pandas使用总结
一、pandas简介
Pandas是基于Numpy开发出的,是一款开放源码的BSD许可的Python库,为Python编程语言提供了高性能,易于使用的数据结构和数据分析工具。Pandas用于广泛的领域,包括金融,经济,统计,分析等学术和商业领域。
学习pandas之前建议先学习numpy。
二、pandas数据结构
pandas包含3中数据结构:
- 系列(Series)
- 数据帧(DataFrame)
- 面板(Panel)
系列类似于一维数组,可以用行索引来访问系列中的元素;数据帧类似于二维数组,可以使用行索引和列索引来访问数据,相当于关系数据库中的数据表;面板为3维的数据结构。3中数据结构中,较高维数据结构是其较低维数据结构的容器。 例如,DataFrame是Series的容器,Panel是DataFrame的容器。而且在这3中数据结构中,数据帧DataFrame的使用最为普遍。
三、系列(Series)的创建
可以使用函数pandas.Series( data, index, dtype, copy)来创建pandas中的系列,其中data为创建系列的数据形式,如python中的list,dict和numpy中的ndarray;index为行索引,如果没有提供,则默认为np.arange(len(data));dtype用来指定数据类型,如果未指定,则推断数据类型;copy指定是否复制数据,默认为False。
1、创建空系列
import numpy as np
import pandas as pd
# 创建空系列
s = pd.Series()
print s
输出:
Series([], dtype: float64)
2、使用python列表创建系列
# 默认索引为np.arange(3)
a = pd.Series([1, 2, 3])
print a
# 指定索引为10,11,12
b = pd.Series([1, 2, 3], index=["10", "11", "12"])
print b
输出:
0 1
1 2
2 3
dtype: int64
10 1
11 2
12 3
dtype: int64
3、使用常数创建系列
a = pd.Series(5, index=[0, 1, 2])
print a
输出:
0 5
1 5
2 5
dtype: int64
pandas将会使用提供的常量填充系列的每个索引对应的位置。
4、使用numpy数组创建系列
a = pd.Series(np.arange(5))
print a
输出:
0 0
1 1
2 2
3 3
4 4
dtype: int32
5、使用python字典创建系列
字典(dict)可以作为输入传递,如果没有指定索引,则按排序顺序取得字典键以构造索引。 如果传递了索引,索引中与标签对应的数据中的值将被拉出。
a = pd.Series({1:"one", 2:"two", 3:"three"})
print a
b = pd.Series({1:"one", 2:"two", 3:"three"}, index=[1, 3])
print b
c = pd.Series({1:"one", 2:"two", 3:"three"}, index=[10, 11, 12])
print c
输出:
1 one
2 two
3 three
dtype: object
1 one
3 three
dtype: object
10 NaN
11 NaN
12 NaN
dtype: float64
在c中,索引10,11,12没有对应的数据,所以显示为NaN(Not a Number)。
四、系列(Series)的基本操作
1、访问Series中的元素
可以通过索引或切片的方式访问Series中的元素
s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
print s
#索引访问
print s[0]
print s['a']
#切片访问
print s[1:]
print s[:'c']
输出:
a 1
b 2
c 3
dtype: int64
1
1
b 2
c 3
dtype: int64
a 1
b 2
c 3
dtype: int64
2、获取Series的索引与值
s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
print s
#获取索引
print s.index
#获取值
print s.values
输出:
a 1
b 2
c 3
dtype: int64
Index([u'a', u'b', u'c'], dtype='object')
[1 2 3]
3、填充Series中的NaN(s.fillna())
c = pd.Series({1:"one", 2:"two", 3:"three"}, index=[10, 11, 12])
print c
#将NaN填充为0
c = c.fillna(0)
print c
输出:
10 NaN
11 NaN
12 NaN
dtype: float64
10 0.0
11 0.0
12 0.0
dtype: float64
4、替换(s.replace())
a = pd.Series([1, 2, 3])
print a
#将值3替换成6
a = a.replace(3, 6)
print a
输出:
0 1
1 2
2 3
dtype: int64
0 1
1 2
2 6
dtype: int64
5、排序
a = np.arange(10)
print a
np.random.shuffle(a)
print a
s = pd.Series(a)
#根据值降序排序
print s.sort_values(ascending=False)
#根据索引降序排序
print s.sort_index(ascending=False)
输出:
[0 1 2 3 4 5 6 7 8 9]
[0 4 1 8 9 6 2 5 3 7]
4 9
3 8
9 7
5 6
7 5
1 4
8 3
6 2
2 1
0 0
dtype: int32
9 7
8 3
7 5
6 2
5 6
4 9
3 8
2 1
1 4
0 0
dtype: int32
6、head和tail
head和tail用于对Series的小样本取样,s.head()将返回系列s的前5行,可以使用s.head(n)来返回系列的前n行,s.tail(n)返回s的倒数前n行。
s = pd.Series(np.arange(6))
print s
print s.head()
print s.head(2)
print s.tail()
print s.tail(2)
输出:
0 0
1 1
2 2
3 3
4 4
5 5
dtype: int32
0 0
1 1
2 2
3 3
4 4
dtype: int32
0 0
1 1
dtype: int32
1 1
2 2
3 3
4 4
5 5
dtype: int32
4 4
5 5
dtype: int32
7、与numpy类似的操作
a = pd.Series(np.arange(5))
# 元素个数
print a.size
# 形状
print a.shape
# 纬度
print a.ndim
# 元素类型
print a.dtype
输出:
5
(5L,)
1
int32
五、数据帧(DataFrame)的创建
与Series不同,DataFrame为二维的数据结构,包含了行索引和列索引,类似于二维表。
可以使用构造函数pandas.DataFrame( data, index, columns, dtype, copy)来创建一个数据帧,其中data为数据帧中的数据,可以为python中的列表list,字典dict,也可以是numpy数组,或者是pandas系列Series及另一个数据帧DataFrame;index为行索引,默认为np.arange(len(data));columns为列索引,列索引对于不同的数据类型有不同的默认值;dtype可以用来指定列的数据类型;copy用来指定是否复制数据,默认为False。
1、使用列表list创建
a = [1, 2, 3]
dfa = pd.DataFrame(a)
print dfa
b = [[1, 2, 3], [4, 5, 6]]
dfb = pd.DataFrame(b)
print dfb
输出:
0
0 1
1 2
2 3
0 1 2
0 1 2 3
1 4 5 6
可以看到,除了行索引外,还多了列索引,是一个二维的数据结构。
2、使用字典dict创建
a = {"no":"001", "age":20, "name":"frank"}
dfa = pd.DataFrame(a, index=[0])
print dfa
b = {"no":["001", "002"], "age":[20, 21], "name":["frank", "peter"]}
dfb = pd.DataFrame(b)
print dfb
输出:
age name no
0 20 frank 001
age name no
0 20 frank 001
1 21 peter 002
需要注意的是,在字典a中,字典的值为一个常量(标量),不可迭代,所以在使用字典a创建DataFrame时要指定行索引,不然会报错。字典的键会被当做列索引。此时,若手动指定列索引,则列索引需在字典键的集合中,否则将会以NaN填充新的列索引对应的列。
b = {"no":["001", "002"], "age":[20, 21], "name":["frank", "peter"]}
df1 = pd.DataFrame(b)
print df1
print '-'*20
df2 = pd.DataFrame(b, columns=["no", "name"])
print df2
print '-'*20
df3 = pd.DataFrame(b, columns=["name", "gender"])
print df3
print '-'*20
df4 = pd.DataFrame(b, columns=["gender", "score"])
print df4
输出:
age name no
0 20 frank 001
1 21 peter 002
--------------------
no name
0 001 frank
1 002 peter
--------------------
name gender
0 frank NaN
1 peter NaN
--------------------
Empty DataFrame
Columns: [gender, score]
Index: []
3、使用字典列表创建
a = [{"no":"001", "age":20, "name":"frank"}, {"no":"002", "age":21, "name":"peter"}]
dfa = pd.DataFrame(a)
print dfa
#字典长度不一致
b = [{"no":"001", "age":20, "name":"frank"}, {"no":"002", "age":21, "name":"peter", "gender":"m"}]
dfb = pd.DataFrame(b)
print dfb
输出:
age name no
0 20 frank 001
1 21 peter 002
age gender name no
0 20 NaN frank 001
1 21 m peter 002
在b中,第二个字典多了一个字段gender,在第一个字典中会用NaN来填补此字段。
4、使用numpy数组创建
df = pd.DataFrame(np.random.randint(1, 10, (3, 3)), columns=['a', 'b', 'c'])
print df
输出:
a b c
0 4 6 9
1 9 1 3
2 1 2 3
5、使用系列Series创建
a = pd.Series(np.arange(3))
dfa = pd.DataFrame(a)
print dfa
b = {"no":pd.Series([1, 2, 3]), "age":pd.Series([20, 21, 22])}
print pd.DataFrame(b)
#指定行索引
c = {"no":pd.Series([1, 2, 3], index=["a", "b", "c"]), "age":pd.Series([20, 21, 22], index=["a", "b", "c"])}
print pd.DataFrame(c)
输出:
0
0 0
1 1
2 2
age no
0 20 1
1 21 2
2 22 3
age no
a 20 1
b 21 2
c 22 3
除了上面这几种创建DataFrame的方式外,还可以直接从文件中读取数据创建DataFrame,在文件操作中将对其总结。
六、数据帧(DataFrame)基本操作
在上文中Series的基本操作在DataFrame中也同样适用。
1、访问DataFrame中的元素
使用df[列索引]的方式或属性运算符.访问列,使用df.loc和df.iloc函数访问行或者数据帧的一个子数据帧。
a = np.random.randint(10, size=(3, 3))
print a
print '-'*20
df = pd.DataFrame(a, index=['i', 'j', 'k'], columns=['x', 'y', 'z'])
print df
print '-'*20
#使用列索引访问列
print df['x']
print '-'*20
#使用属性运算符访问列
print df.x
print '-'*20
#使用行索引访问行
print df.loc['i']
print '-'*20
#使用切片方式访问行列
print df.loc[:, 'x':'y']
print '-'*20
#访问多行,返回一个DataFrame
print df.loc[['i', 'j']]
print '-'*20
#使用整数索引访问行
print df.iloc[0]
print '-'*20
#访问具体的元素
print df.loc['j', 'y']
输出:
[[6 9 9]
[6 3 3]
[8 9 9]]
--------------------
x y z
i 6 9 9
j 6 3 3
k 8 9 9
--------------------
i 6
j 6
k 8
Name: x, dtype: int32
--------------------
i 6
j 6
k 8
Name: x, dtype: int32
--------------------
x 6
y 9
z 9
Name: i, dtype: int32
--------------------
x y
i 6 9
j 6 3
k 8 9
--------------------
x y z
i 6 9 9
j 6 3 3
--------------------
x 6
y 9
z 9
Name: i, dtype: int32
--------------------
3
2、行列的增加与删除
2.1 添加行
使用df.append(df1),将数据帧df1添加到df的后面(两个数据帧的列索引需相同)。
a = np.arange(9).reshape(3, 3)
dfa = pd.DataFrame(a, index=['i', 'j', 'k'], columns=['x', 'y', 'z'])
print dfa
#提供列索引
b = np.random.randint(10, size=(3, 3))
dfb = pd.DataFrame(b, columns=['x', 'y', 'z'])
print dfa.append(dfb)
#不提供索引
dfb = pd.DataFrame(b)
print dfa.append(dfb)
输出:
x y z
i 0 1 2
j 3 4 5
k 6 7 8
x y z
i 0 1 2
j 3 4 5
k 6 7 8
0 4 4 7
1 4 9 9
2 8 2 7
0 1 2 x y z
i NaN NaN NaN 0.0 1.0 2.0
j NaN NaN NaN 3.0 4.0 5.0
k NaN NaN NaN 6.0 7.0 8.0
0 4.0 4.0 7.0 NaN NaN NaN
1 4.0 9.0 9.0 NaN NaN NaN
2 8.0 2.0 7.0 NaN NaN NaN
2.2、删除行
使用df.drop()删除行。
a = np.arange(9).reshape(3, 3)
df = pd.DataFrame(a, index=['i', 'j', 'k'], columns=['x', 'y', 'z'])
print df
print df.drop('i')
输出:
x y z
i 0 1 2
j 3 4 5
k 6 7 8
x y z
j 3 4 5
k 6 7 8
2.3、添加列
有两种方法添加列。
a = np.arange(9).reshape(3, 3)
df = pd.DataFrame(a, columns=['x', 'y', 'z'])
print df
# 方法一
df['i'] = pd.DataFrame(['3', '4', '5'])
print df
# 方法二
df['j'] = df['x'] + df['y']
print df
输出:
x y z
0 0 1 2
1 3 4 5
2 6 7 8
x y z i
0 0 1 2 3
1 3 4 5 4
2 6 7 8 5
x y z i j
0 0 1 2 3 1
1 3 4 5 4 7
2 6 7 8 5 13
2.4、删除列
有两种方法删除列:使用del和df.pop(列标签)。
a = np.arange(9).reshape(3, 3)
df = pd.DataFrame(a, columns=['x', 'y', 'z'])
print df
#方法一
del df['x']
print df
#方法二
df.pop('z')
print df
输出:
x y z
0 0 1 2
1 3 4 5
2 6 7 8
y z
0 1 2
1 4 5
2 7 8
y
0 1
1 4
2 7
3、获取索引与值
a = np.arange(9).reshape(3, 3)
df = pd.DataFrame(a, columns=['x', 'y', 'z'])
print df.index
print df.columns
print df.values
输出:
x y z
0 0 1 2
1 3 4 5
2 6 7 8
RangeIndex(start=0, stop=3, step=1)
Index([u'x', u'y', u'z'], dtype='object')
[[0 1 2]
[3 4 5]
[6 7 8]]
4、按值排序
可以使用DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')对DataFrame进行排序,by为字符串或字符串列表,指明了根据哪一列进行排序;axis为要排序的轴,默认为0;ascending表明是否为升序排序,默认为False;kind为使用的排序算法,有3中算法可以选择: {‘quicksort’, ‘mergesort’, ‘heapsort’},mergesort是唯一的稳定排序算法,默认为quicksort;na_position有两个值可以选:first和last,first表示将NaN放在开头,last表示将NaN放在末尾。
df = pd.DataFrame({
'col1' : ['A', 'A', 'B', np.nan, 'D', 'C'],
'col2' : [2, 1, 9, 8, 7, 4],
'col3': [0, 1, 9, 4, 2, 3],
})
print df
print "根据col1升序排序:"
print df.sort_values(by=["col1"])
print "根据col1, col2升序排序:"
print df.sort_values(by=["col1", "col2"])
print "根据col1降序排序"
print df.sort_values(by=["col1"], ascending=False)
输出:
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
3 NaN 8 4
4 D 7 2
5 C 4 3
根据col1升序排序:
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
5 C 4 3
4 D 7 2
3 NaN 8 4
根据col1, col2升序排序:
col1 col2 col3
1 A 1 1
0 A 2 0
2 B 9 9
5 C 4 3
4 D 7 2
3 NaN 8 4
根据col1降序排序
col1 col2 col3
4 D 7 2
5 C 4 3
2 B 9 9
0 A 2 0
1 A 1 1
3 NaN 8 4
5、填充NaN
可以使用df.fillna(value)将NaN替换成value
df = pd.DataFrame({
'x' : ['A', 'A', 'B', np.nan, 'D', 'C'],
'y' : [2, 1, 9, 8, 7, 4],
'z': [0, 1, 9, 4, 2, 3],
})
print df
print '-'*20
#将NaN填充为0
print df.fillna(0)
输出:
x y z
0 A 2 0
1 A 1 1
2 B 9 9
3 NaN 8 4
4 D 7 2
5 C 4 3
--------------------
x y z
0 A 2 0
1 A 1 1
2 B 9 9
3 0 8 4
4 D 7 2
5 C 4 3
6、条件索引
df = pd.DataFrame(np.arange(9).reshape(3, 3))
print df
#大于5的值替换为-1
df[df>5] = -1
print df
输出:
0 1 2
0 0 1 2
1 3 4 5
2 6 7 8
0 1 2
0 0 1 2
1 3 4 5
2 -1 -1 -1
7、其他操作
a = np.arange(9).reshape(3, 3)
df = pd.DataFrame(a)
print a
#元素个数
print df.size
#形状
print df.shape
#维度
print df.ndim
#数据类型
print df.dtypes
#开头两行
print df.head(2)
#结束两行
print df.tail(2)
输出:
a = np.arange(9).reshape(3, 3)
df = pd.DataFrame(a)
print a
#元素个数
print df.size
#形状
print df.shape
#维度
print df.ndim
#数据类型
print df.dtypes
#开头两行
print df.head(2)
#结束两行
print df.tail(2)
a = np.arange(9).reshape(3, 3)
df = pd.DataFrame(a)
print a
#元素个数
print df.size
#形状
print df.shape
#维度
print df.ndim
#数据类型
print df.dtypes
#开头两行
print df.head(2)
#结束两行
print df.tail(2)
[[0 1 2]
[3 4 5]
[6 7 8]]
9
(3, 3)
2
0 int32
1 int32
2 int32
dtype: object
0 1 2
0 0 1 2
1 3 4 5
0 1 2
1 3 4 5
2 6 7 8
七、pandas统计函数
在统计函数的应用中,需要了解轴axis的概念,轴用来为超过一维的数组定义的属性,二维数据拥有两个轴:第0轴沿着行的垂直往下,第1轴沿着列的方向水平延伸。在DataFrame中,当axis为0时代表行,对列计算;当axis=1时,代表列,对行计算,如df.sum(axis=0)表示对数据帧中的每一列分别求和,而df.sum(axis=1)表示对每一行进行求和。
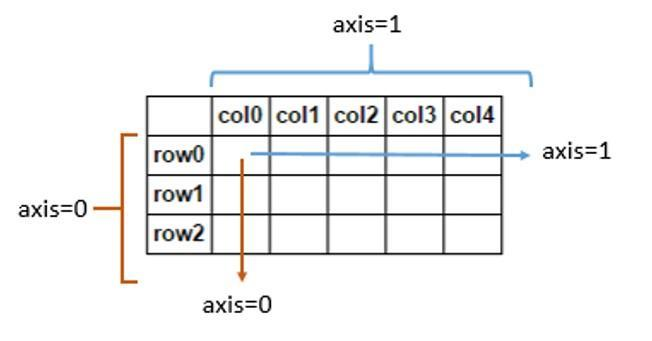
常用统计函数的用法如下:
a = {
"name":["张三", "李四", "王二", "麻子"],
"age":[20, 21, 19, 22],
"score":[90, 91, 92, 93]
}
df = pd.DataFrame(a)
print df
#分数总和
print df['score'].sum()
#分数平均数
print df['score'].mean()
#分数中位数
print df['score'].median()
#分数标准差
print df['score'].std()
#年龄最大值
print df['age'].min()
#年龄最小值
print df['age'].max()
#汇总数据
print df.describe()
输出:
age name score
0 20 张三 90
1 21 李四 91
2 19 王二 92
3 22 麻子 93
366
91.5
91.5
age score
count 4.000000 4.000000
mean 20.500000 91.500000
std 1.290994 1.290994
min 19.000000 90.000000
25% 19.750000 90.750000
50% 20.500000 91.500000
75% 21.250000 92.250000
max 22.000000 93.000000
下面的例子体现了axis=0和axis=1的差别:
df = pd.DataFrame(np.arange(9).reshape(3, 3), columns=['x', 'y', 'z'])
print df
print '-'*20
#axis默认为0,与df.sum()相同
print df.sum(axis=0)
print '-'*20
print df.sum(axis=1)
输出:
x y z
0 0 1 2
1 3 4 5
2 6 7 8
--------------------
x 9
y 12
z 15
dtype: int64
--------------------
0 3
1 12
2 21
dtype: int64
可以看到当axis=0时对列进行求和,当axis=1时对行进行求和。
八、文件操作
1、读取文件
可以使用pandas.read_csv()方法来读取文件,从官方文档可以看到该方法的参数非常多,下面介绍一些常用的参数:filepath_or_buffer用来指定文件路径;sep用来指定分隔符,默认为逗号,;delimiter同sep;header指定第几行为列名,默认为0;names指定列名;nrows指定读取文件的前多少行,对于读取大文件的一部分很有用;encoding指定编码方式。
在D盘根目录创建文件test.txt,内容如下:

#没有指定header,则第一行为列名
df = pd.read_csv("D:\\test.txt")
print df
#指定header为None
df = pd.read_csv("D:\\test.txt", header=None)
print df
#手动指定列名
df = pd.read_csv("D:\\test.txt", names=["name", "a", "b", "c"])
print df
输出:
张三 1 2 3
0 李四 4 5 6
0 1 2 3
0 张三 1 2 3
1 李四 4 5 6
name a b c
0 张三 1 2 3
1 李四 4 5 6
2、保存文件
使用DataFrame.to_csv()来将DataFrame中的数据保存为文件,to_csv()的参数非常多,这里介绍几个常用的参数:path_or_buf为保存文件的路径,如果没有提供,则返回一个字符串;sep指定文件中的分隔符, 默认为逗号,;na_rep指定缺失数据的表示,默认为空;columns用来指定DataFrame中的哪几列要保存到文件中;header表示是否写下列名,默认为True,还可以将一个字符串列表赋值给header表明要保存的列名;index指定是否写下行索引,默认为True;encoding指定编码。
df = pd.DataFrame({
'x' : ['A', 'A', 'B', np.nan, 'D', 'C'],
'y' : [2, 1, 9, 8, 7, 4],
'z': [0, 1, 9, 4, 2, 3],
})
print df
#使用默认的参数值
df.to_csv("D:\\df.txt")
输出:
x y z
0 A 2 0
1 A 1 1
2 B 9 9
3 NaN 8 4
4 D 7 2
5 C 4 3
保存的文件内容:

df = pd.DataFrame({
'x' : ['A', 'A', 'B', np.nan, 'D', 'C'],
'y' : [2, 1, 9, 8, 7, 4],
'z': [0, 1, 9, 4, 2, 3],
})
print df
#不保存行索引和列索引,分隔符改为空格,将NaN替换为0
df.to_csv("D:\\df.txt", sep=' ', header=False, index=False, na_rep=0)
保存的文件内容:
九、参考
1、https://www.yiibai.com/pandas/
2 、https://www.jianshu.com/p/7414364992e4
pandas使用总结的更多相关文章
- pandas基础-Python3
未完 for examples: example 1: # Code based on Python 3.x # _*_ coding: utf-8 _*_ # __Author: "LEM ...
- 10 Minutes to pandas
摘要 一.创建对象 二.查看数据 三.选择和设置 四.缺失值处理 五.相关操作 六.聚合 七.重排(Reshaping) 八.时间序列 九.Categorical类型 十.画图 十一 ...
- 利用Python进行数据分析(15) pandas基础: 字符串操作
字符串对象方法 split()方法拆分字符串: strip()方法去掉空白符和换行符: split()结合strip()使用: "+"符号可以将多个字符串连接起来: join( ...
- 利用Python进行数据分析(10) pandas基础: 处理缺失数据
数据不完整在数据分析的过程中很常见. pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据. pandas使用isnull()和notnull()函数来判断缺失情况. 对于缺失数据一般处理 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- pandas.DataFrame对行和列求和及添加新行和列
导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFra ...
- pandas.DataFrame排除特定行
使用Python进行数据分析时,经常要使用到的一个数据结构就是pandas的DataFrame 如果我们想要像Excel的筛选那样,只要其中的一行或某几行,可以使用isin()方法,将需要的行的值以列 ...
随机推荐
- Visual Studio Code 教程之————入门篇
Visual Studio代码是一个轻量级但功能强大的源代码编辑器,可在您的桌面上运行,适用于Windows,macOS和Linux.它内置对JavaScript,TypeScript和Node.js ...
- 15 Most Read Data Science Articles in 2015. So far …
15 Most Read Data Science Articles in 2015. So far … We've compiled the latest set of "most rea ...
- Java并发编程原理与实战八:产生线程安全性问题原因(javap字节码分析)
前面我们说到多线程带来的风险,其中一个很重要的就是安全性,因为其重要性因此,放到本章来进行讲解,那么线程安全性问题产生的原因,我们这节将从底层字节码来进行分析. 一.问题引出 先看一段代码 packa ...
- Java并发编程原理与实战一:聊聊并发
一.大纲 •你真的了解并发吗 •多线程和并发 •多线程和多进程 •线程一定快吗 •学习并发的四个阶段 •学习目标 •适合人群 •荐书 二.学习并发的四个阶段 •熟练掌握API,能够完成并发编程 • ...
- 实验一 《网络对抗技术》逆向及Bof技术
- python加速包numba并行计算多线程
1.下面直接上代码需要注意的地方numba的官网找到 1)有一些坑自己去numba的官网找找看,下面是我的写的一个加速的程序,希望对你有帮助. #coding:utf-8 import time fr ...
- Djangoform表单Ajax控制跳转
需求: 1:在登陆页面输入账号密码后,ajax异步提交数据给后端验证. 2:验证通过后,后端指定跳转页面,并把页面封装进返回的Json数据中,由ajax控制from表单跳转到目标页面 一:登陆页面HT ...
- pywin32记录备忘
项目地址:http://sourceforge.net/projects/pywin32/ 文档地址:http://docs.activestate.com/activepython/2.7/pywi ...
- CMD命令利用tasklist与taskkill关闭程序
昨天远程服务器后,服务器无故卡住了,鼠标各种延迟与无反应,想在进程管理器里关闭程序也卡住,想点击重启系统也卡死无反应.纠结后win+R打开了cmd用shutdown重启才算搞定.重启期间思考了下,如何 ...
- 【HASPDOG】hasp_update参数f和i区别
[root@BICServer-TX shared]# ./hasp_update This is a simple demo program for the Sentinel Update and ...