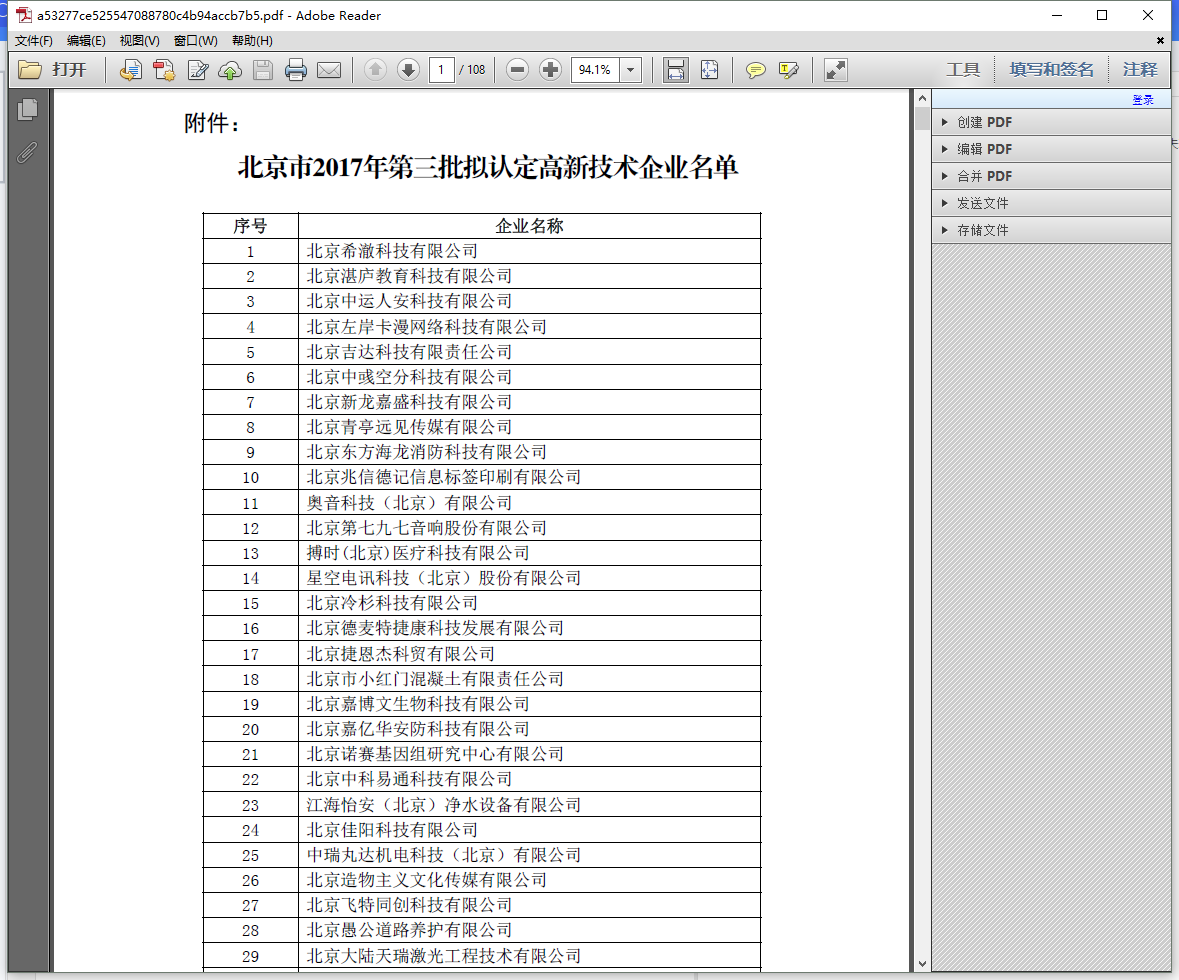
python读取PDF无非就是三种方式(我所了解的),pdfminer、pdf2htmlEX 和 Tabula。综合考虑后,选择了最后一种。下面对三种方式分别介绍:
pdfminer
该方式从网上搜索的结果是,可以提取pdf文本数据,但是提取后表格信息就乱了。所以本人没有亲自实验,就果断放弃了实验该方法。如果只是提取pdf里面的文本内容,该方式可能是比较合适的。
pdf2htmlEX
该方式是通过把pdf格式转换成html格式,然后再提取信息的方法。
Github: https://github.com/coolwanglu/pdf2htmlEX
需先下载pdf2htmlEX可执行程序,下载地址:https://github.com/coolwanglu/pdf2htmlEX/wiki/Download。
#-*- conding: utf-8 -*-
import subprocess
subprocess.call('"D:\Program Files (x86)\pdf2htmlEX-win32-0.14.6-upx-with-poppler-data\pdf2htmlEX.exe" --dest-dir E:\\test\extract\\2017gq\\out E:\\test\extract\\2017gq\\a53277ce525547088780c4b94accb7b5.pdf', shell=True)
执行以上代码,会在指定目录 E:\test\extract\2017gq\out 下生成对应html文件,浏览器中查看效果:
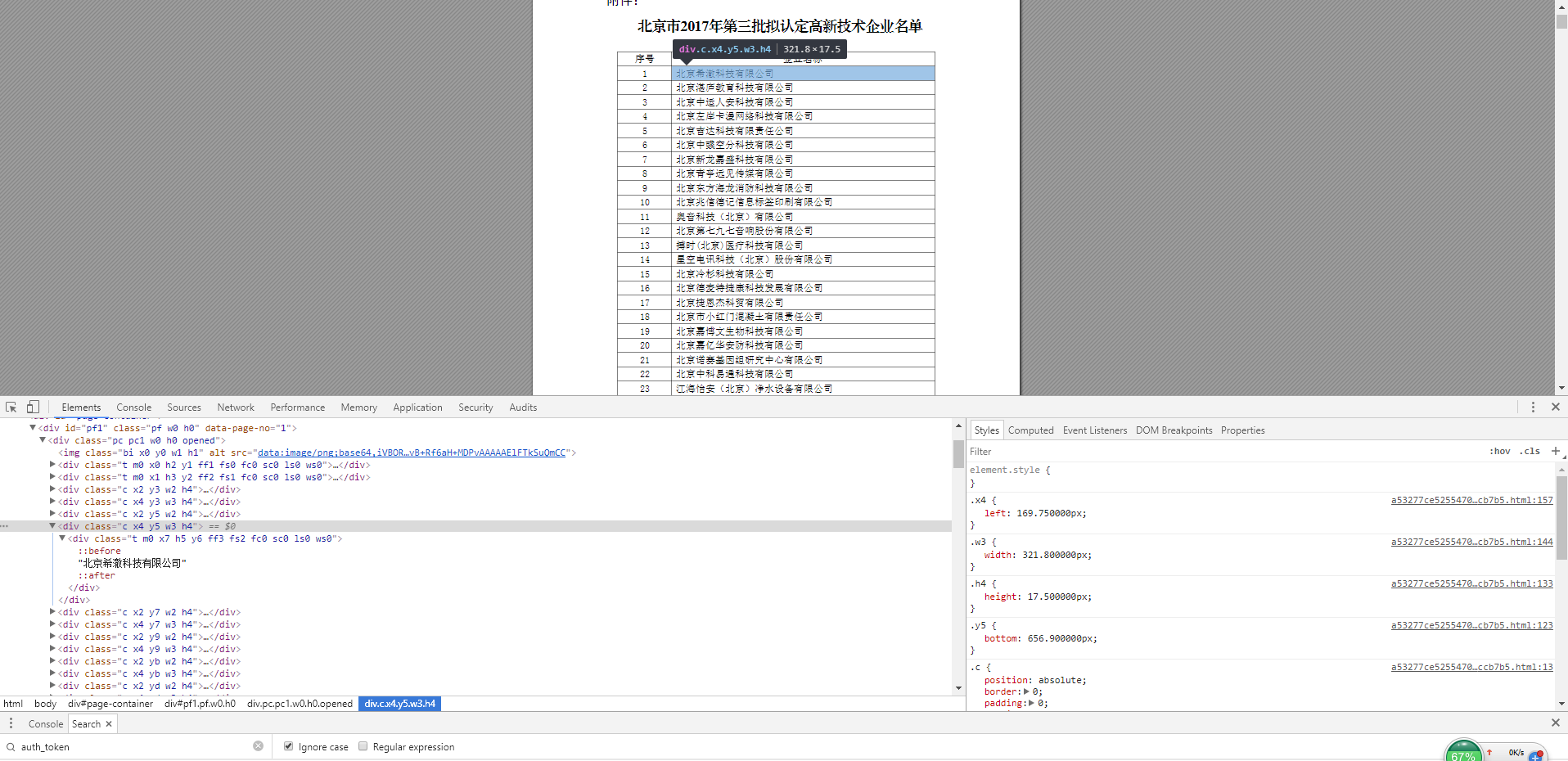
可以看到整体转换的效果非常不错,但是转换后的标签没有特点,使数据的提取变得非常困难。多番尝试后,感觉该方法不够通用,没法解决我的需求。也许对于单纯的pdf转html,该方式可能是最好的选择。
Tabula
Tabula是专门用来提取PDF表格数据的,同时支持PDF导出为CSV、Excel格式。
官网: http://tabula.technology/
Github: https://github.com/chezou/tabula-py
首先安装tabula-py: pip install tabula-py
tabula-py依赖库包括java、pandas、numpy,所以需保证运行环境中安装了这些库。
#-*- conding: utf-8 -*-
import tabula
df = tabula.read_pdf("E:\\test\\extract\\2017gq\\a53277ce525547088780c4b94accb7b5.pdf", encoding='gbk', pages='all')
print(df)
for indexs in df.index:
# 遍历打印企业名称
print(df.loc[indexs].values[1].strip())
执行以上代码,成功打印出表格中的所有企业名称,查看打印的 df 的结构,如下图:

总结
以上三种方式中,最后一种方式完美的解决了我的从PDF表格中提取数据的需求,希望能抛砖引玉,大家在使用时选择最适合自己的方法,如有介绍不当之处,望留言中指正,谢过。
Python使用Tabula提取PDF表格数据的更多相关文章
- 利用python第三方库提取PDF文件的表格内容
小爬最近接到一个棘手任务:需要提取手机话费电子发票PDF文件中的数据.接到这个任务的第一时间,小爬决定搜集各个地区各个时间段的电子发票文件,看看其中的差异点.粗略统计下来,PDF文件的表格框架是统一的 ...
- python提取分析表格数据
#/bin/python3.4# -*- coding: utf-8 -*- import xlrd def open_excel(file="file.xls"): try: d ...
- Python利用xlutils统计excel表格数据
假设有像上这样一个表格,里面装满了各式各样的数据,现在要利用模板对它进行统计每个销售商的一些数据的总和.模板如下: 代码开始: 1 #!usr/bin/python3 2 # -*-coding=ut ...
- python:字符串中提取特定的数据
在日志文件中有一大堆,格式相同的文本,需要提取出接口耗时的时间 >>> 运单号:71742507538566,快递100接口耗时:8,返回结果:[{"lengthPre&q ...
- 个人永久性免费-Excel催化剂功能第88波-批量提取pdf文件信息(图片、表格、文本等)
日常办公场合中,除了常规的Excel.Word.PPT等文档外,还有一个不可忽略的文件格式是pdf格式,而对于想从pdf文件中获取信息时,常规方法将变得非常痛苦和麻烦.此篇给大家送一pdf文件提取信息 ...
- 另类爬虫:从PDF文件中爬取表格数据
简介 本文将展示一个稍微不一样点的爬虫. 以往我们的爬虫都是从网络上爬取数据,因为网页一般用HTML,CSS,JavaScript代码写成,因此,有大量成熟的技术来爬取网页中的各种数据.这次, ...
- python提取网页表格并保存为csv
0. 1.参考 W3C HTML 表格 表格标签 表格 描述 <table> 定义表格 <caption> 定义表格标题. <th> 定义表格的表头. <tr ...
- 办公室文员必备python神器,将PDF文件表格转换成excel表格!
[阅读全文] 第三方库说明 # PDF读取第三方库 import pdfplumber # DataFrame 数据结果处理 import pandas as pd 初始化DataFrame数据对象 ...
- 干货--Excel的表格数据的一般处理和常用python模块。
写在前面: 本文章的主要目的在于: 介绍了python常用的Excel处理模块:xlwt,xlrd,xllutils,openpyxl,pywin32的使用和应用场景. 本文只针对于Excel表中常用 ...
随机推荐
- 如何用shell脚本取出服务器图片
一 ,SHELL 是什么 (1)shell是一种命令行解释器. (2)是用户和Linux内核之间沟通的桥梁,属于中间件.见下图 (3)交互流程:shell接受用户输入的指令 =>将指令传达给Li ...
- 机器学习笔记1 - Hello World In Machine Learning
前言 Alpha Go在16年以4:1的战绩打败了李世石,17年又以3:0的战绩战胜了中国围棋天才柯洁,这真是科技界振奋人心的进步.伴随着媒体的大量宣传,此事变成了妇孺皆知的大事件.大家又开始激烈的讨 ...
- hdu4893 Wow! Such Sequence!
线段树结点上保存一个一般的sum值,再同一时候保存一个fbsum,表示这个结点表示的一段数字若为斐波那契数时的和 当进行3操作时,仅仅用将sum = fbsum就可以 其它操作照常进行,仅仅是单点更新 ...
- Azure: 给 ubuntu 虚机挂载数据盘
在 azure 上创建的虚机默认会分配两个磁盘,分别是系统盘和一个临时磁盘.如果我们要在系统中安装使用 mysql 等软件,需要再创建并挂载单独的数据盘用来保存数据库文件.这是因为临时磁盘被定义为:用 ...
- IDEA定位到类的代码区域(查看类的源码)
经常需要查看某一个类中的成员变量和方法,那么怎么进入到这个类的源码区域呢?在IDEA中只需要使用快捷键: ctrl+shift+t 就可以快速定位到这个类的源码.
- flask 上传文件
flask upload 近日在学习python,接触到了flask框架,刚好客户有个需求,需要在网页上传一个python 代码的zip包,然后使用docker 容器运行这个zip里面的程序,输出结果 ...
- MyEclipse 2014 破解版下载:我有,需要的给我说一声,给你发过去
1.破解版的,需要的在下面给我说一声,云盘给你发过去.
- 非等高cell实战(01)-- 实现微博页面
非等高cell实战(01)-- 实现微博页面 学习过UITableView.AutoLayout以及MVC的相关知识,接下来通过一个微博页面实战来整合一下. 首先看一下效果图: 需求分析 此页面为非等 ...
- CSS3渐变相关
背景渐变 background: -moz-linear-gradient( top,#f24652,#da2c3c); background: -o-linear-gradient(top,#f24 ...
- 【python】字符串变量赋值时字符串可用单或双引号
>>> name='萧峰' >>> print(name) 萧峰 >>> name="独孤求败" >>> p ...