缓存一致性和跨服务器查询的数据异构解决方案canal
当你的项目数据量上去了之后,通常会遇到两种情况,第一种情况应是最大可能的使用cache来对抗上层的高并发,第二种情况同样也是需要使用分库
分表对抗上层的高并发。。。逼逼逼起来容易,做起来并不那么乐观,由此引入的问题,不见得你有好的解决方案,下面就具体分享下。
一:尽可能的使用Cache
比如在我们的千人千面系统中,会针对商品,订单等维度为某一个商家店铺自动化建立大约400个数据模型,然后买家在淘宝下订单之后,淘宝会将订单推
送过来,订单会在400个模型中兜一圈,从而推送更贴切符合该买家行为习惯的短信和邮件,这是一个真实的业务场景,为了应对高并发,这些模型自然都是缓
存在Cache中,模型都是从db中灌到redis的,那如果有新的模型进来了,我如何通知redis进行缓存更新呢???通常的做法就是在添加模型的时候,顺便更新
redis。。。对吧,如下图:
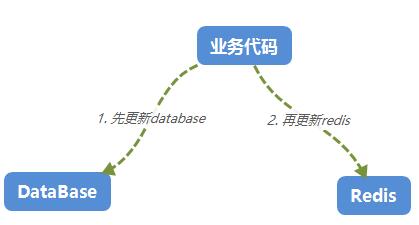
说的简单,web开发的程序员会说,麻蛋的,我管你什么业务,更新你妹啊。。。我把自己的手头代码写好就可以了,我要高内聚,所以你必须碰一鼻子灰。
除了一鼻子灰之后,也许你还会遇到更新database成功,再更新redis的时候失败,可人家不管,而且错误日志还是别人的日志系统里面,所以你很难甚至
无法保证这个db和cache的缓存一致性,那这个时候能不能换个思路,我直接写个程序订阅database的binlog,从binlog中分析出模型数据的CURD操作,根
据这些CURD的实际情况更新Redis的缓存数据,第一个可以实现和web的解耦,第二个实现了高度的缓存一致性,所以新的架构是这样的。
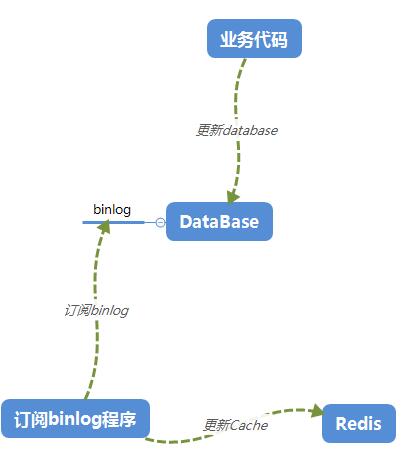
上面这张图,相信大家都能看得懂,重点就是这个处理binlog程序,从binlog中分析出CURD从而更新Redis,其实这个binlog程序就是本篇所说的canal。。。
一个伪装成mysql的slave,不断的通过dump命令从mysql中盗出binlog日志,从而完美的实现了这个需求。
二:数据异构
本篇开头也说到了,数据量大了之后,必然会存在分库分表,甚至database都要分散到多台服务器上,现在的电商项目,都是业务赶着技术跑。。。
谁也不知道下一个业务会是一个怎样的奇葩,所以必然会导致你要做一些跨服务器join查询,你以为自己很聪明,其实DBA早就把跨服务器查询的函数给你
关掉了,求爹爹拜奶奶都不会给你开的,除非你杀一个DBA祭天,不过如果你的业务真的很重要,可能DBA会给你做数据异构,所谓的数据异构,那就是
将需要join查询的多表按照某一个维度又聚合在一个DB中。让你去查询。。。。。
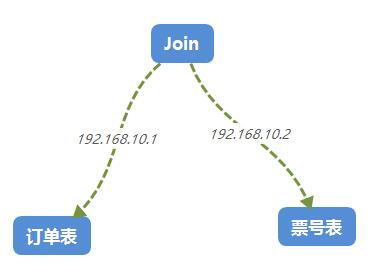
那如果用canal来订阅binlog,就可以改造成下面这种架构。
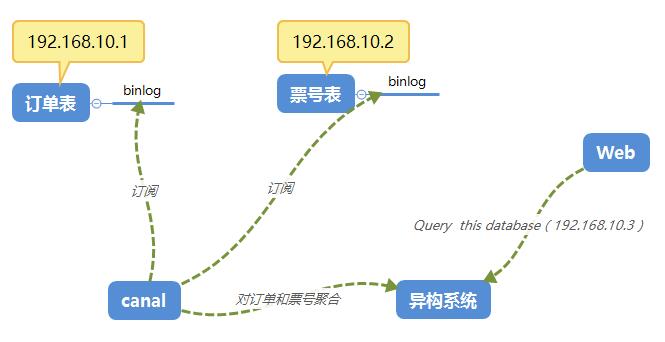
三:搭建一览
好了,canal的应用场景给大家也介绍到了,最主要是理解这种思想,人家搞不定的东西,你的价值就出来了。
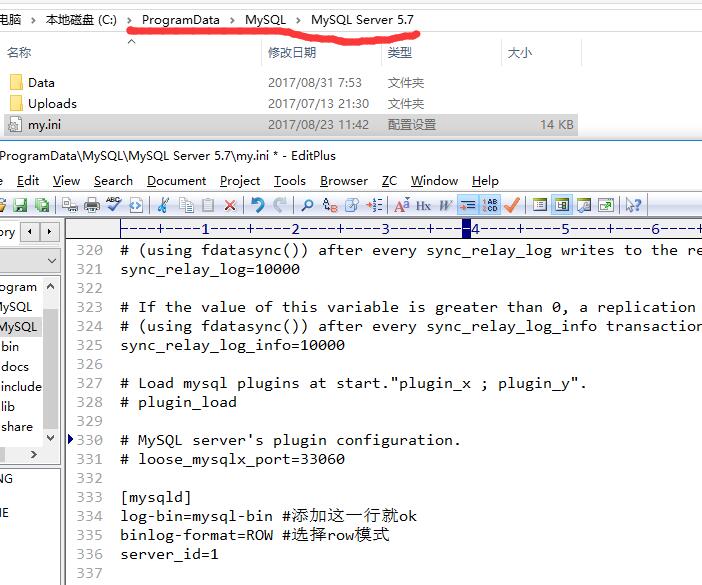
1. 开启mysql的binlog功能
开启binlog,并且将binlog的格式改为Row,这样就可以获取到CURD的二进制内容,windows上的路径为:C:\ProgramData\MySQL\MySQL Server 5.7\my.ini。
log-bin=mysql-bin #添加这一行就ok
binlog-format=ROW #选择row模式
server_id=
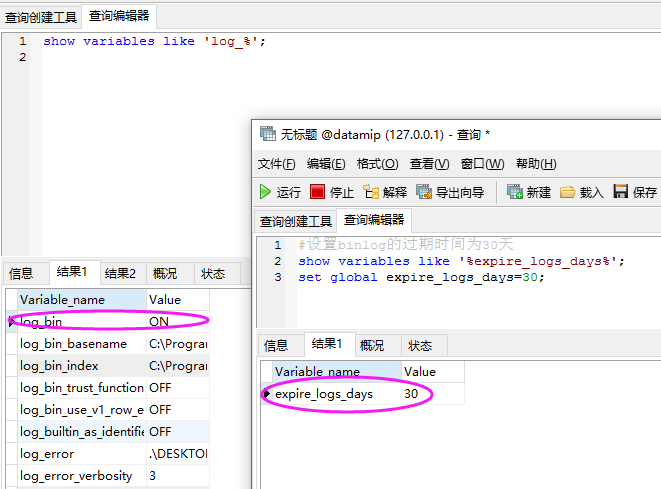
2. 验证binlog是否开启
使用命令验证,并且开启binlog的过期时间为30天,默认情况下binlog是不过期的,这就导致你的磁盘可能会爆满,直到挂掉。
show variables like 'log_%'; #设置binlog的过期时间为30天
show variables like '%expire_logs_days%';
set global expire_logs_days=;
3. 给canal服务器分配一个mysql的账号权限,方便canal去偷binlog日志。
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES; show grants for 'canal'
4. 下载canal
github的地址: https://github.com/alibaba/canal/releases
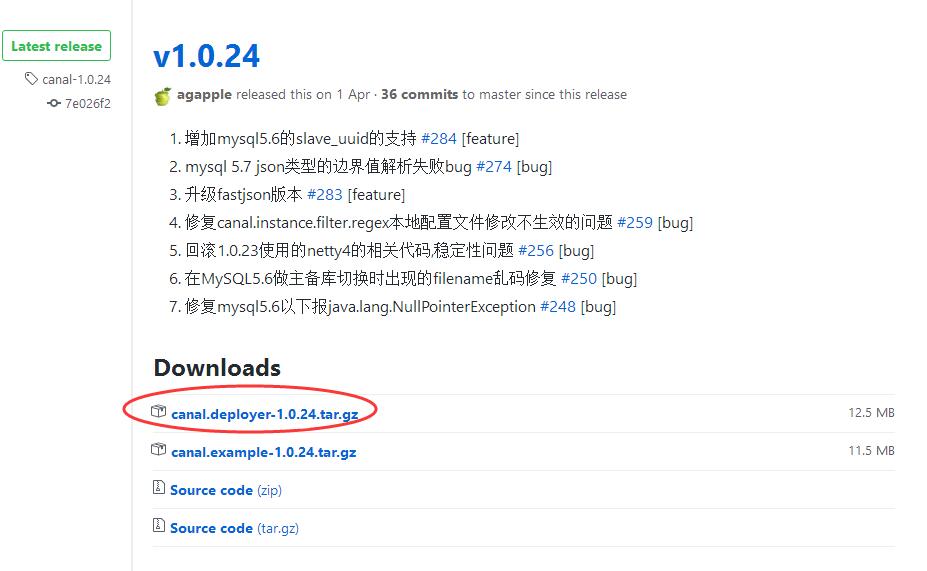
5. 然后就是各种tar解压 canal.deployer-1.0.24.tar.gz => canal
[root@localhost myapp]# ls
apache-maven-3.5.0-bin.tar.gz dubbo-monitor-simple-2.5.4-SNAPSHOT.jar nginx tengine-2.2.0.tar.gz
canal gearmand nginx-1.13.4.tar.gz tengine_st
canal.deployer-1.0.24.tar.gz gearmand-1.1.17 nginx_st tomcat
dubbo gearmand-1.1.17.tar.gz redis zookeeper
dubbo-monitor-simple-2.5.4-SNAPSHOT maven redis-4.0.1.tar.gz zookeeper-3.4.9.tar.gz
dubbo-monitor-simple-2.5.4-SNAPSHOT-assembly.tar.gz mysql-5.7.19-linux-glibc2.12-x86_64.tar.gz tengine
[root@localhost myapp]# cd canal
[root@localhost canal]# ls
bin conf lib logs
[root@localhost canal]# cd conf
[root@localhost conf]# ls
canal.properties example logback.xml spring
[root@localhost conf]# cd example
[root@localhost example]# ls
instance.properties meta.dat
[root@localhost example]#
6. canal 和 instance 配置文件
canal的模式是这样的,一个canal里面可能会有多个instance,也就说一个instance可以监控一个mysql实例,多个instance也就可以对应多台服务器
的mysql实例。也就是一个canal就可以监控分库分表下的多机器mysql。
《1》 canal.properties
它是全局性的canal服务器配置,具体如下,这里面的参数涉及到方方面面。
#################################################
######### common argument #############
#################################################
canal.id= 1
canal.ip=
canal.port= 11111
canal.zkServers=
# flush data to zk
canal.zookeeper.flush.period = 1000
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE ## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false # support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60 # network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30 # binlog filter config
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false # binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB # binlog ddl isolation
canal.instance.get.ddl.isolation = false #################################################
######### destinations #############
#################################################
canal.destinations= example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5 canal.instance.global.mode = spring
canal.instance.global.lazy = false
#canal.instance.global.manager.address = 127.0.0.1:1099
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml #################################################
## mysql serverId
canal.instance.mysql.slaveId = 1234 # position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp = #canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp = # username/password,需要改成自己的数据库信息
canal.instance.dbUsername = root
canal.instance.dbPassword = 123456
canal.instance.defaultDatabaseName = datamip
canal.instance.connectionCharset = UTF-8 # table regex
canal.instance.filter.regex = .*\\..* #################################################
由于是全局性的配置,所以上面三处标红的地方要注意一下:
canal.port= 11111 当前canal的服务器端口号
canal.destinations= example 当前默认开启了一个名为example的instance实例,如果想开多个instance,用","逗号隔开就可以了。。。
canal.instance.filter.regex = .*\\..* mysql实例下的所有db的所有表都在监控范围内。
《2》 instance.properties
这个就是具体的某个instances实例的配置,未涉及到的配置都会从canal.properties上继承。
#################################################
## mysql serverId
canal.instance.mysql.slaveId = 1234 # position info
canal.instance.master.address = 192.168.23.1:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp = #canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp = # username/password
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
canal.instance.defaultDatabaseName =datamip
canal.instance.connectionCharset = UTF-8 # table regex
canal.instance.filter.regex = .*\\..*
# table black regex
canal.instance.filter.black.regex = #################################################
上面标红的地方注意下就好了,去偷binlog的时候,需要知道的mysql地址和用户名,密码。
7. 开启canal
大家要记得把/canal/bin 目录配置到 /etc/profile 的 Path中,方便快速开启,通过下图你会看到11111端口已经在centos上开启了。
[root@localhost bin]# ls
canal.pid startup.bat startup.sh stop.sh
[root@localhost bin]# pwd
/usr/myapp/canal/bin
[root@localhost example]# startup.sh
cd to /usr/myapp/canal/bin for workaround relative path
LOG CONFIGURATION : /usr/myapp/canal/bin/../conf/logback.xml
canal conf : /usr/myapp/canal/bin/../conf/canal.properties
CLASSPATH :/usr/myapp/canal/bin/../conf:/usr/myapp/canal/bin/../lib/zookeeper-3.4.5.jar:/usr/myapp/canal/bin/../lib/zkclient-0.1.jar:/usr/myapp/canal/bin/../lib/spring-2.5.6.jar:/usr/myapp/canal/bin/../lib/slf4j-api-1.7.12.jar:/usr/myapp/canal/bin/../lib/protobuf-java-2.6.1.jar:/usr/myapp/canal/bin/../lib/oro-2.0.8.jar:/usr/myapp/canal/bin/../lib/netty-all-4.1.6.Final.jar:/usr/myapp/canal/bin/../lib/netty-3.2.5.Final.jar:/usr/myapp/canal/bin/../lib/logback-core-1.1.3.jar:/usr/myapp/canal/bin/../lib/logback-classic-1.1.3.jar:/usr/myapp/canal/bin/../lib/log4j-1.2.14.jar:/usr/myapp/canal/bin/../lib/jcl-over-slf4j-1.7.12.jar:/usr/myapp/canal/bin/../lib/guava-18.0.jar:/usr/myapp/canal/bin/../lib/fastjson-1.2.28.jar:/usr/myapp/canal/bin/../lib/commons-logging-1.1.1.jar:/usr/myapp/canal/bin/../lib/commons-lang-2.6.jar:/usr/myapp/canal/bin/../lib/commons-io-2.4.jar:/usr/myapp/canal/bin/../lib/commons-beanutils-1.8.2.jar:/usr/myapp/canal/bin/../lib/canal.store-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.sink-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.server-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.protocol-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.parse.driver-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.parse.dbsync-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.parse-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.meta-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.instance.spring-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.instance.manager-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.instance.core-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.filter-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.deployer-1.0.24.jar:/usr/myapp/canal/bin/../lib/canal.common-1.0.24.jar:/usr/myapp/canal/bin/../lib/aviator-2.2.1.jar:
cd to /usr/myapp/canal/conf/example for continue
[root@localhost example]# netstat -tln
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:11111 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN
tcp6 0 0 :::111 :::* LISTEN
tcp6 0 0 :::22 :::* LISTEN
tcp6 0 0 ::1:631 :::* LISTEN
tcp6 0 0 ::1:25 :::* LISTEN
[root@localhost example]#
8. Java Client 代码
canal driver 需要在maven仓库中获取一下:http://www.mvnrepository.com/artifact/com.alibaba.otter/canal.client/1.0.24,不过依赖还是蛮多的。
<!-- https://mvnrepository.com/artifact/com.alibaba.otter/canal.client -->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.0.24</version>
</dependency>
9. 启动java代码进行验证
下面的代码对table的CURD都做了一个基本的判断,看看是不是能够智能感知,然后可以根据实际情况进行redis的更新操作。。。
package com.datamip.canal; import java.awt.Event;
import java.net.InetSocketAddress;
import java.util.List; import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.Header;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException; public class App { public static void main(String[] args) throws InterruptedException { // 第一步:与canal进行连接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.23.170", 11111),
"example", "", "");
connector.connect(); // 第二步:开启订阅
connector.subscribe(); // 第三步:循环订阅
while (true) {
try {
// 每次读取 1000 条
Message message = connector.getWithoutAck(1000); long batchID = message.getId(); int size = message.getEntries().size(); if (batchID == -1 || size == 0) {
System.out.println("当前暂时没有数据");
Thread.sleep(1000); // 没有数据
} else {
System.out.println("-------------------------- 有数据啦 -----------------------");
PrintEntry(message.getEntries());
} // position id ack (方便处理下一条)
connector.ack(batchID); } catch (Exception e) {
// TODO: handle exception } finally {
Thread.sleep(1000);
}
}
} // 获取每条打印的记录
@SuppressWarnings("static-access")
public static void PrintEntry(List<Entry> entrys) { for (Entry entry : entrys) { // 第一步:拆解entry 实体
Header header = entry.getHeader();
EntryType entryType = entry.getEntryType(); // 第二步: 如果当前是RowData,那就是我需要的数据
if (entryType == EntryType.ROWDATA) { String tableName = header.getTableName();
String schemaName = header.getSchemaName(); RowChange rowChange = null; try {
rowChange = RowChange.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
} EventType eventType = rowChange.getEventType(); System.out.println(String.format("当前正在操作 %s.%s, Action= %s", schemaName, tableName, eventType)); // 如果是‘查询’ 或者 是 ‘DDL’ 操作,那么sql直接打出来
if (eventType == EventType.QUERY || rowChange.getIsDdl()) {
System.out.println("rowchange sql ----->" + rowChange.getSql());
return;
} // 第三步:追踪到 columns 级别
rowChange.getRowDatasList().forEach((rowData) -> { // 获取更新之前的column情况
List<Column> beforeColumns = rowData.getBeforeColumnsList(); // 获取更新之后的 column 情况
List<Column> afterColumns = rowData.getAfterColumnsList(); // 当前执行的是 删除操作
if (eventType == EventType.DELETE) {
PrintColumn(beforeColumns);
} // 当前执行的是 插入操作
if (eventType == eventType.INSERT) {
PrintColumn(afterColumns);
} // 当前执行的是 更新操作
if (eventType == eventType.UPDATE) {
PrintColumn(afterColumns);
}
});
}
}
} // 每个row上面的每一个column 的更改情况
public static void PrintColumn(List<Column> columns) { columns.forEach((column) -> { String columnName = column.getName();
String columnValue = column.getValue();
String columnType = column.getMysqlType();
boolean isUpdated = column.getUpdated(); // 判断 该字段是否更新 System.out.println(String.format("columnName=%s, columnValue=%s, columnType=%s, isUpdated=%s", columnName,
columnValue, columnType, isUpdated)); }); }
}
<1> Update操作
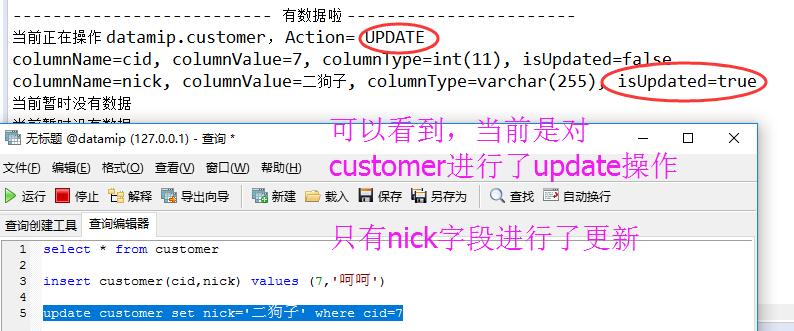
<2> Insert操作
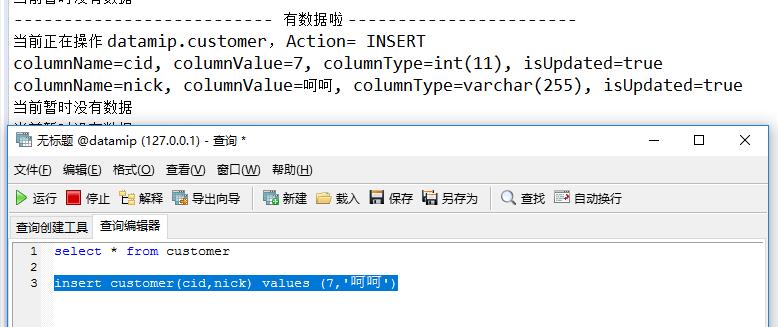
<3> Delete 操作
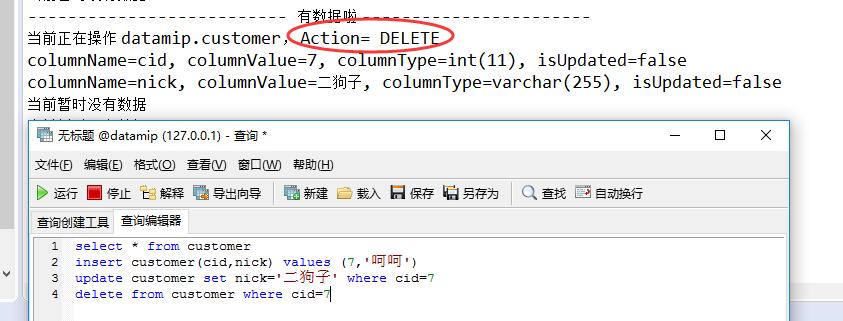
从结果中看,没毛病,有图有真相,好了,本篇就说到这里,对于开发的你,肯定是有帮助的~~~
缓存一致性和跨服务器查询的数据异构解决方案canal的更多相关文章
- sql 跨服务器查询数据
方法一:用OPENDATASOURCE [SQL SERVER] 跨服务器查询 --1 打开 reconfigure reconfigure SELECT * FROM OPENDATASOURCE( ...
- sqlserver 两 表 数据 复制 (附加 跨服务器 查询的方法)
一 : 这个sql 语句 可以快速的 将 一 个旧表 中的指定字段的数据 复制到 另一个新表的指定字段中 insert into dbo.Customer ( CustomerId , Custome ...
- SQLServer 跨服务器查询的两个办法
网上搜了跨服务器查询的办法,大概就是Linked Server(预存连接方式并保证连接能力)和OpenDataSource(写在语句中,可移植性强).根据使用函数的不同,性能差别显而易见...虽然很简 ...
- SQL Server跨服务器查询的实现方法,OpenDataSource
SQL Server跨服务器查询的方法我们经常需要用到,下面就为您介绍两种SQL Server跨服务器查询的方法,如果您感兴趣的话,不妨一看. SQL Server跨服务器查询方法一:用OPENDAT ...
- 跨服务器查询sql语句样例
若2个数据库在同一台机器上:insert into DataBase_A..Table1(col1,col2,col3----)select col11,col22,col33-- from Data ...
- 开启MSSQLServer跨服务器查询功能
首先在MSSQL客户端中进行如下图文操作配置 其次使用脚本进行操作配置 ---开启SQLServer 跨服务器查询功能 exec sp_configure 'show advanced options ...
- 跨服务器查询信息的sql
--跨服务器查询信息的sql: select * from openrowset( 'SQLOLEDB', '192.168.1.104'; 'sa'; '123.com',[AutoMonitorD ...
- 跨服务器查询sql语句样例(转)
若2个数据库在同一台机器上: insert into DataBase_A..Table1(col1,col2,col3----) select col11,col22,col33-- from Da ...
- SQL跨服务器查询数据库
有时候一个项目需要用到两个数据库或多个数据库而且这些数据库在不同的服务器上时,就需要通过跨服务器查找数据 在A服务器的数据库a查询服务器B的数据库b 的bb表 假如服务器B的IP地址为:10.0.22 ...
随机推荐
- java用户界面窗口
java用户界面窗口 窗口框 代码如下: package Day08; import java.awt.Color;import java.awt.FlowLayout;import java.awt ...
- shell脚本中字符串的常见操作及"command not found"报错处理(附源码)
简介 昨天在通过shell脚本实现一个功能的时候,由于对shell处理字符串的方法有些不熟悉导致花了不少时间也犯了很多错误,因此将昨日的一些错误记录下来,避免以后再犯. 字符串的定义与赋值 # 定义S ...
- C#中的Infinity和NaN
C#中double和float类型有两个特殊值: Infinity(无穷大):5.0 / 0.0 = Infinity NaN(not a number):0.0 / 0.0 = NaN 计算表达式 ...
- (转)Servlet初始化、运行、销毁全部过程
Servlet初始化.运行.销毁全部过程 (2012-07-05 10:41:26) 标签: 杂谈 分类: java基础面试知识 Servlet的生命周期是由servlet的容器来控制的.分为3个阶段 ...
- matlab图片清晰度调整
打开.fig文件后: 1.首先设置窗口中的文字大小和相关的图例 2.然后将窗口缩小到要在word中或者ppt中展示图片的大小(避免图片缩小减少清晰度) 3.调整横纵坐标说明,使得布局合理 4.点击Ei ...
- OpenLayers3--ol3--新特性
OL3: A high-performance, feature-packed library for all your mapping needs < 一个可以满足各种地图应用的高性能的.功能 ...
- HDU5723 Abandoned country (最小生成树+深搜回溯法)
Description An abandoned country has n(n≤100000) villages which are numbered from 1 to n. Since aban ...
- hdu--1018--Big Number(斯特林公式)
Big Number Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total ...
- 【思维】【水】 南阳oj 喷水装置(一)
描述 现有一块草坪,长为20米,宽为2米,要在横中心线上放置半径为Ri的喷水装置,每个喷水装置的效果都会让以它为中心的半径为实数Ri(0<Ri<15)的圆被湿润,这有充足的喷水装置i(1& ...
- 【水题】HDU--1280 前m大的数
还记得Gardon给小希布置的那个作业么?(上次比赛的1005)其实小希已经找回了原来的那张数表,现在她想确认一下她的答案是否正确,但是整个的答案是很庞大的表,小希只想让你把答案中最大的M个数告诉她就 ...