spring boot / cloud (十五) 分布式调度中心进阶
spring boot / cloud (十五) 分布式调度中心进阶
在<spring boot / cloud (十) 使用quartz搭建调度中心>这篇文章中介绍了如何在spring boot项目中集成quartz.
今天这篇文章则会进一步跟大家讨论一下设计和搭建分布式调度中心所需要关注的事情.
下面先看一下,总体的逻辑架构图:
分布式调度-逻辑架构示意
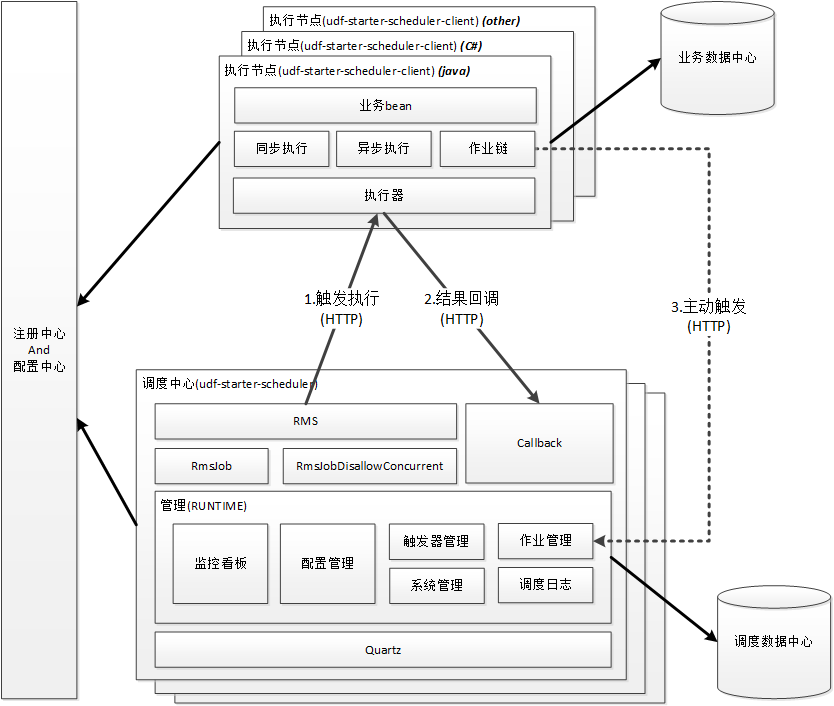
架构设计
总体思路是,将调度和执行两个概念分离开来,形成调度中心和执行节点两个模块:
调度中心
是一个公共的平台,负责所有任务的调度,以及任务的管理,不涉及任何业务逻辑,从上图可以看到,它主要包括如下模块:
核心调度器quartz : 调度中心的核心,按照jobDetail和trigger的设定发起作业调度,并且提供底层的管理api
管理功能 : 可通过restful和web页面的方式动态的管理作业,触发器的CURD操作,并且实时生效,而且还可以记录调度日志,以及可以以图表,表格,等各种可视化的方式展现调度中心的各个维度的指标信息
RmsJob和RmsJobDisallowConcurrent : 基于http远程调用(RMS)的作业和禁止并发执行的作业
Callback : 用于接收"执行节点"异步执行完成后的信息
执行节点
是嵌入在各个微服务中的一个执行模块,负责接收调度中心的调度,专注于执行业务逻辑,无需关系调度细节,并且理论上来说,它主要包括如下模块:
同步执行器 : 同步执行并且返回调度中心触发的任务
异步执行器 : 异步执行调度中心触发的任务,并且通过callback将执行结果反馈给调度中心
作业链 : 可任意组合不同任务的执行顺序和依赖关系,满足更复杂的业务需求
业务bean : 业务逻辑的载体
架构优点
这样一来,调度中心只负责调度,执行节点只负责业务,相互通过http协议进行沟通,两部分可以完全解耦合,增强系统整体的扩展性
并且引入了异步执行器的概念,这一样一来,调度中心就能以非阻塞的形式触发执行器,可以不受任务业务逻辑带来的性能影响,进一步提高了系统的性能
然后理论上来说执行节点是不局限于任何的语言或者平台的,并且与调度中心采用的是通用的http协议,真正的可以做到跨平台
特点
集群,高可用,故障转移
整体的解决方案是建立在spring cloud基础上的,依赖于服务发现eureka,可使所有的服务去中心化,来实现集群和高可用
调度中心的核心依赖于quartz,而quartz是原生支持集群的,它通过将作业和触发器的细节持久化到数据库中,然后在通过db锁的方式,与集群中的各个节点通讯,从而实现了去中心化
而执行节点和调度中心都是注册在eureka上的,通过ribbon的客户端负载均衡的特性,自动屏蔽坏掉的节点,自动发现新增加的节点,可使双方的http通信都做到高可用.
如下是quartz集群配置的片段:
#Configure scheduler
org.quartz.scheduler.instanceName=clusterQuartzScheduler #实例名称
org.quartz.scheduler.instanceId=AUTO #自动设定实例ID
org.quartz.scheduler.skipUpdateCheck=true
#Configure JobStore and Cluster
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX #使用jdbc持久化到数据中
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate #sql代理,mysql
org.quartz.jobStore.useProperties=true
org.quartz.jobStore.tablePrefix=QRTZ_ #表前缀
org.quartz.jobStore.isClustered=true #开启集群模式
org.quartz.jobStore.clusterCheckinInterval=20000
org.quartz.jobStore.misfireThreshold=60000
线程池调优
quartz的默认配置,可根据实际情况进行调整.
#Configure ThreadPool
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool #线程池类型
org.quartz.threadPool.threadCount=5 #线程池数量
org.quartz.threadPool.threadPriority=5 #优先级
这里就体现出了分离调度的业务逻辑的好处,在传统的做法中,调度器承载着业务逻辑,必然会占用执行线程更长时间,并发能力受业务逻辑限制.
将业务逻辑分离出去后,并且采用异步任务的方式,调度器触发某个任务后,将立即返回,这时占用执行线程的时间会大幅缩短.
所以在相同的线程池数量下,采用这种架构,是可以大幅度的提高调度中心的并发能力的.
集中化配置管理
同样,整个解决方案也依赖于spring cloud config server.
我们在系统中抽象出了一系列的元数据用于做系统配置,这些元数据在org.itkk.udf.scheduler.meta包下,大家可以查看,这些元数据基本囊括了所有作业和触发器的属性,通过@ConfigurationProperties特性,可轻松的将这些元数据类转化为配置文件.
并且设计上简化了后续管理api的复杂度,我们某个作业或者某个触发器的一套属性归纳到一个CODE中,然后后续通过这个CODE就能操作所对应的作业或者触发器.
配置片段如下:
#jobGroup
org.itkk.scheduler.properties.jobGroup.general=通用
#triggerGroup
org.itkk.scheduler.properties.triggerGroup.general=通用
#rmsJob
org.itkk.scheduler.properties.jobDetail.rmsJob.name=generalJob
org.itkk.scheduler.properties.jobDetail.rmsJob.group=general
org.itkk.scheduler.properties.jobDetail.rmsJob.className=org.itkk.udf.scheduler.job.RmsJob
org.itkk.scheduler.properties.jobDetail.rmsJob.description=通用作业
org.itkk.scheduler.properties.jobDetail.rmsJob.recovery=false
org.itkk.scheduler.properties.jobDetail.rmsJob.durability=true
org.itkk.scheduler.properties.jobDetail.rmsJob.autoInit=true
#rmsJobDisallowConcurrent
org.itkk.scheduler.properties.jobDetail.rmsJobDisallowConcurrent.name=generalJobDisallowConcurrent
org.itkk.scheduler.properties.jobDetail.rmsJobDisallowConcurrent.group=general
org.itkk.scheduler.properties.jobDetail.rmsJobDisallowConcurrent.className=org.itkk.udf.scheduler.job.RmsJobDisallowConcurrent
org.itkk.scheduler.properties.jobDetail.rmsJobDisallowConcurrent.description=通用作业(禁止并发)
org.itkk.scheduler.properties.jobDetail.rmsJobDisallowConcurrent.recovery=false
org.itkk.scheduler.properties.jobDetail.rmsJobDisallowConcurrent.durability=true
org.itkk.scheduler.properties.jobDetail.rmsJobDisallowConcurrent.autoInit=true
#simpleTrigger
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.jobCode=rmsJob
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.name=testSimpleTrigger
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.group=general
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.intervalInMilliseconds=10000
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.autoInit=true
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.description=测试简单触发器
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.dataMap.serviceCode=SCH_CLIENT_UDF_SERVICE_A_DEMO
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.dataMap.beanName=testBean
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.dataMap.async=true
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.dataMap.param1=a
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.dataMap.param2=b
org.itkk.scheduler.properties.simpleTrigger.testSimpleTrigger.dataMap.param3=123
以上可以看,我们可以通过properties配置文件设定作业和触发器的任何属性,并且通过如:simpleTrigger这个code,就能随意的通过管理api进行curd操作.
基于rms的JobDetail
从上面的配置可以看到,解决方案中内置了两个默认的jobDetail,一个是rmsJob另一个是rmsJobDisallowConcurrent.
想要使用它们很简单,为它们配置一个触发器即可,rmsjob通过以下属性来确定自己将要调用那个任务:
#配置simple或者corn触发器的dataMap属性,并且添加如下值:
#指定要调用那个rms,这里设定的是rmscode,不太清楚的话可以回看第八篇文章
省略.serviceCode=SCH_CLIENT_UDF_SERVICE_A_DEMO
#指定要调用哪一个bean
省略.beanName=testBean
#是否采用异步方式
省略.async=true
#业务参数
省略.param1=a
省略.param2=b
省略.param3=123
如下方式可以在执行节点中定义一个执行器
@Component("testBean")
public class TestSch extends AbstractExecutor {
@Override
public void handle(String id, Map<String, Object> jobDataMap) {
try {
LOGGER.info("任务执行了------id:{}, jobDataMap:{}", id, jobDataMap);
} catch (JsonProcessingException e) {
throw new SchException(e);
}
}
}
这样就能为某一个执行器设定触发器,从而做到调度的功能.
而rmsJob是可以并发的触发执行器的.
禁止并发的基于rms的JobDetail
在这个解决方案中禁止并发有两个层次
第一个层次就是默认实现的rmsJobDisallowConcurrent,大家看源码就知道,这个类上标注了@DisallowConcurrentExecution,这个注解的含义是禁止作业并发执行.
在传统的做法中jobdetail中包含了业务逻辑,没有异步的远程操作,所以说在类上标注这个注解能做到禁止并发.
但是现在有了异步任务的概念,触发器触发执行器后立即就返回结束了,如果这个时候,触发器的触发间隔小于执行器的执行时间,那么依然还是会有任务并发执行的.
这显然是不希望发生的,既然禁止并发,那么就一定要完全的做到禁止并发,如下设定保证了这一点:
protected void disallowConcurrentExecute(RmsJobParam rmsJobParam) throws JobExecutionException {
if (!this.hasRunning(rmsJobParam)) { //没有正在运行的任务才能运行
this.execute(rmsJobParam);
} else { //跳过执行,并且记录
RmsJobResult result = new RmsJobResult();
result.setId(rmsJobParam.getId());
result.setStats(RmsJobStats.SKIP.value());
save(rmsJobParam, result);
}
}
在禁止并发的异步任务触发前,会校验当前这个任务是否正在执行,如果正在执行的话,跳过并且记录.
异步任务,异步回调
执行节点中的任务即可同步执行也可异步执行,通过配置触发器的async属性来控制的,
同步执行 : 的任务适合执行时间短,执行时间稳定,并且有必要立即知道返回结果的任务
异步执行 : 高并发,高性能的执行方式,没有特别的限制,推荐使用
如下实现片段:
//SchClientController中
public RestResponse<RmsJobResult> execute(@RequestBody RmsJobParam param) {
//记录来接收时间
Date receiveTime = new Date();
//定义返回值
RmsJobResult result = new RmsJobResult();
result.setClientReceiveTime(receiveTime);
result.setId(param.getId());
result.setClientStartExecuteTime(new Date());
//执行(区分同步跟异步)
if (param.getAsync()) {
schClientHandle.asyncHandle(param, result);
result.setStats(RmsJobStats.EXECUTING.value());
} else {
schClientHandle.handle(param);
result.setClientEndExecuteTime(new Date());
result.setStats(RmsJobStats.COMPLETE.value());
}
//返回
return new RestResponse<>(result);
}
//SchClientHandle中
//异步执行
@Async
public void asyncHandle(RmsJobParam param, RmsJobResult result) {
try {
//执行
this.handle(param);
result.setClientEndExecuteTime(new Date());
result.setStats(RmsJobStats.COMPLETE.value());
//回调
this.callback(result);
} catch (Exception e) {
result.setClientEndExecuteTime(new Date());
result.setStats(RmsJobStats.ERROR.value());
result.setErrorMsg(ExceptionUtils.getStackTrace(e));
//回调
this.callback(result);
//抛出异常
log.error("asyncHandle error:", e);
throw new SchException(e);
}
}
//同步执行
public void handle(RmsJobParam param) {
//判断bean是否存在
if (!applicationContext.containsBean(param.getBeanName())) {
throw new SchException(param.getBeanName() + " not definition");
}
//获得bean
AbstractExecutor bean = applicationContext.getBean(param.getBeanName(), AbstractExecutor.class);
//执行
bean.handle(param);
}
//异步回调(重处理)
@Retryable(maxAttempts = 3, value = Exception.class)
private void callback(RmsJobResult result) {
log.info("try to callback");
final String serviceCode = "SCH_CLIENT_CALLBACK_1";
rms.call(serviceCode, result, null, new ParameterizedTypeReference<RestResponse<String>>() {
}, null);
}
//回调失败后的处理
@Recover
public void recover(Exception e) {
log.error("try to callback failed:", e);
}
任务链
在执行器父类中提供如下方法,可在执行节点触发其他执行器:
//调用链 (允许并发,异步调用)
protected String chain(boolean isConcurrent, String parentId, String serviceCode,
String beanName, boolean async, Map<String, String> param)
而在执行器中的使用样例:
@Component("testBean")
public class TestSch extends AbstractExecutor {
@Override
public void handle(String id, Map<String, Object> jobDataMap) {
try {
LOGGER.info("任务执行了------id:{}, jobDataMap:{}", id, xssObjectMapper.writeValueAsString(jobDataMap)); //NOSONAR
if (!jobDataMap.containsKey(TriggerDataMapKey.PARENT_TRIGGER_ID.value())) {
LOGGER.info("job链---->"); //NOSONAR
Map<String, String> param = new HashMap<>();
param.put("chain1", "1");
param.put("chain2", "2");
this.chain(id, "SCH_CLIENT_UDF_SERVICE_A_DEMO", "testBean", param);
}
} catch (JsonProcessingException e) {
throw new SchException(e);
}
}
}
这样可以使得执行器更加灵活,可以随意组合
管理api
依赖于quartz的底层管理api,我们可以抽象出一系列restFul的api,目前实现的功能如下:
作业管理 : 保存作业 , 保存作业(覆盖) , 移除作业 , 立即触发作业
触发器管理 : 保存简单触发器 , 保存简单触发器(覆盖) , 保存CRON触发器 , 保存CRON触发器(覆盖) , 删除触发器
计划任务管理 : 清理数据
misfire设定
quartz原生的设定,表示那些错过了触发时间的触发器,后续处理的规则,可能是因为 : 服务不可用 , 线程阻塞,线程池耗尽 , 等..
simple触发器
MISFIRE_INSTRUCTION_FIRE_NOW
以当前时间为触发频率立即触发执行
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT
不触发立即执行
等待下次触发频率周期时刻执行
以总次数-已执行次数作为剩余周期次数,重新计算FinalTime
调整后的FinalTime会略大于根据starttime计算的到的FinalTime值
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT
不触发立即执行
等待下次触发频率周期时刻,执行至FinalTime的剩余周期次数
保持FinalTime不变,重新计算剩余周期次数(相当于错过的当做已执行)
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT
以当前时间为触发频率立即触发执行
以总次数-已执行次数作为剩余周期次数,重新计算FinalTime
调整后的FinalTime会略大于根据starttime计算的到的FinalTime值
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT
以当前时间为触发频率立即触发执行
保持FinalTime不变,重新计算剩余周期次数(相当于错过的当做已执行)
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
以错过的第一个频率时间立刻开始执行
MISFIRE_INSTRUCTION_SMART_POLICY(默认)
智能根据trigger属性选择策略:
repeatCount为0,则策略同MISFIRE_INSTRUCTION_FIRE_NOW
repeatCount为REPEAT_INDEFINITELY,则策略同MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT
否则策略同MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT
cron触发器
MISFIRE_INSTRUCTION_DO_NOTHING
是什么都不做,继续等下一次预定时间再触发
MISFIRE_INSTRUCTION_FIRE_ONCE_NOW
是立即触发一次,触发后恢复正常的频率
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
以错过的第一个频率时间立刻开始执行
MISFIRE_INSTRUCTION_SMART_POLICY(默认)
根据创建CronTrigger时选择的MISFIRE_INSTRUCTION_XXX更新CronTrigger的状态。
如果misfire指令设置为MISFIRE_INSTRUCTION_SMART_POLICY,则将使用以下方案:
指令将解释为MISFIRE_INSTRUCTION_FIRE_ONCE_NOW
大家可根据自身情况进行设定
结束
今天跟大家分享了分布式调度的设计思路和想法,由于个人时间问题,这个设计的核心部分虽然已经完成,但是比如web界面,restful api,都还没有完成,后续有空就会把这些东西都弄上去的.
不过总体来说,把核心的思想讲出来了,也欢迎大家提出意见和建议
代码仓库 (博客配套代码)
想获得最快更新,请关注公众号

spring boot / cloud (十五) 分布式调度中心进阶的更多相关文章
- spring boot / cloud (十六) 分布式ID生成服务
spring boot / cloud (十六) 分布式ID生成服务 在几乎所有的分布式系统或者采用了分库/分表设计的系统中,几乎都会需要生成数据的唯一标识ID的需求, 常规做法,是使用数据库中的自动 ...
- spring boot / cloud (十二) 异常统一处理进阶
spring boot / cloud (十二) 异常统一处理进阶 前言 在spring boot / cloud (二) 规范响应格式以及统一异常处理这篇博客中已经提到了使用@ExceptionHa ...
- spring boot / cloud (十四) 微服务间远程服务调用的认证和鉴权的思考和设计,以及restFul风格的url匹配拦截方法
spring boot / cloud (十四) 微服务间远程服务调用的认证和鉴权的思考和设计,以及restFul风格的url匹配拦截方法 前言 本篇接着<spring boot / cloud ...
- spring boot / cloud (十七) 快速搭建注册中心和配置中心
spring boot / cloud (十七) 快速搭建注册中心和配置中心 本文将使用spring cloud的eureka和config server来搭建. 然后搭建的模式,有很多种,本文主要聊 ...
- spring boot / cloud (十八) 使用docker快速搭建本地环境
spring boot / cloud (十八) 使用docker快速搭建本地环境 在平时的开发中工作中,环境的搭建其实一直都是一个很麻烦的事情 特别是现在,系统越来越复杂,所需要连接的一些中间件也越 ...
- spring boot / cloud (十九) 并发消费消息,如何保证入库的数据是最新的?
spring boot / cloud (十九) 并发消费消息,如何保证入库的数据是最新的? 消息中间件在解决异步处理,模块间解耦和,和高流量场景的削峰,等情况下有着很广泛的应用 . 本文将跟大家一起 ...
- Spring Boot (十五): 优雅的使用 API 文档工具 Swagger2
1. 引言 各位在开发的过程中肯定遇到过被接口文档折磨的经历,由于 RESTful 接口的轻量化以及低耦合性,我们在修改接口后文档更新不及时,导致接口的调用方(无论是前端还是后端)经常抱怨接口与文档不 ...
- Spring Boot教程(五)调度任务
构建工程 创建一个Springboot工程,在它的程序入口加上@EnableScheduling,开启调度任务. @SpringBootApplication @EnableScheduling pu ...
- 使用Intellij中的Spring Initializr来快速构建Spring Boot/Cloud工程(十五)
在之前的所有Spring Boot和Spring Cloud相关博文中,都会涉及Spring Boot工程的创建.而创建的方式多种多样,我们可以通过Maven来手工构建或是通过脚手架等方式快速搭建,也 ...
随机推荐
- volume 生命周期管理 - 每天5分钟玩转 Docker 容器技术(44)
Data Volume 中存放的是重要的应用数据,如何管理 volume 对应用至关重要.前面我们主要关注的是 volume 的创建.共享和使用,本节将讨论如何备份.恢复.迁移和销毁 volume. ...
- 教你做炫酷的碎片式图片切换 (canvas)
前言 老规矩,先上 DEMO 和 源码.图片区域是可以点击的,动画会从点击的位置开始发生. 本来这个效果是我3年前做的,只是当是是用无数个 div 标签完成的,性能比较成问题,在移动端完全跑不动.最近 ...
- Apache FtpServer 实现文件的上传和下载
1 下载需要的jar包 Ftp服务器实现文件的上传和下载,主要依赖jar包为: 2 搭建ftp服务器 参考Windows 上搭建Apache FtpServer,搭建ftp服务器 3 主要代码 在ec ...
- Java之集合的遍历与迭代器
集合的遍历 依次获取集合中的每一个元素 将集合转换成数组,遍历数组 //取出所有的学号, 迭代之后显示学号为1004-1009 Object[] c=map.keySet().toArray();// ...
- 二.GC相关之Java内存模型
根据上节描述的问题,我们知道其最终原因是GC导致的.本节我们就先详细探讨下与GC息息相关的Java内存模型. 名词解释:变量,理解为java的基本类型.对象,理解为java new出来的实例. Jav ...
- 一步一步深入理解Dijkstra算法
先简单介绍一下最短路径: 最短路径是啥?就是一个带边值的图中从某一个顶点到另外一个顶点的最短路径. 官方定义:对于内网图而言,最短路径是指两顶点之间经过的边上权值之和最小的路径. 并且我们称路径上的第 ...
- 数据结构与算法--KMP算法查找子字符串
数据结构与算法--KMP算法查找子字符串 部分内容和图片来自这三篇文章: 这篇文章.这篇文章.还有这篇他们写得非常棒.结合他们的解释和自己的理解,完成了本文. 上一节介绍了暴力法查找子字符串,同时也发 ...
- python教程6-2:字符串标识符
标识符合法性检查. 1.字母或者下划线开始. 2.后面是字母.下划线或者数字. 3.检查长度大于等于1. 4.可以识别关键字. python35 idcheck.py idcheck.py impo ...
- C++ STL 栈和队列详解
一.解释: 1.栈 栈是一种特殊的线性表.其特殊性在于限定插入和删除数据元素的操作只能在线性表的一端进行.如下所示: 结论:后进先出(Last In First Out),简称为LIFO线性表. 举个 ...
- 解决lxml不含etree模块导致scrapy startproject ***出错
本文环境:win10(64) python3.6(64) 背景:之前已成功安装scrapy(1.4.0),但在命令行敲 scrapy startproject ***出错,错误提示:from ... ...