brk(), sbrk() 用法详解
brk() , sbrk() 的声明如下:
- #include <unistd.h>
- int brk(void *addr);
- void *sbrk(intptr_t increment);
这两个函数都用来改变 "program break" (程序间断点)的位置,这个位置可参考下图:
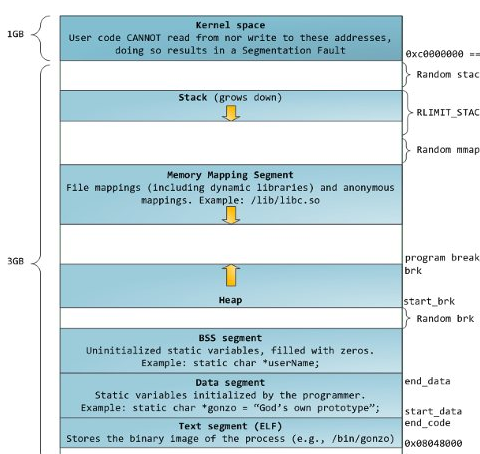
如 man 里说的:
引用brk() and sbrk() change the location of the program break, which defines the end of the process's data segment (i.e., the program break is the first location after the end of the uninitialized data segment).
brk() 和 sbrk() 改变 "program brek" 的位置,这个位置定义了进程数据段的终止处(也就是说,program break 是在未初始化数据段终止处后的第一个位置)。
如此翻译过来,似乎会让人认为这个 program break 是和上图中矛盾的,上图中的 program break 是在堆的增长方向的第一个位置处(堆和栈的增长方向是相对的),而按照说明手册来理解,似乎是在 bss segment 结束那里(因为未初始化数据段一般认为是 bss segment)。
首先说明一点,一个程序一旦编译好后,text segment ,data segment 和 bss segment 是确定下来的,这也可以通过 objdump 观察到。下面通过一个程序来测试这个 program break 是不是在 bss segment 结束那里:
- #include <stdio.h>
- #include <unistd.h>
- #include <stdlib.h>
- #include <sys/time.h>
- #include <sys/resource.h>
- int bssvar; //声明一个味定义的变量,它会放在 bss segment 中
- int main(void)
- {
- char *pmem;
- long heap_gap_bss;
- printf ("end of bss section:%p\n", (long)&bssvar + 4);
- pmem = (char *)malloc(32); //从堆中分配一块内存区,一般从堆的开始处获取
- if (pmem == NULL) {
- perror("malloc");
- exit (EXIT_FAILURE);
- }
- printf ("pmem:%p\n", pmem);
- //计算堆的开始地址和 bss segment 结束处得空隙大小,注意每次加载程序时这个空隙都是变化的,但是在同一次加载中它不会改变
- heap_gap_bss = (long)pmem - (long)&bssvar - 4;
- printf ("1-gap between heap and bss:%lu\n", heap_gap_bss);
- free (pmem); //释放内存,归还给堆
- sbrk(32); //调整 program break 位置(假设现在不知道这个位置在堆头还是堆尾)
- pmem = (char *)malloc(32); //再一次获取内存区
- if (pmem == NULL) {
- perror("malloc");
- exit (EXIT_FAILURE);
- }
- printf ("pmem:%p\n", pmem); //检查和第一次获取的内存区的起始地址是否一样
- heap_gap_bss = (long)pmem - (long)&bssvar - 4; //计算调整 program break 后的空隙
- printf ("2-gap between heap and bss:%lu\n", heap_gap_bss);
- free(pmem); //释放
- return 0;
- }
下面,我们分别运行两次程序,并查看其输出:
引用[beyes@localhost C]$ ./sbrk
end of bss section:0x8049938
pmem:0x82ec008
1-gap between heap and bss:2762448
pmem:0x82ec008
2-gap between heap and bss:2762448
[beyes@localhost C]$ ./sbrk
end of bss section:0x8049938
pmem:0x8dbc008
1-gap between heap and bss:14100176
pmem:0x8dbc008
2-gap between heap and bss:14100176
从上面的输出中,可以发现几点:
1. bss 段一旦在在程序编译好后,它的地址就已经规定下来。
2. 一般及简单的情况下,使用 malloc() 申请的内存,释放后,仍然归还回原处,再次申请同样大小的内存区时,还是从第 1 次那里获得。
3. bss segment 结束处和堆的开始处的空隙大小,并不因为 sbrk() 的调整而改变,也就是说明了 program break 不是调整堆头部。
所以,man 手册里所说的 “program break 是在未初始化数据段终止处后的第一个位置” ,不能将这个位置理解为堆头部。这时,可以猜想应该是在堆尾部,也就是堆增长方向的最前方。下面用程序进行检验:
当 sbrk() 中的参数为 0 时,我们可以找到 program break 的位置。那么根据这一点,检查一下每次在程序加载时,系统给堆的分配是不是等同大小的:
- #include <stdio.h>
- #include <unistd.h>
- #include <stdlib.h>
- #include <sys/time.h>
- #include <sys/resource.h>
- int main(void)
- {
- void *tret;
- char *pmem;
- pmem = (char *)malloc(32);
- if (pmem == NULL) {
- perror("malloc");
- exit (EXIT_FAILURE);
- }
- printf ("pmem:%p\n", pmem);
- tret = sbrk(0);
- if (tret != (void *)-1)
- printf ("heap size on each load: %lu\n", (long)tret - (long)pmem);
- return 0;
- }
运行上面的程序 3 次:
引用[beyes@localhost C]$ ./sbrk
pmem:0x80c9008
heap size on each load: 135160
[beyes@localhost C]$ ./sbrk
pmem:0x9682008
heap size on each load: 135160
[beyes@localhost C]$ ./sbrk
pmem:0x9a7d008
heap size on each load: 135160
[beyes@localhost C]$ ./sbrk
pmem:0x8d92008
heap size on each load: 135160
[beyes@localhost C]$ vi sbrk.c
从输出可以看到,虽然堆的头部地址在每次程序加载后都不一样,但是每次加载后,堆的大小默认分配是一致的。但是这不是不能改的,可以使用 sysctl 命令修改一下内核参数:
引用#sysctl -w kernel/randomize_va_space=0
这么做之后,再运行 3 次这个程序看看:
引用[beyes@localhost C]$ ./sbrk
pmem:0x804a008
heap size on each load: 135160
[beyes@localhost C]$ ./sbrk
pmem:0x804a008
heap size on each load: 135160
[beyes@localhost C]$ ./sbrk
pmem:0x804a008
heap size on each load: 135160
从输出看到,每次加载后,堆头部的其实地址都一样了。但我们不需要这么做,每次堆都一样,容易带来缓冲区溢出攻击(以前老的 linux 内核就是特定地址加载的),所以还是需要保持 randomize_va_space 这个内核变量值为 1 。
下面就来验证 sbrk() 改变的 program break 位置在堆的增长方向处:
- #include <stdio.h>
- #include <unistd.h>
- #include <stdlib.h>
- #include <sys/time.h>
- #include <sys/resource.h>
- int main(void)
- {
- void *tret;
- char *pmem;
- int i;
- long sbrkret;
- pmem = (char *)malloc(32);
- if (pmem == NULL) {
- perror("malloc");
- exit (EXIT_FAILURE);
- }
- printf ("pmem:%p\n", pmem);
- for (i = 0; i < 65; i++) {
- sbrk(1);
- printf ("%d\n", sbrk(0) - (long)pmem - 0x20ff8); //0x20ff8 就是堆和 bss段 之间的空隙常数;改变后要用 sbrk(0) 再次获取更新后的program break位置
- }
- free(pmem);
- return 0;
- }
运行输出:
引用[beyes@localhost C]$ ./sbrk
pmem:0x804a008
1
2
3
4
5... ...
61
62
63
64
从输出看到,sbrk(1) 每次让堆往栈的方向增加 1 个字节的大小空间。
而 brk() 这个函数的参数是一个地址,假如你已经知道了堆的起始地址,还有堆的大小,那么你就可以据此修改 brk() 中的地址参数已达到调整堆的目的。
实际上,在应用程序中,基本不直接使用这两个函数,取而代之的是 malloc() 一类函数,这一类库函数的执行效率会更高。 还需要注意一点,当使用 malloc() 分配过大的空间,比如超出 0x20ff8 这个常数(在我的系统(Fedora15)上是这样,别的系统可能会有变)时,malloc 不再从堆中分配空间,而是使用 mmap() 这个系统调用从映射区寻找可用的内存空间。
brk(), sbrk() 用法详解的更多相关文章
- brk(), sbrk() 用法详解【转】
转自:http://blog.csdn.net/sgbfblog/article/details/7772153 贴上原文地址,好不容易找到了:brk(), sbrk() -- 改变数据段长度 brk ...
- [转帖]强大的strace命令用法详解
强大的strace命令用法详解 文章转自: https://www.linuxidc.com/Linux/2018-01/150654.htm strace是什么? 按照strace官网的描述, st ...
- C#中string.format用法详解
C#中string.format用法详解 本文实例总结了C#中string.format用法.分享给大家供大家参考.具体分析如下: String.Format 方法的几种定义: String.Form ...
- @RequestMapping 用法详解之地址映射
@RequestMapping 用法详解之地址映射 引言: 前段时间项目中用到了RESTful模式来开发程序,但是当用POST.PUT模式提交数据时,发现服务器端接受不到提交的数据(服务器端参数绑定没 ...
- linux管道命令grep命令参数及用法详解---附使用案例|grep
功能说明:查找文件里符合条件的字符串. 语 法:grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>] ...
- mysql中event的用法详解
一.基本概念mysql5.1版本开始引进event概念.event既“时间触发器”,与triggers的事件触发不同,event类似与linux crontab计划任务,用于时间触发.通过单独或调用存 ...
- CSS中伪类及伪元素用法详解
CSS中伪类及伪元素用法详解 伪类的分类及作用: 注:该表引自W3School教程 伪元素的分类及作用: 接下来让博主通过一些生动的实例(之前的作业或小作品)来说明几种常用伪类的用法和效果,其他的 ...
- c++中vector的用法详解
c++中vector的用法详解 vector(向量): C++中的一种数据结构,确切的说是一个类.它相当于一个动态的数组,当程序员无法知道自己需要的数组的规模多大时,用其来解决问题可以达到最大节约空间 ...
- AngularJS select中ngOptions用法详解
AngularJS select中ngOptions用法详解 一.用法 ngOption针对不同类型的数据源有不同的用法,主要体现在数组和对象上. 数组: label for value in a ...
随机推荐
- tomcat7以上,ajax post参数后台获取不到的问题
AJAX post传参后台获取不到查询参数. 网上找了各种方法,包括设置content-type,又是把json转成json格式字符串,问题依然存在,但是把post改成get又可以获取到,百思不得其解 ...
- java基础系列--Date类
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/7126930.html 1.Date类概述 Date类是从JDK1.1就开始存在的老类,其提 ...
- NEWS-包名-baseTest-类名-ConfigManager
package baseTest; import java.io.IOException;import java.io.InputStream;import java.util.Properties; ...
- Javascript 判断变量类型的陷阱 与 正确的处理方式
Javascript 由于各种各样的原因,在判断一个变量的数据类型方面一直存在着一些问题,其中最典型的问题恐怕就是 typeof null 会返回 object 了吧.因此在这里简单的总结一下判断数据 ...
- voa 2015 / 4 / 15
illustrated - v. to explain or decorate a story, book, etc., with pictures pediatrician – n. a docto ...
- Java Jpa 规范
Jpa最早是EJB3.0里面的内容,JSR 220: Enterprise JavaBeansTM 3.0 https://www.jcp.org/en/jsr/detail?id=220 后来大约在 ...
- java基础06 Java中的递归
一.递归是指直接或间接地调用自身. 二.递归的注意事项: A:要有出口,否则就是死递归 B:次数不能过多,否则内存溢出 C:构造方法不能递归使用 三.举例子 递归 ...
- Akka(14): 持久化模式:PersistentActor
Akka程序的特点之一就是高弹性或者强韧性(resilient)的,因为Actor具有自我修复的能力.当Actor模式的程序出现中断情况如:系统崩溃.人为终结等,系统在重启后有关Actor可以恢复之前 ...
- DL4NLP——词表示模型(三)word2vec(CBOW/Skip-gram)的加速:Hierarchical Softmax与Negative Sampling
上篇博文提到,原始的CBOW / Skip-gram模型虽然去掉了NPLM中的隐藏层从而减少了耗时,但由于输出层仍然是softmax(),所以实际上依然“impractical”.所以接下来就介绍一下 ...
- HTML中重要的知识点,表单
今天跟大家分享一下有关HTML中比较重要的一个知识点-表单: <form></form>表单 这是一个双标签,form表单有两个必须要有的属性,①action就是指表单传递到的 ...